When information needs to be displayed in tabular format, web tables or data tables are usually used. In essence, the displayed data can be static or dynamic. You often see examples in e-commerce portals where product specifications are displayed in Web tables. With its widespread use, you often encounter the need to Selenium test Automate scenarios that process them in scripts.
In Ben Selenium WebDriver tutorial In, I'll look at how to handle web tables in Selenium and some useful operations that can be performed on Web tables. By the end of this tutorial, you will have a comprehensive understanding of Web tables in Selenium test automation and the methods used to access the contents of Web tables.
What are Web tables in Selenium?
In Selenium Web form yes WebElement , just like any other popular web element, such as text box, radio button, check box, drop-down menu, etc. Web tables and their contents can identify elements (rows / columns) by using WebElement functions and locators.
A table consists of rows and columns. The table created for a web page is called a web page table. Here are some important tags related to web tables:
Types of Web tables in Selenium
The tables fall into two broad categories: http://github.crmeb.net/u/defu
Static web page table
As the name suggests, the information in the table is static in nature.
Dynamic web page table
The information displayed in the table is dynamic. For example, detailed product information, sales reports, etc. on e-commerce websites.
To demonstrate how Selenium works with tables, we use the tables available in the w3school HTML tables page. Although there are fewer problems with cross browser testing when using tables, some older browsers of Internet Explorer, Chrome and other Web browsers do not support the HTML Table API.
Now that we have introduced the basics, in this Selenium WebDriver tutorial, I will introduce some common operations for dealing with tables in Selenium, which will help you automate Selenium testing.
Processing Web tables in Selenium
I will use the local Selenium WebDriver to perform browser operations to process the table in Selenium, which exists on the w3schools html table page. The HTML code of the Web table for presentation is provided in the try it adapter page.
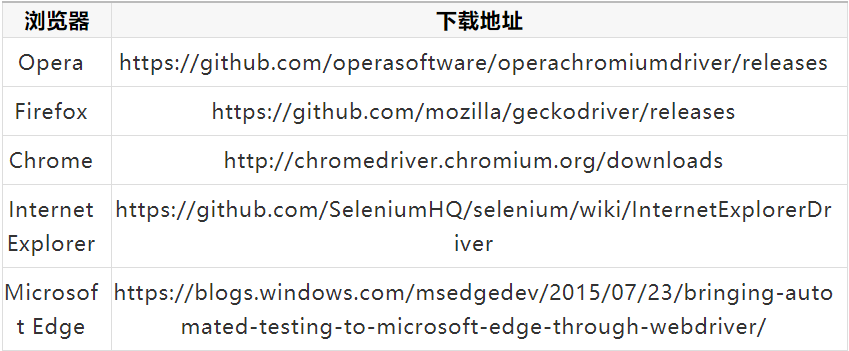
Selenium WebDriver for popular browsers can be downloaded from the location mentioned below:
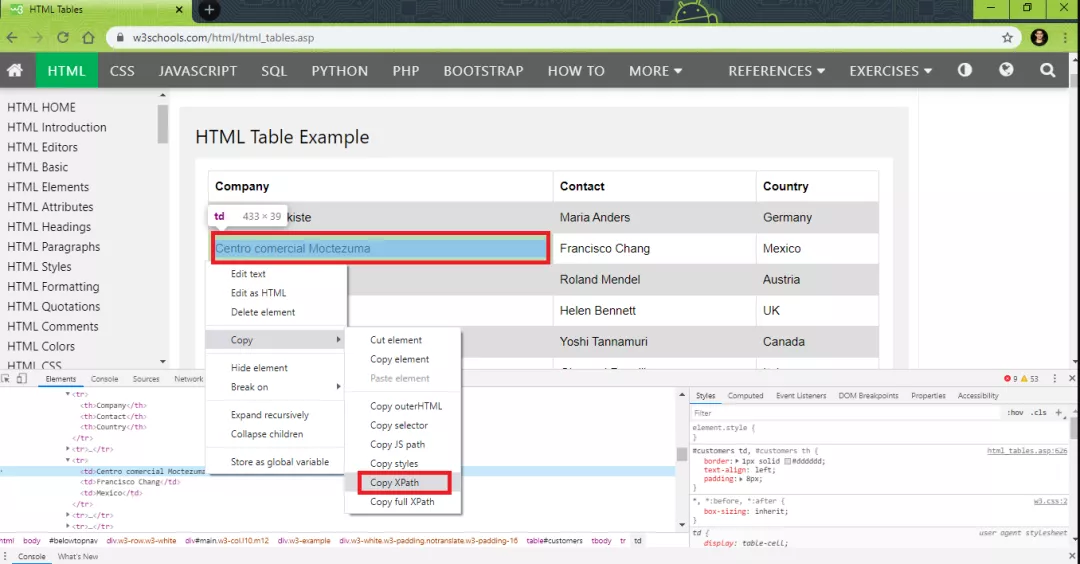
I'll use the Python unittest framework to work with tables in Selenium WebDriver. Even if you use other programming languages for Selenium test automation, the core logic for accessing elements in Web tables remains the same.
Note – in all scenarios, the implementations in setUp () and teardown () are the same. We will not repeat this section in every example shown in the blog.
Number of rows and columns in the processing Web table
The label in the < tr > table indicates the rows in the table, which is used to obtain information about the number of rows in the table. Use XPath (/ / * [@ id = 'customers'] / tbody / tr [2] / td) to calculate the number of columns in the Web table in Selenium. Use the check tool in the browser to get the XPath of rows and columns to process the tables in Selenium for automatic browser testing.
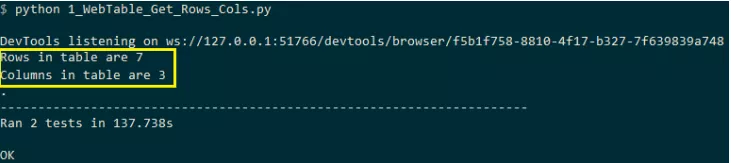
Although the header in the network table is not < td >, < th > in the current example, you can still use tags to calculate the number of columns. The XPath for calculating the number of columns using the < th > tag is / / * [@@ id = 'customers'] / tbody / tr / th
A 30 second WebDriverWait has been added to ensure that the Web table is loaded before performing any operation to process the table in Selenium (class_name = W3 example).
Gets the number of rows in the Web table in Selenium
num_rows = len (driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr"))
Gets the number of columns in the Web table in Selenium
num_cols = len (driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr[2]/td"))
Complete implementation
import unittest import time from selenium import webdriver from selenium.webdriver.support.select import Select from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC test_url = "https://www.w3schools.com/html/html_tables.asp" class WebTableTest(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.maximize_window() def test_1_get_num_rows_(self): driver = self.driver driver.get(test_url) WebDriverWait(driver, 60).until(EC.presence_of_element_located((By.CLASS_NAME, "w3-example"))) num_rows = len (driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr")) print("The rows in the table are " + repr(num_rows)) def test_2_get_num_cols_(self): driver = self.driver driver.get(test_url) WebDriverWait(driver, 60).until(EC.presence_of_element_located((By.CLASS_NAME, "w3-example"))) # num_cols = len (driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr/th")) num_cols = len (driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr[2]/td")) print("The columns in the table are " + repr(num_cols)) def tearDown(self): self.driver.close() self.driver.quit() if __name__ == "__main__": unittest.main()
The following is the output snapshot
Print the contents of the Web table with Selenium
In order to access the contents of each row and column in Selenium to process the tables in Selenium, we iterated < tr > every row in the Web table (). After we get the details about the row, we will iterate over the labels under the < td > row.
