King Glory This game has a lot of heroes. Every hero has his own skin. On the official website of King Glory, every hero's skin has its own high definition poster. This article will show you how to download these skin posters using the python crawler method.
Crawler Path Exploration
First, let's look at what we're crawling for. There's a skin poster display area at the top of each hero's details page.
The following figure is: Heroes Info Page for Xishi, King's Glory website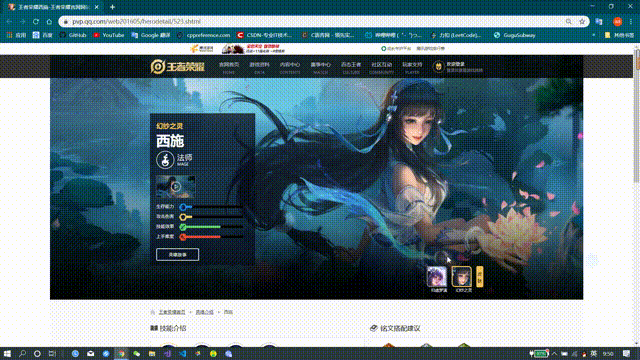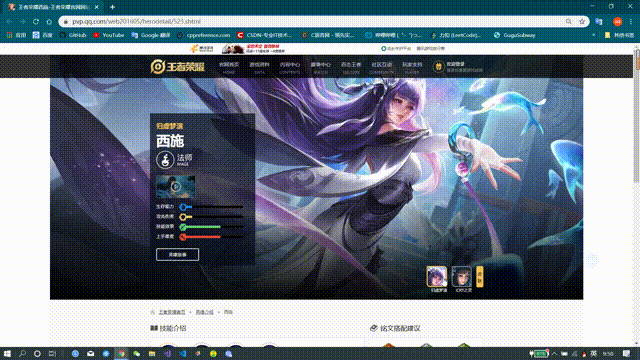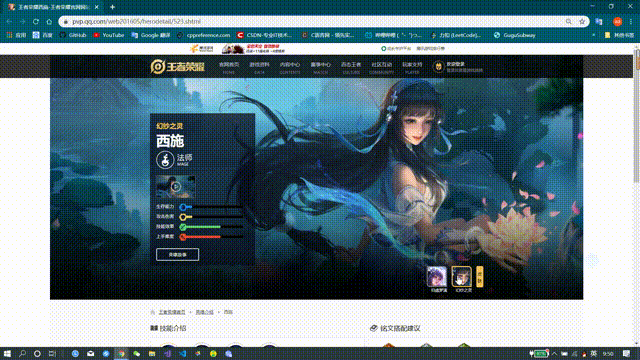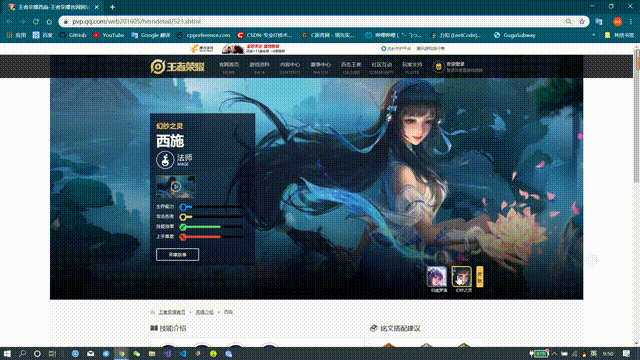
Give our crawlers a starting point
It's not difficult to find that if we want the crawler to get links to the details pages of all the heroes, we can set the crawler's starting point asRoyal Glory website - Heroes profile page From this page, you can easily get the details page of each hero.
