
Preface
Previous Article How connectors are designed in Tomcat Describes the design of connectors in Tomcat. We know that connectors are responsible for listening to network ports, getting connection requests, then converting Servlet-compliant requests to containers for processing. This article will follow the ideas of the previous article to see how containers request a request to a container..
Note: This tomcat version is 9.0.21 and is not recommended for zero-base readers.
From the Adapter
We continue with the source code of the Adapter in the previous article, which ends with the following source code:
//Source 1. Class: CoyoteAdapter implements Adapter public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) throws Exception { Request request = (Request) req.getNote(ADAPTER_NOTES); Response response = (Response) res.getNote(ADAPTER_NOTES); postParseSuccess = postParseRequest(req, request, res, response); if (postParseSuccess) { //check valves if we support async request.setAsyncSupported( connector.getService().getContainer().getPipeline().isAsyncSupported()); // Calling the container connector.getService().getContainer().getPipeline().getFirst().invoke( request, response); } }
The main purpose of the above source code is to get the container, then call getPipeline() to get the Pipeline, and finally invoke it. Let's see what this Pipeline does.
//Source 2.Pipeline interface public interface Pipeline extends Contained { public Valve getBasic(); public void setBasic(Valve valve); public void addValve(Valve valve); public Valve[] getValves(); public void removeValve(Valve valve); public Valve getFirst(); public boolean isAsyncSupported(); public void findNonAsyncValves(Set<String> result); } //Source 3. Valve interface public interface Valve { public Valve getNext(); public void setNext(Valve valve); public void backgroundProcess(); public void invoke(Request request, Response response) throws IOException, ServletException; public boolean isAsyncSupported();