In this case, both rows (< tr >) and columns (< td >) are variable for this Selenium WebDriver tutorial. Therefore, row and column numbers are calculated dynamically. The following shows the XPath used to access information in specific rows and columns:
XPath access row: 2, column: 2 – / / * [@ @ = = "customers"] / tbody / tr [2] / td [1]
XPath access row: 3, column: 1 – / / * [@ id = "customers"] / tbody / tr [3] / td [1]
The table that performs Selenium test automation has 7 rows and 3 columns. Therefore, when a nested for loop is executed, the range of rows is 2... 7 and the range of columns is 1... 4. Add variable factors, namely row and column numbers, to formulate the final XPath.
for t_row in range(2, (rows + 1)): for t_column in range(1, (columns + 1)): FinalXPath = before_XPath + str(t_row) + aftertd_XPath + str(t_column) + aftertr_XPath cell_text = driver.find_element_by_xpath(FinalXPath).text
Below this Selenium WebDriver tutorial is a complete implementation of processing all existing content into a table in Selenium.
import unittest import time test_url = "https://www.w3schools.com/html/html_tables.asp" before_XPath = "//*[@id='customers']/tbody/tr[" aftertd_XPath = "]/td[" aftertr_XPath = "]" def test_get_row_col_info_(self): driver = self.driver driver.get(test_url) # time.sleep(30) WebDriverWait(driver, 60).until(EC.presence_of_element_located((By.CLASS_NAME, "w3-example"))) rows = len(driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr")) # print (rows) columns = len(driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr[2]/td")) # print(columns) # print("Company"+" "+"Contact"+" "+"Country") for t_row in range(2, (rows + 1)): for t_column in range(1, (columns + 1)): FinalXPath = before_XPath + str(t_row) + aftertd_XPath + str(t_column) + aftertr_XPath cell_text = driver.find_element_by_xpath(FinalXPath).text # print(cell_text, end = ' ') print(cell_text) print()
The following is an output snapshot of what is printed to process tables in Selenium:
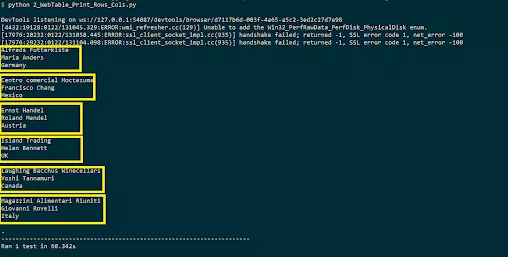
Read the data in the row to process the table in Selenium
In order to access the contents of each row to process the table in Selenium, the row (< tr >) is variable and the column (< td >) remains unchanged. Therefore, rows are calculated dynamically. At the bottom of this Selenium WebDriver tutorial is an XPath for accessing information, where rows are variable factors and columns remain unchanged for Selenium test automation.
XPath access row: 1, column: 1 – / / * [@ id = "customers"] / tbody / tr [1] / td [1]
XPath access row: 2, column: 2 – / / * [@ @ = = "customers"] / tbody / tr [2] / td [2]
XPath access row: 3, column: 2 – / / * [@ id = "customers"] / tbody / tr [3] / td [2]
The execution range of the for loop is 2... 7. The value of the column value appended to the XPath is td [1] / td [2] / td [3], depending on the rows and columns that must be accessed to process the table in Selenium.