We enter the hero details page by clicking on the hero's avatar. From the browser's checking function, you can see: The hyperlink corresponding to Pangu's avatar is as follows: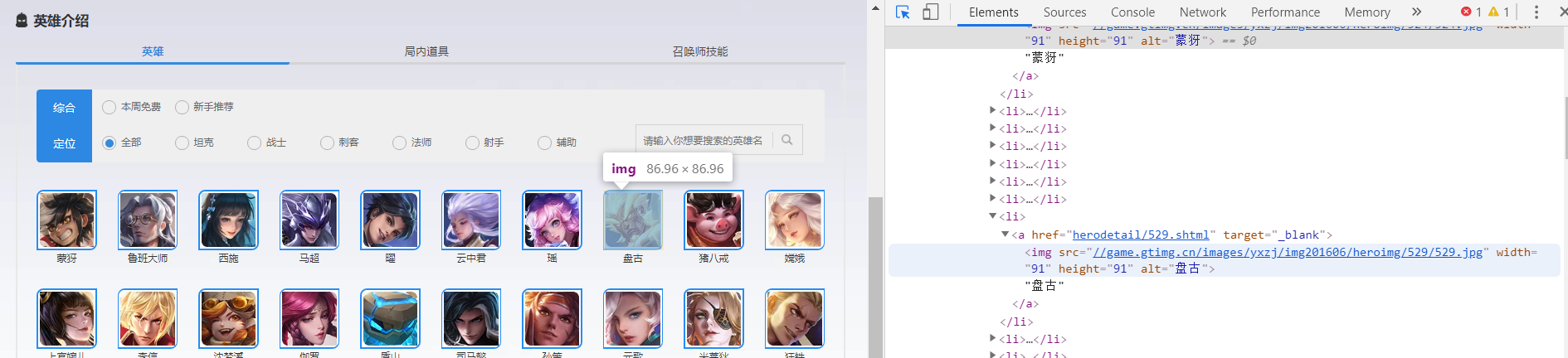
<a href="herodetail/529.shtml" target="_blank"> <img src="//game.gt img.cn/images/yxzj/img201606/heroimg/529/529.jpg" width="91" height="91" alt="Pangu"> Pangu </a>
The herf in the a tag is the web page address where the hyperlink will jump, the src in the img tag is the resource address of the avatar, accessing the resource address can save the picture, and what we are looking for is the src corresponding to the skin picture.
It is not difficult to find that the three digits at the end of the img correspond to the three digits at the end of the hyperlink, which can be interpreted as the hero id.
The following methods can be used to get the img tags of all hero faces on this page, get the hero id, and name, and then get the url of hero details page by string processing through the hero id, as follows:
import requests from bs4 import BeautifulSoup url = "https://pvp.qq.com/web201605/herolist.shtml" resp = requests.get(url) resp.encoding = "GBK" soup = BeautifulSoup(resp.text,'lxml') alldiv = soup.find_all('img', width = '91') for i in alldiv: print(i) #Output: #<img alt="Jun in the Cloud" height="91" src="//game.gtimg.cn/images/yxzj/img201606/heroimg/506/506.jpg" width="91"/> #<img alt="Yao" height="91" src="//game.gtimg.cn/images/yxzj/img201606/heroimg/505/505.jpg" width="91"/> #.......................................Many, many lines name = i['alt'] print(name,end=" ") #Output: #Jun Yao Pan Pig, Shang Guan Waner Li Xin, Shenmeng River Galogen Mountains Sima Sun Che Yuan Ge Miledy Iron Game Star Pei Tiger Yang Yuhuan Gong Dai, a hermit daughter of the Ming Dynas*Li Yuanfang, Zhang Fei Liu, the reserve cow Monkey, Arthur Monkey, Right Jingna Kelu, does not