We can literally understand that Pipeline is a pipe, and Valve is a valve. In fact, Tomcat does the same thing as literally.Each container has a pipe and there are multiple valves in the pipe.We demonstrate this through subsequent analysis.
Pipeline-Valve
We can see that the source code above is the interface between Pipeline and Valve, Pipeline mainly sets up Valve, and Valve is a chain list, then invoke the method.Let's review this source:
//Source 4 connector.getService().getContainer().getPipeline().getFirst().invoke( request, response);
Here is the pipe that gets the container directly, then gets the first Valve to call.We mentioned earlier that Valve is a linked list, where only the first is called, that is, you can call the last through Next.Let's go back to our first article, " How Tomcat started in SpringBoot As mentioned in the book, containers are divided into four subcontainers, Engine, Host, Context, Wrapper. They are also parent-child relationships, Engine>Host>Context>Wrapper.
As I mentioned earlier, every container has a Pipeline, so how does that come across?Looking at the interface source of the container, we can see that Pipeline is a basic property of the container interface definition:
//Source 5. public interface Container extends Lifecycle { //Omit other code /** * Return the Pipeline object that manages the Valves associated with * this Container. * * @return The Pipeline */ public Pipeline getPipeline(); }
We know that each container has a pipe (Pipeline), there are many valves in the pipe, and Valve can be called in a chain, so the question is, how does Valve in the parent container pipe call Valve in the child container?In the implementation class StandardPipeline for Pipeline, we found the following sources:
/** // Source 6. * The basic Valve (if any) associated with this Pipeline. */ protected Valve basic = null; /** * The first valve associated with this Pipeline. */ protected Valve first = null; public void addValve(Valve valve) { //Omit some code // Add this Valve to the set associated with this Pipeline if (first == null) { first = valve; valve.setNext(basic); } else { Valve current = first; while (current != null) { //Loop here to set Valve and make sure the last one is basic if (current.getNext() == basic) { current.setNext(valve); valve.setNext(basic); break; } current = current.getNext(); } } container.fireContainerEvent(Container.ADD_VALVE_EVENT, valve); }
From the code above, we know that base is the last valve in a pipe (Pipeline). It makes sense that all chain calls can be completed as long as the last valve is the first valve in the next container.Let's use a request debug to see if, like our guess, we break a point in the service method in the CoyoteAdapter with the following effect:
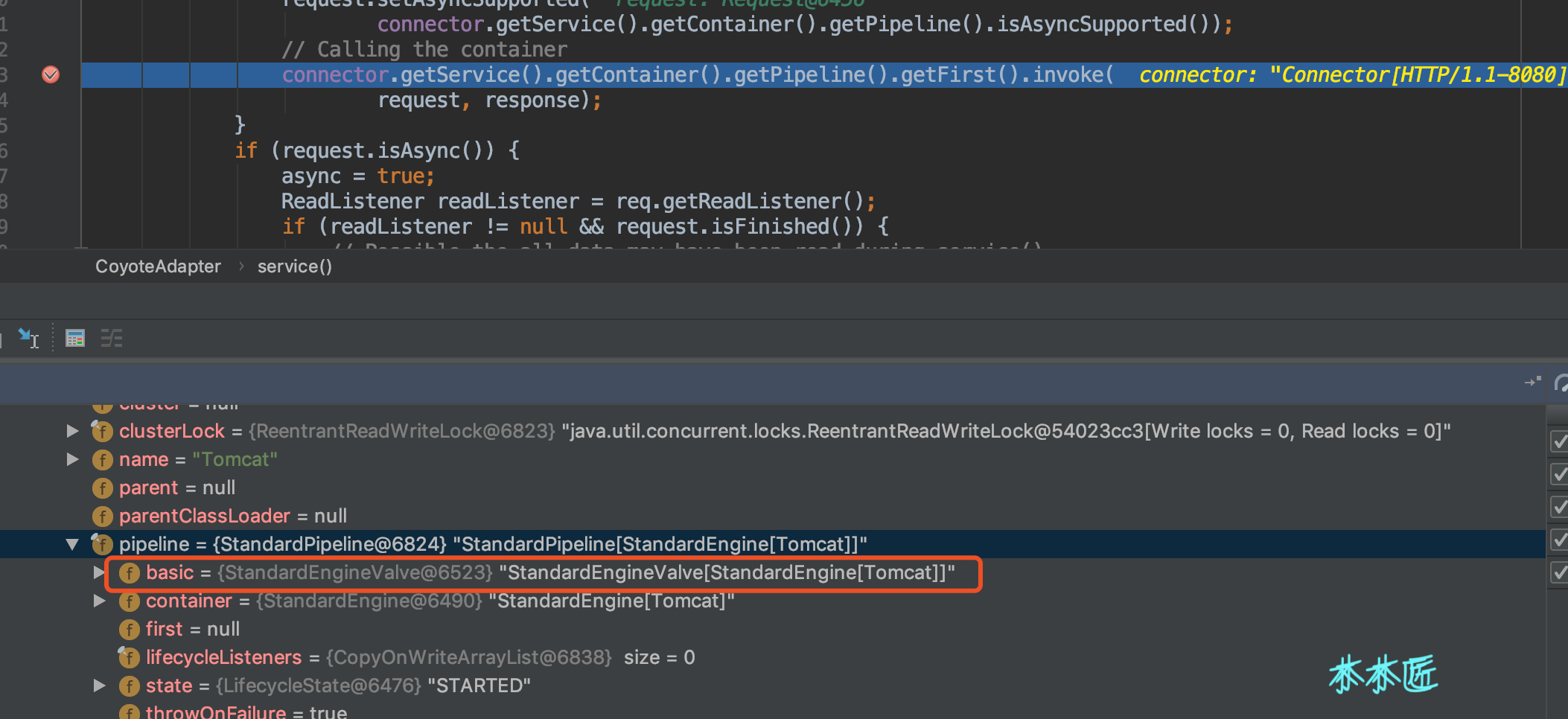
Here we know that when the adapter calls the container, that is, the pipeline that calls Engine, there is only one valve, which is basic and has a value of Standard EngineValve.We found the invoke method for this valve as follows:
//Source 7. public final void invoke(Request request, Response response) throws IOException, ServletException { // Select the Host to be used for this Request Host host = request.getHost(); if (host == null) { // HTTP 0.9 or HTTP 1.0 request without a host when no default host // is defined. This is handled by the CoyoteAdapter. return; } if (request.isAsyncSupported()) { request.setAsyncSupported(host.getPipeline().isAsyncSupported()); } // Ask this Host to process this request host.getPipeline().getFirst().invoke(request, response); }
Let's Continue debug and see the results as follows:
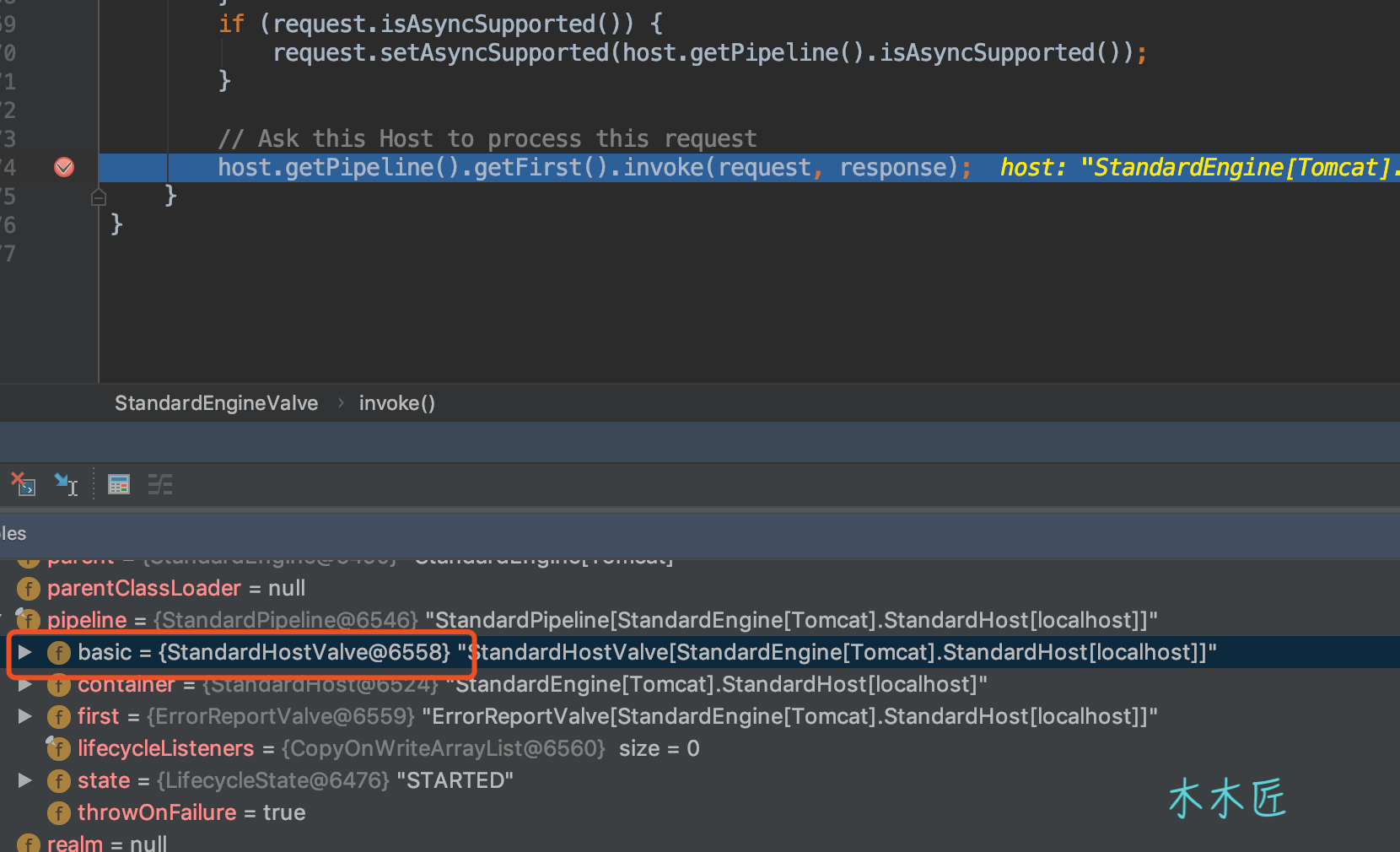
So the base here actually calls the Pipeline and Valve of the Host container, that is, the base in each container pipe is the valve responsible for calling the next subcontainer.I use a diagram to show:
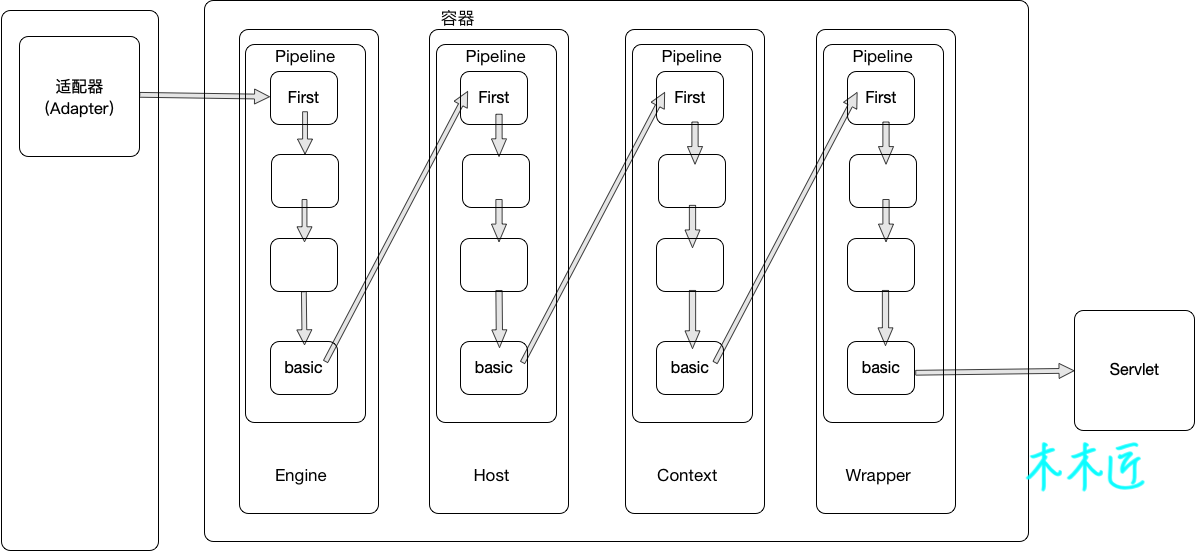
This diagram clearly describes how the container inside Tomcat flows the request, requests coming from the Connector enter the Engine container, which is chained through the valves in the Pieline, and the final basic valve is the first valve responsible for calling the next container and is constantly adjustedWrapper is used, then Wrapper executes the Servlet.
