Hive supports the following formats for storing data: TEXTFILE (row storage), sequencefile (row storage), ORC (column storage) and PARQUET (column storage)
1: Column storage and row storage
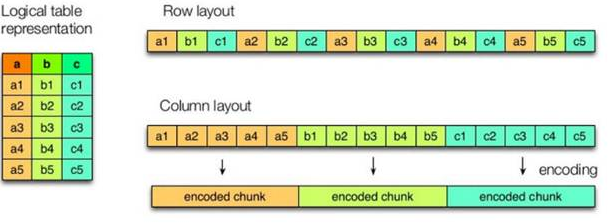
The left side of the figure above is a logical table, the first one on the right is row storage, and the second one is column storage.
The storage formats of TEXTFILE and SEQUENCEFILE are based on row storage.
ORC and PARQUET are based on column storage.
1: Characteristics of row storage
When querying a whole row of data that meets the conditions, the column storage needs to find the corresponding value of each column in each aggregated field. The row storage only needs to find one value, and the rest values are in adjacent places, so the row storage query speed is faster.
2: Characteristics of column storage
Because the data of each field is aggregated and stored, the amount of data read can be greatly reduced when only a few fields are required for query.
The data type of each field must be the same. Column storage can be targeted to design better compression algorithms. select some fields are more efficient.
2: TEXTFILE format
In the default format, data is not compressed, resulting in high disk overhead and high data parsing overhead. It can be used in combination with gzip and Bzip2 (the system automatically checks and automatically decompresses when executing queries), but with gzip, hive will not segment the data, so it is impossible to operate the data in parallel.
3: ORC format
Orc (Optimized Row Columnar) is a new storage format introduced in hive version 0.11.
You can see that each Orc file is composed of one or more strings, each of which is 250MB in size. This stripe is actually equivalent to the RowGroup concept, but the size is 4MB - > 250MB, which can improve the throughput of sequential reading. Each stripe consists of three parts: index data, row data and stripe footer:
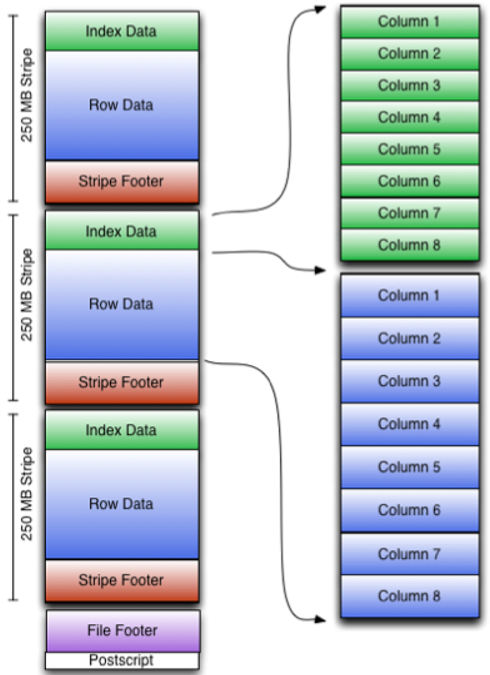
An orc file can be divided into several strips
A stripe can be divided into three parts
indexData: index data for some columns
rowData: real data storage
StripFooter: metadata information of stripe
1) Index Data: a lightweight index. By default, an index is made every 1W rows. The index here only records the offset of each field of a row in Row Data.
2) Row Data: specific data is stored. Take some rows first, and then store these rows by column. Each column is encoded and divided into multiple streams for storage.
3) Stripe Footer: stores the metadata information of each stripe.
Each file has a File Footer, where the number of rows of each Stripe and the data type information of each Column are stored.
At the end of each file is a PostScript, which records the compression type of the whole file and the length information of FileFooter. When reading a file, you will seek to read PostScript at the end of the file, parse the length of File Footer from the inside, read FileFooter again, parse the information of each Stripe from the inside, and then read each Stripe, that is, read from back to front.
4: PARQUET format
Parquet is a columnar storage format for analytical business. It was jointly developed by Twitter and Cloudera. In May 2015, parquet graduated from the Apache incubator and became the top project of Apache.
Parquet file is stored in binary mode, so it can not be read directly. The file includes the data and metadata of the file. Therefore, parquet format file is self parsed.
Generally, when storing Parquet data, the size of row groups will be set according to the Block size. Generally, the minimum unit of data processed by each Mapper task is a Block, so each row group can be processed by one Mapper task to increase the parallelism of task execution. The format of Parquet file is shown in the following figure.
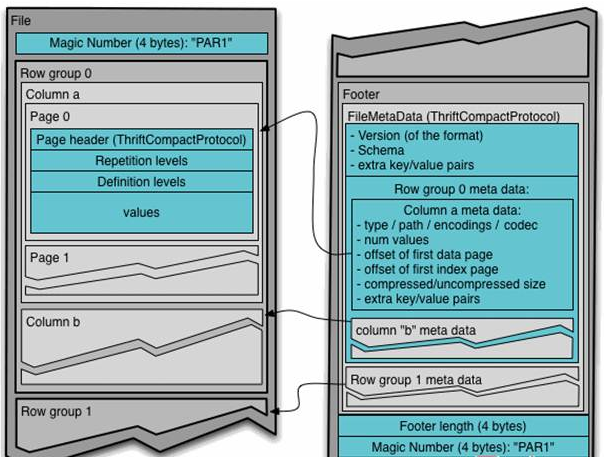
The above figure shows the contents of a Parquet file. Multiple line groups can be stored in a file. The first part of the file is the Magic Code of the file, which is used to verify whether it is a Parquet file. Footer length records the size of the file metadata. The offset of the metadata can be calculated from this value and the file length, The metadata of the file includes the metadata information of each row group and the Schema information of the data stored in the file. In addition to the metadata of each row group in the file, the metadata of the page is stored at the beginning of each page. In Parquet, there are three types of pages: data page, dictionary page and index page. The data page is used to store the value of the column in the current row group. The dictionary page stores the encoding Dictionary of the column value. Each column block contains at most one dictionary page. The index page is used to store the index of the column under the current row group. At present, the index page is not supported in Parquet.
5: Comparison experiment of mainstream file storage formats
The compression ratio of stored files and query speed are compared.
Compression ratio test of stored files
1: TextFile
(1) Create a table and store data in TEXTFILE format
use myhive; create table log_text ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string )ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE ;
(2) Loading data into a table
load data local inpath '/install/hivedatas/log.data' into table log_text ;
(3) Check the data size in the table. The size is 18.1M
0: jdbc:hive2://node03:10000> dfs -du -h /user/hive/warehouse/myhive.db/log_text; 18.1 M /user/hive/warehouse/log_text/log.data
2: ORC
(1) Create a table and store data in ORC format
create table log_orc( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS orc ;
(2) Loading data into a table
insert into table log_orc select * from log_text ;
(3) View data size in table
dfs -du -h /user/hive/warehouse/myhive.db/log_orc; 2.8 M /user/hive/warehouse/log_orc/123456_0
The orc storage format uses = = zlib compression = = by default to compress the data, so the data will become 2.8M, which is very small
3: Parquet
(1) Create a table and store data in parquet format
create table log_parquet( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS PARQUET ;
(2) Loading data into a table
insert into table log_parquet select * from log_text ;
(3) View data size in table
dfs -du -h /user/hive/warehouse/myhive.db/log_parquet; 13.1 M /user/hive/warehouse/log_parquet/123456_0
Conclusion: the compression ratio of stored files
ORC > Parquet > textFile
Query speed test of stored files:
1)TextFile hive (default)> select count(*) from log_text; _c0 100000 Time taken: 21.54 seconds, Fetched: 1 row(s) 2)ORC hive (default)> select count(*) from log_orc; _c0 100000 Time taken: 20.867 seconds, Fetched: 1 row(s) 3)Parquet hive (default)> select count(*) from log_parquet; _c0 100000 Time taken: 22.922 seconds, Fetched: 1 row(s) Summary of query speed of stored files: ORC > TextFile > Parquet