know the fire dance Zhang Lianghua, Mulan Mausoleum King Hanjun, Liu Bang, Jiangzi Yalua Cheng bites Jin Angela, Cicada, Guan Feather, Wu Zetian Feather Damo Jema Keluo Li, White House, Ben Wu Ren Ji Ji Marco Polo, Vicao Cao Zheng Ji Zhou Yulu Biyue BaiyueZhong Wuyan A Yigao has moved away from Sun Shang Xiangxue's political office, No. 7, Zhou Luban, Liu Zenzhuang. Zhao Yun Xiao Qian is quite good. _id = i['src'].split('.')[0][-3:] url = "https://pvp.qq.com/web201605/herodetail/%s.shtml"%_id print(url) #output #https://pvp.qq.com/web201605/herodetail/506.shtml #https://pvp.qq.com/web201605/herodetail/505.shtml #https://pvp.qq.com/web201605/herodetail/529.shtml #https://pvp.qq.com/web201605/herodetail/511.shtml #https://pvp.qq.com/web201605/herodetail/515.shtml #.......................................Many, many lines
So we can get the URLs of the hero details pages for all the heroes.Next, explore how to find skin names and SRCs for skin posters from the hero details page:
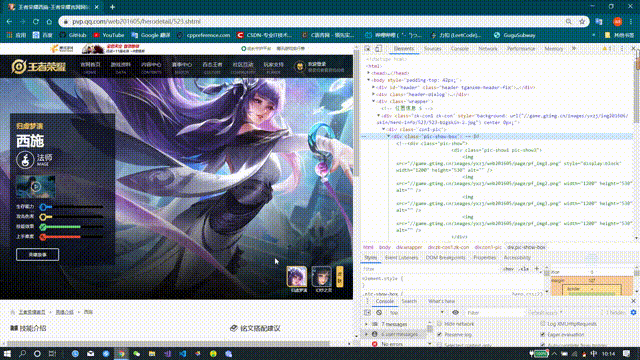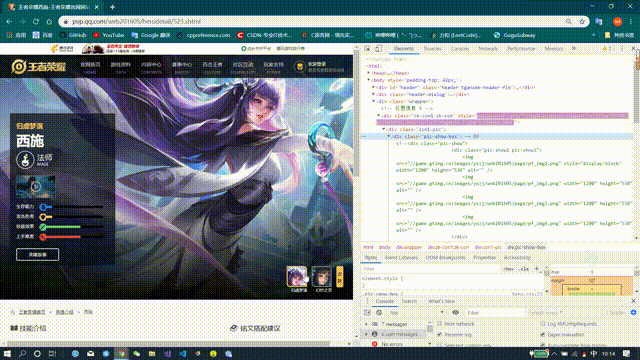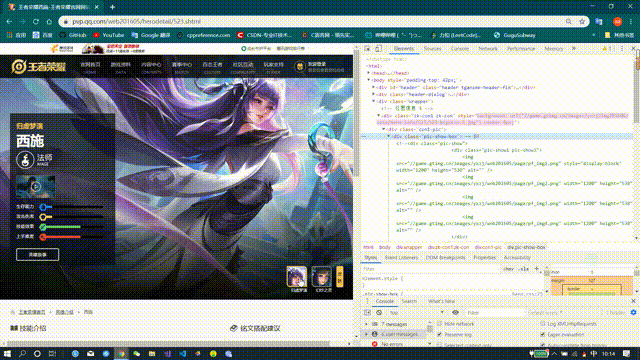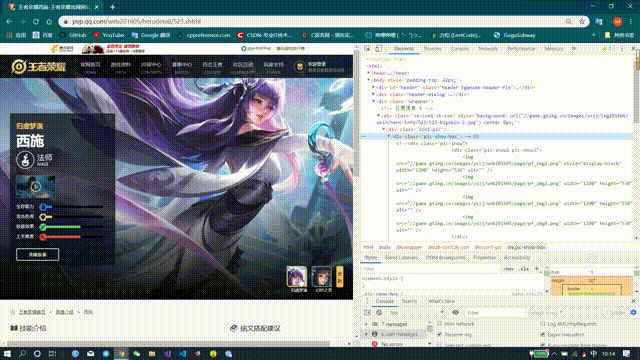
Through the browser's checking function, it was found that the resource links in the backgrounds in the div tag slightly changed when the background image was switched again

It's easy to know that this url is the src of the skin poster we're looking for. Don't believe try opening it:
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/523/523-bigskin-1.jpg
http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/523/523-bigskin-2.jpg
Look at two pages and you'll see the rules for this link: http://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/523/523-bigskin-1.jpg
The first two 523 are the hero numbers, and the second one is the corresponding skin numbers (see how many skins the hero has, the numbers are 1,2,3,4,5,6,7 in turn...n).
