The previous article introduced Hadoop distributed configuration , but designed to be highly available, this time use zookeeper to configure Hadoop highly available.
1. Environmental preparation
1) modify IP
2) modify the mapping of host name and host name and IP address
3) turn off the firewall
4) ssh password free login
5) create hadoop users and user groups
6) install and update the installation source, JDK, configuration environment variables, etc
2. Server planning
| Node1 |
Node2 |
Node3 |
| NameNode |
NameNode |
|
| JournalNode |
JournalNode |
JournalNode |
| DataNode |
DataNode |
DataNode |
| ZK |
ZK |
ZK |
| ResourceManager |
|
ResourceManager |
| NodeManager |
NodeManager |
NodeManager |
3. Configure Zookeeper cluster
Refer to my previous article Zookeeper installation and configuration instructions
4. Install Hadoop
1) official download address: http://hadoop.apache.org/
2) decompress Hadoop 2.7.2 to / usr / local / Hadoop 2.7
3) modify the group and owner of hadoop 2.7 to hadoop
chown -R hadoop:hadoop /usr/local/hadoop2.7
4) configure Hadoop? Home
vim /etc/profile
#HADOOP_HOME export HADOOP_HOME=/usr/local/hadoop2.7 export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
5. Configure Hadoop cluster high availability
5.1 configure HDFS cluster
hadoop-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_221
hadoop-site.xml
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- Fully distributed cluster name --> <property> <name>dfs.nameservices</name> <value>hadoopCluster</value> </property> <!-- Cluster NameNode What are the nodes --> <property> <name>dfs.ha.namenodes.hadoopCluster</name> <value>nn1,nn2</value> </property> <!-- nn1 Of RPC Mailing address --> <property> <name>dfs.namenode.rpc-address.hadoopCluster.nn1</name> <value>node1:9000</value> </property> <!-- nn2 Of RPC Mailing address --> <property> <name>dfs.namenode.rpc-address.hadoopCluster.nn2</name> <value>node2:9000</value> </property> <!-- nn1 Of http Mailing address --> <property> <name>dfs.namenode.http-address.hadoopCluster.nn1</name> <value>node1:50070</value> </property> <!-- nn2 Of http Mailing address --> <property> <name>dfs.namenode.http-address.hadoopCluster.nn2</name> <value>node2:50070</value> </property> <!-- Appoint NameNode Metadata in JournalNode Storage location on --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node1:8485;node2:8485;node3:8485/hadoopCluster</value> </property> <!-- Configure the isolation mechanism, that is, only one server can respond to the external at the same time --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- When using isolation mechanism ssh Keyless login--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/home/hadoop/.ssh/id_rsa</value> </property> <!-- statement journalnode Server storage directory--> <property> <name>dfs.journalnode.edits.dir</name> <value>/data_disk/hadoop/jn</value> </property> <!-- Turn off permission check--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property> <!-- Access agent class: client,hadoopCluster,active Configuration failure auto switch implementation mode--> <property> <name>dfs.client.failover.proxy.provider.hadoopCluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:///data_disk/hadoop/name</value> <description>In order to ensure the security of metadata, multiple directories are generally configured</description> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:///data_disk/hadoop/data</value> <description>datanode Data storage directory for</description> </property> <property> <name>dfs.replication</name> <value>3</value> <description>HDFS Number of replica stores for blocks of,The default is 3.</description> </property> </configuration>