Let's see if the Wrapper source really works as we say:
//Source 8. public final void invoke(Request request, Response response) throws IOException, ServletException { //Omit some sources Servlet servlet = null; if (!unavailable) { servlet = wrapper.allocate(); } // Create the filter chain for this request ApplicationFilterChain filterChain = ApplicationFilterFactory.createFilterChain(request, wrapper, servlet); filterChain.doFilter(request.getRequest(), response.getResponse()); }
Looking at this, you might say that it means you just created a filter and called it, not a Servlet call Yes, there is no call to the Servlet, but we know that the filter is executed before the Servlet, that is, it will execute after the filterChain.doFilter is executed.Let's see if the source code for the ApplicationFilterChain is what we say:
//Source 9. public void doFilter(ServletRequest request, ServletResponse response) throws IOException, ServletException { //Omit some code internalDoFilter(request,response); } //Source 10. private void internalDoFilter(ServletRequest request, ServletResponse response) throws IOException, ServletException { //Omit some code // Call the next filter if there is one if (pos < n) { //Omit some code ApplicationFilterConfig filterConfig = filters[pos++]; Filter filter = filterConfig.getFilter(); filter.doFilter(request, response, this); return; } //Call servlet // We fell off the end of the chain -- call the servlet instance servlet.service(request, response);
From the source code, we find that after all the filters have been called, the servlet starts calling the service.Let's look at the implementation class of the servlet

The HttpServlets and GenericServlets we are familiar with here are classes of Tomcat packages, but actually only HttpServlets, because GenericServlets are the parent of HttpServlets.Later, it is handed over to the framework for processing, and the request within Tomcat is now complete.
