
Kafka was originally developed by Linkedin company. It is a distributed, partition and multi replica distributed message system based on zookeeper coordination. Its biggest feature is that it can process a large amount of data in real time to meet various demand scenarios: such as hadoop based batch processing system, low latency real-time system Storm/Spark streaming engine, web/nginx logs, access logs, message services, etc. are written in scala language. Linkedin contributed to the Apache foundation and became a top open source project in 2010.
Usage scenario of Kafka
- log collection: a company can use Kafka to collect logs of various services and open them to various consumer s in the form of unified interface services, such as hadoop, Hbase, Solr, etc.
- Message system: decoupling producers and consumers, caching messages, etc.
- User activity tracking: Kafka is often used to record various activities of web users or app users, such as web browsing, search, click and other activities. These activity information is published by various servers to Kafka's topic, and then subscribers subscribe to these topics for real-time monitoring and analysis, or load them into hadoop and data warehouse for offline analysis and mining.
- Operational indicators: Kafka is also often used to record operational monitoring data. It includes collecting data of various distributed applications and producing centralized feedback of various operations, such as alarm and report.
Kafka basic concept
Kafka is a distributed and partitioned message service (officially called commit log). It provides the functions that a message system should have, but it does have a unique design. It can be said that Kafka borrowed the idea of JMS specification, but did not fully follow JMS specification.
First, let's take a look at the basic message related terms:

Therefore, from a higher level, the producer sends messages to the Kafka cluster through the network, and then consumer s consume them, as shown in the following figure:
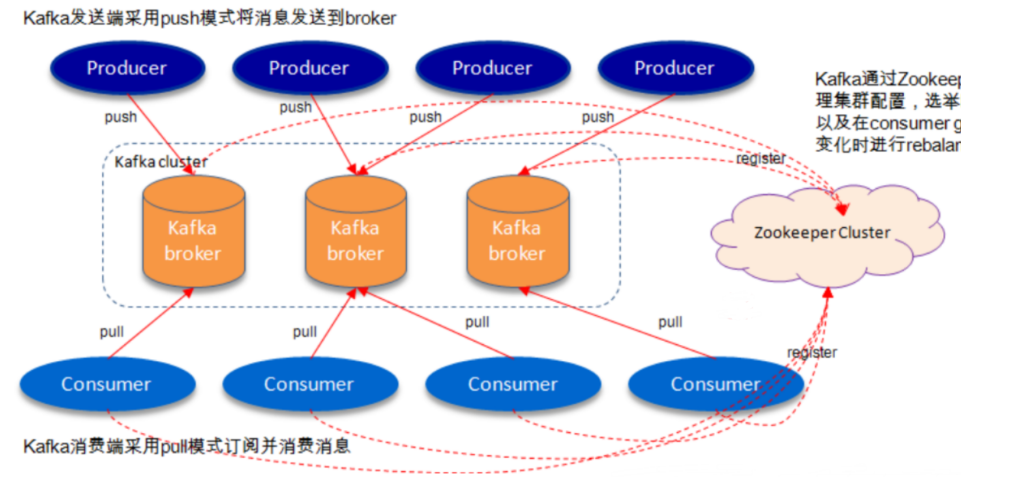
The communication between brokers and consumers is completed by TCP protocol.
Topic and message Log
Let's first deeply understand Kafka's high-level abstract concept Topic.
It can be understood that Topic is the name of a category, and similar messages are sent under the same Topic. For each Topic, there can be multiple partition log files:
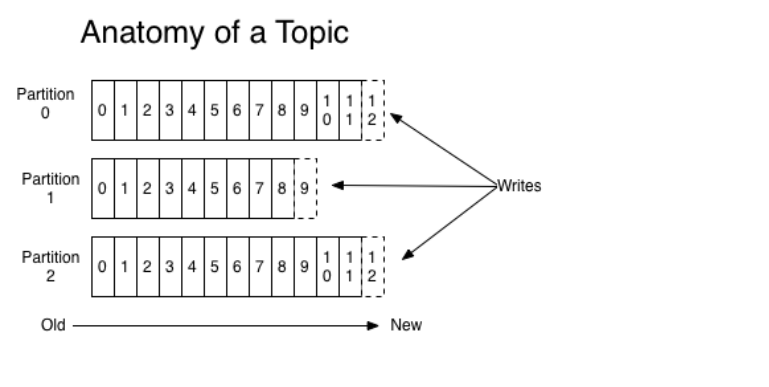
Partition is an ordered sequence of messages, which are added to a file called commit log in order. Messages in each partition have a unique number called offset, which is used to uniquely identify messages in a partition.
Tip: each partition corresponds to a commit log file. The offsets of messages in a partition are unique, but the offsets of messages in different partitions may be the same.
Topic, Partition and Broker can be understood in this way
A topic represents a logical business data set. For example, put different topics according to the data operation messages of different tables in the database, put order related operation messages into order topic, and user related operation messages into user topic. For large websites, the back-end data is massive, and the order messages are likely to be very huge, For example, there are hundreds of gigabytes or even terabytes. If you put so much data on one machine, there will be a capacity limitation problem. Then you can divide multiple partitions within topic to store data in pieces. Different partitions can be located on different machines, and each machine runs a Kafka process Broker.
The kafka cluster maintains all messages generated by the producer within the configured time range, regardless of whether these messages are consumed or not. For example, the log retention time is set to 2 days. kafka will maintain all messages produced in the last two days, and the messages two days ago will be discarded. The performance of kafka has nothing to do with the amount of data retained, so saving a large amount of data (log information) will not have any impact.
Each consumer works based on its own consumption progress (offset) in the commit log. In kafka, the consumption offset is maintained by the consumer itself; Generally, we consume the messages in the commit log one by one in order. Of course, I can repeatedly consume some messages or skip some messages by specifying offset. This means that the impact of consumers in kafka on the cluster is very small. Adding or reducing one consumer has no impact on the cluster or other consumers, because each consumer maintains its own offset. Therefore, kafka cluster is stateless, and its performance will not be affected by the number of consumers. kafka also records a lot of key information in zookeeper to ensure its statelessness, which is very convenient for horizontal expansion.
Why partition storage of data under Topic?
- The commit log file is limited by the size of the file system on the machine. After partitioning, theoretically, a topic can process any amount of data.
- To improve parallelism
Distributed Distribution
The partitions of log are distributed among different brokers in the kafka cluster. Each broker can request to back up the data on the partitions of other brokers. kafka cluster supports configuring the number of backups for a partition.
For each partition, one broker acts as a "leader" and 0 or more other brokers act as "followers". Leaders handle all read-write requests for this partition, while followers passively copy the results of leaders. If this leader fails, one of the followers will automatically become a new leader.
Producers
The producer sends the message to the topic and is responsible for selecting which partition of the topic to send the message to. Through round robin does simple load balancing. It can also be distinguished according to a keyword in the message. Usually the second method is used more.
Consumers
There are two traditional messaging modes: queue and publish subscribe
- queue mode: multiple consumers read data from the server, and the message will only reach one consumer.
- Publish subscribe mode: messages will be broadcast to all consumer s.
Based on these two patterns, Kafka provides an abstract concept of consumer: consumer group.
- queue mode: all consumers are in the same consumer group.
- Publish subscribe mode: all consumers have their own unique consumer group.
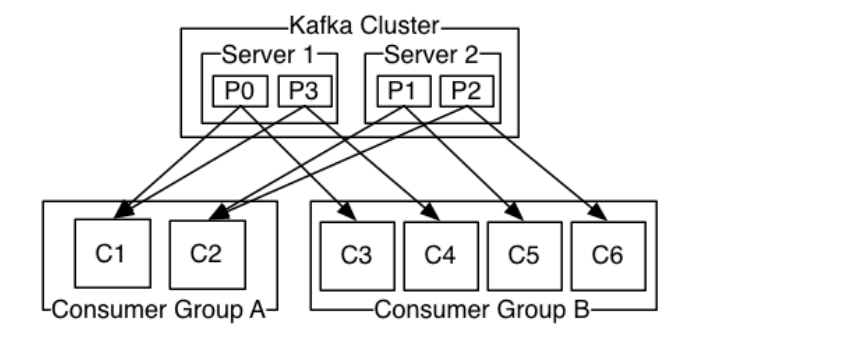
The above figure shows that the kafka cluster consists of two broker s, with a total of four partitions (p0-p3). This cluster consists of two consumer groups. A has two consumer instances and B has four.
Usually, a topic will have several consumer groups, and each consumer group is a logical subscriber. Each consumer group is composed of multiple consumer instance s to achieve the functions of scalability and disaster tolerance.
Consumption order
Kafka has stronger order guarantee than traditional message system.
A partition has only one consumer instance in a consumer group at the same time, so as to ensure the order. The number of consumer instances in a consumer group cannot be more than the number of partitions in a Topic. Otherwise, the extra consumers will not consume messages.
Kafka only guarantees the local order of message consumption within the scope of partition, and cannot guarantee the total order of consumption in multiple partitions in the same topic.
If there is a need to ensure the overall consumption order, we can set the number of partition s of topic to 1 and the number of consumer instance s in the consumer group to 1.
At a higher level, Kafka provides the following guarantees:
Messages sent to a Topic will be added to the commit log in the order they are sent. This means that if the messages M1 and M2 are sent by the same producer and M1 is sent earlier than m2, the offset of M1 will be smaller than that of commit 2 in the commit log. A consumer can consume messages in the order of sending in the commit log.
If the backup factor of a topic is set to N, Kafka can tolerate the failure of N-1 servers, and the messages stored in the commit log will not be lost.
Construction and use of kafka cluster
Environmental preparation before installation
Since Kafka is developed in Scala and runs on the JVM, you need to install JDK before installing Kafka.
yum install java‐1.8.0‐openjdk* ‐y
kafka depends on zookeeper, so you need to install zookeeper first
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz tar ‐zxvf zookeeper‐3.4.12.tar.gz cd zookeeper‐3.4.12 cp conf/zoo_sample.cfg conf/zoo.cfg # Start zookeeper bin/zkServer.sh start bin/zkCli.sh ls / #View related nodes of zk's root directory
Step 1: download the installation package
Download version 2.2.0 release and unzip it:
wget https://archive.apache.org/dist/kafka/1.1.0/kafka_2.11-1.1.0.tgz tar ‐xzf kafka_2.11‐1.1.0.tgz cd kafka_2.11‐1.1.0
Step 2: start the service
Now start the kafka service:
Startup script syntax: kafka server start.sh [ daemon] server. As you can see from properties, server The configuration path of properties is a mandatory parameter, Daemon means that the background process is running, otherwise the service will be stopped after the ssh client exits. (note that the ip address associated with the linux host name will be used when starting kafka, so you need to configure the host name and the ip mapping of linux into the local host, using vim /etc/hosts)
bin/kafka-server-start.sh -daemon config/server.properties # Let's go to the zookeeper directory and check the zookeeper directory tree through the zookeeper client bin/zkCli.sh ls / #View the root directory kafka related nodes of zk ls /brokers/ids #View kafka node
| Property | Default | Description |
| broker.id | 0 | Each broker can be identified by a unique non negative integer id; This id can be used as the "name" of the broker. You can choose any number you like as the id, as long as the id is unique. |
| log.dirs | /tmp/kafka-logs | kafka the path where the data is stored. This path is not unique, it can be multiple, and the paths only need to be separated by commas; Whenever a new partition is created, the path containing the least partitions will be selected. |
| listeners | 9092 | The port on which the server accepts client connections |
| zookeeper.connect | localhost:2181 | The format of the zookeeper connection string is: hostname:port, where hostname and port are the host and port of a node in the zookeeper cluster respectively; If zookeeper is a cluster, the connection mode is hostname1:port1, hostname2:port2, hostname3:port3 |
| log.retention.hours | 168 | The time saved before each log file is deleted. The default data saving time is the same for all topic s. |
| min.insync.replicas | 1 | When producer sets acks to - 1, min.insync Replicas specifies the minimum number of replicas (it must be confirmed that the write data of each replica is successful). If this number is not reached, the producer will generate an exception when sending a message |
| delete.topic.enable | false | Allow deletion of topics |
Step 3: create a theme
Now let's create a topic named "test". This topic has only one partition, and the backup factor is also set to 1:
bin/kafka‐topics.sh ‐‐create ‐‐zookeeper 192.168.0.60:2181 ‐‐replication-factor 1 ‐‐partitions 1 ‐‐topic test
Now we can use the following command to view the current topic in kafka
bin/kafka‐topics.sh ‐‐list ‐‐zookeeper 192.168.0.60:2181
In addition to manually creating a Topic, when the producer publishes a message to a specified Topic, if the Topic does not exist, it will be created automatically.
Delete theme
bin/kafka‐topics.sh ‐‐delete ‐‐topic test ‐‐zookeeper 192.168.0.60:2181
Step 4: send message
kafka comes with a producer command client, which can read the content from the local file, or we can input the content directly from the command line and send these contents to the kafka cluster in the form of messages. By default, each line is treated as a separate message. First, we need to run the script to publish the message, and then enter the content of the message to be sent in the command:
bin/kafka‐console-producer.sh --broker-list 192.168.0.60:9092 --topic test >this is a msg >this is a another msg
Step 5: consumption news
For consumer, kafka also carries a command-line client, which will output the obtained content in the command. The default is to consume the latest message:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.0.60:9092 --consumer-property group.id=testGroup --topic test
If you want to consume the previous message, you can specify it through the -- from beginning parameter, as follows:
bin/kafka-console-consumer.sh --bootstrap-server 192.168.0.60:9092 --from-beginning --topic test
If you run the above commands through different terminal windows, you will see the contents entered in the producer terminal and will soon be displayed in the consumer terminal window.
All the above commands have some additional options; When we run the command without any parameters, the detailed usage of the command will be displayed. There are other commands as follows:
View group name
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.0.60:9092 --list
View consumer's consumption offset
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.0.60:9092 --describe --group testGroup

Note that current offset, log end offset and lag are the current consumption offset, the end offset (HW) and the number of messages behind consumption
Consumption multi theme
bin/kafka-console-consumer.sh --bootstrap-server 192.168.0.60:9092 --whitelist "test|test-2"
Unicast consumption
The mode that a message can only be consumed by one consumer is similar to the queue mode. Just let all consumers in the same consumption group, execute the following consumption commands on two clients respectively, and then send a message to the topic. As a result, only one client can receive the message
bin/kafka-console-consumer.sh --bootstrap-server 192.168.0.60:9092 --consumer-property group.id=testGroup --topic test
Multicast consumption
The mode that a message can be consumed by multiple consumers is similar to the publish subscribe mode. In view of Kafka's feature that the same message can only be consumed by one consumer in the same consumption group, multicast can be realized as long as these consumers belong to different consumption groups. We add another consumer who belongs to the testGroup-2 consumer group. As a result, both clients can receive messages
bin/kafka-console-consumer.sh --bootstrap-server 192.168.0.60:9092 --consumer-property group.id=testGroup2 --topic test
Step 6: kafka cluster configuration
So far, we have all run the broker on a single node, which doesn't mean much. For kafka, a single broker means that there is only one node in the kafka cluster. To increase the number of nodes in the kafka cluster, you only need to start a few more broker instances. For a better understanding, let's start three broker instances on one machine at the same time.
First, we need to establish the configuration files of the other two broker s:
cp config/server.properties config/server-1.properties cp config/server.properties config/server-2.properties
The contents of the configuration file are as follows:
config/server-1.properties:
#broker. The ID attribute must be unique in the kafka cluster broker.id=1 #kafka deployed machine ip and service port number listeners=PLAINTEXT://192.168.0.60:9093 log.dir=/usr/local/data/kafka-logs-1
Now let's create a new topic. Set the number of copies to 3 and the number of partitions to 2:
bin/kafka-topics.sh --create --zookeeper 192.168.0.60:2181 --replication-factor 3 --partitions 2 --topic my-replicated-topic
Check the status of topic
bin/kafka-topics.sh --describe --zookeeper 192.168.0.60:2181 --topic my-replicated-topic

The following is the explanation of the output content. The first line is the summary information of all partitions, and each subsequent line represents the information of each partition.
- The leader node is responsible for all read and write requests for a given partition.
- replicas indicates the number of broker s on which a partition is backed up. No matter whether this point is a "leader" or not, even if this node hangs, it will be listed.
- isr is a subset of replicas. It only lists the nodes of the partition that are currently alive and have been synchronously backed up.
We can run the same command to view the topic named "test" created earlier
bin/kafka-topics.sh --describe --zookeeper 192.168.0.60:2181 --topic test

The number of partitions of topic is 1 and the backup factor is 1, so the display is as shown above. Of course, we can also increase the number of partitions of topic through the following commands (currently kafka does not support reducing partitions):
bin/kafka‐topics.sh -alter --partitions 3 --zookeeper 127.0.0.1:2181 --topic test
Now let's send some message s to the newly created my replicated topic. kafka cluster can add all kafka nodes:
bin/kafka-console‐producer.sh --broker-list 192.168.0.60:9092,192.168.0.60:9093,192.168.0.60:9094 --topic my-replica ted-topic >my test msg 1 >my test msg 2
Start spending now:
bin/kafka‐console‐consumer.sh ‐‐bootstrap‐server 192.168.0.60:9092 ‐‐from‐beginning ‐‐topic my‐replicated‐topic my test msg 1 my test msg 2
Now let's test our fault tolerance. Because broker1 is currently the leader of partition 0 of my replicated topic, we want to kill it
ps ‐ef | grep server.properties kill ‐9 14776
Now execute the command:
bin/kafka‐topics.sh ‐‐describe ‐‐zookeeper 192.168.0.60:9092 ‐‐topic my‐replicated‐topic
We can see that the leader node of partition 0 has become broker 0. Note that there is no node 1 in Isr. The leader election is also conducted from Isr (in sync replica).
At this point, we can still consume new news:
bin/kafka‐console‐consumer.sh ‐‐bootstrap‐server 192.168.0.60:9092 ‐‐from‐beginning ‐‐topic my‐replicated‐topic my test msg 1 my test msg 2
View the leader information corresponding to the topic partition:

Java client access Kafka
Introducing maven dependency
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka‐clients</artifactId> <version>1.1.0</version> </dependency>
Message sender code
public class MsgProducer {
public static void main(String[] args) throws InterruptedException, ExecutionException {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.60:9092,192.168.0.60:9093,192.168.0.60:9094");
/*
Send message persistence mechanism parameters
(1)acks=0: It means that the producer can continue to send the next message without waiting for any broker to confirm the reply of the message. Highest performance, but most likely to lose messages.
(2)acks=1: At least wait until the leader has successfully written the data to the local log, but you don't need to wait for all follower s to write successfully. You can continue to send the next message.
In this case, if the follower does not successfully back up the data, and the leader
If you hang up again, the message will be lost.
(3)acks=‐1 Or all: this means that the leader needs to wait for all backups (the number of backups configured by min.insync.replicas) to be successfully written to the log. This strategy will ensure that as long as there is
A backup survives without losing data.
This is the strongest data guarantee. Generally, this configuration is only used in financial level or scenes dealing with money.
*/
props.put(ProducerConfig.ACKS_CONFIG, "1");
//If the message fails to be sent, it will be retried. The default retry interval is 100ms. Retry can ensure the reliability of message sending, but it may also cause repeated message sending, such as network jitter, so it needs to be sent to the receiver
While doing the idempotent processing of message reception
props.put(ProducerConfig.RETRIES_CONFIG, 3);
//Retry interval setting
props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 300);
//Set the local buffer for sending messages. If this buffer is set, messages will be sent to the local buffer first, which can improve message sending performance. The default value is 33554432, or 32MB
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
//The kafka local thread fetches data from the buffer and sends it to the broker in batches,
//Set the size of batch messages. The default value is 16384, or 16kb, which means that a batch is sent when it is full of 16kb
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
//The default value is 0, which means that the message must be sent immediately, but this will affect performance
//Generally, it is set to about 100ms, which means that after the message is sent, it will enter a local batch. If the batch is full of 16kb within 100ms, it will be sent together with the batch
go
//If the batch is not full within 100 milliseconds, the message must also be sent. The message sending delay time cannot be too long
props.put(ProducerConfig.LINGER_MS_CONFIG, 100);
//Serialize the sent key from the string into a byte array
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//Serialize the sent message value from a string into a byte array
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
Producer<String, String> producer = new KafkaProducer<>(props);
int msgNum = 5;
CountDownLatch countDownLatch = new CountDownLatch(msgNum);
for (int i = 1; i <= msgNum; i++) {
Order order = new Order(i, 100 + i, 1, 1000.00);
//Specify send partition
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("order‐topic"
, 0, order.getOrderId().toString(), JSON.toJSONString(order));
//No sending partition is specified. The specific sending partition calculation formula is: hash(key)%partitionNum
/*ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("my‐replicated‐topic"
, order.getOrderId().toString(), JSON.toJSONString(order));*/
//Synchronization blocking method for waiting for successful message sending
/*RecordMetadata metadata = producer.send(producerRecord).get();
System.out.println("Sending message result in synchronization mode: "+" topic ‐ "+ metadata. Topic() +" |partition ‐“
+ metadata.partition() + "|offset‐" + metadata.offset());*/
//Send message asynchronously
producer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception != null) {
System.err.println("Failed to send message:" + exception.getStackTrace());
}
if (metadata != null) {
System.out.println("Send message results asynchronously:" + "topic‐" + metadata.topic() + "|partition‐"
+ metadata.partition() + "|offset‐" + metadata.offset());
}
countDownLatch.countDown();
}
});
//Send points TODO
}
countDownLatch.await(5, TimeUnit.SECONDS);
producer.close();
}
}
Message receiver code
public class MsgConsumer {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.0.60:9092");
// Consumer group name
props.put(ConsumerConfig.GROUP_ID_CONFIG, "testGroup");
// Submit offset automatically
/*props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// Interval between automatic submission of offset
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG , "1000");*/
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
/*
Heartbeat time: the service broker confirms whether the consumer has a fault through heartbeat. If a fault is found, it will send it through heartbeat
rebalance Give instructions to other consumer s to tell them to rebalance. This time can be a little shorter
*/
props.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG, 1000);
//How long does the server-side broker think that a consumer has failed when it doesn't perceive the heartbeat? The default is 10 seconds
props.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10 * 1000);
/*
If the interval between two poll operations exceeds this time, the broker will think that the processing capacity of the consumer is too weak,
It will be kicked out of the consumption group and the partition will be allocated to other consumer s
*/
props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 30 * 1000);
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// Consumption theme
String topicName = "order‐topic";
//consumer.subscribe(Arrays.asList(topicName));
// Consumption designated partition
//consumer.assign(Arrays.asList(new TopicPartition(topicName, 0)));
//Message backtracking consumption
consumer.assign(Arrays.asList(new TopicPartition(topicName, 0)));
consumer.seekToBeginning(Arrays.asList(new TopicPartition(topicName, 0)));
//Specify offset consumption
//consumer.seek(new TopicPartition(topicName, 0), 10);
while (true) {
/*
* poll() API It is a long polling for pulling messages, mainly to judge whether the consumer is still alive, as long as we continue to call poll(),
* Consumers will live in their own group and continue to consume messages specifying partition.
* The bottom layer does this: the consumer continuously sends a heartbeat to the server if a session
* timeout.ms)consumer If they hang up or cannot send heartbeat, the consumer will be considered as hung up,
* This Partition will also be reassigned to other partitions
*/
ConsumerRecords<String, String> records = consumer.poll(Integer.MAX_VALUE);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Message received: offset = %d, key = %s, value = %s%n", record.offset(), record.key(),
record.value());
}
if (records.count() > 0) {
// Submit offset
consumer.commitSync();
}
}
}
}Spring Boot integrates Kafka
Introducing spring boot kafka dependency
<dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring‐kafka</artifactId> </dependency>
application. The YML configuration is as follows:
server: port: 8080 spring: kafka: bootstrap‐servers: 192.168.0.60:9092,192.168.0.60:9093 producer: # producer retries: 3 # If a value greater than 0 is set, the client will resend the failed records batch‐size: 16384 buffer‐memory: 33554432 # Specify the encoding and decoding method of message key and message body key‐serializer: org.apache.kafka.common.serialization.StringSerializer value‐serializer: org.apache.kafka.common.serialization.StringSerializer consumer: group‐id: mygroup enable‐auto‐commit: true
Sender Code:
@RestController
public class KafkaController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping("/send")
public void send() {
kafkaTemplate.send("mytopic", 0, "key", "this is a msg");
}
}
Consumer code:
@Component
public class MyConsumer {
/**
* @KafkaListener(groupId = "testGroup", topicPartitions = {
* @TopicPartition(topic = "topic1", partitions = {"0", "1"}),
* @TopicPartition(topic = "topic2", partitions = "0",
* partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "100"))
* },concurrency = "6")
* //concurrency Is the number of consumers in the same group, which is the number of concurrent consumption. It must be less than or equal to the total number of partitions
* @param record
*/
@KafkaListener(topics = "mytopic",groupId = "testGroup")
public void listen(ConsumerRecord<String, String> record) {
String value = record.value();
System.out.println(value);
System.out.println(record);
}
}