In this article, we mainly learn about the performance of SORT BY, ORDER BY, DISTRIBUTE BY and CLUSTER BY in Hive.
First, prepare the test data:
CREATE TABLE IF NOT EXISTS tmp_sport_user_step_1d(
dt STRING COMMENT 'dt',
uid STRING COMMENT 'uid',
step INT COMMENT 'sport step'
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
LINES TERMINATED BY '\n';
INSERT INTO TABLE tmp_sport_user_step_1d (dt, uid, step) VALUES
('20211123', 'a1', 100),
('20211123', 'a2', 200),
('20211123', 'a3', 300),
('20211123', 'a4', 400),
('20211123', 'a5', 500),
('20211123', 'a6', 600),
('20211123', 'a7', 700),
('20211123', 'a8', 800),
('20211123', 'a9', 900),
('20211124', 'a1', 900),
('20211124', 'a2', 800),
('20211124', 'a3', 700),
('20211124', 'a4', 600),
('20211124', 'a5', 500),
('20211124', 'a6', 400),
('20211124', 'a7', 300),
('20211124', 'a8', 200),
('20211124', 'a9', 100);1. Order By
In Hive, ORDER BY ensures the global order of data. Therefore, all data is sent to a Reducer. Because there is only one Reducer, it takes a long time to calculate when the input scale is large. The ORDER BY syntax in Hive is similar to that in SQL. The output is sorted according to one or more items. You can specify ascending or descending sorting:
SELECT uid, step FROM tmp_sport_user_step_1d ORDER BY step DESC;
The operation results are as follows:
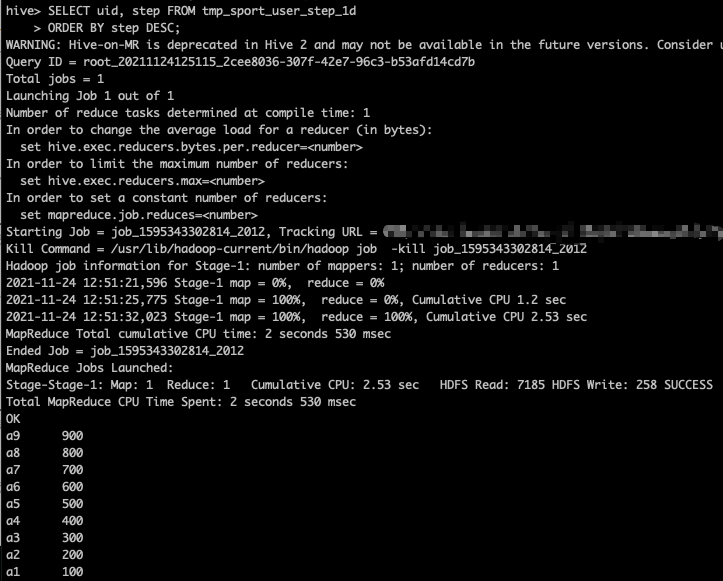
The ORDER BY clause has some limitations: In strict mode, i.e. hive mapred. Mode = strict, the ORDER BY clause must be followed by a LIMIT clause. If hive mapred. If mode is set to nonstrict, the LIMIT clause can be omitted. The reason is that in order to achieve global ordering of all data, only one reducer can be used to sort the final output. If the number of rows in the output is too large, a single reducer may take a long time to complete. If the LIMIT clause is not specified in strict mode, the following error will be reported:
hive> set hive.mapred.mode=strict; hive> select * from adv_push_click order by click_time; FAILED: SemanticException 1:47 order by-s without limit are disabled for safety reasons. If you know what you are doing, please make sure that hive.strict.checks.large.query is set to false and that hive.mapred.mode is not set to 'strict' to enable them.. Error encountered near token 'click_time'
hive.mapred.mode is hive 0.3 0 version is added. The default values are as follows:
- Hive 0.x: nonstrict
- Hive 1.x: nonstrict
- Hive 2.x: strict (HIVE-12413)
Notice that the columns are specified by name, not by location number. At hive 0.11 0 and later, when the following configurations are implemented, columns can be specified by location:
- For hive 0.11 0 to 2.1 x. Set hive groupby. orderby. position. Alias is set to true (the default value is false).
- For hive 2.2 0 and later, hive orderby. position. Alias defaults to true.
2. Sort By
If there are too many rows in the output, a single Reducer may take a long time to complete. Hive adds an alternative method, SORT BY, which only sorts the data in each Reducer, that is, performs a local sort. This can ensure that the output data of each Reducer is ordered (but not globally). This can improve the efficiency of global sorting later.
