1, Introduction to internal implementation of Git warehouse
Git is essentially a content addressable file system, which locates the file according to the SHA-1 hash value of the file content. The core of Git is a simple key value data store. Inserting any type of content into git database will return a key value. The inserted content can be retrieved again at any time through the returned key value. Any data can be saved to the through the underlying command hash object Git directory and return the corresponding key value.
Git contains a set of tools for version control system, including high-level commands and low-level commands. Advanced commands are mainly used by users. The underlying commands can spy on the internal working mechanism of GIT, but most of the underlying commands are not oriented to end users and are more suitable as a part of new commands and custom scripts.
When git init is used to create a warehouse, GIT will create one Git directory, whose directory structure is as follows:

A. the description file is only used by GitWeb program.
B. The config file contains project specific configuration options.
C. The info directory contains a global exclude file, which is used to place files that you do not want to be recorded in Ignored patterns in gitignore file.
D. The hooks directory contains hook scripts on the client or server side.
E. The objects directory stores all data contents, including info and pack subdirectories.
F. The refs directory stores a pointer to the submission object of the data (Branch).
G. The HEAD file indicates which branch is currently checked out.
H. The index (to be created) file holds the staging area information.
objects, refs, HEAD and index are the four core parts of Git warehouse.
2, Git object
1. Introduction to Git objects
Git objects are divided into four types: data object (blob), tree object (tree), commit object (commit) and tag object (tag). The design idea of GIT file system is similar to that of linux file system, that is, the file content and file attributes are stored separately, the file content is stored in the file system, and the file attribute information such as file name, owner and permission is stored in another area.
Git uses SHA-1 encryption algorithm to generate a unique hexadecimal SHA-1 hash value with a length of 40 characters for each file it manages to uniquely identify the object. If the file does not change, the SHA-1 hash value will not change; If the file changes, a new SHA-1 hash value is generated. The first two characters of the 40 character SHA-1 hash value are used as the directory name and the last 38 characters are used as the file name to identify the generated git object.
The SHA-1 hash value of Git object is calculated as follows:
header = "<type> " + content.length + "\0" hash = sha1(header + content)
When calculating the object hash, Git will first add a header to the object header. The header consists of three parts: the first part represents the type of object, which can take blob, tree and commit to represent data object, tree object and submission object respectively; The second part is the byte length of data; The third part is an empty byte, which is used to separate header and content. After adding the header to the content header, use the sha1 algorithm to calculate a 40 bit hash value.
When manually calculating the hash of Git objects, you should pay attention to:
A. The second part of the header is about the calculation of data length, which must be the length of bytes rather than the length of strings;
B. The operation of header + content is not string level splicing, but binary level splicing.
The hash methods of various Git objects are the same, except that:
A. The object is a tree, the object is a tree, and the object is a blob;
B. The data content is different. The content of the data object can be any content, while the content of the tree object and the submission object has a fixed format.
Git cat file can be used to read all git objects, including data objects, tree objects and submission objects.
git cat-file -p [hash-key]
You can view the contents of existing object objects
git cat-file -t [hash-key]
You can view existing object types
2. Git data object
2.1Git data object introduction
Data objects are usually used to store the contents of files, but do not include file names, permissions and other information. It has nothing to do with the path of the data object and its corresponding file and whether the file name is changed or not.
Git will calculate a SHA-1 hash value according to the file content, and use the hash value as the index to store the file in the GIT file system. Since the hash value of the same file content is the same, GIT will store the same file content only once. The GIT hash object command can be used to calculate the hash value of the file content and store the generated data object in the GIT file system.
echo -en "hello,git" | git hash-object --stdin
f28ffa36cdf69904e516babfdb3005e108dddfb7
Use the - N option after echo to prevent the automatic addition of line breaks at the end of the string, otherwise the actual hash object passed to git will be hello,git\n
Data object view:
git show + object name (SHA1 hash value)
2.2Git data object SHA-1 hash value calculation
The content format of the data object is as follows:
blob <content length><NULL><content>
Use git hash object to calculate SHA1 hash value of text
echo -en "hello,git" | git hash-object --stdin
f28ffa36cdf69904e516babfdb3005e108dddfb7
Calculate SHA1 hash value of text using openssl:
echo -en "blob 9\0hello,git" | openssl sha1
(stdin)= f28ffa36cdf69904e516babfdb3005e108dddfb7
If there is Chinese in the text, it must be noted that the calculation of data length is the number of bytes rather than the number of characters. You can view the number of bytes of text using the command:
echo -n "chinese" | wc -c
2.3 access of GIT data object
git init Test
Initialize a version Library
cd Test
Enter Test
find .git/objects
Find Contents in git/objects directory
Git initializes the objects directory and creates the pack and info directories, but both are empty.
echo 'test content' | git hash-object -w --stdin
Save text to Git database
d670460b4b4aece5915caf5c68d12f560a9fe3e4
Key value returned
-The w option instructs the hash object command to store data objects; If this option is not specified, the above command returns only the corresponding key value.