Multi-Application Isolation Implementation of Tomcat
We know Tomcat supports deployment of multiple applications, so how does Tomcat support deployment of multiple applications?How do you ensure that multiple applications are not confused?To understand this, let's go back to the adapter, back to the service method
//Source 11. Class: CoyoteAdapter public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) throws Exception { //Omit some code // Parse and set Catalina and configuration specific // request parameters //Processing URL mappings postParseSuccess = postParseRequest(req, request, res, response); if (postParseSuccess) { //check valves if we support async request.setAsyncSupported( connector.getService().getContainer().getPipeline().isAsyncSupported()); // Calling the container connector.getService().getContainer().getPipeline().getFirst().invoke( request, response); } }
We only talked about the code connector.getService().getContainer().getPipeline().getFirst().invoke (request, response) in the previous source code. This part of the code is to call the container, but there is a postParseRequest method to process the mapping request before calling the container. Let's follow up on the source code:
//Source 12. Class: CoyoteAdapter protected boolean postParseRequest(org.apache.coyote.Request req, Request request, org.apache.coyote.Response res, Response response) throws IOException, ServletException { //Omit some code boolean mapRequired = true; while (mapRequired) { // This will map the the latest version by default connector.getService().getMapper().map(serverName, decodedURI, version, request.getMappingData()); //404 error if no context is found if (request.getContext() == null) { // Don't overwrite an existing error if (!response.isError()) { response.sendError(404, "Not found"); } // Allow processing to continue. // If present, the error reporting valve will provide a response // body. return true; } }
This is a loop to process the Url mapping. If the Context is not found, a 404 error is returned. Let's continue with the source code:
//Source 13. Class: Mapper public void map(MessageBytes host, MessageBytes uri, String version, MappingData mappingData) throws IOException { if (host.isNull()) { String defaultHostName = this.defaultHostName; if (defaultHostName == null) { return; } host.getCharChunk().append(defaultHostName); } host.toChars(); uri.toChars(); internalMap(host.getCharChunk(), uri.getCharChunk(), version, mappingData); } //Source 14. Class: Mapper private final void internalMap(CharChunk host, CharChunk uri, String version, MappingData mappingData) throws IOException { //Omit some code // Virtual host mapping handles Host mapping MappedHost[] hosts = this.hosts; MappedHost mappedHost = exactFindIgnoreCase(hosts, host); //Omit some code if (mappedHost == null) { mappedHost = defaultHost; if (mappedHost == null) { return; } } mappingData.host = mappedHost.object; // Context mapping handles context mapping ContextList contextList = mappedHost.contextList; MappedContext[] contexts = contextList.contexts; //Omit some code if (context == null) { return; } mappingData.context = contextVersion.object; mappingData.contextSlashCount = contextVersion.slashCount; // Wrapper mapping handles Servlet mapping if (!contextVersion.isPaused()) { internalMapWrapper(contextVersion, uri, mappingData); } }
Due to the large number of source codes above, I omitted a lot of code and kept the code that understands the main logic. Generally speaking, processing Url consists of three parts, mapping Host, mapping Context, and mapping Servlet (to save space, please ask interested students to study the specific source details on their own).