SORT BY syntax is similar to ORDER BY syntax, except that one keyword is ORDER and the other keyword is SORT. You can specify any field to SORT, and add ASC keyword (default) after the field to SORT in ascending ORDER, or add DESC keyword to SORT in descending ORDER:
SET mapreduce.job.reduces = 3; SELECT uid, step FROM tmp_sport_user_step_1d SORT BY step;
The sort order will depend on the column type. If the column is numeric, the sort order is also numeric; If the column is of string type, the sort order is dictionary order.
As shown above, we set up three reducers to SORT BY according to the step of motion steps (if there is only one Reducer, the function is the same as ORDER BY to realize global sorting). The operation results are as follows:
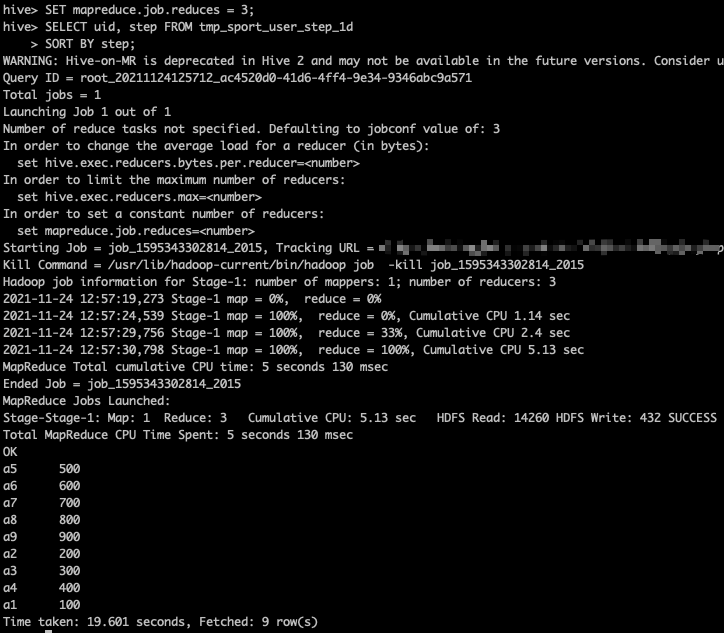
From the above output, we can see that the overall output is disordered, and it is impossible to judge whether a single Reducer is orderly. Therefore, we output the data to a file:
SET mapreduce.job.reduces = 3; INSERT OVERWRITE DIRECTORY '/user/hadoop/temp/study/tmp_sport_user_step_1d_sort_by' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' SELECT uid, step FROM tmp_sport_user_step_1d SORT BY step;
Because we have set up three reducers, there will be three file outputs:
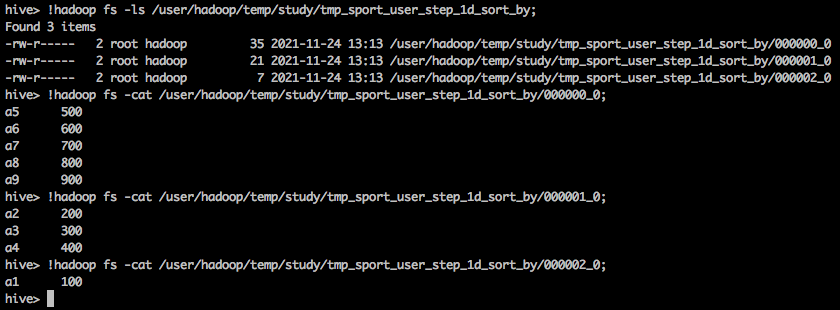
As can be seen from the above, the output of each Reducer is ordered, but there is no global order.
