1. Concept
① A node has a performance bottleneck, which may be the failure of the machine where the node is located (network, disk, etc.), the network delay of the machine, insufficient disk, and frequent GC,Data hotspot and other reasons.
② Most message oriented middleware, such as kafka of consumer from broker Put data pull Local, and producer Put data push reach broker.
2. Influence of back pressure
Back pressure will affect checkpoint ① checkpoint Duration:checkpoint barrier Follow the normal data flow. If the data processing is blocked, the checkpoint barrier The length of time flowing through the entire data pipeline becomes longer, resulting in checkpoint The overall time becomes longer. ② state Size: to ensure Exactly-Once Accurate once, for those with more than two input pipes Operator,checkpoint barrier Alignment is required, i.e. a faster input pipe is received barrier After that, the data behind it will be cached but not processed until the end of the slower input pipeline barrier Also arrived. These cached data will be put into state Inside, cause checkpoint Get bigger. checkpoint Is the key to ensuring accuracy, checkpoint Longer time may lead to checkpoint Timeout failed and state Size may slow down checkpoint Even lead to OOM.
3.Flink's back pressure mechanism
Realization of network flow control: dynamic feedback / automatic back pressure

Consumer It needs to be given in time Producer Make one feedback,Immediately inform Producer What is the acceptable rate. There are two types of dynamic feedback:
Negative feedback: occurs when the reception rate is less than the transmission rate, and is notified Producer Reduce transmission rate
Positive feedback: occurs when the sending rate is less than the receiving rate, and is notified Producer You can increase the transmission rate
3.1 Flink backpressure mechanism
Flink has three types of data exchange:- Data exchange of the same Task;
- Data exchange between different tasks and the JVM;
- Exchange between different tasks and different Task managers.
3.1.1 data exchange of the same Task
Multiple operators are connected in series through operator chain, which is mainly used to avoid the overhead of serialization and network communication.
Operator chain operator chain Conditions for concatenating multiple operators:
① The parallelism of upstream and downstream is consistent
② The penetration of downstream nodes is 1
③ Upstream and downstream nodes share the same slot
④ Downstream node chain Strategy is ALWAYS(for example map,flatmap,filter The default is ALWAYS)
⑤ Upstream node chain Strategy is ALWAYS or HEAD(source The default is HEAD)
⑥ The data partition method between two nodes is forward
⑦ User not disabled chain
3.1.2 different tasks are the same Task Manager Data exchange

3.1.3 exchange between different tasks and different Task managers
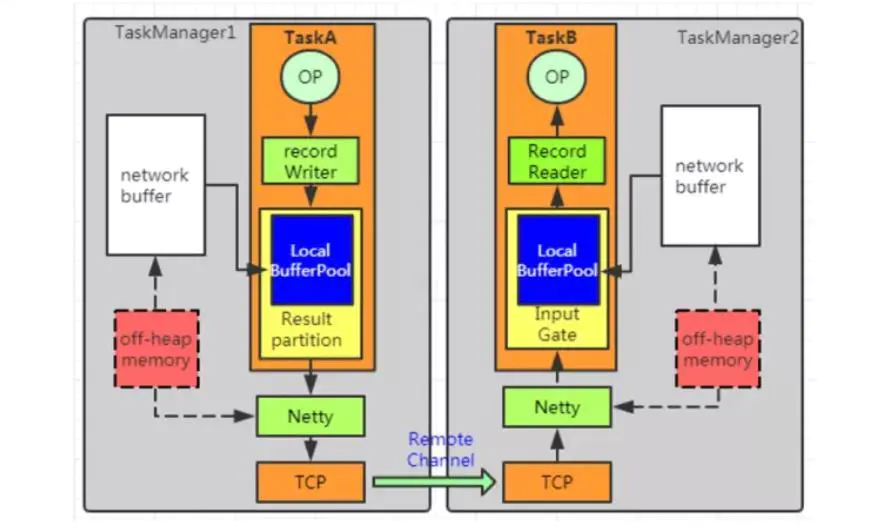
The difference from the above 3.1.2 is that the data is transferred to netty first, and the data is pushed to the Task at the remote end through netty.