--stdin option indicates that the above command reads the content from the standard input. If this option is not specified, the path of the file to be stored must be given at the end of the command.
The command outputs a checksum with a length of 40 characters, which is a SHA-1 hash value and a checksum obtained by performing SHA-1 checksum operation with the data to be stored plus a header.
find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4
You can see a file in the objects directory. Git stores content in such a way that a file corresponds to a piece of content, and names the file with the SHA-1 checksum of the content plus the specific header information. The first two characters of the checksum are used to name subdirectories, and the remaining 38 characters are used as file names.
You can retrieve data from the Git database through the cat file command. Specify the - p option to instruct the cat file command to automatically determine the type of content and display format friendly content:
git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test content
Implementation of version control principle of 2.4Git
Through simple version control of a file, this paper reveals the principle of Git version control. First, create a new file and store its contents in the Git database.
echo "version 1" > test
Write test file contents
git hash-object -w test
Store test file to Git database
83baae61804e65cc73a7201a7252750c76066a30
echo 'version 2' > test
Write new contents of test file
git hash-object -w test
Store the modified test file in Git database again
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
The Git database records two different versions of the test file.
find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 .git/objects/83/baae61804e65cc73a7201a7252750c76066a30 .git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
Restore the test file to the first version:
git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test
cat test
Read the contents of test file
version 1
Restore the test file to the second version:
git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test
cat test
Read the contents of test file
version 2
In the above version control of the file, it is unrealistic to remember the SHA-1 value corresponding to each version of the file, and the file name is not saved.
Using the cat file - t command, you can view any object type stored inside Git, as long as the SHA-1 value of the given object.
git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a blob
Through the hash value of each data object, you can access any data object in the Git file system, but it is obviously unrealistic to remember the SHA-1 hash value of the data object. Data object only solves the problem of file content storage, while the storage of file name needs to be realized through tree object.
3. Git tree object
3.1Git object introduction
Tree objects contain multiple pointers to data objects or other tree objects, which are used to represent the directory hierarchical relationship between contents.
All contents of Git are stored in the form of tree objects and data objects. The tree objects correspond to directory entries in UNIX, and the data objects correspond to inodes or file contents. A tree object contains one or more tree entries. Each tree object record contains a SHA-1 pointer to the data object or subtree object and the corresponding mode, type and file name information.
The latest tree object currently corresponding to an item can be viewed using the following commands:
git cat-file -p master^{tree}The master^{tree} syntax indicates the tree object pointed to by the latest Submission on the master branch. The directory (the corresponding tree object record) is not a data object, but a pointer to another tree object.
Tree object view:
git show + object name / git LS tree + object name
Git LS files -- the stage command can view the contents of the staging area.
3.2Git tree object SHA1 hash value calculation
The content format of the tree object is as follows:
tree <content length><NUL><file mode> <filename><NUL><item sha>...
The < item Sha > part is the sha1 code in binary form, not the sha1 code in hexadecimal form.
git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txt
Firstly, use xxd to convert 83baae61804e65cc73a7201a7252750c76066a30 into binary form, and save the result as SHA1 Txt to facilitate additional operations later.
echo -en "83baae61804e65cc73a7201a7252750c76066a30" | xxd -r -p > sha1.txt
Construct the content part and save it to the file content txt
echo -en "100644 test.txt\0" | cat - sha1.txt > content.txt
Calculate the length of content
cat content.txt | wc -c
Generate SHA-1
echo -en "tree 36\0" | cat - content.txt | openssl sha1
(stdin)= d8329fc1cc938780ffdd9f94e0d364e0ea74f579
3.3 git tree object generation
Git creates and records a corresponding tree object according to the state represented by the temporary storage area (i.e. index file) at a certain time. In this way, a series of tree objects (within a certain time period) can be recorded successively. Therefore, to create a tree object, you first need to create a staging area by staging some files. Create a staging area for the first version of a single file (test.txt file) through update index. Using the update index command, you can add the first version of the test file to a new temporary storage area.
git update-index --add --cacheinfo 100644 \ 83baae61804e65cc73a7201a7252750c76066a30 test
--Add means to add a new file name. If you add a file name for the first time, you must use this option-- Cacheinfo < mode > < Object > < Path > is the mode, hash value and path of the data object to be added, < Path > means that not only a simple file name but also a path can be specified for the data object. In addition, it should be noted that after adding files using Git update index, you must use Git write tree to write to the Git file system, otherwise it will only exist in the temporary storage area.
The specified file mode is 100644, indicating that it is an ordinary file. Other options include: 100755, representing an executable file; 120000 represents a symbolic link.
You can now write the contents of the staging area to a tree object through the write tree command. There is no need to specify the - w option. If a tree object does not exist, a new tree object will be automatically created according to the current staging area state when calling the write tree command.
git write-tree
5bf35b145b6281c080d58b6d19a5113a47f782ed
git cat-file -p 5bf35b145b6281c080d58b6d19a5113a47f782ed
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test
git cat-file -t 5bf35b145b6281c080d58b6d19a5113a47f782ed
tree
git tree objects are generated in the process of commit, and their generation will be based on The contents of the index file in the git directory. The operation of git add is to save the information of the file into the index file, and generate a tree object according to the content of the index when committing.
Use Git update index to specify the name and schema for the data object, and then use Git write tree to write the tree object to the Git file system.
Create a new tree object, including test Txt file and a new file.
echo 'new file' > new.txt git update-index --cacheinfo 100644 \ 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt git update-index --add new.txt
The staging area now contains test Txt file and a new file new Txt to generate a new tree object using the current staging area.
git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
The new tree object contains two file records, test The SHA-1 value of TXT is the second version of test txt. Add the first tree object to the second tree object to make it a subdirectory of the new tree object. The tree object can be read into the temporary storage area by calling the read tree command. By specifying the -- prefix option on the read tree, an existing tree object is read into the staging area as a subtree.
git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579 git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak 100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt 100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
If you create a working directory based on the new tree object, the root directory of the working directory contains two files and a subdirectory named bak, which contains test Txt file.
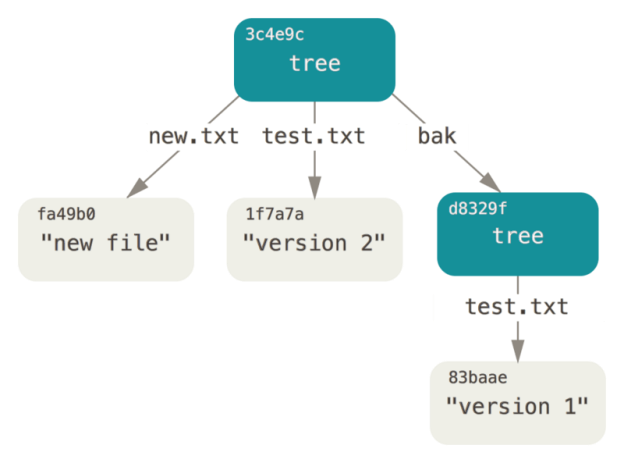
The tree object solves the problem of file name, and because the tree object is submitted in stages, the tree object can be regarded as a snapshot of the source code directory tree in the development stage, so the tree object can be used as the source code version management. However, you need to remember the hash value of each tree object to find the source code file directory tree of each stage. In source code version control, you also need to know who submitted the code, when, and the description information submitted. The submission object is to solve the above problems.
4. Git submit object
4.1Git submission object introduction
The submission object points to a tree object with relevant description information to mark the status of the project at a specific point in time. The submission object contains some metadata about the point in time, such as timestamp, author of the last submission, pointer to the last submission, and so on.
The submitted objects are as follows:
git show / git log + -s + --pretty=raw +Object name
4.2Git submission object generation
The submission object is used to save the author, time and description of the submission. You can use Git commit tree to write the submission object to the Git file system.
echo 'first commit' | git commit-tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
162f9174ac6bb4c5d41bfc00fcb5147e2d62b839
In addition to specifying the tree object to be submitted, the commit tree also needs to provide the submission description. However, the author and time of submission are automatically generated according to the environment variables and do not need to be specified. Due to the different author and time of submission, the SHA-1 hash value of the submission object is also different.