3. Distribute By
Distribution by can control how the Map side distributes data to the Reduce side, which is similar to the partition partitioner in MapReduce to partition data. Hive will distribute the data to the corresponding Reducer according to the column after distribution by. By default, the MapReduce calculation framework will calculate the corresponding hash value according to the key entered in the Map, and then evenly distribute the key value pairs to multiple reducers according to the obtained hash value. As shown below, we set three reducers to DISTRIBUTE BY according to the date dt:
SET mapreduce.job.reduces = 3; SELECT dt, uid, step FROM tmp_sport_user_step_1d DISTRIBUTE BY dt;
The operation results are as follows:
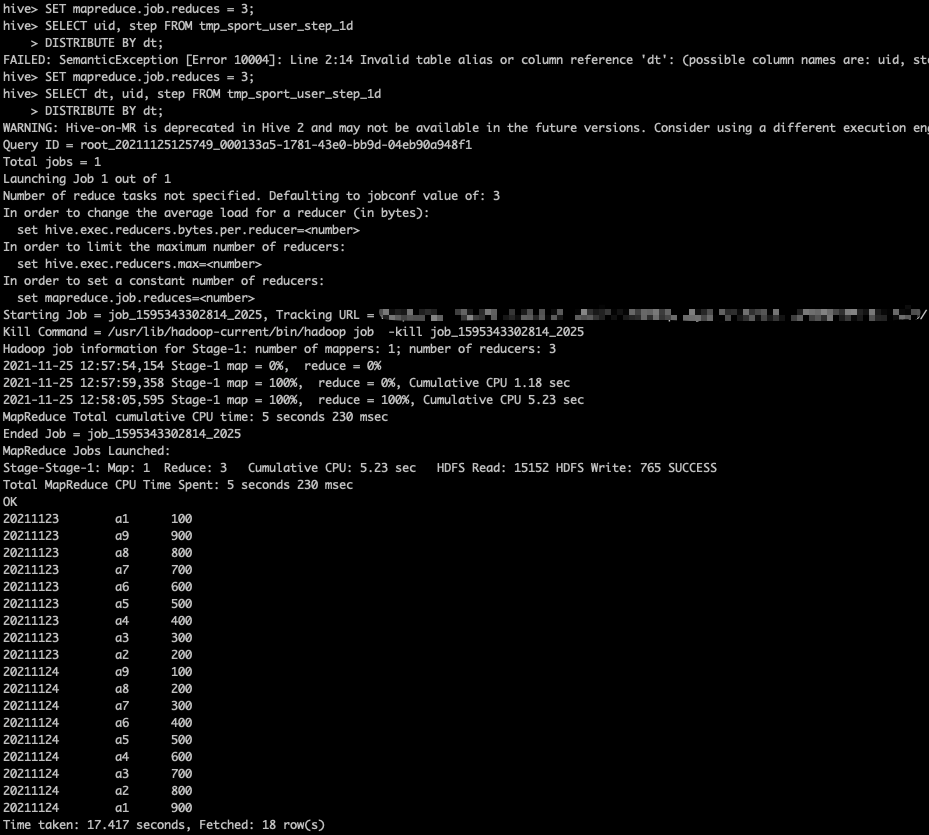
From the above output, we cannot judge whether the data of the same date is distributed to the same Reducer. Therefore, we output the data to the file:
SET mapreduce.job.reduces = 3; INSERT OVERWRITE DIRECTORY '/user/hadoop/temp/study/tmp_sport_user_step_1d_distribute_by' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' SELECT dt, uid, step FROM tmp_sport_user_step_1d DISTRIBUTE BY dt;