3.2 TCP based backpressure mechanism of Flink (before V1.5)
Before version 1.5, TCP flow control mechanism was adopted instead of feedback mechanism.
- TCP based before Flink 1.5 Back pressure mechanism
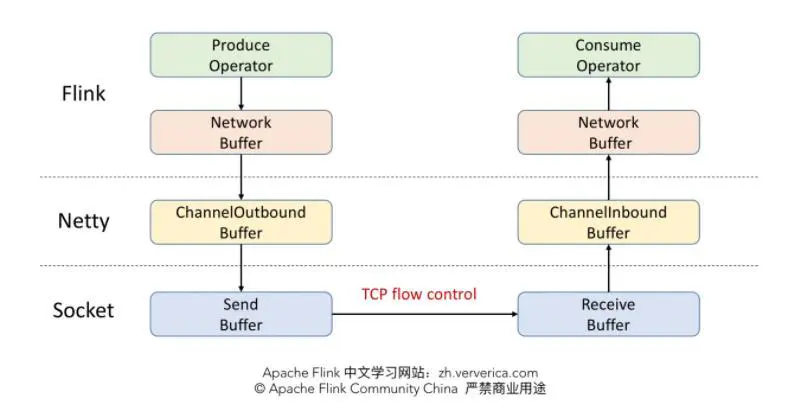
- TCP realizes network flow control by using sliding window
Reference: 1 [computer network] 3.1 transport layer - TCP/UDP protocol
2.Apache Flink advanced tutorial (7): network flow control and back pressure analysis
Example: TCP uses sliding windows to limit traffic
Step 1: the sender will send 4, 5 and 6, and the receiver can also receive all data.
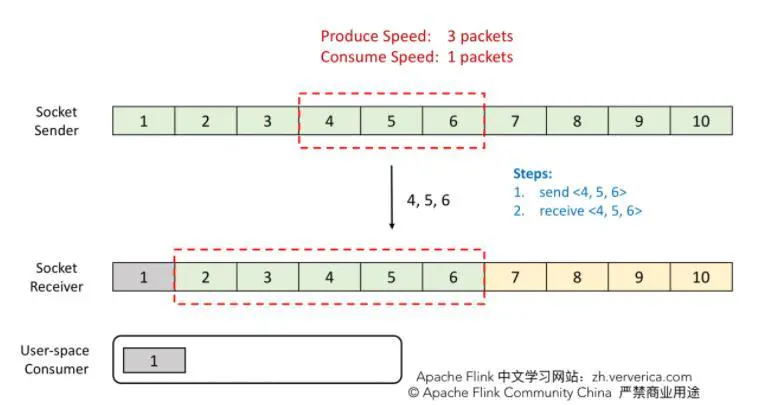
Step 2: when the consumer consumes 2, the window at the receiving end will slide forward one grid, that is, there is 1 grid left in the window. Then it is sent to the sender ACK = 7,window = 1.



- Disadvantages of TCP based backpressure mechanism

① single Task The back pressure blocked the whole TaskManager of socket,cause checkpoint barrier Can't spread, eventually leading to checkpoint Time growth even checkpoint Timeout failed.
② The backpressure path is too long, resulting in backpressure time delay.