before_XPath = "//*[@id='customers']/tbody/tr[" aftertd_XPath_1 = "]/td[1]" aftertd_XPath_2 = "]/td[2]" aftertd_XPath_3 = "]/td[3]" for t_row in range(2, (rows + 1)): FinalXPath = before_XPath + str(t_row) + aftertd_XPath_1 cell_text = driver.find_element_by_xpath(FinalXPath).text print(cell_text)
Complete implementation
#Selenium Webdriver tutorials can be processed in selenium to automate selenium testing import unittest import time from selenium import webdriver from selenium.webdriver.support.select import Select from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC test_url = "https://www.w3schools.com/html/html_tables.asp" before_XPath = "//*[@id='customers']/tbody/tr[" aftertd_XPath_1 = "]/td[1]" aftertd_XPath_2 = "]/td[2]" aftertd_XPath_3 = "]/td[3]" #aftertr_XPath = "]" def test_get_row_col_info_(self): driver = self.driver driver.get(test_url) # time.sleep(30) WebDriverWait(driver, 60).until(EC.presence_of_element_located((By.CLASS_NAME, "w3-example"))) rows = len(driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr")) # print (rows) columns = len(driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr[2]/td")) # print(columns) print("Data in row, column 1") print() for t_row in range(2, (rows + 1)): FinalXPath = before_XPath + str(t_row) + aftertd_XPath_1 cell_text = driver.find_element_by_xpath(FinalXPath).text print(cell_text) print() print("2 Column display data") print() for t_row in range(2, (rows + 1)): FinalXPath = before_XPath + str(t_row) + aftertd_XPath_2 cell_text = driver.find_element_by_xpath(FinalXPath).text print(cell_text) print() print("The data is displayed in the row, column 3") print() for t_row in range(2, (rows + 1)): FinalXPath = before_XPath + str(t_row) + aftertd_XPath_3 cell_text = driver.find_element_by_xpath(FinalXPath).text print(cell_text)
Read the data in the row to process the output snapshot of the table in Selenium as follows:
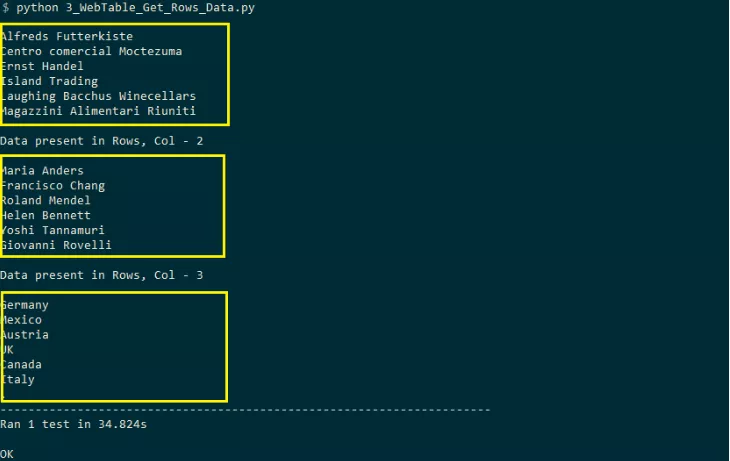
Read the data in the column to process the table in the column
For accessing the handle table in Selenium by column, the row remains unchanged, while the column number is variable, that is, the column is calculated dynamically. At the bottom of this Selenium WebDriver tutorial is XPath, which is used to access information, where columns are variable and rows are constant.
XPath access row: 2, column: 2 – / / * [@ @ = = "customers"] / tbody / tr [2] / td [2]
XPath access row: 2, column: 3 – / / * [@ id = "customers"] / tbody / tr [2] / td [3]
XPath access row: 2, column: 4 – / / * [@ id = "customers"] / tbody / tr [2] / td [4]
When executing the for loop, the range of columns is 1... 4. Depending on the rows and columns that must be accessed, the row values attached to the XPath are tr [1] / tr [2] / tr [3].
before_XPath_1 = "//*[@id='customers']/tbody/tr[1]/th[" before_XPath_2 = "//*[@id='customers']/tbody/tr[2]/td[" after_XPath = "]" for t_col in range(1, (num_columns + 1)): FinalXPath = before_XPath_1 + str(t_col) + after_XPath cell_text = driver.find_element_by_xpath(FinalXPath).text print(cell_text)
Complete implementation
import unittest import time from selenium import webdriver from selenium.webdriver.support.select import Select from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC test_url = "https://www.w3schools.com/html/html_tables.asp" before_XPath_1 = "//*[@id='customers']/tbody/tr[1]/th[" before_XPath_2 = "//*[@id='customers']/tbody/tr[2]/td[" after_XPath = "]" def test_get_row_col_info_(self): driver = self.driver driver.get(test_url) # time.sleep(30) WebDriverWait(driver, 60).until(EC.presence_of_element_located((By.CLASS_NAME, "w3-example"))) num_rows = len(driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr")) # print (rows) num_columns = len(driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr[2]/td")) # print(columns) print("The data in column 1 is the header") print() for t_col in range(1, (num_columns + 1)): FinalXPath = before_XPath_1 + str(t_col) + after_XPath cell_text = driver.find_element_by_xpath(FinalXPath).text print(cell_text) print("Data in column 2") print() for t_col in range(1, (num_columns + 1)): FinalXPath = before_XPath_2 + str(t_col) + after_XPath cell_text = driver.find_element_by_xpath(FinalXPath).text print(cell_text)
As you can see from the execution snapshot, the title column is also read to get the title of the column.