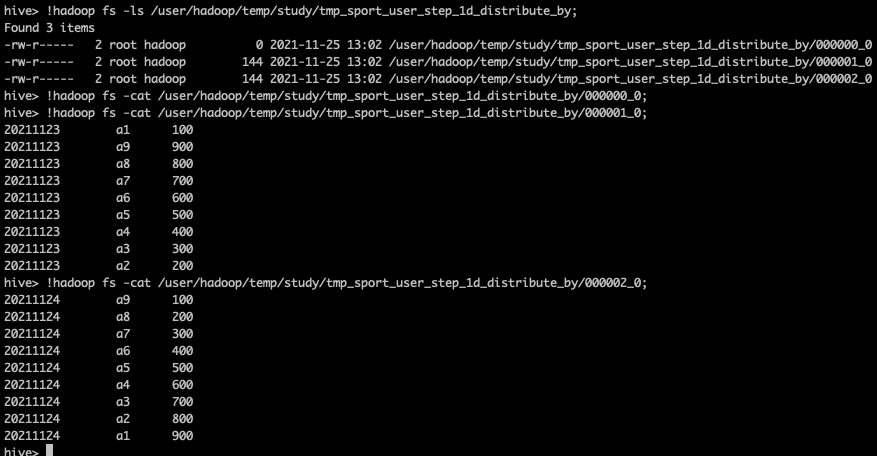
You can see from the above that data of the same date is distributed to the same Reducer. How can we sort the data in the same date in descending order according to the number of motion steps step? As shown below, DISTRIBUTE BY is performed according to the date dt, and SORT BY is performed according to the number of motion steps step:
SET mapreduce.job.reduces = 3; SELECT dt, uid, step FROM tmp_sport_user_step_1d DISTRIBUTE BY dt SORT BY step DESC;
The operation results are as follows:
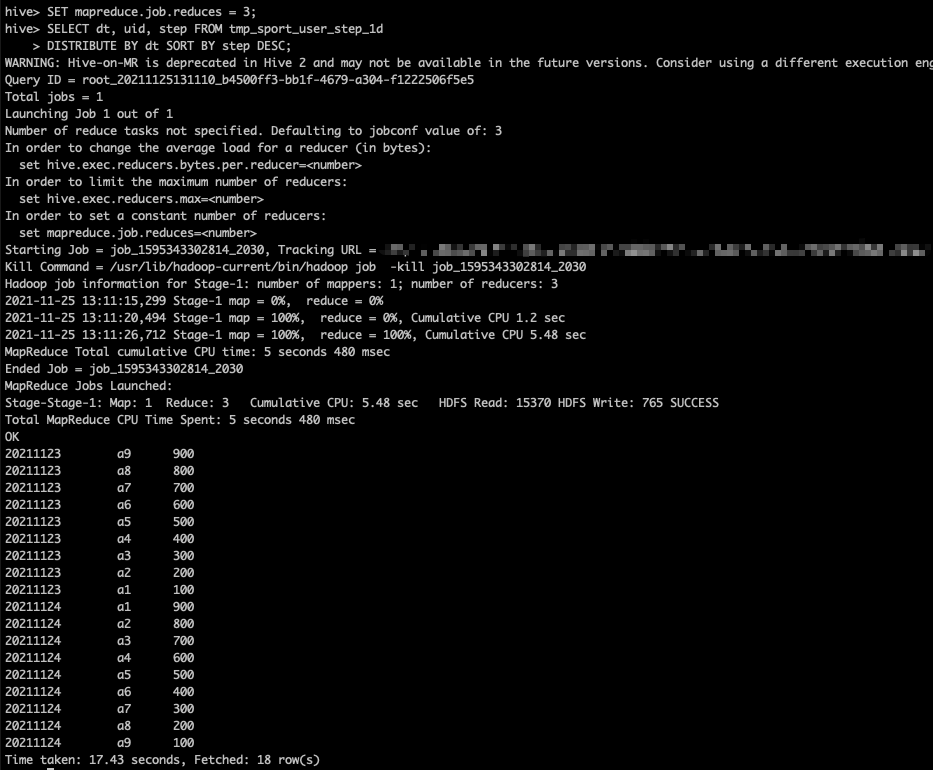
Let's export the data to a file to see how the data is distributed:
SET mapreduce.job.reduces = 3; INSERT OVERWRITE DIRECTORY '/user/hadoop/temp/study/tmp_sport_user_step_1d_distribute_by_sort_by' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' SELECT dt, uid, step FROM tmp_sport_user_step_1d DISTRIBUTE BY dt SORT BY step DESC;
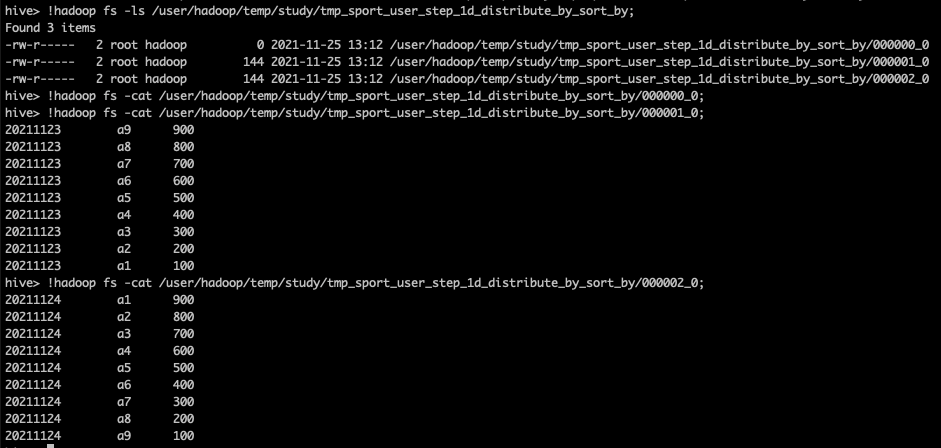
As can be seen from the above, the data of the same date are distributed to the same Reducer and sorted in descending order according to the step of motion steps.