One detail we can see here is that the three processing logic are tightly related, and only if Host is not empty will Context be processed, and the same is true for Servlet s.So as long as we have different Host configurations here, then all the subsequent subcontainers will be different, thus completing the effect of application isolation.However, for SpringBoot's embedded Tomcat approach (launched using the jar package), there is no multi-application mode, and one application is itself a Tomcat.
For ease of understanding, I've also drawn a multi-application isolation diagram, where we assume there are two domain names admin.luozhou.com and web.luozhou.com, and then I deploy two applications under each domain name, User,log,blog,shop.So when I go to add users, I ask Servlet for add under User's Context under admin.luozhou.com domain name (Note: This example design does not conform to actual development principles, and add should be done as a controller in the framework, not as a Servlet).
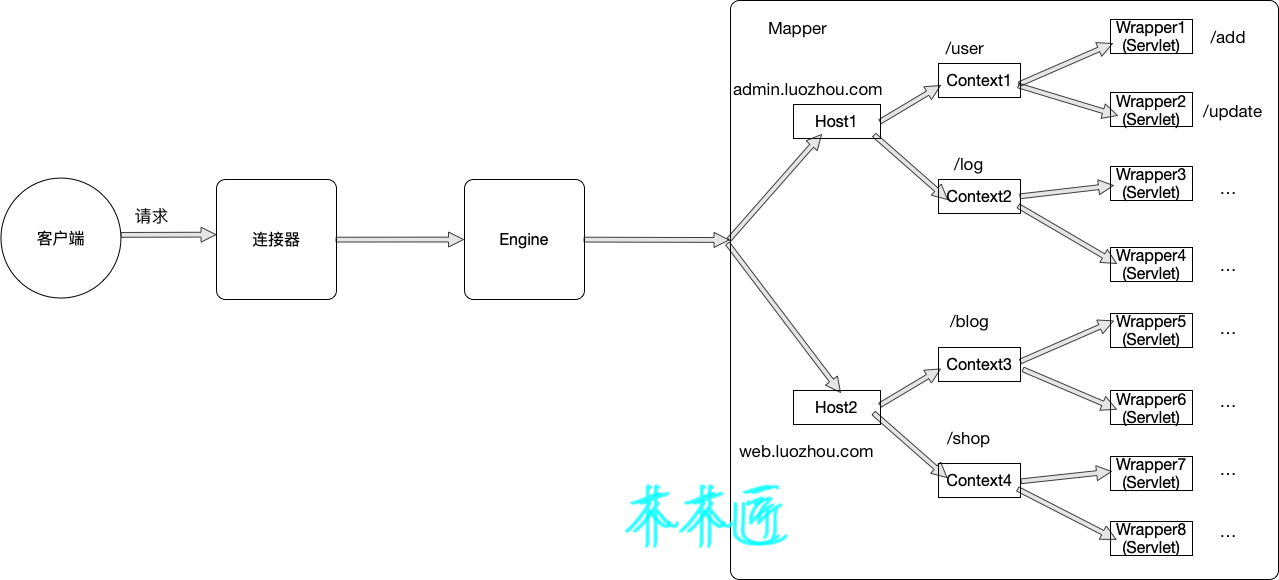
summary
This article examines how containers in Tomcat handle requests, so let's review:
- Connector calls container after dropping request to adapter adapter
- The inside of the container is invoked through the Pieline-Valve mode, while the parent container invokes the child container through a basic valve.
- The last subcontainer wrapper builds a filter to make the filter call when it finishes calling, and the last step inside Tomcat is to call the servlet.You can also understand our common HttpServlet, where all Servlet-based frameworks enter the framework process (including SpringBoot).
- Finally, we analyze how Tomcat achieves multi-application isolation. Through multi-application isolation analysis, we also understand why Tomcat designs so many sub-containers that can fulfill different scenario requirements at different granularity levels as needed.
Copyright notice: Original article, please indicate the source for reprinting.