1. System built-in functions
(1) View the functions provided by the system
show functions;
(2) Displays the usage of the built-in function
desc function upper;
(3) Displays the usage of the built-in function in detail
desc function extended upper;
2. Common built-in functions
2.1 empty field assignment
(1) Function description
NVL: assign a value to the data whose value is NULL. Its format is NVL (value, default_value). Its function is to return default if value is NULL_ Value, otherwise return the value of value. If both parameters are NULL, return NULL.
(2) Data preparation: use employee table
(3) Query: if the comm of the employee is NULL, use - 1 instead
select comm,nvl(comm, -1) from emp;
(4) Query: if the comm of the employee is NULL, the leader id will be used instead
select comm, nvl(comm,mgr) from emp;
2.2 CASE WHEN
(1) Data preparation
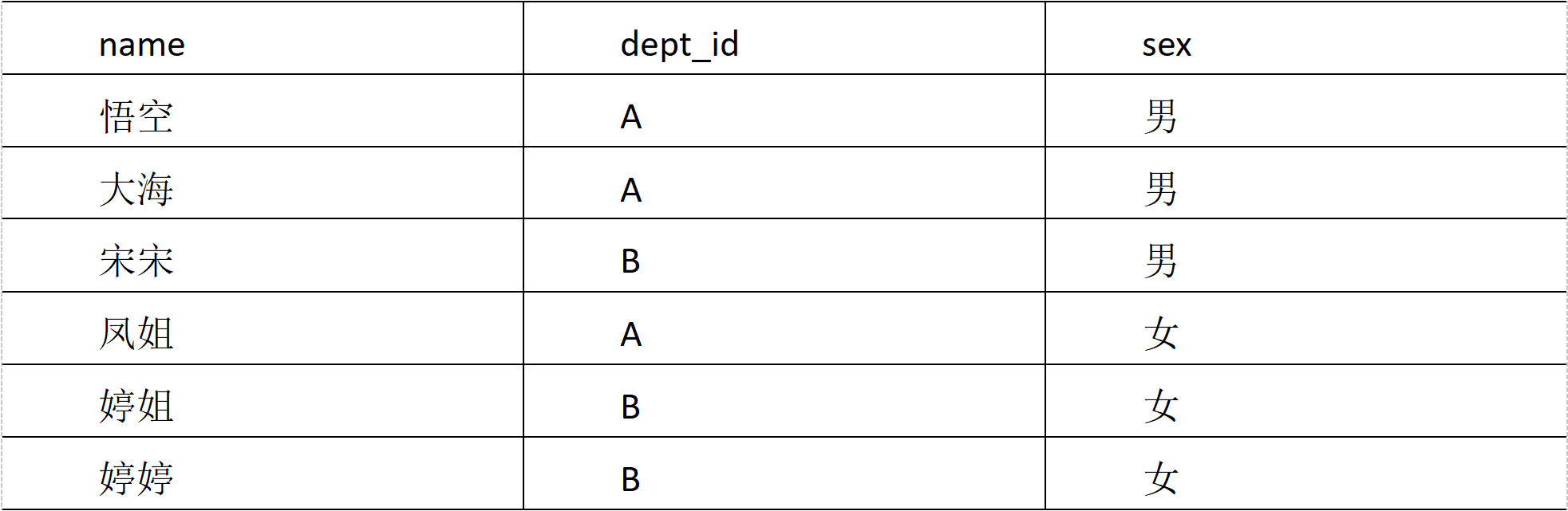
(2) Demand
Find out the number of men and women in different departments. The results are as follows:
A 2 1 B 1 2
(3) Create local emp_sex.txt, import data
vim emp_sex.txt #Add data name of a fictitious monkey with supernatural powers A male sea A male Song song B male Miss Luo Yu feng A female Sister Ting B female Tingting B female
(4) Create hive table and import data
#Create Hive table create table emp_sex( name string, dept_id string, sex string) row format delimited fields terminated by "\t"; #Import data load data inpath '/mario/hive/7/emp_sex.txt' into table emp_sex;
(5) Query data by demand
select dept_id, sum(case sex when 'male' then 1 else 0 end) male_count, sum(case sex when 'female' then 1 else 0 end) female_count from emp_sex group by dept_id;
2.3 line transfer
(1) Description of correlation function
CONCAT(string A/col, string B/col...): returns the result of connecting input strings. Any input string is supported;
CONCAT_WS(separator, str1, str2,...): it is a special form of CONCAT(). The first parameter is the separator between the remaining parameters. The delimiter can be the same string as the remaining parameters. If the delimiter is NULL, the return value will also be NULL. This function skips any NULL and empty strings after the delimiter parameter. The separator will be added between the connected strings;
COLLECT_SET(col): the function only accepts basic data types. Its main function is to de summarize the values of a field and generate an array type field.