4. Cluster By
In the previous example, the dt column was used in the DISTRIBUTE BY statement, while the step column was in the SORT BY statement. If the columns involved in these two statements are exactly the same, and the ascending sorting method (that is, the default sorting method) is adopted, then in this case, CLUSTER BY is equivalent to the previous two statements, which is a short form of the previous two sentences. As shown below, we only use CLUSTER BY statements for the step field:
SET mapreduce.job.reduces = 3; SELECT dt, uid, step FROM tmp_sport_user_step_1d CLUSTER BY step;
The operation results are as follows:
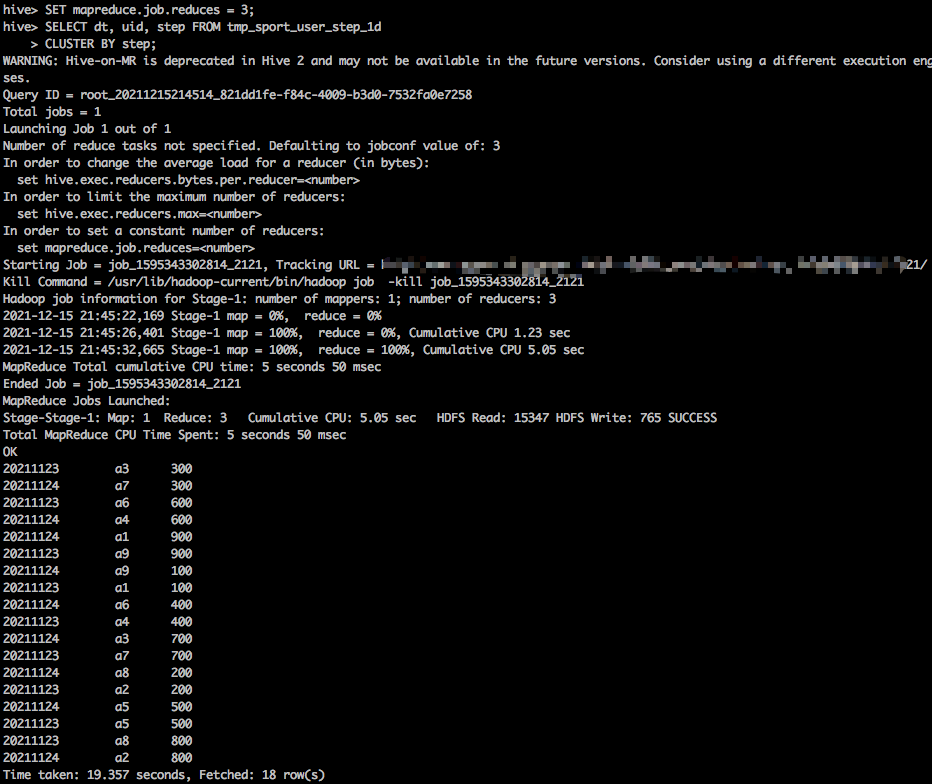
Let's export the data to a file to see how the data is distributed:
SET mapreduce.job.reduces = 3; INSERT OVERWRITE DIRECTORY '/user/hadoop/temp/study/tmp_sport_user_step_1d_cluster_by' ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' SELECT dt, uid, step FROM tmp_sport_user_step_1d CLUSTER BY step;
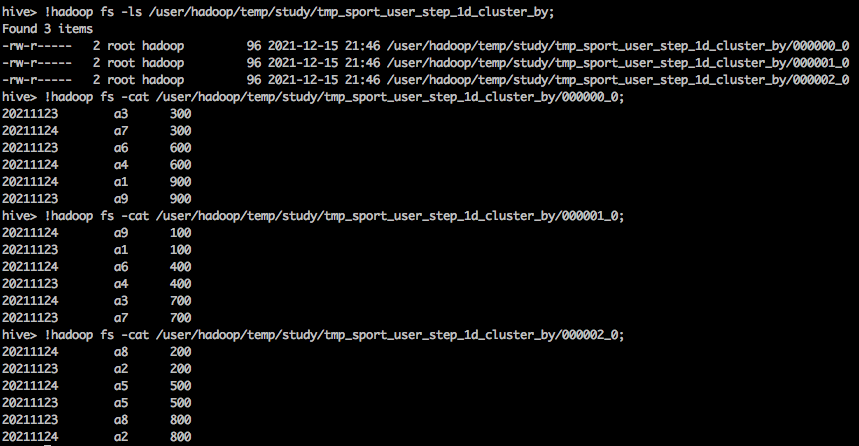
As can be seen from the above, the data of the same motion step is distributed to the same Reducer and sorted in ascending order.
reference resources: