Redis Cluster is the Redis Cluster function officially provided by redis
1. Why Redis Cluster
1.Master slave replication cannot achieve high availability 2.With the development of the company, the number of users and concurrency are increasing, and the business needs higher efficiency QPS,In master-slave replication, a single machine QPS May not meet business needs 3.Considering the amount of data, when the existing server memory cannot meet the needs of business data, simply adding memory to the server cannot meet the requirements. At this time, it is necessary to consider the distributed requirements and distribute the data to different servers 4.Network traffic demand: the traffic of the service has exceeded the upper limit of the network card of the server, and distributed distribution can be considered for diversion 5.Offline computing requires intermediate buffer and other requirements
2. Data distribution
2.1 why data distribution
For full data, the single Redis node cannot meet the requirements. The data is divided into several subsets according to the partition rules
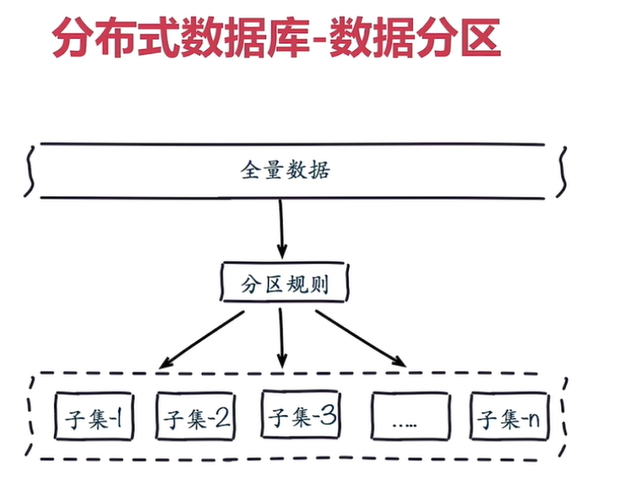
2.2 sequential distribution of common data distribution methods
For example, 1 to 100 numbers should be saved on three nodes, partitioned in order, and the data should be evenly distributed among the three nodes 1 Data from No. 34 to No. 33 are saved to node 1, data from No. 34 to No. 66 are saved to node 2, and data from No. 67 to No. 100 are saved to node 3
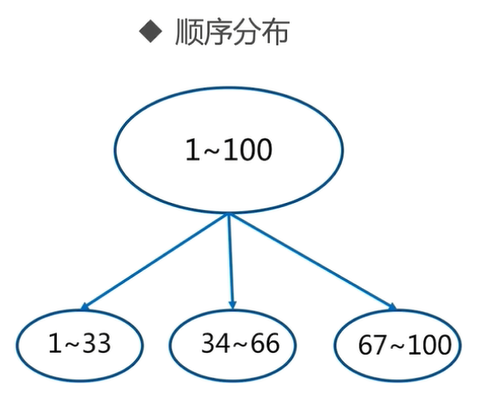
Sequential partition is often used in the design of relational database
2.3 hash distribution of common data distribution methods
For example, for 1 to 100 numbers, hash each number, and then divide the hash result of each number by the number of nodes to get the remainder. If the remainder is 1, it will be saved on the first node, if the remainder is 2, it will be saved on the second node, and if the remainder is 0, it will be saved on the third node. This can ensure that the data is scattered and the data distribution is relatively uniform
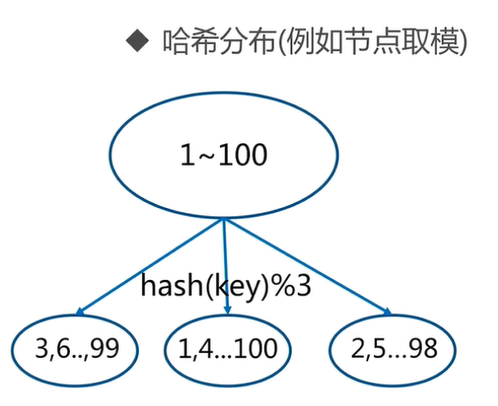
Hash distribution is divided into three partition methods:
2.3.1 node residual zoning
For example, there are 100 data. After each data is hash ed, the remainder is calculated with the number of nodes, and saved on different nodes according to the remainder
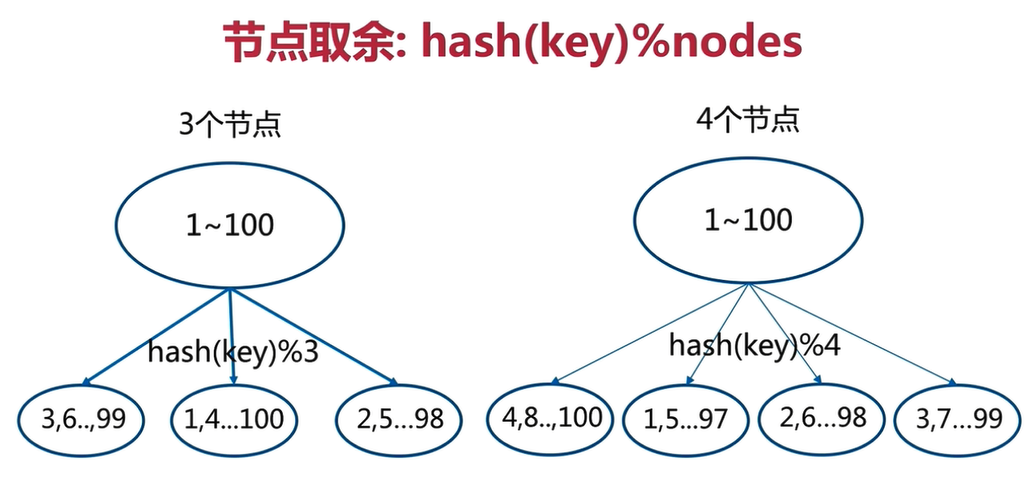
Node redundancy is a very simple partition method
There is a problem with the node redundancy partition method: when adding or reducing nodes, 80% of the data in the original nodes will be migrated and all data will be redistributed
It is recommended to use multiple capacity expansion for node redundancy partition. For example, three nodes were used to save data, and six nodes were used to save data. In this way, only 50% of the data needs to be appropriately moved. After data migration, data cannot be read from the cache for the first time. Data must be read from the database and then written back to the cache before the migrated data can be read from the cache
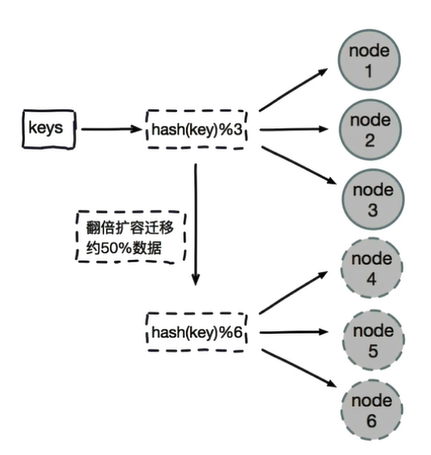
Advantages of node redundancy method:
Client fragmentation Simple configuration: hash the data and then get the remainder
Disadvantages of node redundancy method:
Data migration occurs when a data node scales
The number of migrations is related to adding node data. It is recommended to double and expand the capacity
2.3.2 consistent hash partition
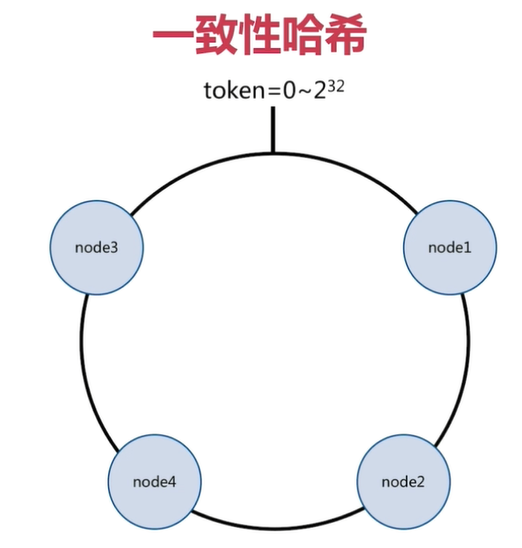
Consistent hash principle:
Treat all the data as one token Ring, token The data range in the ring is the 32nd power of 0 to 2. Then assign one to each data node token Range value, this node is responsible for saving the data within this range.
For each key conduct hash Operation, where is the result after being hashed token Within the range of, you can find the nearest node clockwise key Will be saved on this node.
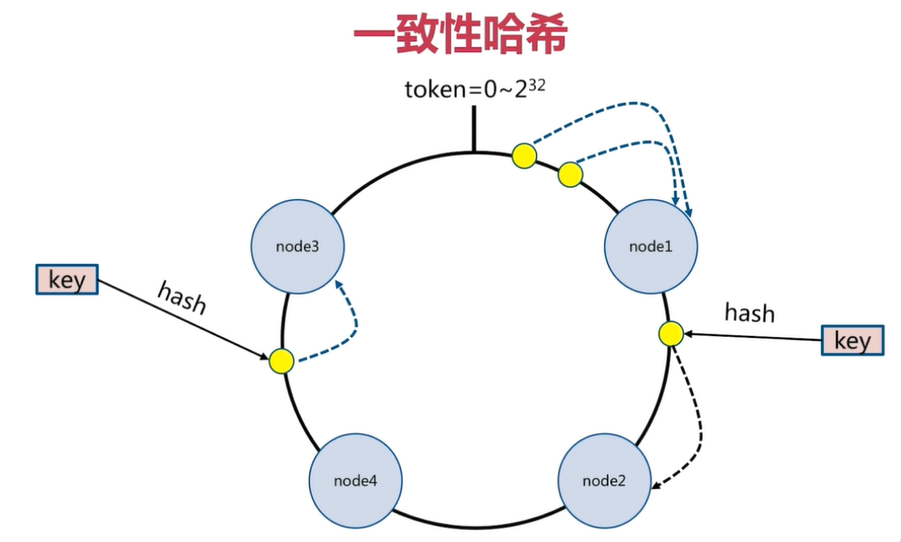
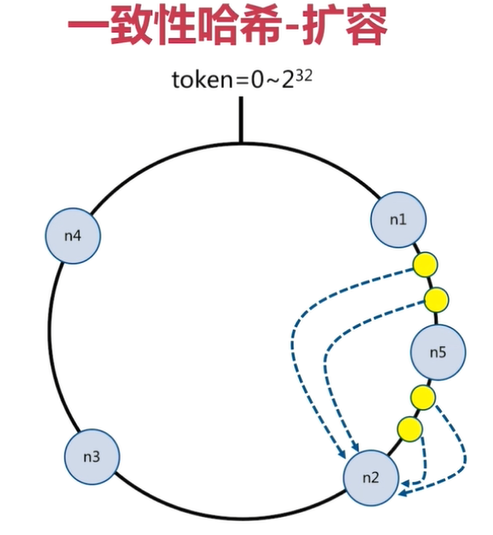
In the figure above, there are four key cover hash The subsequent value is in n1 Node and n2 Between nodes, according to the clockwise rule, these four key Will be saved in n2 On the node, If in n1 Node and n2 Add between nodes n5 Node, when there is key cover hash The subsequent value is in n1 Node and n5 Between nodes, these key Will be saved in n5 On the node In the above example, add n5 After the node is, the data will be migrated in n1 Node and n2 Between nodes, n3 Node and n4 Nodes are not affected, and the scope of data migration is greatly reduced Similarly, if there are 1000 nodes and one node is added at this time, the affected node range is only 2 / 1000 at most Consistent hashing is generally used when there are many nodes
Advantages of consistent hash partition:
Client fragmentation: hash + Clockwise(Optimized residual) When a node scales, it only affects adjacent nodes, but there is still data migration
Disadvantages of consistent hash partition:
Double the scale to ensure minimum data migration and load balancing
2.3.3 virtual slot partition
Virtual slot partition is the partition method adopted by Redis Cluster
Preset virtual slots, and each slot is equivalent to a number with a certain range. Each slot maps a data subset, which is generally larger than the number of nodes
The preset virtual slots in Redis Cluster range from 0 to 16383
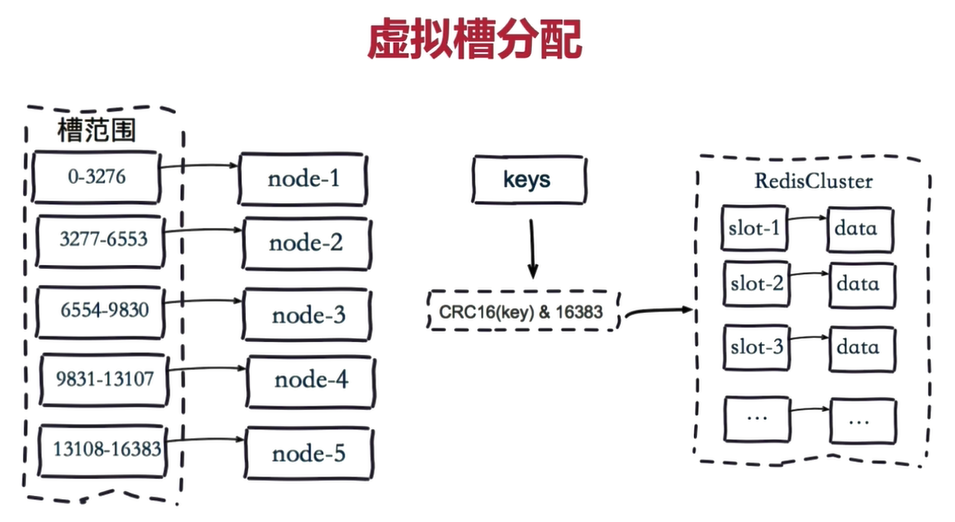
Steps:
1.16384 slots are evenly distributed according to the number of nodes and managed by nodes
2.For each key according to CRC16 Rule conduct hash operation
3.hold hash Results 16383 was taken out
4.Send the remainder to Redis node
5.The node receives the data and verifies whether it is within the range of the slot number managed by itself
If it is within the slot number range managed by yourself, save the data to the data slot, and then return the execution result
If it is outside the slot number range managed by itself, the data will be sent to the correct node, and the correct node will save the data in the corresponding slotIt should be noted that Redis Cluster nodes will share messages, and each node will know which node is responsible for which range of data slots
In the virtual slot distribution mode, since each node manages a part of the data slot, the data is saved to the data slot. When the node expands or shrinks, the data slot can be reallocated and migrated, and the data will not be lost.
Characteristics of virtual slot partition:
Use server management node, slot, data: for example Redis Cluster It can disperse the data and ensure uniform data distribution
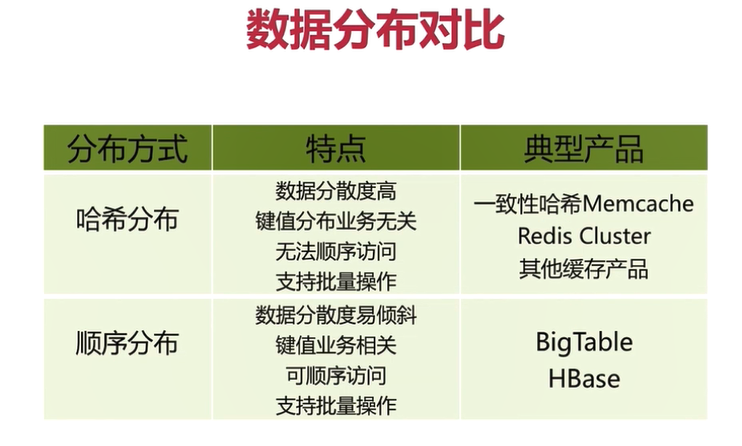
2.3 comparison between sequential distribution and hash distribution
3. Basic architecture of redis cluster
3.1 nodes
Redis Cluster is a distributed architecture: there are multiple nodes in Redis Cluster, and each node is responsible for data reading and writing
Each node communicates with each other.
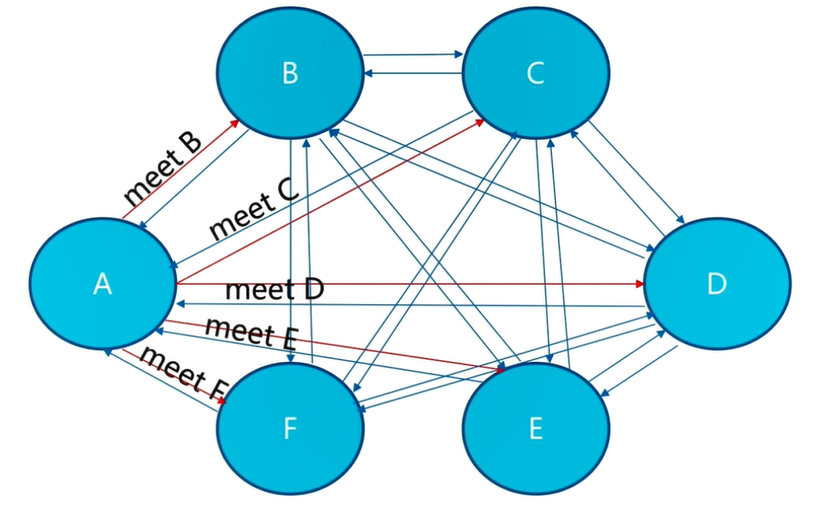
3.2 meet operation
Nodes communicate with each other
meet operation is the basis of mutual communication between nodes. meet operation has certain frequency and rules
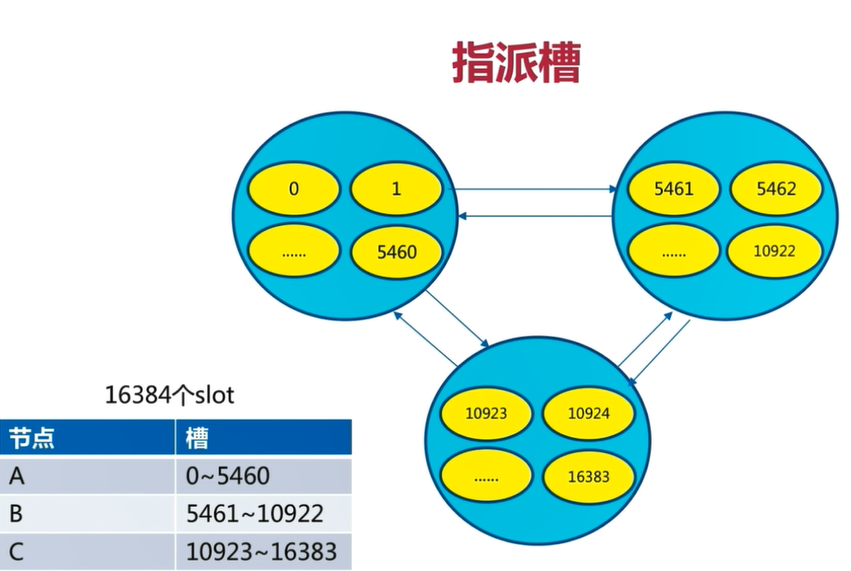
3.3 distribution tank
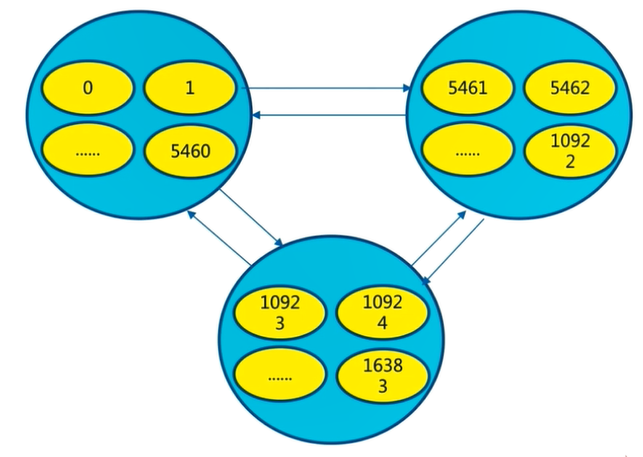
The 16384 slots are evenly allocated to nodes for management, and each node can only read and write to its own slot
Since each node communicates with each other, each node knows the range of slots that another node is responsible for managing
When the client accesses any node, it hash es the data key according to CRC16 rules, and then obtains 16383 from the operation result. If the remainder is within the slot managed by the currently accessed node, the corresponding data will be returned directly
If it is not within the slot range managed by the current node, the client will be told which node to go to obtain data, and the client will go to the correct node to obtain data
3.4 reproduction
To ensure high availability, each master node has a slave node. When the master node fails, the Cluster will achieve high availability of the master and standby according to the rules
For nodes, there is a configuration item: cluster enabled, that is, whether to start in cluster mode
3.5 client routing
3.5.1 moved redirection
1.Each node is shared through communication Redis Cluster The relationship between the slot and the corresponding node in the cluster 2.Client to Redis Cluster Any node of sends a command, and the node receiving the command will CRC16 Rule conduct hash Operation and 16383 remainder, calculate their own slots and corresponding nodes 3.If the slot storing data is assigned to the current node, execute the command in the slot and return the command execution result to the client 4.If the slot where the data is saved is not within the management scope of the current node, it returns to the client moved Redirection exception 5.The client receives the result returned by the node. If yes moved Exception, from moved Get the information of the target node from the exception 6.The client sends a command to the target node to obtain the command execution result
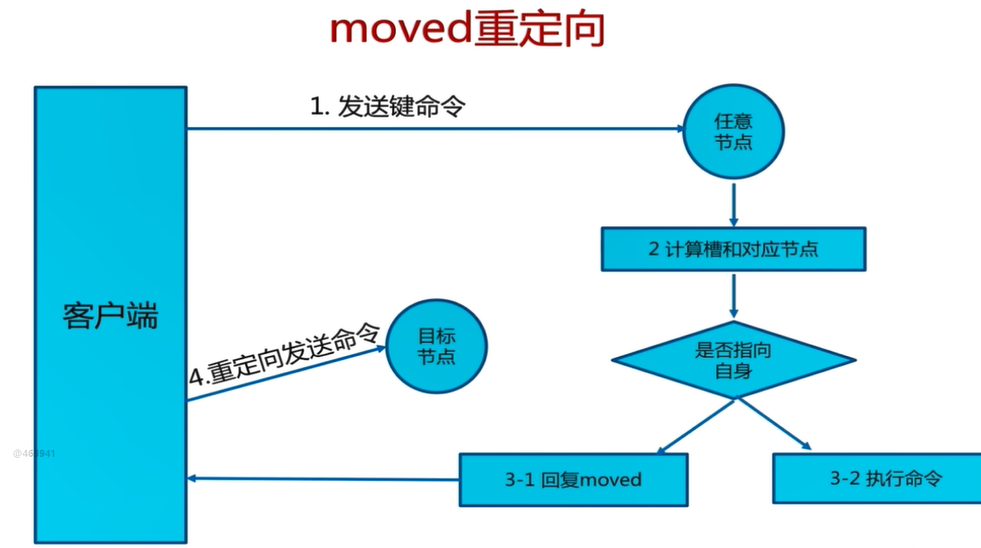
It should be noted that the client will not automatically find the target node to execute the command
Slot hit: direct return

[root@mysql ~]# redis-cli -p 9002 cluster keyslot hello (integer) 866
Slot Miss: moved exception
[root@mysql ~]# redis-cli -p 9002 cluster keyslot php (integer) 9244

[root@mysql ~]# redis-cli -c -p 9002 127.0.0.1:9002> cluster keyslot hello (integer) 866 127.0.0.1:9002> set hello world -> Redirected to slot [866] located at 192.168.81.100:9003 OK 192.168.81.100:9003> cluster keyslot python (integer) 7252 192.168.81.100:9003> set python best -> Redirected to slot [7252] located at 192.168.81.101:9002 OK 192.168.81.101:9002> get python "best" 192.168.81.101:9002> get hello -> Redirected to slot [866] located at 192.168.81.100:9003 "world" 192.168.81.100:9003> exit [root@mysql ~]# redis-cli -p 9002 127.0.0.1:9002> cluster keyslot python (integer) 7252 127.0.0.1:9002> set python best OK 127.0.0.1:9002> set hello world (error) MOVED 866 192.168.81.100:9003 127.0.0.1:9002> exit [root@mysql ~]#
3.5.2 ask redirection
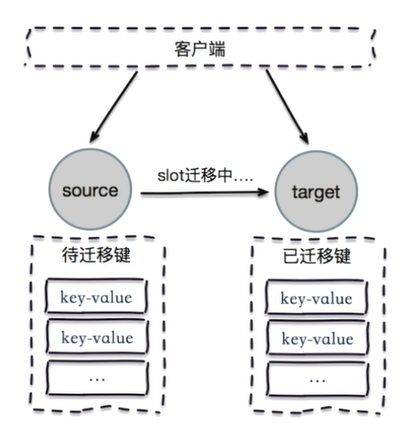
When expanding and shrinking the cluster, you need to migrate the slot and the data in the slot
When the client sends a command to a node, the node returns a moved exception to the client, telling the client the node information of the slot corresponding to the data
If the cluster is being expanded or emptied at this time, when the client sends a command to the correct node, the slot and the data in the slot have been migrated to other nodes, it will return ask, which is the ask redirection mechanism
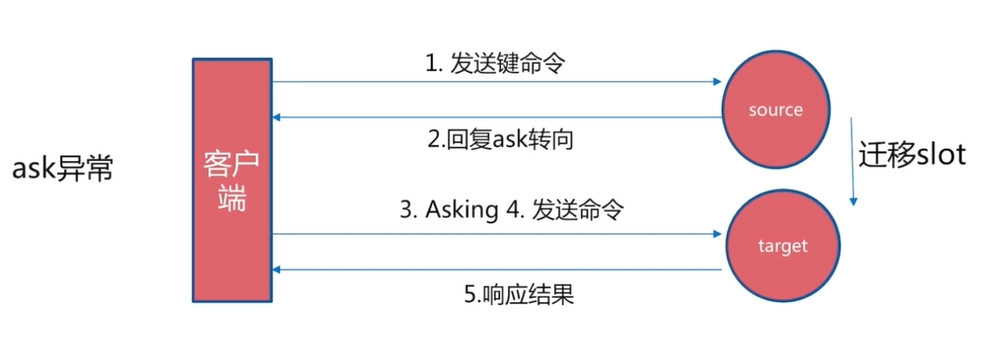
Steps:
1.The client sends a command to the target node. The slot in the target node has been migrated to another node. At this time, the target node will return ask Turn to the client 2.The client sends a message to the new node Asking Command to the new node, and then send the command to the new node again 3.The new node executes the command and returns the command execution result to the client
Similarities and differences between moved exception and ask exception
Both are client redirects moved Exception: the slot has been determined to migrate, that is, the slot is no longer in the current node ask Exception: the slot is still migrating
3.5.3 smart smart client
The primary goal of using smart client: pursuing performance
Select a runnable node from the cluster and use Cluster slots to initialize the slot and node mapping
Map the results of Cluster slots locally and create a JedisPool for each node, which is equivalent to setting a JedisPool for each redis node, and then you can read and write data
Precautions when reading and writing data:
each JedisPool Cached in slot And nodes node Relationship between
key and slot Relationship: Yes key conduct CRC16 Rule conduct hash After that, the result obtained by taking the remainder with 16383 is the slot
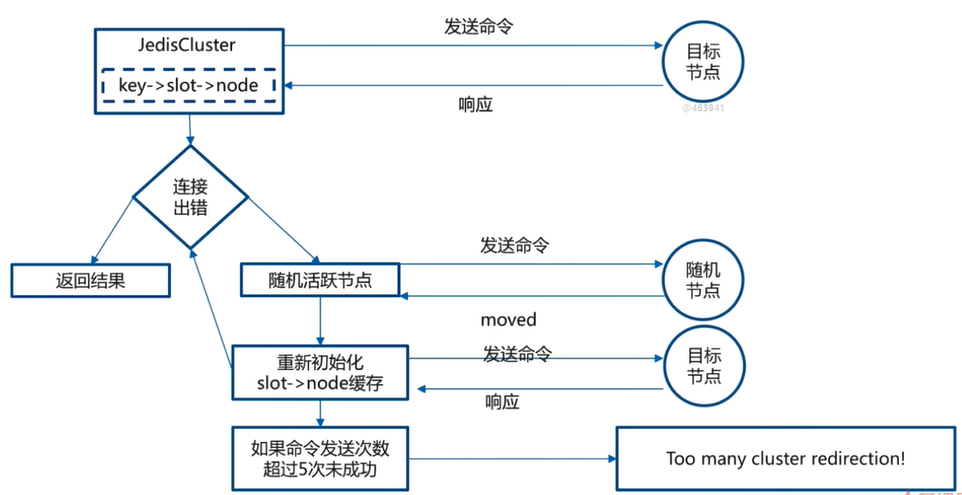
JedisCluster When you start, you already know key,slot and node The relationship between the target nodes can be found
JedisCluster Send commands to the target node, and the target node responds directly to JedisCluster
If JedisCluster If there is an error connecting to the target node, then JedisCluster You will know that the connected node is a wrong node
here JedisCluster The command will be sent to the random node, and the random node will return moved Abnormal give JedisCluster
JedisCluster Will reinitialize slot And node Then send a command to the new target node, and the target command executes the command and sends it to the JedisCluster response
If the command is sent more than 5 times, an exception is thrown"Too many cluster redirection!"
3.6 multi node command implementation
Redis Cluster does not support scanning all nodes with the scan command
Multi node command is to execute a command on all nodes
Batch operation optimization
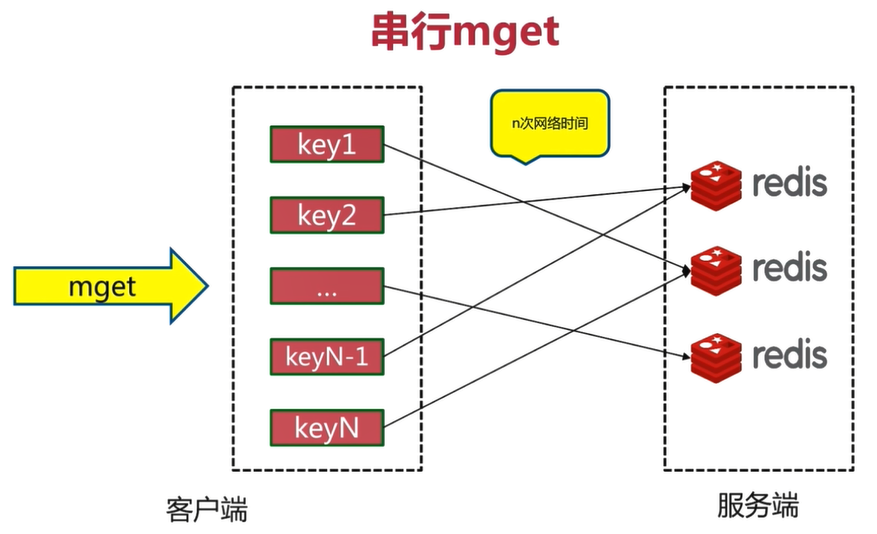
3.6.1 serial mget
Define a for loop, traverse all key s, get values from all Redis nodes and summarize them. It is simple, but inefficient, and requires n times of network time
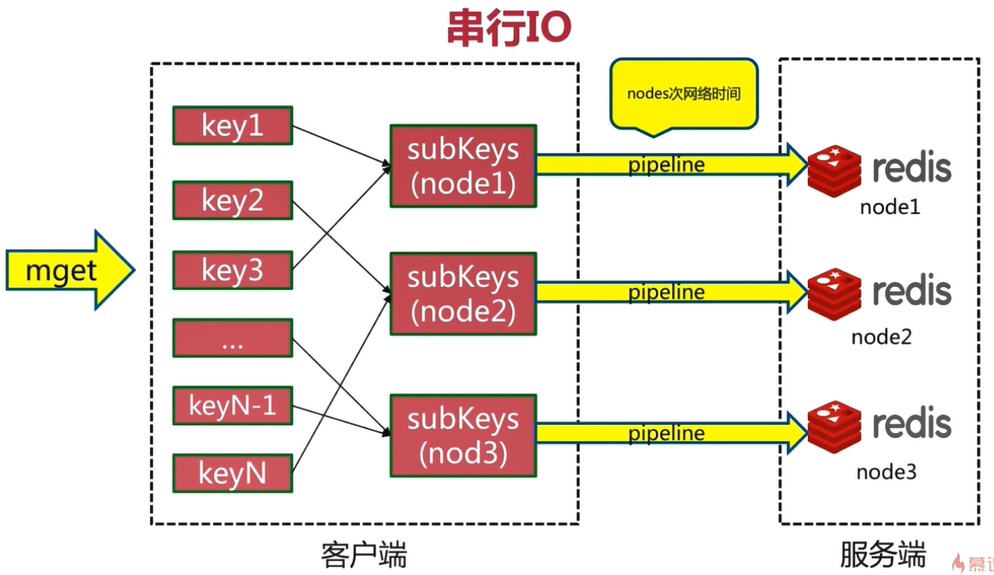
3.6.2 serial IO
Optimize the serial mget, cohere locally in the client, CRC16hash each key, and then get the remainder with 16383 to know which key corresponds to which slot
The corresponding relationship between the slot and the node has been cached locally, and then the key s are grouped according to the node to form a subset, and then the pipeline is used to send the command to the corresponding node, which requires nodes times of network time, which greatly reduces the network time overhead
3.6.3 parallel IO
Parallel IO is an optimization of serial IO. After grouping key s, start the corresponding number of threads according to the number of nodes, and request data from node nodes in parallel according to multi-threaded mode. It only takes one network time
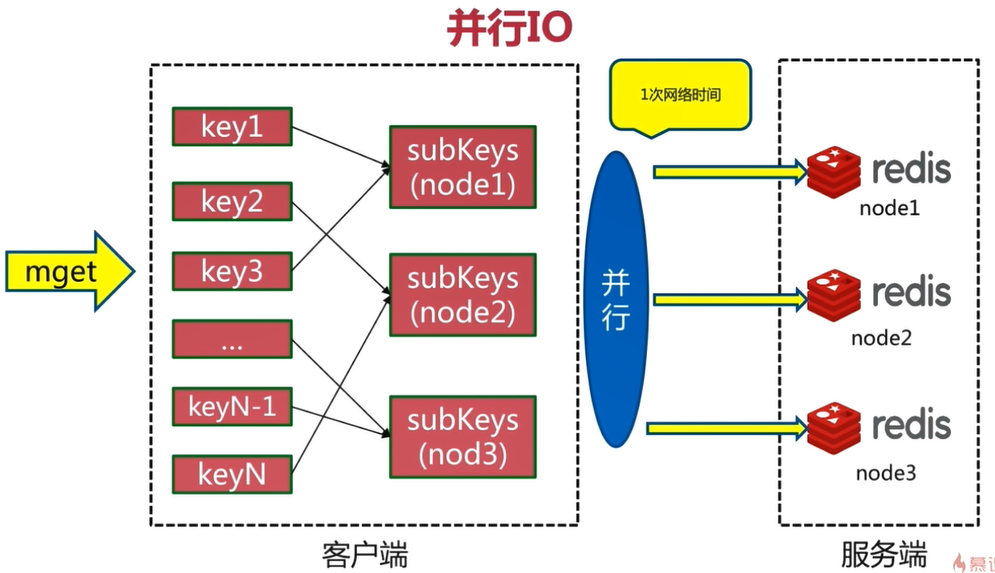
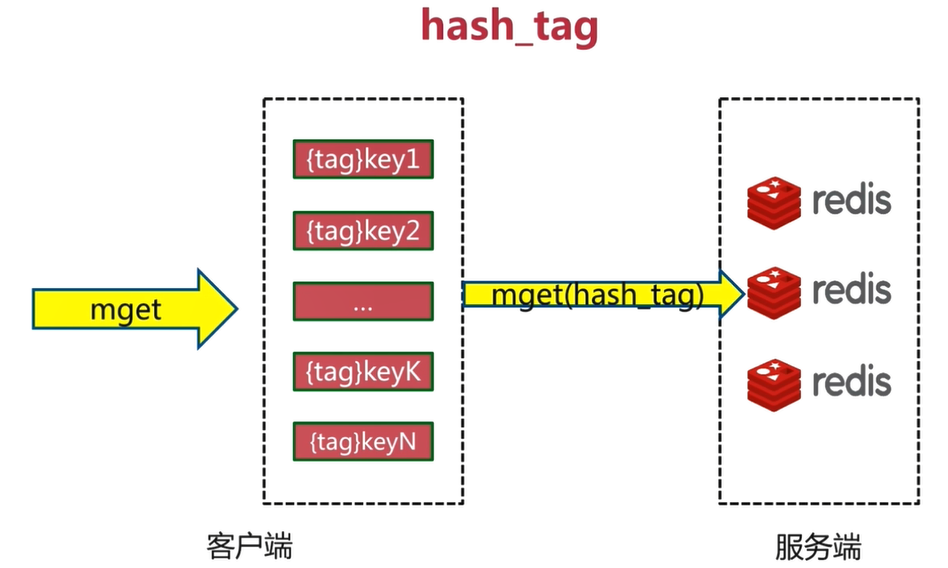
3.6.4 hash_tag
Hash the key_ Wrap the tag, and then enclose the tag in curly braces to ensure that all keys request data from only one node. In this way, to execute a command similar to mget, you only need to go to one node to obtain data, which is more efficient
3.6.5 analysis of advantages and disadvantages of four optimization schemes

3.7 fault discovery
Redis Cluster realizes fault discovery through ping/pong messages: sentinel is not required
ping/pong can not only transmit the corresponding messages between nodes and slots, but also other states, such as node master-slave state, node failure, etc
Fault detection is realized through this mode, which is divided into subjective offline and objective offline
3.7.1 subjective offline
A node thinks that another node is unavailable. 'bias' only represents one node's judgment of another node, not the cognition of all nodes
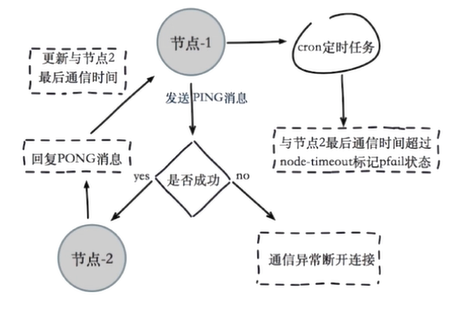
Subjective offline process:
1.Node 1 sends regularly ping Message to node 2
2.If the transmission is successful, it means that node 2 is running normally, and node 2 will respond PONG The message is sent to node 1, which updates the last communication time with node 2
3.If the transmission fails, the communication between node 1 and node 2 is abnormal, and the connection will still be sent to node 2 in the next scheduled task cycle ping news
4.If node 1 finds that the last communication time with node 2 exceeds node-timeout,Then node 2 is identified as pfail state
3.7.2 objective offline
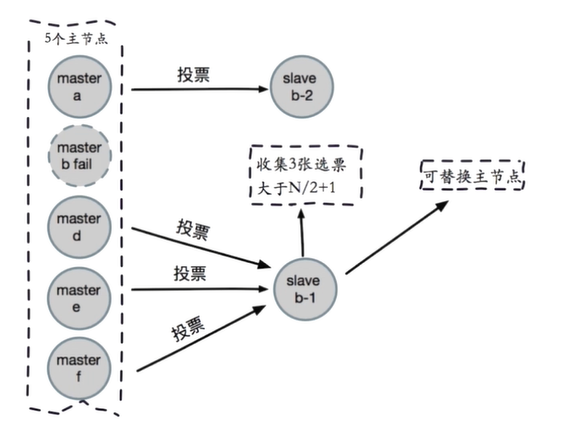
When more than half of the master nodes holding slots mark the subjective offline of a node, the fairness of judgment can be guaranteed
In cluster mode, only the master node has read-write permission and cluster slot maintenance permission, and the slave node has copy permission
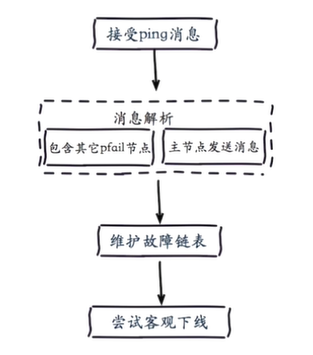
Objective offline process:
1.A node receives messages sent by other nodes ping Message, if received ping The message contains additional information pfail Node, this node will add the message content of subjective offline to its own fault list, which contains the status information of each node to other nodes received by the current node 2.After the current node adds the message content of subjective offline to its own fault list, it will try to objectively offline the fault node
The cycle of the fault list is: node timeout * 2 of the cluster to ensure that the previous fault messages will not affect the fault messages in the cycle and ensure the fairness and effectiveness of the objective offline
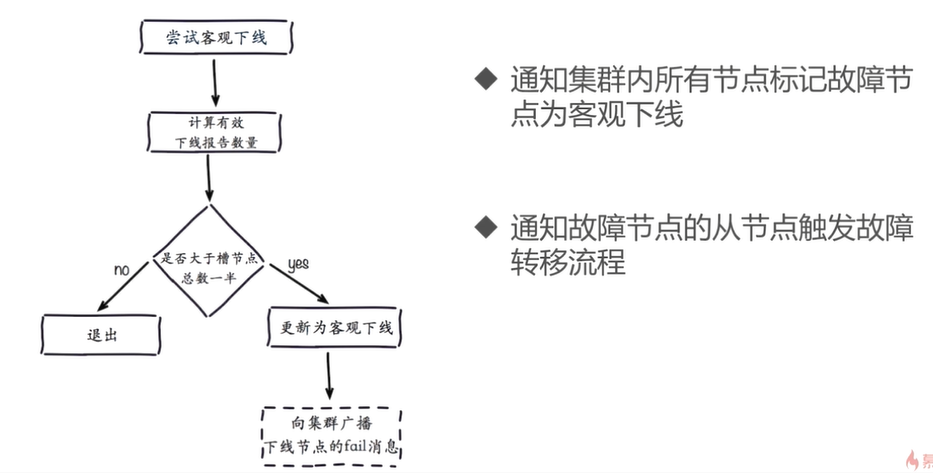
3.8 fault recovery
3.8.1 qualification inspection
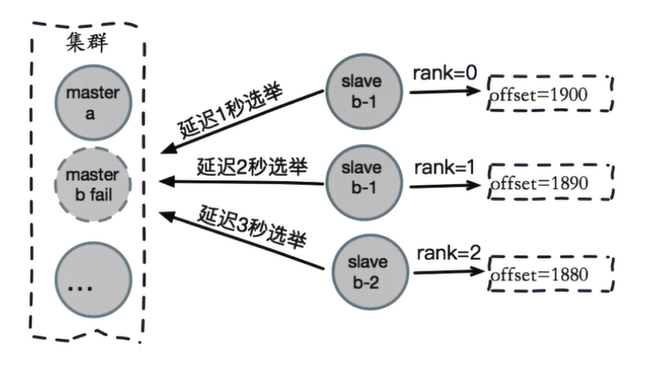
Check the qualification of the slave node. Only the slave node that is not checked can start fault recovery Check the disconnection time between each slave node and the failed master node exceed cluster-node-timeout * cluster-slave-validity-factor Number, disqualification cluster-node-timeout The default is 15 seconds, cluster-slave-validity-factor The default value is 10 If the default values are used for both parameters, each node checks the disconnection time with the failed master node. If it exceeds 150 seconds, this node is not likely to become a replacement master node
3.9.2 election preparation time
Make the slave node with the largest offset have the conditions for priority to become the master node
3.8.3 election voting
Vote on the selected slave nodes to select a new master node
3.8.4 replace master node
Current from node to off node(slaveof no one) implement cluster del slot Cancel the slot in the charge of the failed master node and execute cluster add slot Assign these slots to yourself Broadcast your to the cluster pong Message indicating that the failed slave node has been replaced
3.8.5 failover drill
Execute on a master node kill -9 {pid}To simulate downtime3.9 disadvantages of redis cluster
When the number of nodes is large, the performance will not be very high Solution: use smart client. The smart client knows which node is responsible for managing which slot, and when the mapping relationship between the node and the slot changes, the client will also know the change, which is a very efficient way
4. Build Redis Cluster
There are two installation methods for building Redis Cluster
- 1.Native command installation
-
5. Common problems in development, operation and maintenance
5.1 cluster integrity
The default value of cluster require full coverage is yes, that is, the cluster will provide services only when all nodes in the cluster are online and 16384 slots are in service
All 16384 slots in the cluster are in service to ensure the integrity of the cluster
When a node fails or is failing over, you will be prompted: (error)CLUSTERDOWN The cluster is down
It is recommended to set cluster require full coverage to no
5.2 bandwidth consumption
Redis Cluster nodes regularly exchange mission messages and do some heartbeat detection
It is officially recommended that the number of Redis Cluster nodes should not exceed 1000. When the number of nodes in the cluster is too large, it will cause bandwidth consumption that can not be ignored
Message sending frequency: when a node finds that the last communication time with other nodes exceeds cluster node timeout / 2, it will directly send a PING message
Message data volume: slots slot array (2kb space) and 1 / 10 of the status data of the whole cluster (the status data of 10 nodes is about 1kb)
Scale of machines deployed by nodes: the more machines distributed in the cluster and the more uniform the number of nodes divided by each machine, the higher the overall available bandwidth in the cluster
Bandwidth optimization:
Avoid using'large'Cluster: avoid using one cluster for multiple businesses. Large businesses can use multiple clusters cluster-node-timeout:Balance of bandwidth and failover speed Distribute to multiple machines as evenly as possible: ensure high availability and bandwidth
5.3 Pub/Sub broadcast
If you execute publish on any cluster node, the published message will be propagated in the cluster, and other nodes in the cluster will subscribe to the message, so the bandwidth overhead of the node will be great
publish broadcasts at each node of the cluster to increase the bandwidth
Solution: to ensure high availability when Pub/Sub needs to be used, a set of Redis Sentinel can be opened separately
5.4 cluster tilt
For distributed database, skew problem is common
Cluster skew means that the memory used by each node is inconsistent
5.4.1 reasons for data skew
1. Uneven allocation of nodes and slots, if redis trib is used There are few opportunities for this to happen when RB tools build clusters
redis-trib.rb info ip:port View node, slot and key value distribution redis-trib.rb rebalance ip:port Balance(Use with caution)
2. The number of keys corresponding to different slots varies greatly
CRC16 The algorithm is relatively uniform under normal conditions
May exist hash_tag
cluster countkeysinslot {slot}Get the number of key values corresponding to the slot3. Include bigkey: for example, large string, hash of millions of elements, set, etc
At the slave node: redis-cli --bigkeys Optimize: optimize data structure
4. Memory related configurations are inconsistent
hash-max-ziplist-value: Under certain conditions, hash have access to ziplist set-max-intset-entries: Under certain conditions, set have access to intset There are several nodes in a cluster. When some nodes are configured with the above two optimizations, the other nodes are not configured with the above two optimizations When saved in the cluster hash perhaps set It will cause uneven node data Optimization: regularly check the configuration consistency
5. Request tilt: hotspot key
important key perhaps bigkey Redis Cluster A node has a very important key,There will be hot issues
5.4.2 cluster tilt Optimization:
avoid bigkey Don't use hotkeys hash_tag When the consistency is not high, the local cache can be used+ MQ(Message queue)
5.5 cluster read-write separation
Read only connection: in cluster mode, the slave node does not accept any read-write requests
When a read request is made to the slave node, it is redirected to the master node responsible for the slot
The readonly command can be read: connection level command. When the connection is disconnected, the readonly command needs to be executed again
Read write separation:
The same problem: replication delay, reading expired data, slave node failure
Modify client: cluster slaves {nodeId}5.6 data migration
Official migration tool: redis trib RB and import
You can only migrate from a stand-alone to a cluster
Online migration is not supported: the source needs to stop writing
Breakpoint continuation is not supported
Single threaded migration: impact depth
Online migration:
Vipshop: redis-migrate-tool Pea Pod: redis-port
5.7 cluster VS single machine
Cluster limitations:
key Limited batch operation support: for example mget,mset Must be in one slot key Transactions and Lua Limited support: Operational key Must be on a node key Is the minimum granularity of data partition: not supported bigkey partition Multiple databases are not supported: there is only one database in cluster mode db0 Replication only supports one layer: tree replication structure is not supported Redis Cluster Meet the scalability of capacity and performance, many businesses'unwanted' Most of the time, client performance will'reduce' Command cannot be used across nodes: mget,keys,scan,flush,sinter etc. Lua And transactions cannot be used across nodes More complex client maintenance: SDK And application consumption(For example, more connection pools)
Redis Sentinel is enough for many scenes
6. Summary of redis cluster:
1.Redis Cluster The data partition rule adopts virtual slot mode(16384 Slot),Each node is responsible for a part of the slot and related data to realize the load balancing of data and requests
2.build Redis Cluster It is divided into four steps: preparing nodes, meet Operation, allocate slots, copy data.
3.Redis Officially recommended redis-trib.rb Tool quick build Redis Cluster
4.Cluster scaling is achieved by moving slots and related data between nodes
During capacity expansion, the slot is migrated from the source node to the new node according to the slot migration plan
When shrinking, if the offline node has a responsible slot, it needs to be migrated to other nodes before passing through cluster forget The command makes all nodes in the cluster forget to be offline
5.use smart The client operation cluster maximizes the communication efficiency. The client is responsible for calculating the mapping of maintenance keys, slots and nodes to quickly locate the target node
6.The automatic failover process of cluster is divided into fault discovery and node recovery. The node offline is divided into subjective offline and objective offline. When more than half of the nodes think that the fault node is subjective offline, mark this node as objective offline status. The slave node is responsible for triggering the fault recovery process for the objective offline master node to ensure the availability of the cluster
7.Common problems in development, operation and maintenance include: seat consumption of super large-scale clusters, pub/sub Broadcast problem, cluster tilt problem, comparison between single machine and cluster, etc