3.3 credit based backpressure mechanism of Flink (since V1.5)
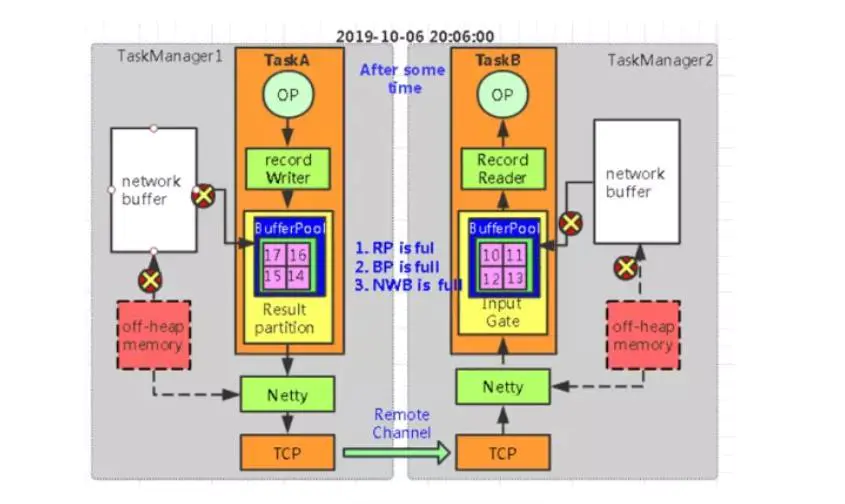
The back pressure mechanism is implemented at the Flink level, and the feedback is transmitted through ResultPartition and InputGate .Credit-base of feedback Steps: ① every time ResultPartition towards InputGate When sending data, one will be sent backlog size Tell the downstream how many messages to send, and the downstream will calculate how many messages to send Buffer To receive messages. ( backlog The function of is to make the consumer feel the situation of our production side) ② If there is sufficient downstream Buffer ,Will be returned upstream Credit (Indicates remaining buffer Quantity) to inform the sending message (whether the two dotted lines on the figure are used or not) Netty and Socket Communicate).
Production section send backlog=1

The consumer returns credit=3

When the production end runs out of buffer, it returns credit=0

There is also a data backlog on the production side
4. Locate the back pressure node
4.1 back pressure monitoring of Flink Web UI - direct mode
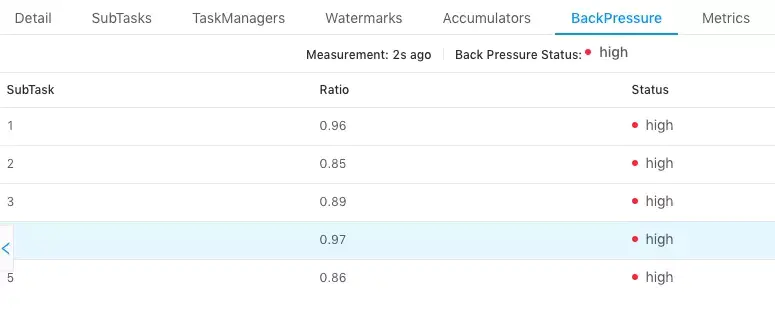
The following two scenarios may cause backpressure:
① The sending rate of this node cannot keep up with its data generation rate. This scenario is generally a single input multiple output operator, such as FlatMap. Positioning means because it is from Source Task reach Sink Task The first node with backpressure, so this node is the root node of backpressure.
② The downstream node processes data slowly, and the transmission rate of the node is limited by backpressure. The positioning means is to continue to check the downstream nodes from this node.
matters needing attention:
① because Flink Web UI The backpressure panel monitors the sending end, so the root node of backpressure does not necessarily reflect high backpressure on the backpressure panel. If a node is a performance bottleneck, it will not cause high backpressure in itself, but high backpressure in its upstream. Overall, if the first node with backpressure is found, the backpressure source is this node or its downstream node.
② The above two states cannot be distinguished through the back pressure panel, so they need to be combined Metrics And other monitoring means. If the number of nodes of a job is large or the degree of parallelism is large, all nodes need to be collected Task According to the stack information, the pressure on the back pressure panel will be very large or even unavailable.