Then we tried to find the number and name of the hero's skin and found this label in the inspection tool.We can get the skin name from this tag, and of course the number of names will tell the number of skin (n can exit the number).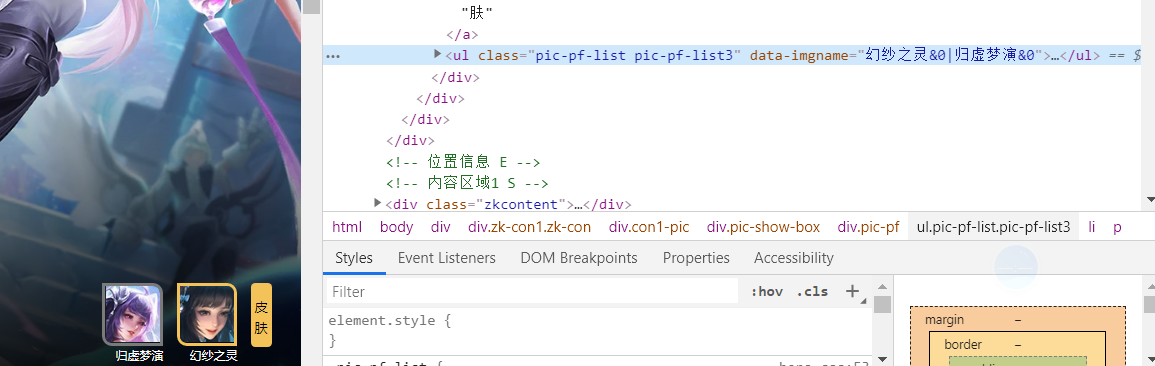
The methods are as follows:
import requests from bs4 import BeautifulSoup url = "https://pvp.qq.com/web201605/herolist.shtml" resp = requests.get(url) resp.encoding = "gbk" soup = BeautifulSoup(resp.text,'lxml') alldiv = soup.find_all('img', width = '91') for i in alldiv: _id = i['src'].split('.')[-2][-3:] url = "https://pvp.qq.com/web201605/herodetail/%s.shtml"%_id resp1 = requests.get(url) resp1.encoding ='gbk' soup1 = BeautifulSoup(resp1.text, 'lxml') ul = soup1.find('ul',class_="pic-pf-list pic-pf-list3") names = ul['data-imgname'] print("%s"%names) # Output (this is the result of the commented output statement below): #Wing of the Cloud|Horus's Eye # #Deer Ling Shouxin&0|Sen&0 # #God of dawn &0|God of creation&0 # #Worry-free fighters &0|have a surplus every year &0 # #Cold Moon Princess&0|Dew Shadow&0 #...................................................Many, many lines namelist = [] for name in names.split('|'): namelist.append(name.split('&')[0]) print(namelist) print() #Output (this is the result of commenting the output statement above) #['Wing of the Flowing Cloud','Eye of Horus'] # #['Deer Mind Watches','Sen'] # #['Dawn god','Creation god'] # #['Samurai without worry','Return every year'] # #['Cold Moon Princess','Dew Shadow'] # #['Magic Pen','Xiu Zhu Mok','Liang Zhu']
Then code the skin link to match the hero name and skin name
Code parsing
First import the module you want to use
import requests from bs4 import BeautifulSoup
Write a GetSoup function to parse web pages.
Note: There is a request header information set here. If you do not set the request header information, it is equivalent to saying to the server, "Hey! I am a crawler, would you like to give me the data?"
For many servers, crawlers are actually rejected, because crawlers generally request a large amount of data, which puts pressure on the server, so the server is more likely to serve real people.So we set a request head for our crawler to lie to the server and say, "Hey?What browser am I?Send me the data."
Setting up a user-agent for a normal website is enough to fool around, but for some sites it's better to disguise it (case-by-case analysis), just find a copy of the past in the browser's developer tools
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ' 'Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5958.400 SLBrowser/10.0.3533.400'} def GetSoup(url): resp = requests.get(url, headers=headers) resp.encoding = 'gbk' soup = BeautifulSoup(resp.text, 'lxml') return soup
Follow the steps above to visit each hero's details page one by one to get the hero's name - skin name and skin picture
url='https://pvp.qq.com/web201605/herolist.shtml' soup = GetSoup(url) #Find <img>tags for all hero avatars via soup. alldiv = soup.find_all('img', width='91') for div in alldiv: # Get hero Id, hero name from information in <img>tag # Get id _id = div['src'][46:49] # Get hero_name hero_name = div['alt'] # Get the name of each hero's skin and download link for skin pictures # Get skin-name url = 'https://pvp.qq.com/web201605/herodetail/%s.shtml' % _id soup = GetSoup(url) alldiv = soup.find('ul', class_='pic-pf-list pic-pf-list3') names = str(alldiv['data-imgname']).split('|') for i in range(len(names)): names[i]=names[i].split('&')[0] for i in range(len(names)): url5 = 'https://game.gtimg.cn/images/yxzj/img201606/heroimg/%s/%s-mobileskin-%s.jpg' % (_id, _id, i+1) resp5= requests.get(url5) print('Downloading%s-%s.jpg......... ' % (hero_name, names[i])) f = open('C:/Users/TTODS/Desktop/Glory of Kings/Heroic skin/%s-%s.jpg' % (hero_name, names[i]), 'wb') f.write(resp5.content)
Crawl results:
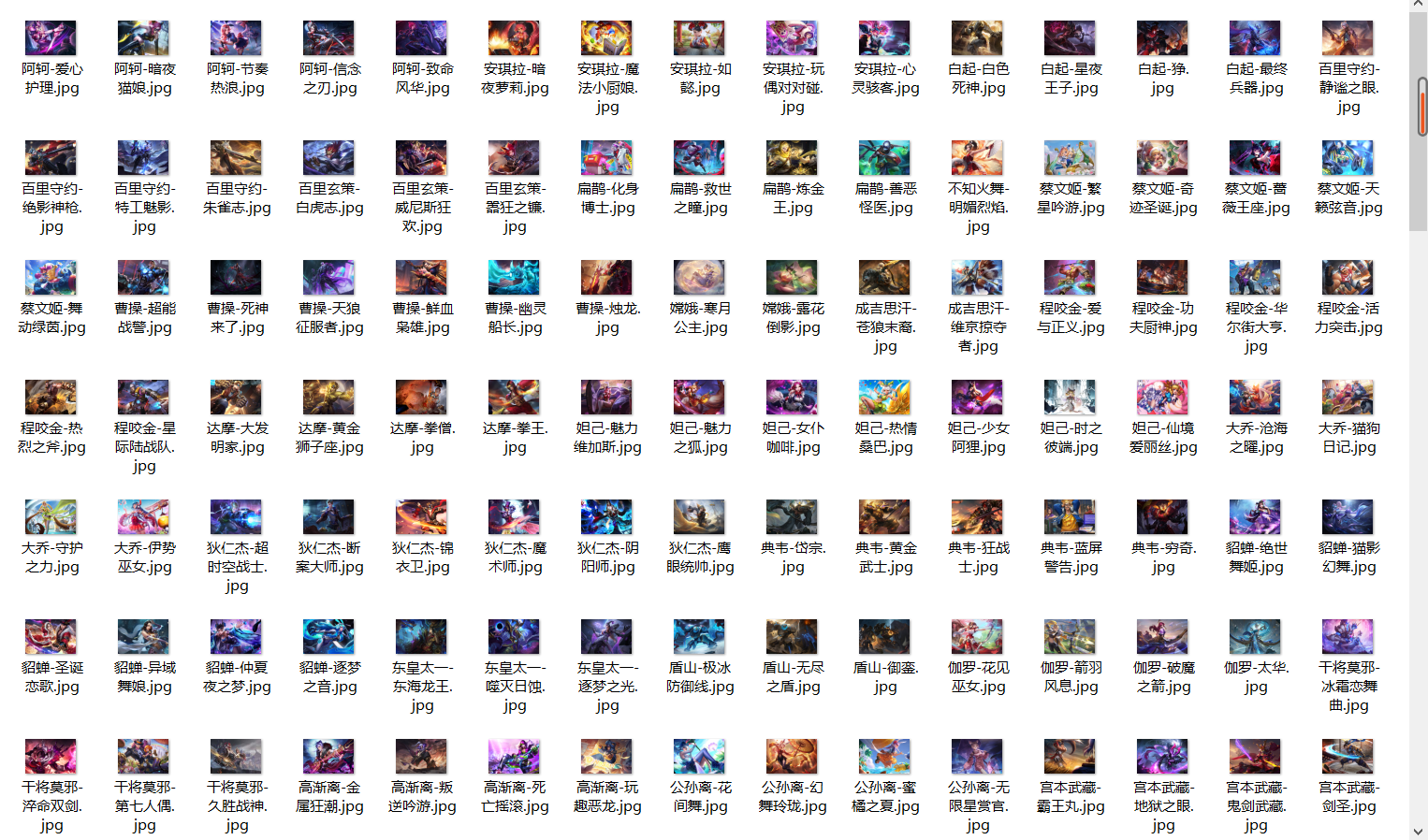
Similarly, we can crawl the hero portraits, equipment pictures, hero skill descriptions and other information on the Royal Glory website. I will not carefully write the process here. I will share the source code below:

