The so-called people gather in groups and things divide in groups. People like to be with people who have the same personality and hobbies.
Commonly known as: get along! Pretty boy, I like you very much~

A and B were childhood sweethearts. A met C through B and found that their interests and hobbies were surprisingly consistent. The three got together and became an inseparable small group. The formation of this small group is a bottom-up iterative process.
Among 200 people, there may be 10 small groups, which may take months to form.
This process of "finding friends" is the topic we want to talk about today: clustering algorithm.
clustering
Clustering algorithm: it is a process of quickly dividing a group of samples into several categories through bottom-up iteration (distance comparison) with distance as a feature.
A more rigorous and professional statement is:
Classify similar objects into the same cluster, so that the similarity of data objects in the same cluster is as large as possible, and the difference of data objects not in the same cluster is as large as possible. That is, after clustering, the data of the same class shall be gathered together as much as possible, and different data shall be separated as much as possible.

Obviously, clustering is an unsupervised learning.
In order to prevent novices from not understanding, here is a brief explanation:
-
For labeled data, we conduct supervised learning. The common classification task is supervised learning;
-
For unlabeled data, we hope to find the potential information in unlabeled data, which is unsupervised learning.
Clustering is a very common and easy-to-use algorithm.
for instance:
I'll give you 10000 pictures of big men who pick their feet and 10000 pictures of cute girls. These 20000 pictures are mixed together.

Well, now I want to throw away all the pictures of cute girls, because I only love picky guys!
In this case, clustering algorithm can be used.
This is a relatively easy to understand example of a more professional demand scenario, such as face recognition.
Face recognition requires a large amount of face data. In the data preparation stage, clustering algorithm can be used to assist in labeling + cleaning data.