(2) Data preparation
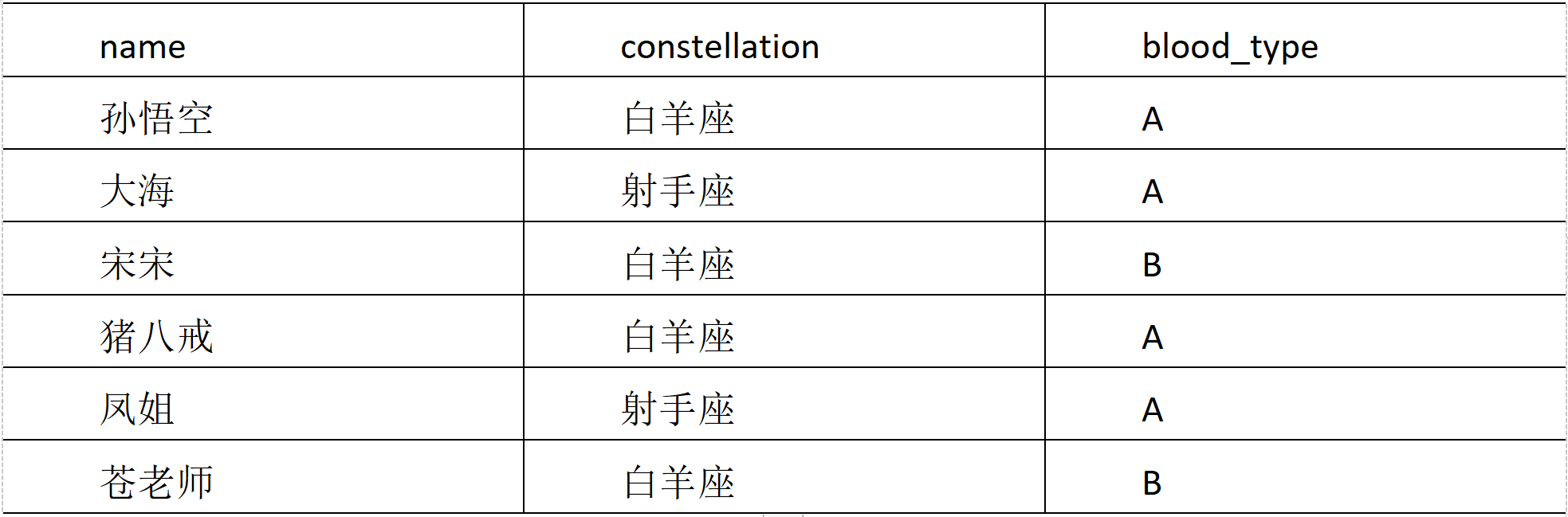
(3) Demand
Classify people with the same constellation and blood type. The results are as follows:
sagittarius,A sea|Miss Luo Yu feng Aries,A Sun WuKong|Zhu Bajie Aries,B Song song|Aoi Sora
(4) Create a local constellation Txt, import data
vim constellation.txt #Add data Sun WuKong Aries A sea sagittarius A Song song Aries B Zhu Bajie Aries A Miss Luo Yu feng sagittarius A
(5) Create hive table and import data
#Create Hive table create table person_info( name string, constellation string, blood_type string) row format delimited fields terminated by "\t"; #Import data load data inpath "/mario/hive/7/constellation.txt" into table person_info;
(6) Query data by demand
select
t1.base,
concat_ws('|', collect_set(t1.name)) name
from
(select
name,
concat(constellation, ",", blood_type) base
from
person_info) t1
group by
t1.base;
2.4 column to row
(1) Function description
Expand (Col): split the complex array or map structure in the hive column into multiple rows.
LATERAL VIEW
Usage: final view udtf (expression) tablealias as columnalias
Explanation: used with split, expand and other udtfs. It can split a column of data into multiple rows of data. On this basis, it can aggregate the split data.
(2) Data preparation

(3) Demand
Expand the array data in the movie category. The results are as follows:
<Suspect tracking Suspense <Suspect tracking action <Suspect tracking science fiction <Suspect tracking plot <Lie to me> Suspense <Lie to me> gangster <Lie to me> action <Lie to me> psychology <Lie to me> plot <War wolf 2 Warfare <War wolf 2 action <War wolf 2 disaster
(4) Create local movie Txt, import data
vim movie.txt #Add data <Suspect tracking Suspense,action,science fiction,plot <Lie to me> Suspense,gangster ,action,psychology,plot <War wolf 2 Warfare,action,disaster
(5) Create hive table and import data
#Create Hive table create table movie_info( movie string, category string) row format delimited fields terminated by "\t"; #Import data load data local inpath "/opt/module/datas/movie.txt" into table movie_info;
(6) Query data by demand
select m.movie, tbl.cate from movie_info m lateral view explode(split(category, ",")) tbl as cate;
2.5 window function (windowing function)
(1) Description of correlation function
**OVER(): * * specifies the data window size of the analysis function. The data window size may change with the change of rows.
**CURRENT ROW: * * CURRENT ROW
**N predicting: * * n rows of data before
**n FOLLOWING: * * next n rows of data
**UNBOUNDED: * * starting point, UNBOUNDED predicting indicates the starting point from the front, UNBOUNDED FOLLOWING indicates the end point from the back
**LAG(col,n,default_val): * * data in the nth row ahead
**LEAD(col,n, default_val): * * data in the next nth row
**NTILE(n): * * distribute the rows of the ordered window to the groups of the specified data. Each group has a number, starting from 1. For each row, NTILE returns the number of the group to which the row belongs. Note: n must be of type int.
(2) Data preparation: name, orderdate, cost
jack,2017-01-01,10 tony,2017-01-02,15 jack,2017-02-03,23 tony,2017-01-04,29 jack,2017-01-05,46 jack,2017-04-06,42 tony,2017-01-07,50 jack,2017-01-08,55 mart,2017-04-08,62 mart,2017-04-09,68 neil,2017-05-10,12 mart,2017-04-11,75 neil,2017-06-12,80 mart,2017-04-13,94
(3) Demand
- Query the customers and total number of people who purchased in April 2017
- Query the customer's purchase details and monthly total purchase amount
- In the above scenario, the cost of each customer is accumulated according to the date
- Query the last purchase time of each customer
- Order information 20% before query
(4) Create local business Txt, import data
vi business.txt
(5) Create hive table and import data
#Create Hive table create table business( name string, orderdate string, cost int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; #Load data load data inpath "/mario/hive/7/business.txt" into table business;
(6) Query data by demand
Query the customers and total number of people who purchased in April 2017
select name,count(*) over () from business where substring(orderdate,1,7) = '2017-04' group by name;
Query the customer's purchase details and monthly total purchase amount
select name,orderdate,cost,sum(cost) over(partition by month(orderdate)) from business;
In the above scenario, the cost of each customer is accumulated according to the date
select name,orderdate,cost, sum(cost) over() as sample1,--Add all rows sum(cost) over(partition by name) as sample2,--Press name Grouping, intra group data addition sum(cost) over(partition by name order by orderdate) as sample3,--Press name Grouping, intra group data accumulation sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--and sample3 equally,Aggregation from starting point to current row sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --Aggregate the current row with the previous row sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--The current line and the previous and subsequent lines sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --Current line and all subsequent lines from business;
Rows must follow the Order by clause to limit the sorting results, and use a fixed number of rows to limit the number of data rows in the partition
View the customer's last purchase time
SELECT name,
orderdate,
cost,
lag(orderdate,1,'1900-01-01') over(partition BY name
ORDER BY orderdate) AS time1
FROM business;
Order information 20% before query
select * from ( select name,orderdate,cost, ntile(5) over(order by orderdate) sorted from business ) t where sorted = 1;
2.6 Rank
(1) Function description
If RANK() sorting is the same, it will be repeated, and the total number will not change
DENSE_ If rank() sorting is the same, it will be repeated and the total number will be reduced
ROW_NUMBER() is calculated in order
(2) Data preparation
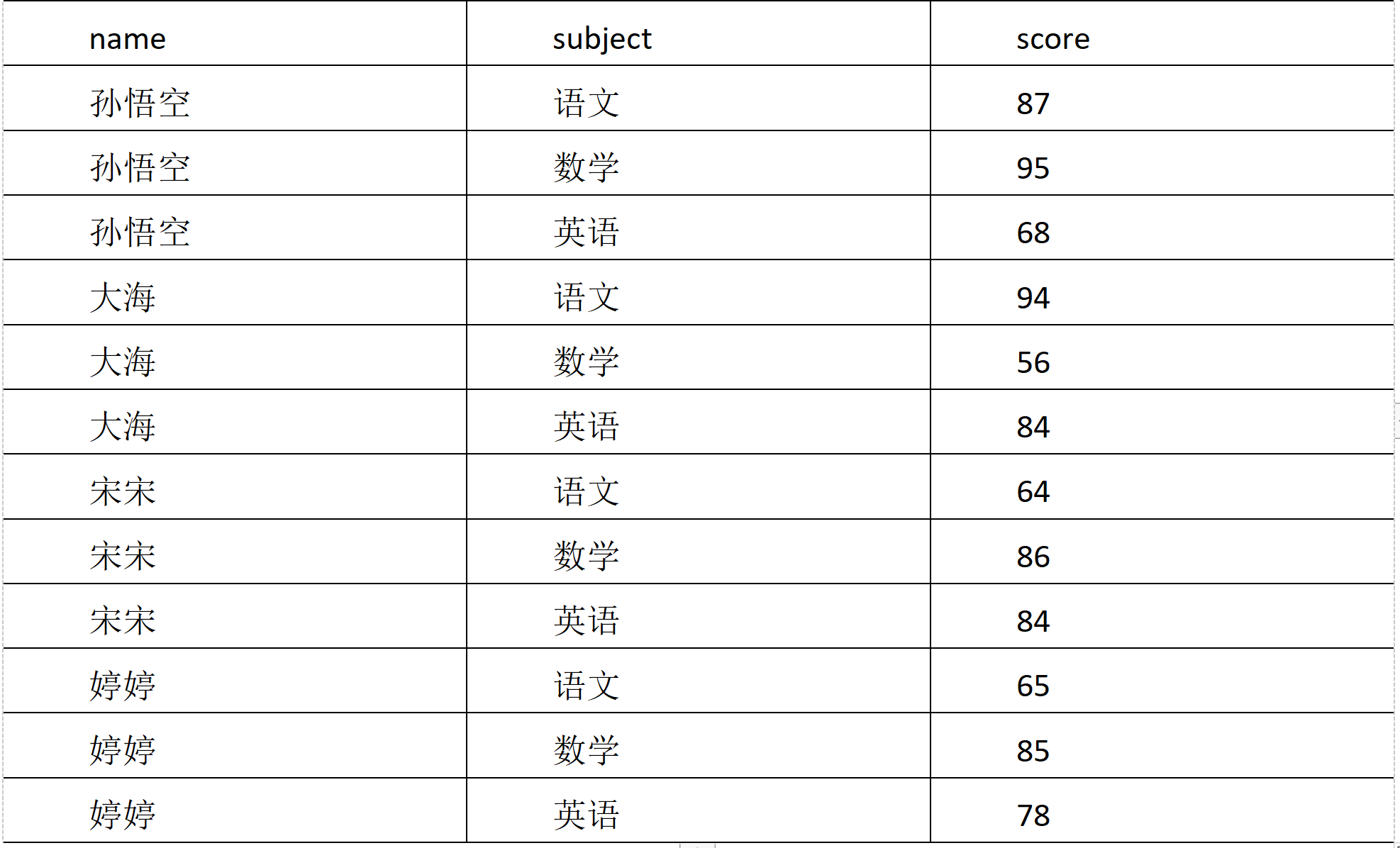
(3) Demand
Calculate the score ranking of each subject.
(4) Create local score Txt, import data
vi score.txt
(5) Create hive table and import data
#Create Hive table create table score( name string, subject string, score int ) row format delimited fields terminated by "\t"; #Load data load data inpath '/mario/hive/7/score.txt' into table score;
(6) Query data by demand
SELECT name,
subject,
score,
rank() over(partition BY subject
ORDER BY score DESC) rp,
dense_rank() over(partition BY subject
ORDER BY score DESC) drp,
row_number() over(partition BY subject
ORDER BY score DESC) rmp
FROM score;
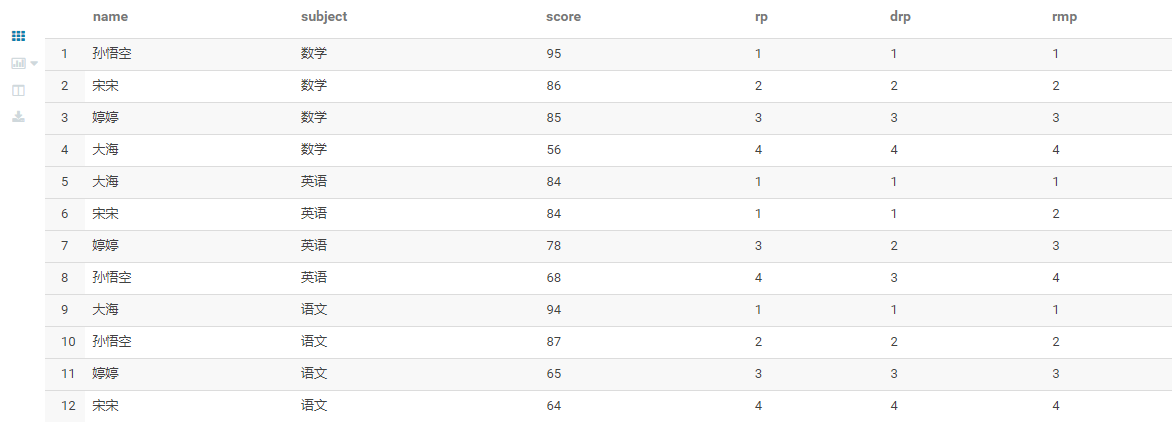
Extension: find the top three students in each subject?
2.7 date correlation function
(1)current_date returns the current date
select current_date();
(2)date_ add, date_ Addition and subtraction of sub date
#Date 90 days from today select date_add(current_date(), 90); #Date 90 days before today select date_sub(current_date(), 90);
(3) Date difference between two dates
#The difference between today and June 4, 1990 SELECT datediff(CURRENT_DATE(), "1990-06-04");
3. User defined functions
(1) Hive comes with some functions, such as max/min, but the number is limited. You can easily expand it by customizing UDF.
(2) When the built-in function provided by Hive cannot meet your business processing needs, you can consider using user-defined function (UDF).
(3) There are three types of user-defined functions:
UDF(User-Defined-Function)
One in and one out
UDAF(User-Defined Aggregation Function)
Aggregate function, one more in and one out
Similar to: count/max/min
UDTF(User-Defined Table-Generating Functions)
One in and many out
Such as lateral view explore()
(4) Official document address
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
(5) Programming steps:
Inherit org apache. hadoop. hive. ql.exec. UDF
You need to implement the evaluate function; The evaluate function supports overloading;
Create a function in hive's command line window
Add jar
add jar linux_jar_path
Create function
create [temporary] function [dbname.]function_name AS class_name;
d. delete the function in the command line window of hive
Drop [temporary] function [if exists] [dbname.]function_name;
(6) Note: UDF must have a return type, which can return null, but the return type cannot be void;
4. Customize UDF functions
(1) Create a Maven project Hive
(2) Import dependency
<dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hive/hive-exec --> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>3.1.2</version> </dependency> </dependencies>
(3) Create a class
package com.atguigu.hive;
import org.apache.hadoop.hive.ql.exec.UDF;
public class Lower extends UDF {
public String evaluate (final String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}
(4) Upload the jar package to the server / opt / module / jars / UDF jar
(5) Add the jar package to hive's classpath
add jar /opt/module/datas/udf.jar;
(6) Create a temporary function associated with the developed java class
create temporary function mylower as "com.atguigu.hive.Lower";
(7) You can use the custom function strip in hql
select ename, mylower(ename) lowername from emp;