Git cat file can be used to view the submitted object.
git cat-file -p 162f9174ac6bb4c5d41bfc00fcb5147e2d62b839 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author scorpio <642960662@qq.com> 1536497938 +0800 committer scorpio <642960662@qq.com> 1536497938 +0800 first commit
For non first submission, you need to specify - p to specify the parent submission object, so that the code version can become a timeline.
echo 'second commit' | git commit-tree 0155eb -p 162f9174ac6bb4c5d41bfc00fcb5147e2d62b839
f6bbc9d4e8de1b35ad66c2115aa8519587c26100
Git cat file check the new submission object and see that there is more parent than the first submission.
Third submission:
echo 'third commit' | git commit-tree 3c4e9c -p f6bbc9d4e8de1b35ad66c2115aa8519587c26100
Third submission view:
git log --stat 26a72965aa9c1bdab9fe5972012bd903f501f006 --pretty=oneline
26a72965aa9c1bdab9fe5972012bd903f501f006 third commit bak/test.txt | 1 + 1 file changed, 1 insertion(+) f6bbc9d4e8de1b35ad66c2115aa8519587c26100 second commit new.txt | 1 + test.txt | 2 +- 2 files changed, 2 insertions(+), 1 deletion(-) 162f9174ac6bb4c5d41bfc00fcb5147e2d62b839 first commit test.txt | 1 + 1 file changed, 1 insertion(+)
Structure diagram of final submission object:
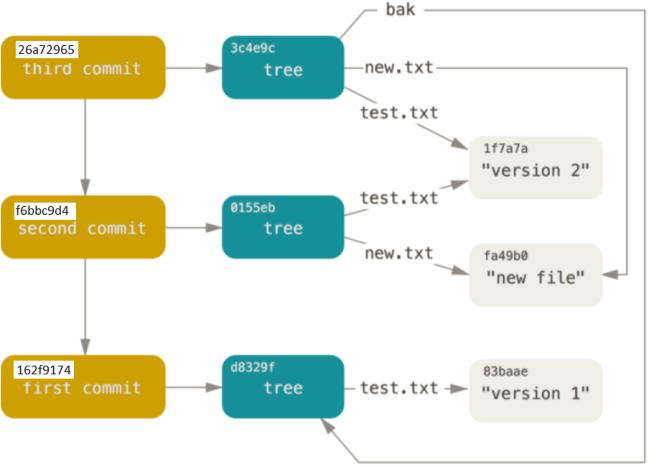
Merged commits may have more than one parent object. If a submission object has no parent object, it is called root commit, which represents the original revision of the project. Each project must have at least one root commit.
4.3 SHA-1 hash value calculation of GIT submission object
The content format of the submission object is as follows:
commit <content length><NUL>tree <tree sha> parent <parent sha> [parent <parent sha> if several parents from merges] author <author name> <author e-mail> <timestamp> <timezone> committer <author name> <author e-mail> <timestamp> <timezone> <commit message>
The first submission object is as follows:
git cat-file -p 162f9174ac6bb4c5d41bfc00fcb5147e2d62b839 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 author scorpio <642960662@qq.com> 1536497938 +0800 committer scorpio <642960662@qq.com> 1536497938 +0800 first commit
Calculate SHA-1 using openssl
echo -n "commit 165\0 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 author scorpio <642960662@qq.com> 1536497938 +0800 committer scorpio <642960662@qq.com> 1536497938 +0800 first commit" | openssl sha1
5. Git object storage
The data object in Git solves the problem of data storage, the tree object solves the problem of file name storage, and the submission object solves the problem of submission information storage.
Git objects (data objects, tree objects, and submission objects) are stored in git/objects directory.
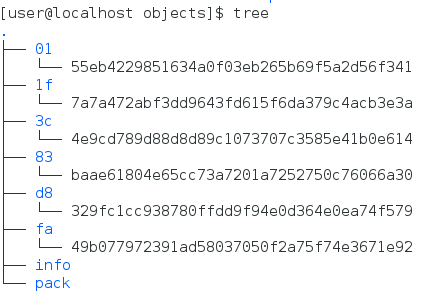
The 40 bit SHA-1 hash value of Git object is divided into two parts: the first two bits are used as the directory name and the last 38 bits are used as the object file name.
The storage path rule of Git object is: git/objects/hash[0, 1]/hash[2, 40]
Algorithm steps of Git object storage:
A. Calculate the length of content and construct header;
B. Add header in front of content and construct Git object;
C. Use sha1 algorithm to calculate the 40 bit hash code of Git object;
D. Compress Git objects using zlib's deflate algorithm;
E. Store the compressed git object in git/objects/hash[0, 2]/hash[2, 40] path;
Use Nodejs to realize the function of GIT hash object - W, that is, calculate the hash value of GIT object and store it in Git file system:
const fs = require('fs')
const crypto = require('crypto')
const zlib = require('zlib')
function gitHashObject(content, type) {
// Construct header
const header = `${type} ${Buffer.from(content).length}\0`
// Construct Git objects
const store = Buffer.concat([Buffer.from(header), Buffer.from(content)])
// Compute hash
const sha1 = crypto.createHash('sha1')
sha1.update(store)
const hash = sha1.digest('hex')
// Compress Git objects
const zlib_store = zlib.deflateSync(store)
// Store Git objects
fs.mkdirSync(`.git/objects/${hash.substring(0, 2)}`)
fs.writeFileSync(`.git/objects/${hash.substring(0, 2)}/${hash.substring(2, 40)}`, zlib_store)
console.log(hash)
}
// Call entry
gitHashObject(process.argv[2], process.argv[3])Test:
node index.js 'hello, world' blob 8c01d89ae06311834ee4b1fab2f0414d35f01102 git cat-file -p 8c01d89ae06311834ee4b1fab2f0414d35f01102 hello, world
3, Git reference
1. Introduction to Git reference
Git operation often needs to browse the complete submission history, but in order to traverse the submission history to find all relevant objects, you must remember the SHA1 hash value of the last submission object. Therefore, you need a file to save the SHA-1 value, give the file a simple name, and then use the name to replace the original SHA-1 value. Yes, I can Find the file containing SHA-1 value in git/refs directory.
find .git/refs
.git/refs .git/refs/heads .git/refs/tags
If you need to create a new reference to help record the location of the latest submission, technically, you only need to write the SHA1 hash value of the latest submission object into the reference file:
echo "524fd8729bbee740392739d22f64784ec81a9804" > .git/refs/heads/test
You can then replace the SHA-1 value with the newly created reference in the Git command.
git log --pretty=oneline test
In general, direct editing of referenced files is not recommended. If you want to update a reference, Git provides a more secure command update ref to edit the reference.
A Git branch is essentially a pointer or reference to the head of a series of submissions. If you want to create a branch on a submission object, you can do the following:
git update-ref refs/heads/newbranchname commit_id
2. HEAD reference
When git branch (branchname) is executed, Git obtains the Sha value of the latest submitted object through the HEAD file. The HEAD file is a symbolic reference. Unlike ordinary references, which contain a SHA-1 value, it is a pointer to other references and points to the current branch. You can view the contents of the HEAD file:
cat .git/HEAD
ref: refs/heads/master
If git checkout test is executed, Git will update the HEAD file.
cat .git/HEAD
ref: refs/heads/test
When git commit is executed, a submission object will be created and its parent submission field will be set with the SHA-1 value pointed to by the reference in the HEAD file.
3. Label reference
A tag object is similar to a submission object and contains a tag creator information, a date, a comment information, and a pointer. The main difference is that the tag object usually points to a submission object rather than a tree object. The tag object always points to the same submission object and adds a more friendly name to the submission object pointed to.
4. Remote reference
If a remote version library is added and pushed, Git will record the value corresponding to each branch in the last push operation and save it in the refs/remotes directory. You can add a remote version library called origin, and then push the master branch to the remote warehouse.
If you check the refs/remotes/origin/master file, you can find that the SHA-1 value corresponding to the master branch of the origin remote version library is the SHA-1 value corresponding to the local master branch during the last communication with the server.
The main difference between remote references and branches (references in the refs/heads directory) is that remote references are read-only. Although git checkout can be to a remote reference, GIT does not point the HEAD reference to the remote reference. Therefore, you can never update a remote reference through the commit command. Git manages remote references as bookmarks that record the last known location status of each branch on the remote server.
4, Git package file
The format in which git originally stored objects to disk is called the "loose" object format. However, GIT will package multiple loose objects into a binary file called "packfile" from time to time to save space and improve efficiency. Git packages objects when there are too many loose objects in the version library, or when git gc command is executed manually, or when pushing to a remote server. To see the packaging process, you can manually execute the git gc command to let git package the objects.
git gc
Counting objects: 47126, done. Delta compression using up to 4 threads. Compressing objects: 100% (16945/16945), done. Writing objects: 100% (47126/47126), done. Total 47126 (delta 29923), reused 46986 (delta 29783)