This is a conventional data mining method.
I sorted out some common clustering algorithms:
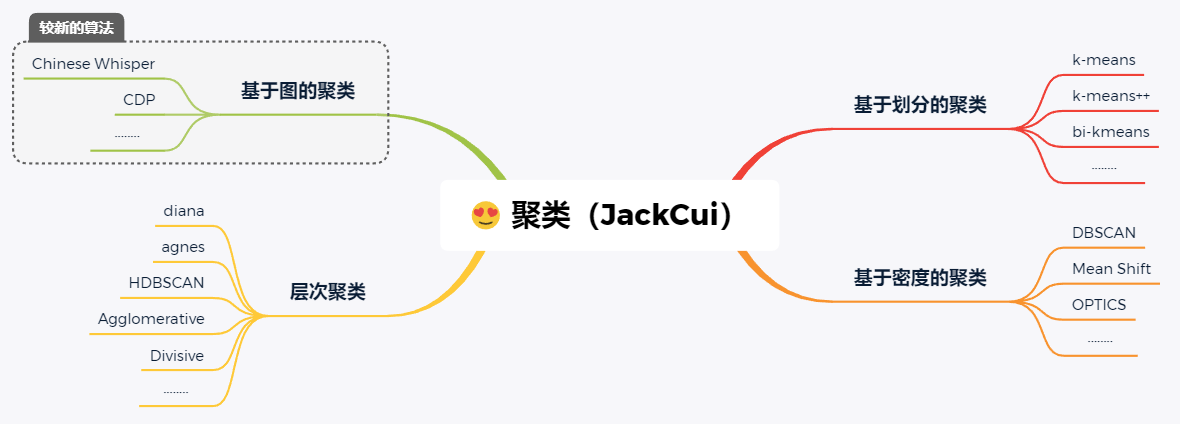
As mentioned earlier, the clustering algorithm classifies the data according to the similarity between samples.
The measurement methods of similarity can be roughly divided into:
-
Distance similarity measure
-
Density similarity measure
-
Connectivity similarity measure
Different types of clustering algorithms adopt different similarity measurement methods between samples.
There are many clustering algorithms, which cannot be described in detail in an article. Today I will take you to learn from the most basic Kmeans.
K-Means
K-Means is a very classic clustering algorithm. Although it is old, it is very practical.
Let's put it this way. I'm doing projects now. I have some small functions and occasionally use K-Means.
K-Means is K-Means, which is defined as follows:
For a given sample set, the sample set is divided into K clusters according to the distance between samples. Let the points in the cluster be connected as closely as possible, and let the distance between clusters be as large as possible
The steps of K-Means clustering are as follows:
-
Randomly select k center points to represent K categories;
-
Calculate the Euclidean distance between N sample points and K center points;
-
Divide each sample point into the nearest (the smallest Euclidean distance) center point category - iteration 1;
-
Calculate the mean value of sample points in each category, get k mean values, and take K mean values as a new center point - iteration 2;
-
Repeat steps 2, 3 and 4;
-
After meeting the convergence conditions, K central points after convergence are obtained (the central point does not change).
The Euclidean distance can be used for K-Means clustering. The Euclidean distance is very simple. The two-dimensional plane is the distance formula of two points. In multi-dimensional space, assuming that the two samples are a(x1,x2,x3,x4...xn) and b(y1,y2,y3,y4...yn), the calculation formula of the Euclidean distance between them is:
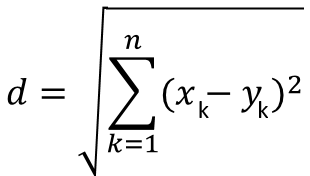
It can be well illustrated by the following figure:
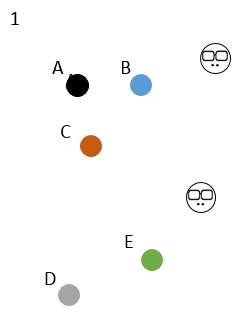
There are 5 samples of ABCDE. At the beginning, select the two initial center points on the right, K=2. Everyone has different colors, and no one is satisfied with anyone;
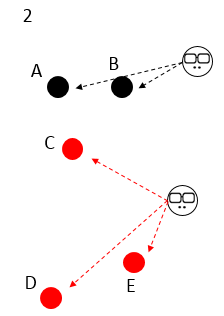
Compare the distance between the five samples and the two initial center points respectively, and select the nearest side. At this time, the five samples are divided into red and black groups;
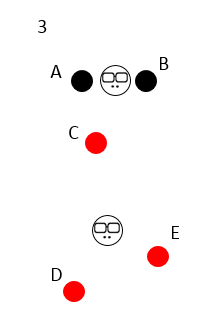
Then start to change the boss. The two initial center points disappear, and two new center points appear at the respective centers of the two classes. The sum of the distances between the two new center points and the samples in the class must be the smallest;
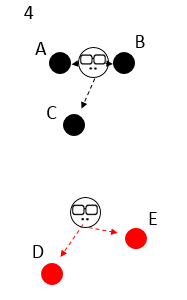
The new boss appears, and the classification is different. C begins to rebel and depends on the new boss because he is closer to the new boss;
The new boss disappears and the new boss appears. He finds that the classification has not changed and the gang is stable, so he converges.
Simply implement it with code:
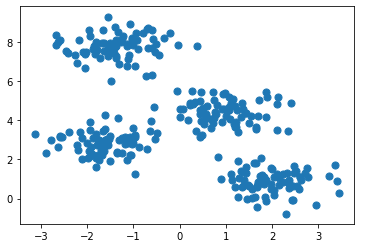
import matplotlib.pyplot as plt import numpy as np from sklearn.datasets.samples_generator import make_blobs X, y_true = make_blobs(n_samples=300, centers=4, cluster_std=0.60, random_state=0) plt.scatter(X[:, 0], X[:, 1], s=50) plt.show()
Generate some random points.
Then K-Means is used for clustering.
from sklearn.cluster import KMeans
"""
KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300,
tol=0.0001, precompute_distances='auto', verbose=0,
random_state=None, copy_x=True, n_jobs=1, algorithm='auto')
Parameters:
n_clusters: Number of clusters
max_iter: Maximum iterated algebra
n_init: The number of times the algorithm is run with different centroid initialization values
init: Method of initializing centroid
precompute_distances: Pre calculated distance
tol: On the parameters of convergence
n_jobs: Number of processes calculated
random_state: Random seed
copy_x: Modify original data
algorithm: "auto", "full" or "elkan"
"full"It's our traditional K-Means Algorithm,
"elkan"elkan K-Means Algorithm. default
"auto"The selection will be based on whether the data value is sparse full"And“ elkan",Dense selection "elkan",Otherwise it will be " full"
Attributes:
cluster_centers_: Centroid coordinates
Labels_: Classification of each point
inertia_: The sum of the distances from each point to the centroid of its cluster.
"""
m_kmeans = KMeans(n_clusters=4)
from sklearn import metrics
def draw(m_kmeans,X,y_pred,n_clusters):
centers = m_kmeans.cluster_centers_
print(centers)
plt.scatter(X[:, 0], X[:, 1], c=y_pred, s=50, cmap='viridis')
#The center point (center of mass) is marked in red
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.5)
print("Calinski-Harabasz score: %lf"%metrics.calinski_harabasz_score(X, y_pred) )
plt.title("K-Means (clusters = %d)"%n_clusters,fontsize=20)
plt.show()
m_kmeans.fit(X)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=4, n_init=10, n_jobs=None, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
y_pred = m_kmeans.predict(X)
draw(m_kmeans,X,y_pred,4)
Clustering operation results:
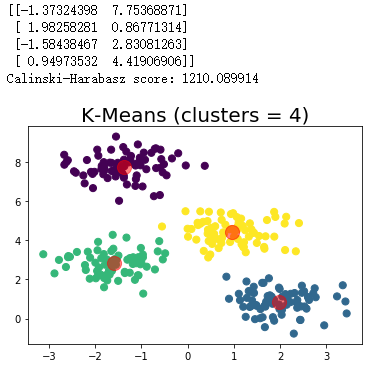
summary
K-Means clustering is the simplest and classic clustering algorithm. Because the number of clustering centers, i.e. K, needs to be set in advance, the scenarios that can be used are also relatively limited.
For example, K-Means clustering algorithm can be used to segment the background before and after a simple expression package image, and extract the foreground of a text image.
The distance measurement method that K-Means clustering can use is not only European distance, but also Manhattan distance and Mahalanobis distance. The idea is the same, but the measurement formulas are different.
There are many clustering algorithms. Let me talk slowly.
Finally, I'll give you a copy of the data structure question brushing notes to help me get offer s from first-line big companies such as BAT. It was written by a great God of Google. It is very useful for students who have weak algorithms or need to improve (mention Code: m19c):
https://pan.baidu.com/s/1txDItPwDrnG8mOloOFbGaQ
For a more detailed algorithm learning route, including learning methods and materials of algorithm, mathematics, programming language, competition, etc., you can see this content:
https://mp.weixin.qq.com/s/oQHXG2pdJXLQpeBsNQkPDA
If you want to see me explain other interesting and practical clustering algorithms, such as CDP, you might as well have a three company to give me some motivation.
I'm Jack. I'll see you next time.