core-site.xml
<configuration> <!-- Appoint HDFS in NameNode Address --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoopCluster</value> </property> <!-- Appoint Hadoop Storage directory where files are generated at run time --> <property> <name>hadoop.tmp.dir</name> <value>file:///data_disk/hadoop/tmp</value> </property> </configuration>
Start hadoop cluster
(1)In each JournalNode On node, enter the following command to start journalnode service sbin/hadoop-daemon.sh start journalnode (2)stay[nn1]On, format it and start bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode (3)stay[nn2]Synchronization nn1 Metadata information for bin/hdfs namenode -bootstrapStandby (4)start-up[nn2] sbin/hadoop-daemon.sh start namenode (5)stay[nn1]On, start all datanode sbin/hadoop-daemons.sh start datanode (6)take[nn1]Switch to Active bin/hdfs haadmin -transitionToActive nn1 (7)Check whether Active bin/hdfs haadmin -getServiceState nn1
Open the browser to view the status of namenode
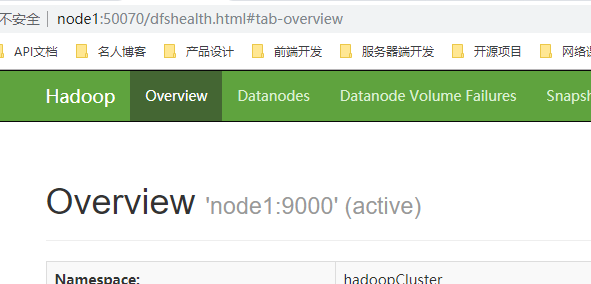
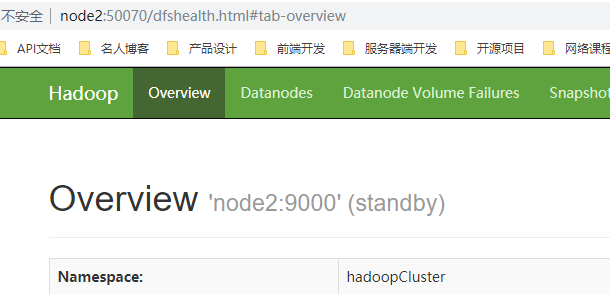
5.2 configure HDFS automatic failover
Add in hdfs-site.xml
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property>
Add in the core-site.xml file
<property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property>
5.2.1 boot
(1)Close all HDFS Services: sbin/stop-dfs.sh (2)start-up Zookeeper Cluster: bin/zkServer.sh start (3)Initialization HA stay Zookeeper Status: bin/hdfs zkfc -formatZK (4)start-up HDFS Services: sbin/start-dfs.sh (5)In each NameNode Start on node DFSZK Failover Controller,Which machine starts first, which machine's NameNode Namely Active NameNode sbin/hadoop-daemon.sh start zkfc
5.2.2 verification
(1)take Active NameNode process kill kill -9 namenode Process id (2)take Active NameNode Machine disconnected from network service network stop
If nn2 does not become active after kill nn1, there may be the following reasons
(1) ssh password free login is not configured properly
(2) foster program is not found, which makes fence impossible. Refer to Bowen
5.3 yarn-ha configuration
yarn-site.xml
<?xml version="1.0"?> <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!--Enable resourcemanager ha--> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!--Statement two resourcemanager Address--> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>node1</value> </property> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>node3</value> </property> <!--Appoint zookeeper Address of the cluster--> <property> <name>yarn.resourcemanager.zk-address</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <!--Enable automatic recovery--> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!--Appoint resourcemanager The status information of is stored in zookeeper colony--> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> </configuration>
5.3.1 start HDFS
(1)In each JournalNode On node, enter the following command to start journalnode Services: sbin/hadoop-daemon.sh start journalnode (2)stay[nn1]On, format it and start: bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode (3)stay[nn2]Synchronization nn1 Metadata information for: bin/hdfs namenode -bootstrapStandby (4)start-up[nn2]: sbin/hadoop-daemon.sh start namenode (5)Start all DataNode sbin/hadoop-daemons.sh start datanode (6)take[nn1]Switch to Active bin/hdfs haadmin -transitionToActive nn1
5.3.2 start YARN
(1)stay node1 Implementation: sbin/start-yarn.sh (2)stay node3 Implementation: sbin/yarn-daemon.sh start resourcemanager (3)View service status bin/yarn rmadmin -getServiceState rm1