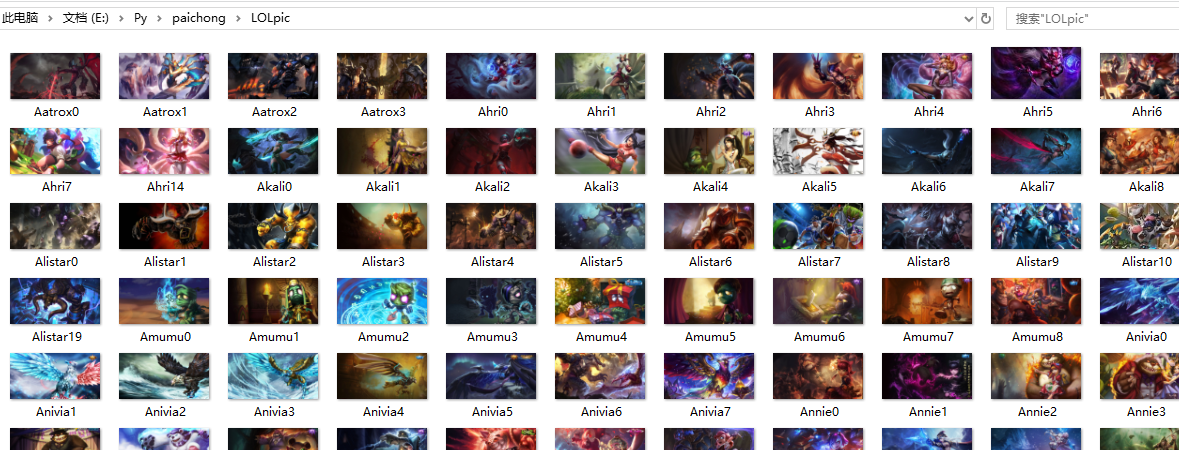
I believe many of my friends are players who love the hero League. The skin production of the hero League is still relatively exquisite. Xiaobian, who has a collection hobby, plans to climb down the skin of the official website with a crawler. Next, let's see how Xiaobian uses python to climb the skin of the hero League! (python crawler source code is attached)
At the beginning, I went to the official website of the League of heroes to find the website of heroes and skin pictures:
URL = r'https://lol.qq.com/data/info-heros.shtml'
From the above website, you can see that all heroes are. Press F12 to view the source code. It is found that the hero and skin pictures are not directly given, but hidden in the JS file. At this time, you need to click Network, find the JS window, refresh the web page, and you will see a champion JS option, click to see a dictionary - which contains the names (English) and corresponding numbers of all heroes (as shown in the figure below).
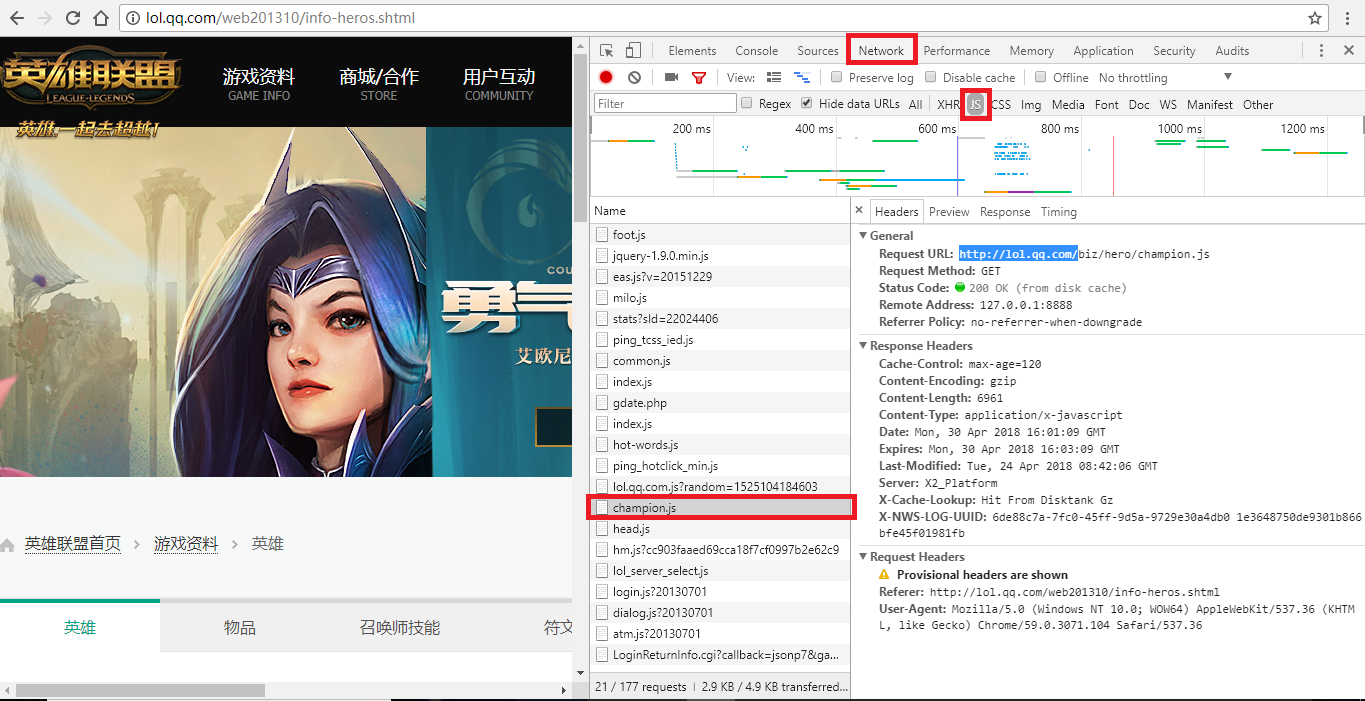
However, only the hero's name (in English) and corresponding number can't find the picture address, so go back to the web page and click a hero casually. After jumping to the page, you find that the pictures of the hero and skin are there, but you also need to find the original address to download. This is to right-click and select "open in new tab". The new web page is the original address of the picture (as shown in the following figure).
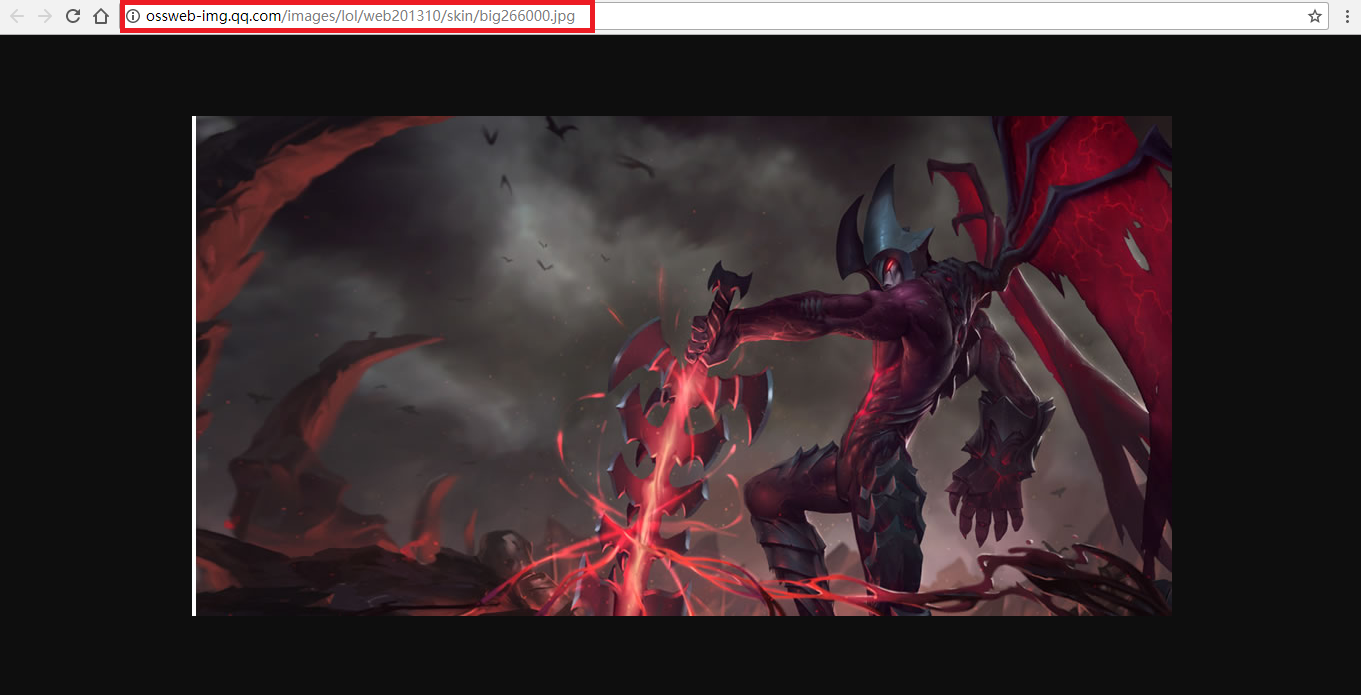
The red box in the figure is the picture address we need. After analysis, we know that the address of each hero and skin is only different in number( http://ossweb-img.qq.com/images/lol/web201310/skin/big266000.jpg )The number has 6 digits. The first 3 digits represent heroes and the last 3 digits represent skin. The js file just found happens to have the hero's number, and the skin code can be defined by yourself. Anyway, there are no more than 20 hero skins, and then they can be combined.
After the picture address is completed, you can start writing the program:
Step 1: get js dictionary
def path_js(url_js):
res_js = requests.get(url_js, verify = False).content
html_js = res_js.decode("gbk")
pat_js = r'"keys":(.*?),"data"'
enc = re.compile(pat_js)
list_js = enc.findall(html_js)
dict_js = eval(list_js[0])
return dict_jsStep 2: extract the key value from the js dictionary and generate the url list
def path_url(dict_js):
pic_list = []
for key in dict_js:
for i in range(20):
xuhao = str(i)
if len(xuhao) == 1:
num_houxu = "00" + xuhao
elif len(xuhao) == 2:
num_houxu = "0" + xuhao
numStr = key+num_houxu
url = r'http://ossweb-img.qq.com/images/lol/web201310/skin/big'+numStr+'.jpg'
pic_list.append(url)
print(pic_list)
return pic_listStep 3: extract the value from the js dictionary to generate the name list
def name_pic(dict_js, path):
list_filePath = []
for name in dict_js.values():
for i in range(20):
file_path = path + name + str(i) + '.jpg'
list_filePath.append(file_path)
return list_filePathStep 4: Download and save data
def writing(url_list, list_filePath):
try:
for i in range(len(url_list)):
res = requests.get(url_list[i], verify = False).content
with open(list_filePath[i], "wb") as f:
f.write(res)
except Exception as e:
print("Error downloading picture,%s" %(e))
return FalseExecute the main program:
if __name__ == '__main__':
url_js = r'http://lol.qq.com/biz/hero/champion.js'
path = r'./data/' #Folder where pictures exist
dict_js = path_js(url_js)
url_list = path_url(dict_js)
list_filePath = name_pic(dict_js, path)
writing(url_list, list_filePath)After running, the website address of each picture will be printed on the console:
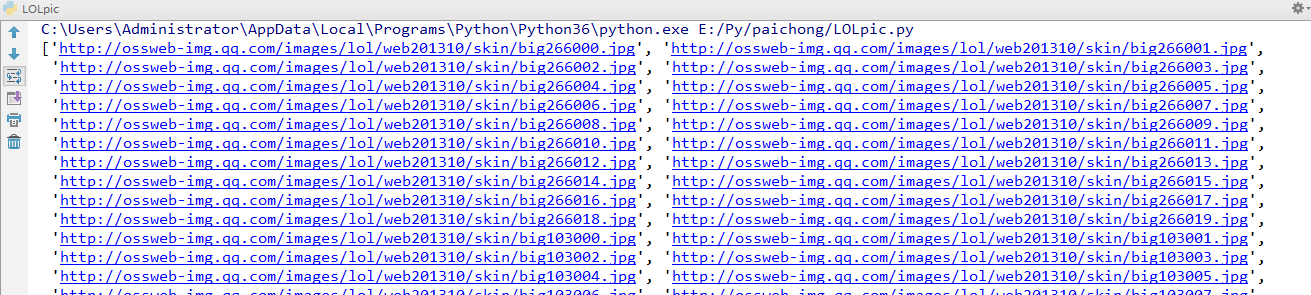
In the folder, you can see that the pictures have been downloaded: