Hive compression and storage
1, Hadoop compression configuration
1.1 MR supported compression coding
In order to support a variety of compression / decompression algorithms, Hadoop introduces an encoder / decoder, as shown in the following table:
Comparison of compression performance
http://google.github.io/snappy/
On a single core of a 64 bit core i7 processor, Snappy compresses at about 250MB / s or higher and decompresses at about 500MB / s or higher.
1.2 compression parameter configuration
To enable compression in Hadoop, you can configure the following parameters (in mapred-site.xml file):
2, Map output stage compression
Turning on map output compression can reduce the amount of data transfer between map and Reduce task in the job. The specific configuration is as follows:
- Enable hive intermediate transmission data compression function
set hive.exec.compress.intermediate=true;
- Enable the map output compression function in mapreduce
set mapreduce.map.output.compress=true;
- Set the compression method of map output data in mapreduce
set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
- Execute query statement
select count(ename) name from emp;
22.593s
3, Reduce output stage compression
When Hive writes the output to the table, the output can also be compressed. Attribute Hive exec. compress. Output controls this function. Users may need to keep the default value false in the default settings file, so that the default output is an uncompressed plain text file. You can set this value to true in the query statement or execution script to enable the output result compression function.
- Enable hive final output data compression
set hive.exec.compress.output=true;
- Enable mapreduce final output data compression
set mapreduce.output.fileoutputformat.compress=true;
- Set mapreduce final data output compression mode
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
- Set mapreduce final data output compression to block compression
set mapreduce.output.fileoutputformat.compress.type=BLOCK;
- Test whether the output is a compressed file
insert overwrite local directory '/root/data/distribute-result0' select * from emp distribute by deptno sort by empno desc;
4, File storage format
The formats of data storage supported by Hive mainly include TEXTFILE, SEQUENCEFILE, ORC and PARQUET.
4.1 column storage and row storage
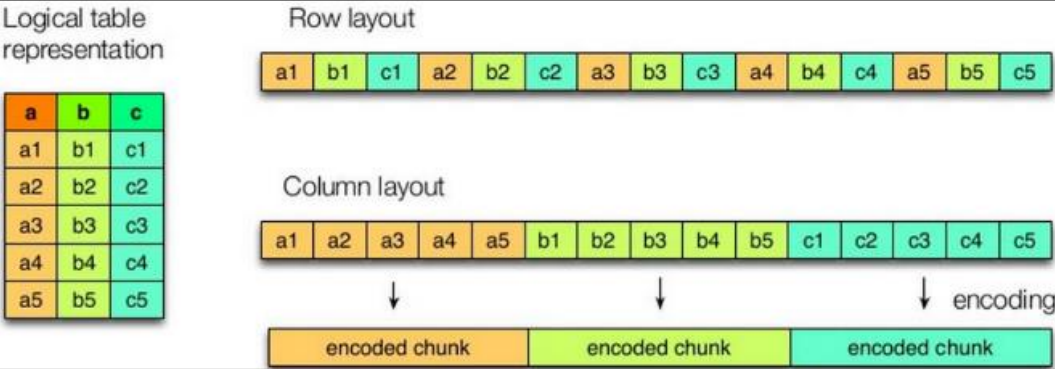
As shown in the figure, the logical table is on the left, the first one on the right is row storage, and the second one is column storage.
-
Characteristics of row storage
When querying a whole row of data that meets the conditions, the column storage needs to find the corresponding value of each column in each aggregated field. The row storage only needs to find one value, and the rest values are in adjacent places, so the row storage query speed is faster. -
Characteristics of column storage
Because the data of each field is aggregated and stored, when only a few fields are required for query, the amount of data read can be greatly reduced; The data type of each field must be the same. Column storage can be targeted to design better compression algorithms.
The storage formats of TEXTFILE and SEQUENCEFILE are based on row storage;
ORC and PARQUET are based on column storage.
4.2 TextFile format
In the default format, data is not compressed, resulting in high disk overhead and high data parsing overhead. It can be used in combination with Gzip and Bzip2, but with Gzip, hive will not segment the data, so it is impossible to operate the data in parallel.
4.3 Orc format
Orc (Optimized Row Columnar) is a new storage format introduced in hive version 0.11.
As shown in the figure below, it can be seen that each Orc file is composed of one or more strips. Each strip is generally the block size of HDFS. Each strip contains multiple records. These records are stored independently according to columns, corresponding to the concept of row group in Parquet. Each stripe consists of three parts: Index Data, Row Data and stripfooter:
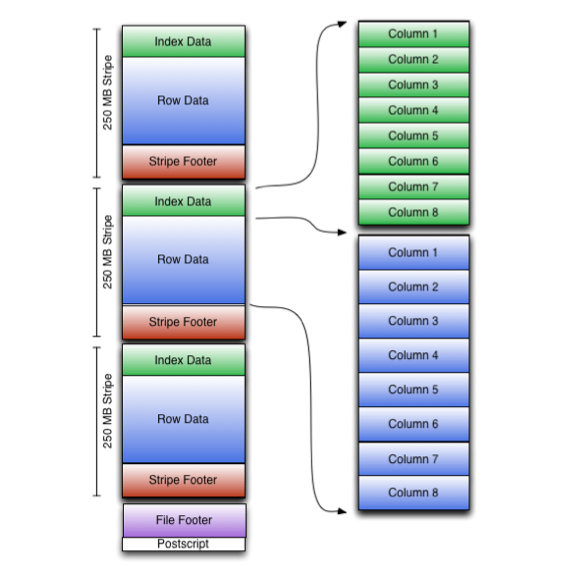
1) Index Data: a lightweight index. By default, an index is made every 1W rows. The index here should only record the offset of each field of a row in Row Data.
2) Row Data: it stores specific data. First take some rows, and then store these rows by column. Each column is encoded and divided into multiple streams for storage.
3) Stripe Footer: stores the type, length and other information of each Stream.
Each file has a File Footer, where the number of rows of each Stripe and the data type information of each Column are stored; At the end of each file is a PostScript, which records the compression type of the whole file and the length information of FileFooter. When reading a file, you will seek to read PostScript at the end of the file, parse the length of File Footer from the inside, read FileFooter again, parse the information of each Stripe from the inside, and then read each Stripe, that is, read from back to front.
4.4 Parquet format
Parquet file is stored in binary mode, so it can not be read directly. The file includes the data and metadata of the file. Therefore, parquet format file is self parsed.
(1) Row group: each row group contains a certain number of rows. At least one row group is stored in an HDFS file, similar to the concept of orc's stripe.
(2) Column chunk: in a row group, each column is saved in a column block, and all columns in the row group are continuously stored in the row group file. The values in a column block are of the same type, and different column blocks may be compressed by different algorithms.
(3) Page: each column block is divided into multiple pages. One page is the smallest coding unit. Different coding methods may be used on different pages of the same column block.
Generally, when storing Parquet data, the size of row groups will be set according to the Block size. Generally, the minimum unit of data processed by each Mapper task is a Block, so each row group can be processed by one Mapper task to increase the parallelism of task execution. Format of Parquet file.
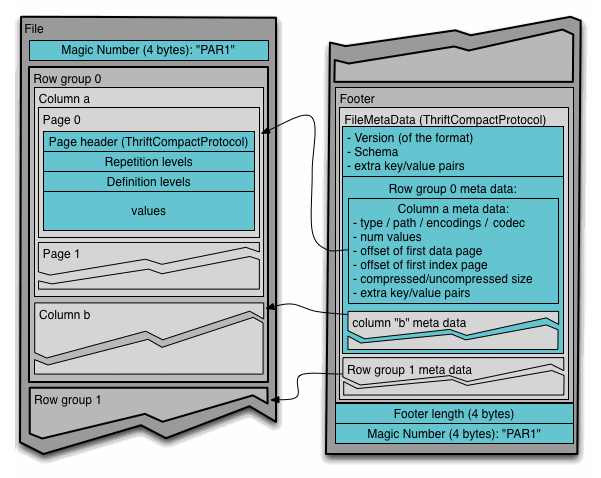
The above figure shows the contents of a Parquet file. Multiple line groups can be stored in a file. The first part of the file is the Magic Code of the file, which is used to verify whether it is a Parquet file. Footer length records the size of the file metadata. The offset of the metadata can be calculated from this value and the file length, The metadata of the file includes the metadata information of each row group and the Schema information of the data stored in the file. In addition to the metadata of each row group in the file, the metadata of the page is stored at the beginning of each page. In Parquet, there are three types of pages: data page, dictionary page and index page. The data page is used to store the value of the column in the current row group. The dictionary page stores the encoding Dictionary of the column value. Each column block contains at most one dictionary page. The index page is used to store the index of the column under the current row group. At present, the index page is not supported in Parquet.
4.5 comparison of mainstream file storage formats
The compression ratio of stored files and query speed are compared.
Compression ratio test of stored files:
-
test data

-
TextFile
-
Create a table and store data in TextFile format
create table log_text ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as textfile;
-
Loading data into a table
load data local inpath '/opt/module/hive/datas/log.data' into table log_text ;
-
View data size in table
dfs -du -h /user/hive/warehouse/log_text; # 18.13 M /user/hive/warehouse/log_text/log.data
-
-
ORC
-
Create a table and store data in ORC format
create table log_orc( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as orc tblproperties("orc.compress"="NONE"); -- set up orc Storage does not use compression -
Loading data into a table
insert into table log_orc select * from log_text;
-
View data size in table
dfs -du -h /user/hive/warehouse/log_orc/ ; # 7.7 M /user/hive/warehouse/log_orc/000000_0
-
-
Parquet
-
Create a table and store data in parquet format
create table log_parquet( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as parquet;
-
Loading data into a table
insert into table log_parquet select * from log_text;
-
View data size in table
dfs -du -h /user/hive/warehouse/log_parquet/; # 13.1 M /user/hive/warehouse/log_parquet/000000_0
-
Comparison summary of stored files: orc > parquet > textfile
Query speed test of stored files:
-
TextFile
insert overwrite local directory '/opt/module/data/log_text' select substring(url,1,4) from log_text;
-
ORC
insert overwrite local directory '/opt/module/data/log_orc' select substring(url,1,4) from log_orc;
-
Parquet
insert overwrite local directory '/opt/module/data/log_parquet' select substring(url,1,4) from log_parquet;
Summary of query speed of stored files: the query speed is similar.
5, Combination of storage and compression
Test storage and compression
Official website: https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
Compression of ORC storage mode:
Note: all parameters about ORCFile appear in the TBLPROPERTIES field of HQL statement
- Create a ZLIB compressed ORC storage method
create table log_orc_zlib(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="ZLIB");
insert into log_orc_zlib select * from log_text;
dfs -du -h /user/hive/warehouse/log_orc_zlib/ ;
# 2.78 M /user/hive/warehouse/log_orc_none/000000_0
- Create a SNAPPY compressed ORC storage method
create table log_orc_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as orc
tblproperties("orc.compress"="SNAPPY");
insert into log_orc_snappy select * from log_text;
dfs -du -h /user/hive/warehouse/log_orc_snappy/;
# 3.75 M /user/hive/warehouse/log_orc_snappy/000000_0
ZLIB is smaller than snappy compression. The reason is that ZLIB adopts deflate compression algorithm. Higher compression ratio than snappy compression.
- Create a snapshot compressed parquet storage method
create table log_parquet_snappy(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
row format delimited fields terminated by '\t'
stored as parquet
tblproperties("parquet.compression"="SNAPPY");
insert into log_parquet_snappy select * from log_text;
dfs -du -h /user/hive/warehouse/log_parquet_snappy/;
# 6.39 MB /user/hive/warehouse/ log_parquet_snappy /000000_0
- Storage mode and compression summary
In the actual project development, the data storage format of hive table is generally orc or parquet. Generally, snappy and lzo are selected for compression.