4.2 Flink Task Metrics - Indirect
(1) Review Flink credit based network
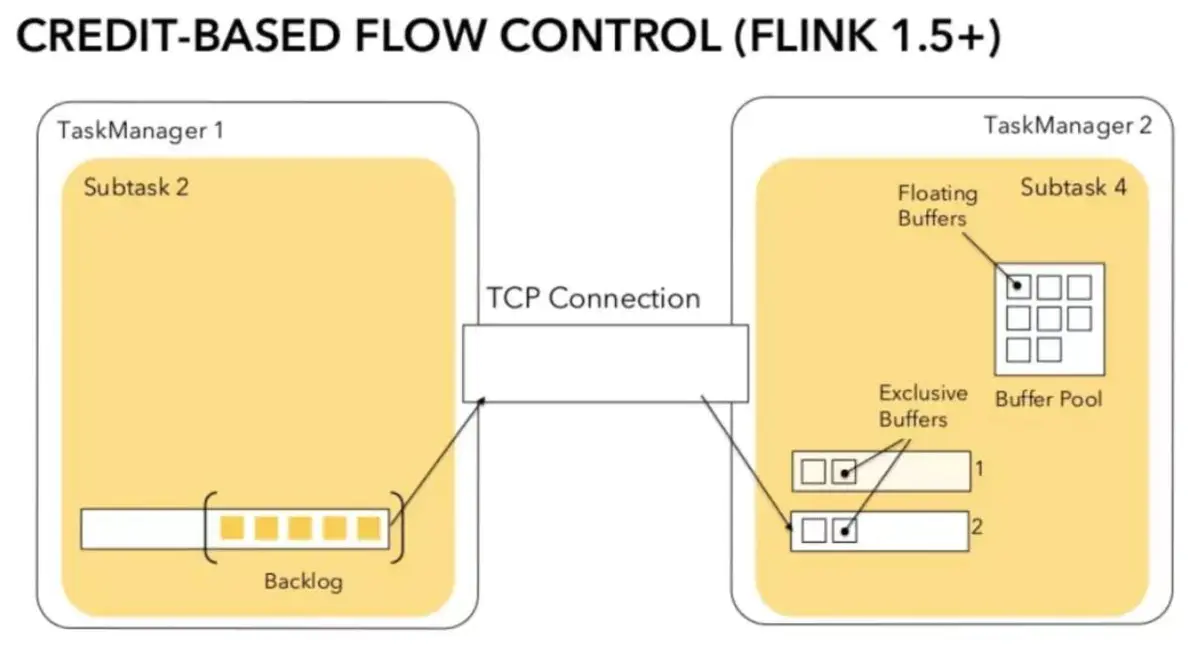
① TaskManager Data transmission between different TaskManager Two on the Subtask Usually, channel Quantity equals grouping key Or equal to the operator concurrency. these channel Will reuse the same TaskManager Process TCP Request and share the receiver Subtask Rank Buffer Pool. ② receiving end each channel In the initial stage, a fixed number of exclusive will be allocated Exclusive Buffer,Used to store received data. operator Operator Release again after use Exclusive Buffer. explain: channel Receiver idle Buffer The quantity is called Credit,Credit It will be regularly synchronized to the sender to decide how many to send Buffer Data. ③ Scenes with high traffic Receiving end, channel Write full Exclusive Buffer After, Flink Will to Buffer Pool Apply for the remaining Floating Buffer. Sender, one Subtask be-all Channel Will share the same Buffer Pool,Therefore, no distinction is made Exclusive Buffer and Floating Buffer.
(2) Flink Task Metrics monitors back pressure
Network and task I/O Metrics is a lightweight backpressure monitor, which is used for continuously running jobs. The following metrics are the most useful backpressure indicators.
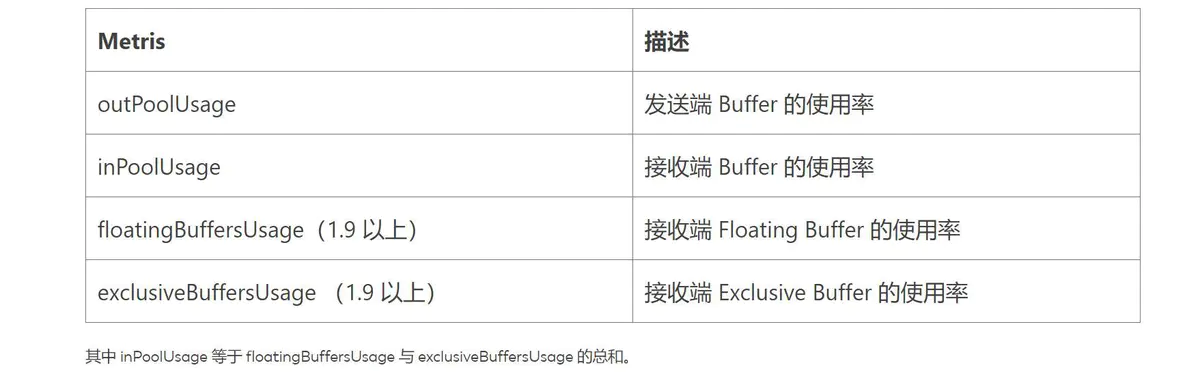
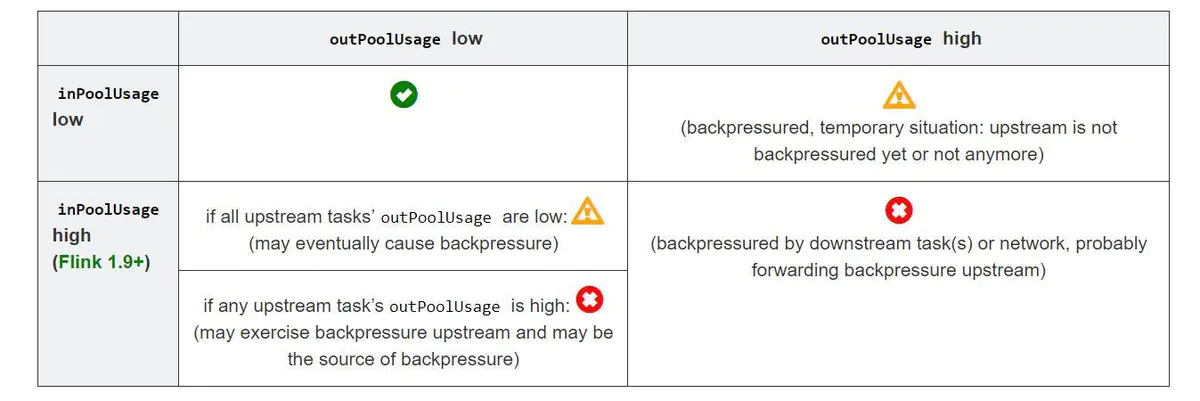
Explanation:
① outPoolUsage and inPoolUsage Both low indicate current Subtask Is normal, and both are high, respectively indicating the current Subtask By downstream backpressure.
② If one Subtask of outPoolUsage Is high, usually downstream Task Therefore, the possibility that it itself is the root of back pressure can be investigated.
③ If one Subtask of outPoolUsage Is low, but its inPoolUsage If it is high, it indicates that it may be the root of backpressure. Because usually the back pressure will be transmitted to its upstream, resulting in some upstream pressure Subtask of outPoolUsage Is high.
Note: backpressure is sometimes transient and has little effect, such as from a channel Short network delay or TaskManager Normal GC,In this case, it can not be handled.
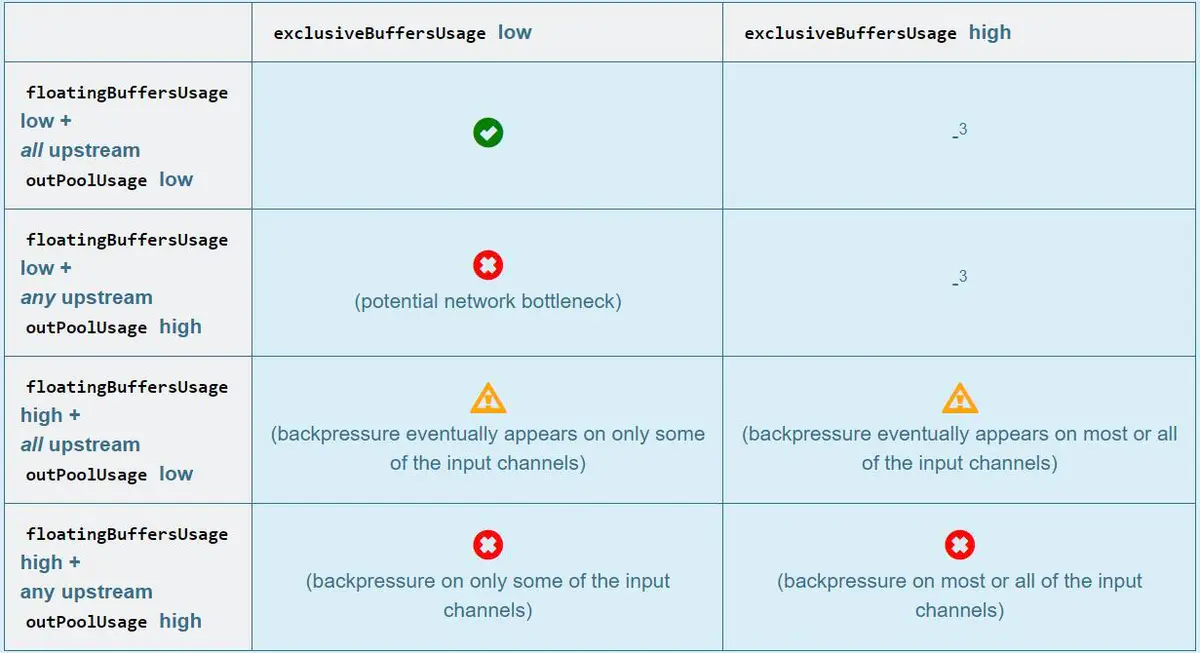
Resolution:
① floatingBuffersUsage High indicates that the back pressure is conducting upstream.
② exclusiveBuffersUsage It indicates that the back pressure may be inclined. If floatingBuffersUsage High exclusiveBuffersUsage Low, there is a tilt. Because a few channel Takes up most of the floating Buffer(channel Have your own exclusive buffer,When exclusive buffer After consumption, it will be used floating Buffer).
5. How does Flink analyze back pressure
The above mainly locates the backpressure through TaskThread, and the analysis of the cause of backpressure is similar to the performance bottleneck of an ordinary program.
(1) Data skew
Confirm through the Records Sent and Record Received of each SubTask in the Web UI. In addition, the State size of different subtasks in the Checkpoint detail is also a useful indicator for analyzing data skew. The solution is to perform local / pre aggregation on the key s of data packets to eliminate / reduce data skew.
(2) Execution efficiency of user code
Conduct CPU profile for TaskManager and analyze whether TaskThread is running full of a CPU core: if it is not running full, analyze the functions in which CPU is mainly spent, such as the user function (ReDoS) of Regex occasionally stuck in the production environment; If it is not full, you need to see where the Task Thread is blocked. It may be some synchronous calls of the user function itself, or system activities such as checkpoint or GC.
(3) TaskManager memory and GC
Frequent Full GC and even loss of contact caused by unreasonable memory in each area of the TaskManager JVM. You can add - 20: + printgcdetails to print GC logs to observe GC problems. It is recommended that TaskManager enable G1 garbage collector to optimize GC.