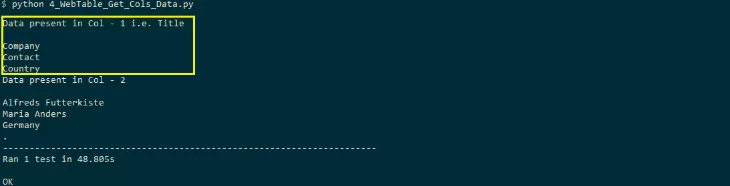
Locate elements to process tables in selenium
The test purpose of this Selenium WebDriver tutorial is to find the existence of elements in Web tables. To do this, the contents of each cell in the Web table are read and compared with the search term. If the element exists, the corresponding row and element are printed to process the table in Selenium.
Since it involves reading the data in each cell, we use the logic described in the section titled the print content of the Web table in Selenium. Perform a case insensitive search to verify the existence of the search term to process the tables in Selenium.
for t_row in range(2, (num_rows + 1)): for t_column in range(1, (num_columns + 1)): FinalXPath = before_XPath + str(t_row) + aftertd_XPath + str(t_column) + aftertr_XPath cell_text = driver.find_element_by_xpath(FinalXPath).text if ((cell_text.casefold()) == (search_text.casefold())): print("Search text"+ search_text +" In the second row " + str(t_row) + " And column" + str(t_column)) elem_found = True break
Complete implementation
import unittest import time from selenium import webdriver from selenium.webdriver.support.select import Select from selenium.webdriver.common.by import By from selenium.webdriver.support.ui import WebDriverWait from selenium.webdriver.support import expected_conditions as EC test_url = "https://www.w3schools.com/html/html_tables.asp" before_XPath_1 = "//*[@id='customers']/tbody/tr[1]/th[" before_XPath_2 = "//*[@id='customers']/tbody/tr[2]/td[" after_XPath = "]" search_text = "mAgazzini Alimentari rIUniti" def test_get_row_col_info_(self): driver = self.driver driver.get(test_url) # time.sleep(30) WebDriverWait(driver, 60).until(EC.presence_of_element_located((By.CLASS_NAME, "w3-example"))) num_rows = len(driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr")) num_columns = len (driver.find_elements_by_xpath("//*[@id='customers']/tbody/tr[2]/td")) elem_found = False for t_row in range(2, (num_rows + 1)): for t_column in range(1, (num_columns + 1)): FinalXPath = before_XPath + str(t_row) + aftertd_XPath + str(t_column) + aftertr_XPath cell_text = driver.find_element_by_xpath(FinalXPath).text if ((cell_text.casefold()) == (search_text.casefold())): print("Search Text "+ search_text +" is present at row " + str(t_row) + " and column " + str(t_column)) elem_found = True break if (elem_found == False): print("Search Text "+ search_text +" not found")
As shown in the execution snapshot of this Selenium WebDriver tutorial, the search term appears in line 7 and column 1
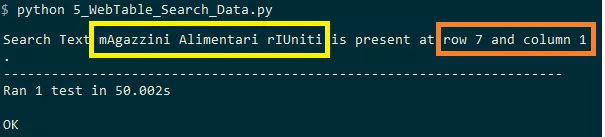
Although many of these operations can be performed on Selenium's Web tables, we have covered the core aspects in this Selenium WebDriver tutorial.