1. Preface
This case is an online learning course purchased a long time ago. Recently, when I suddenly think of it, I realize to record it. Today, with the gradual flow of deep learning, the application of HOG+SVM custom object recognition may not be very large, but in a fixed scene, if the size of custom objects in the image is relatively constant, this method only needs less data sets to achieve good recognition effect. Evaluating the function of an algorithm should be combined with a specific scene. It is not objective to talk about the function without the scene.
2. HOG features
Difference between HOG and SIFT
Both HOG and SIFT are descriptors. Because there are many similar steps in specific operation, many people mistakenly believe that HOG is a kind of SIFT. In fact, there are great differences between the two in use purpose and specific processing details. The main differences between HOG and SIFT are as follows:
(1)SIFT is a description based on key point feature vector.
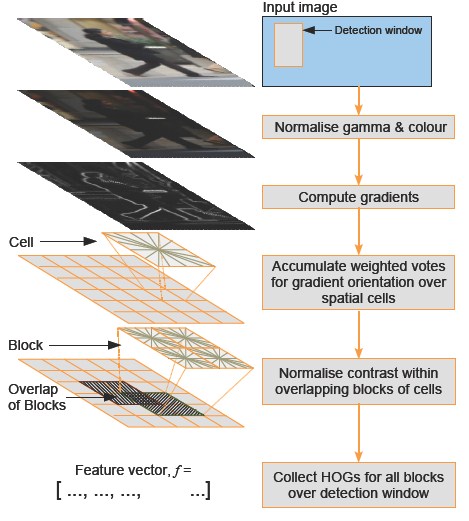
(2)HOG is to divide the image evenly into adjacent small blocks, and then count the gradient in all small blocks histogram.
(3)SIFT needs to find the extreme points of pixels in the image scale space, but not in HOG.
(4)SIFT generally has two steps. The first step extracts feature points from the image, while HOG does not extract feature points from the image.
Advantages and disadvantages of HOG:
(1)HOG represents the structural features of the edge (gradient), so it can describe the local shape information; (2) The quantization of position and direction space can suppress the influence of translation and rotation to a certain extent;
(3) The influence of illumination change can be partially offset by normalizing the histogram in the local area;
(4) Because the influence of illumination color on the image is ignored to a certain extent, the dimension of characterization data required by the image is reduced;
(5) Moreover, due to this block and unit processing method, the relationship between local pixels of the image can be well characterized. Disadvantages:
(1) The generation process of descriptor is lengthy, resulting in slow speed and poor real-time performance; (2) It is difficult to deal with occlusion; (3) Due to the nature of gradient, the descriptor is quite sensitive to noise.

3. Case description + code implementation
The training data is divided into positive sample set and negative sample set. The electricity meter in the positive sample set picture basically fills up the image, as shown below:

The negative sample image does not contain the meter image.
When calculating HOG, the positive sample image will be grayed -- resize (64128) -- to calculate the descriptor.
During the detection, the window sliding detection will be carried out on the test diagram, and the window size is (64128).
Let's go directly to the code. Pay attention to the annotation set. This code has many places worth optimizing, such as adding NMS to the prediction results. If more than two meters in the test image can not be detected effectively, but mechanically give the coordinate average value of several targets, we need to find a way to solve it. For example, we can use the idea of IOU intersection and parallel comparison. Data, I will not post resources temporarily.
Code (please note the comments):
// testOpencv.cpp: defines the entry point for the console application.
//
#include "stdafx.h"
#include <windows.h>
#include <time.h>
#include <opencv2/opencv.hpp>
#include <iostream>
#include <vector>
using namespace cv;
using namespace cv::ml;
using namespace std;
//Relative path of positive sample picture
string positive_dir = "elec_watch/positive";
//Negative sample picture relative path
string negative_dir = "elec_watch/negative";
//Calculate HOG descriptor
void get_hog_descriptor(const Mat &image, vector<float> &desc);
//Generate training data sets and labels
void generate_dataset(Mat &trainData, Mat &labels);
//SVM classifier training
void svm_train(Mat &trainData, Mat &labels);
#define FIXED_WIDTH 64
#define FIXED_HEIGHT 128
struct PredictResult
{
Rect rect;
float score;
static bool LessThan(PredictResult a, PredictResult b)
{
return a.score < b.score;
}
};
int main(int argc, char** argv)
{
// read data and generate dataset
// How did 3780 come from?
//The window size is 64 * 128 and the cell size is 8 * 8, so the window is divided into (64 / 8) * (128 / 8) cell blocks,
//Every 4 (2 * 2) cell blocks are a block, with a total of (64 / 8 - 1) * (128 / 8 - 1) sliding block combinations, and each block generates 36 descriptors,
//So the total descriptor size is 7 * 15 * 36 = 3780
//Mat trainData = Mat::zeros(Size((FIXED_WIDTH / 8 - 1)*(FIXED_HEIGHT / 8 - 1)*36, 26), CV_32FC1);//26 pictures (10 positive samples and 16 negative samples)
//Mat labels = Mat::zeros(Size(1, 26), CV_32SC1);
//generate_dataset(trainData, labels);
//
SVM train, and save model
//svm_train(trainData, labels);
// load model
Ptr<SVM> svm = SVM::load("hog_elec.xml");
// detect custom object test picture
Mat test = imread("elec_watch/test/scene_06-02.jpg");
//zoom
resize(test, test, Size(0, 0), 0.2, 0.2);
imshow("input", test);
Rect winRect;
winRect.width = FIXED_WIDTH;
winRect.height = FIXED_HEIGHT;
int sum_x = 0;
int sum_y = 0;
int count = 0;
vector<PredictResult> predictResultVec;
// Open (slide) window detection The window size is 64(w)*128(h)
for (int row = FIXED_HEIGHT / 2; row < test.rows - FIXED_HEIGHT / 2; row += 4)
{
for (int col = FIXED_WIDTH / 2; col < test.cols - FIXED_WIDTH / 2; col += 4)
{
winRect.x = col - FIXED_WIDTH / 2;//Top left corner x
winRect.y = row - FIXED_HEIGHT / 2;//Upper left corner y
//Get HOG descriptor
vector<float> fv;
get_hog_descriptor(test(winRect), fv);
//Fills the HOG descriptor in the specified format
Mat one_row = Mat::zeros(Size(fv.size(), 1), CV_32FC1);
for (int i = 0; i < fv.size(); i++)
{
one_row.at<float>(0, i) = fv[i];
}
//forecast
float result = svm->predict(one_row);
if (result > 0)
{
//rectangle(test, winRect, Scalar(0, 0, 255), 1, 8, 0);
count += 1;
sum_x += winRect.x;
sum_y += winRect.y;
PredictResult tmp;
tmp.rect = winRect;
tmp.score = result;
predictResultVec.push_back(tmp);
}
}
}
sort(predictResultVec.begin(), predictResultVec.end(), PredictResult::LessThan);
// Display box (average)
winRect.x = sum_x / count;
winRect.y = sum_y / count;
rectangle(test, winRect, Scalar(255, 0, 0), 2, 8, 0);
Instead, find the largest, not the average
//rectangle(test, predictResultVec[0].rect, Scalar(255, 0, 0), 2, 8, 0);
imshow("object detection result", test);
//imwrite("D:/case02.png", test);
waitKey(0);
return 0;
}
void get_hog_descriptor(const Mat &image, vector<float> &desc)
{
HOGDescriptor hog;
int h = image.rows;
int w = image.cols;
//Ensure scaling without distortion
float rate = FIXED_WIDTH*1.0 / w;
Mat img, gray;
resize(image, img, Size(FIXED_WIDTH, int(rate*h)));
cvtColor(img, gray, COLOR_BGR2GRAY);
Mat result = Mat::zeros(Size(FIXED_WIDTH, FIXED_HEIGHT), CV_8UC1);
result = Scalar(127);
Rect roi;
roi.x = 0;
roi.width = FIXED_WIDTH;
roi.y = (FIXED_HEIGHT - gray.rows) / 2;
roi.height = gray.rows;
gray.copyTo(result(roi));
hog.compute(result, desc, Size(8, 8), Size(0, 0));
// printf("desc len : %d \n", desc.size());
}
void generate_dataset(Mat &trainData, Mat &labels)
{
vector<cv::String> images;
//The purpose of the function is to_ The file name used under the dir (positive sample) path is saved in images
glob(positive_dir, images);
int pos_num = images.size();
for (int i = 0; i < images.size(); i++)
{
Mat image = imread(images[i].c_str());
vector<float> fv;
get_hog_descriptor(image, fv);
for (int j = 0; j < fv.size(); j++)
{
trainData.at<float>(i, j) = fv[j];
}
labels.at<int>(i, 0) = 1; //Positive sample
}
images.clear();
//The purpose of the function is to set negative_ The file name used under the dir (negative sample) path is saved in images
glob(negative_dir, images);
for (int i = 0; i < images.size(); i++)
{
Mat image = imread(images[i].c_str());
vector<float> fv;
get_hog_descriptor(image, fv);
for (int j = 0; j < fv.size(); j++)
{
trainData.at<float>(i + pos_num, j) = fv[j];
}
labels.at<int>(i + pos_num, 0) = -1; //Negative sample
}
}
void svm_train(Mat &trainData, Mat &labels)
{
printf("\n start SVM training... \n");
Ptr<SVM> svm = SVM::create();
svm->setC(2.67);
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::LINEAR); //Linear SVM kernel
svm->setGamma(5.383);
svm->train(trainData, ROW_SAMPLE, labels);
clog << "....[Done]" << endl;
printf("end train...\n");
// save xml
svm->save("hog_elec.xml");
}