What is Stream?
Now, many large data systems have tables and databases.
For example, the order table in the e-commerce system often uses the Hash value of the user ID to realize table splitting and database splitting. This is to reduce the amount of data in a single table and optimize the speed of user querying orders.
However, when background administrators review orders, they need to query the data of various data sources to the application layer for consolidation.
For example, when we need to query all orders under the filter conditions and sort them according to a certain condition of the order, the data queried by a single data source can be sorted according to a certain condition, but the sorted data queried by multiple data sources does not mean that they are sorted correctly after consolidation, Therefore, we need to reorder the merged data sets at the application layer.
Before Java 8, we usually reordered the merged data through a for loop or Iterator iteration, or redefined collections The Comparator method of sorts is implemented. The efficiency of these two methods is not very ideal for large data systems.
A new interface class Stream has been added to Java8. It is different from the byte Stream concept we contacted before. The Stream in Java8 collection is equivalent to the advanced Iterator. It can perform various very convenient and efficient aggregation operations or bulk data operations on the collection through Lambda expressions.
The aggregation operation of Stream is similar to that of database SQL, such as sorted, filter, map, etc. In the application layer, we can efficiently realize the aggregation operation similar to database SQL. In terms of data operation, Stream can not only realize data operation in a serial way, but also process a large number of data in a parallel way to improve the data processing efficiency.
Next, let's use a simple example to experience the simplicity and power of Stream.
The demand of this Demo is to filter and group male and female students with a height of more than 160cm in a middle school. We first use the traditional iterative method to realize it. The code is as follows:
Map<String, List<Student>> stuMap = new HashMap<String, List<Student>>();
for (Student stu: studentsList) {
if (stu.getHeight() > 160) { //If the height is greater than 160
if (stuMap.get(stu.getSex()) == null) { //The gender has not been classified
List<Student> list = new ArrayList<Student>(); //Create a new list of students of this gender
list.add(stu);//Put students in the list
stuMap.put(stu.getSex(), list);//Put the list in the map
} else { //This gender classification already exists
stuMap.get(stu.getSex()).add(stu);//If the gender classification already exists, just put it in
}
}
}
We then use the Stream API in Java 8 to implement:
1. Serial implementation
Map<String, List<Student>> stuMap = stuList.stream().filter((Student s) -> s.getHeight() > 160) .collect(Collectors.groupingBy(Student ::getSex));
2. Parallel implementation
Map<String, List<Student>> stuMap = stuList.parallelStream().filter((Student s) -> s.getHeight() > 160) .collect(Collectors.groupingBy(Student ::getSex));
Through the above two simple examples, we can find that the traversal filtering function realized by Stream combined with Lambda expression is very concise and convenient.
How does Stream optimize traversal?
Above, we have a preliminary understanding of the Stream API in Java 8. How does Stream achieve optimization iteration? How is parallelism implemented? Now we will analyze the implementation principle of Stream through the source code of Stream.
1.Stream operation classification
Before understanding the implementation principle of Stream, let's first understand the operation classification of Stream, because its operation classification is actually one of the important reasons for realizing efficient iterative big data collection. Why do you say that? You'll know after analysis.
Officially, the operations in the Stream are divided into two categories: intermediate operations and Terminal operations. Intermediate operations only record the operations, that is, only one Stream will be returned, and no calculation operation will be performed, while the terminal operation implements the calculation operation.
Intermediate operations can be divided into Stateless and Stateful operations. The former means that the processing of elements is not affected by the previous elements, and the latter means that the operation can continue only after all elements are obtained.
Termination operations can also be divided into short circuiting and short circuiting. The former means that the final result can be obtained when some qualified elements are encountered, and the latter means that the final result can be obtained only after all elements are processed. The details of operation classification are shown in the following figure:
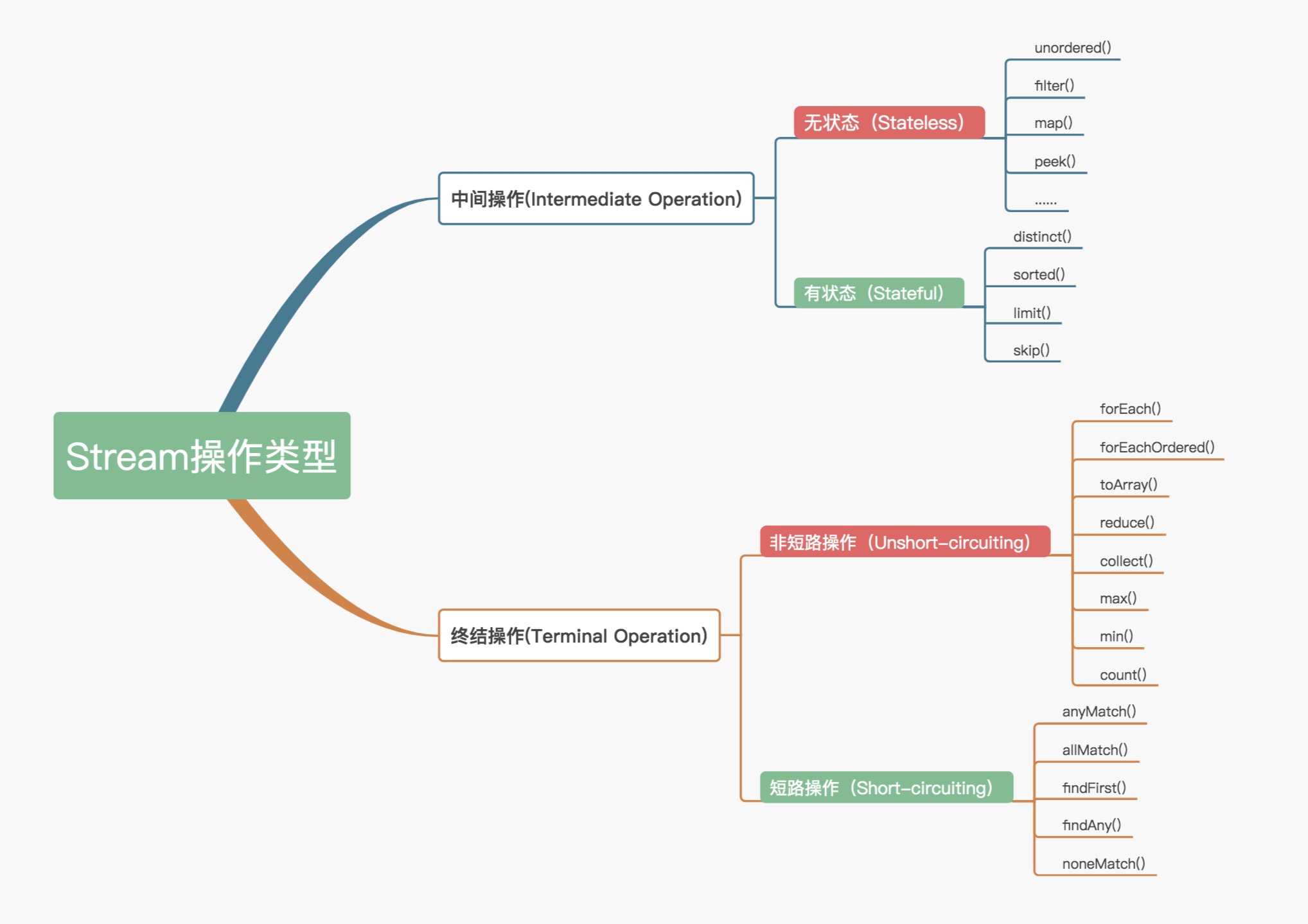
We usually call intermediate operations lazy operations. It is the processing Pipeline composed of this lazy operation, termination operation and data source that realizes the high efficiency of Stream.
2.Stream source code implementation
Before understanding how Stream works, let's first understand which main structural classes are composed of the Stream package and what are the responsibilities of each class. Refer to the following figure:
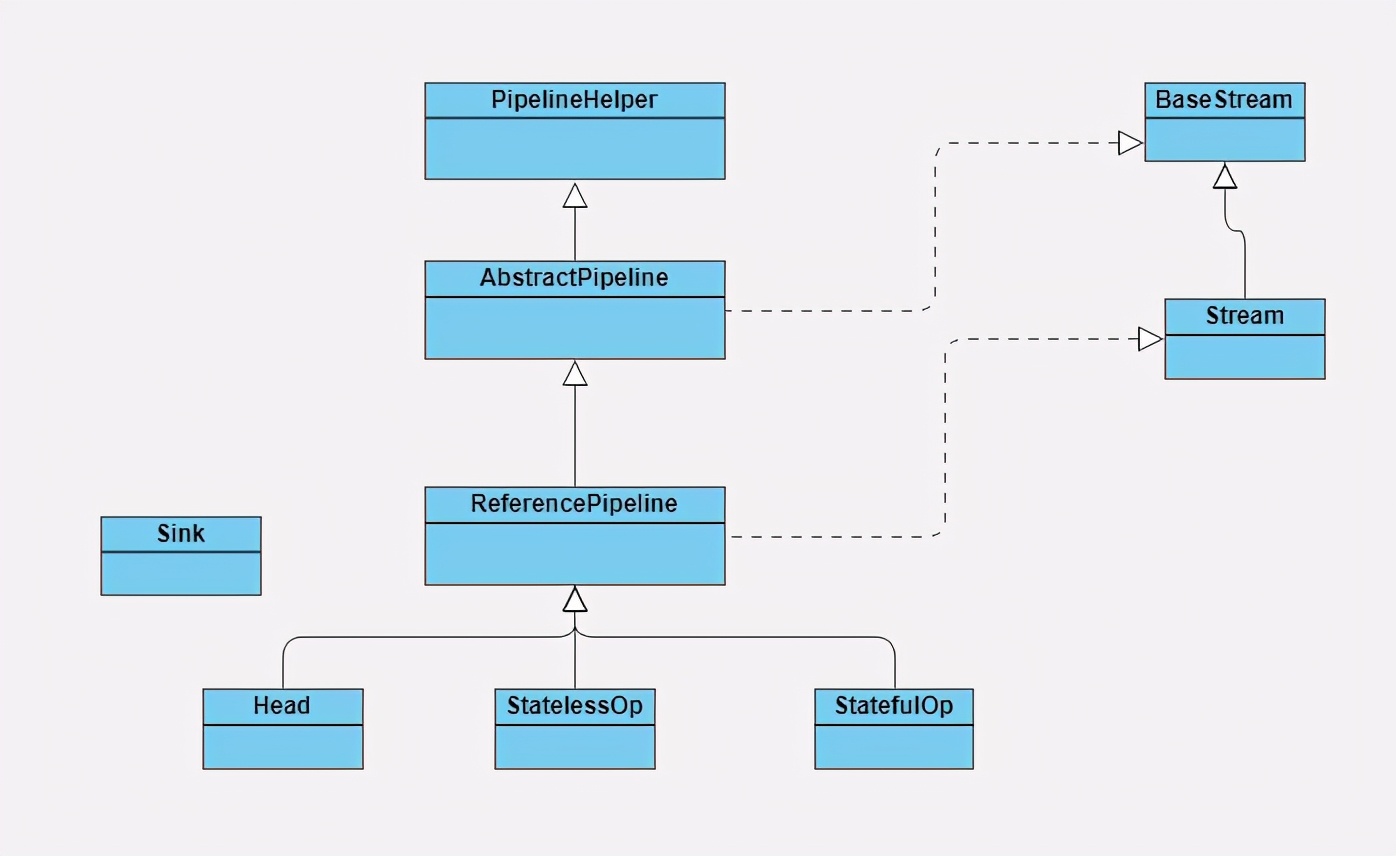
BaseStream and stream are the top interface classes. BaseStream mainly defines the basic interface methods of flow, such as splitter, isParallel, etc; Stream defines some common operation methods of streams, such as map, filter, etc.
ReferencePipeline is a structural class that assembles various operation flows by defining internal classes. He defines three internal classes: Head, StatelessOp and StatefulOp, and implements the interface method between BaseStream and Stream.
The Sink interface is a protocol that defines the relationship between each Stream operation. It contains four methods: begin(), end(), cancelationrequested (), and accpt(). ReferencePipeline will eventually assemble the whole Stream operation into a call chain, and the up-down relationship of each Stream operation on this call chain is defined and implemented through Sink interface protocol.
3.Stream operation superposition
We know that each operation of a Stream is assembled by processing pipelines and completes data processing uniformly. In the JDK, each interrupt operation is named after the use Stage.
The pipeline structure is usually implemented by the ReferencePipeline class. When explaining the Stream package structure earlier, I mentioned that ReferencePipeline includes three internal classes: Head, StatelessOp and StatefulOp.
The Head class is mainly used to define data source operations. When we first call names When using the stream () method, the Head object will be loaded for the first time, which is the operation of loading the data source; Then, intermediate operations are loaded, including stateless intermediate operation StatelessOp object and stateful operation StatefulOp object. At this time, the Stage is not executed, but an intermediate operation Stage linked list is generated through AbstractPipeline; When we call the termination operation, a final Stage will be generated. The previous intermediate operation will be triggered through this Stage. Starting from the last Stage, a Sink chain will be recursively generated. As shown in the figure below:

Let's take another example to see how Stream's operation classification can achieve efficient iteration of large data sets.
List<String> names = Arrays.asList("Zhang San", "Li Si", "bachelor", "Li San", "Liu Laosi", "Wang Xiaoer", "Zhang Si", "Zhang 567");
String maxLenStartWithZ = names.stream()
.filter(name -> name.startsWith("Zhang"))
.mapToInt(String::length)
.max()
.toString();
The requirement of this example is to find a name with the longest length and Zhang as the last name. From a code point of view, you might think it is such an operation process: first, traverse the set once to get all the names starting with "Zhang"; Then traverse the set obtained by the filter once, and convert the name into digital length; Finally, find the longest name from the length set and return it.
Here I want to make it clear to you that this is not the case. Let's step by step analyze how all the operations in this method are performed.
First, because names is an ArrayList Collection, names The Stream () method will call the Stream method of the Collection class basic interface Collection:
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
Then, the Stream method will call the Stream method of the StreamSupport class, in which a ReferencePipeline Head internal class object is initialized:
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator,
StreamOpFlag.fromCharacteristics(spliterator),
parallel);
}
Then call the filter and map methods. These two methods are stateless intermediate operations. Therefore, when executing the filter and map operations, no operation is performed, but a Stage is created to identify each operation of the user.
Generally, the operation of Stream requires a callback function, so a complete Stage is represented by a triple composed of data source, operation and callback function. As shown in the following figure, the filter method and map method of ReferencePipeline are respectively:
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
@Override
@SuppressWarnings("unchecked")
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
new StatelessOp will call the constructor of the parent class AbstractPipeline, which will connect the previous and subsequent stages to generate a Stage linked list:
AbstractPipeline(AbstractPipeline<?, E_IN, ?> previousStage, int opFlags) {
if (previousStage.linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
previousStage.linkedOrConsumed = true;
previousStage.nextStage = this;//Point the next pointer of the current stage to the previous stage
this.previousStage = previousStage;//Assign the current stage to the global variable previousStage
this.sourceOrOpFlags = opFlags & StreamOpFlag.OP_MASK;
this.combinedFlags = StreamOpFlag.combineOpFlags(opFlags, previousStage.combinedFlags);
this.sourceStage = previousStage.sourceStage;
if (opIsStateful())
sourceStage.sourceAnyStateful = true;
this.depth = previousStage.depth + 1;
}
Because when creating each Stage, it will contain an opWrapSink() method, which will encapsulate the specific implementation of an operation in the Sink class, and Sink will overlay operations in the mode of (processing - > forwarding).
When the max method is executed, the max method of ReferencePipeline will be called. At this time, because the max method is a termination operation, a TerminalOp operation will be created, a ReducingSink will be created, and the operation will be encapsulated in the Sink class.
@Override
public final Optional<P_OUT> max(Comparator<? super P_OUT> comparator) {
return reduce(BinaryOperator.maxBy(comparator));
}
Finally, calling the wrapSink method of AbstractPipeline, this method calls opWrapSink to generate a Sink list, and each Sink in the Sink list encapsulates the concrete implementation of an operation.
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}
When the Sink linked list is generated, the Stream starts to execute, and the specific operations in the Sink linked list are executed through the splitter iteration set.
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
The forEachRemaining of the splitter in Java 8 will iterate over the collection. Each iteration will execute a filter operation. If the filter operation passes, the map operation will be triggered, and then the result will be put into the temporary array object for the next iteration. After the intermediate operation is completed, the termination operation max will be triggered.
This is the serial processing mode. How does the other data processing mode of Stream operate?
4.Stream parallel processing
There are two ways for Stream to process data, serial processing and parallel processing. To realize parallel processing, we only need to add a Parallel() method in the code of the example, and the code is as follows:
List<String> names = Arrays.asList("Zhang San", "Li Si", "bachelor", "Li San", "Liu Laosi", "Wang Xiaoer", "Zhang Si", "Zhang 567");
String maxLenStartWithZ = names.stream()
.parallel()
.filter(name -> name.startsWith("Zhang"))
.mapToInt(String::length)
.max()
.toString();
The parallel processing of Stream is the same as the implementation of serial processing before the termination operation. After calling the termination method, the implementation method is a little different. It will call the evaluateParallel method of TerminalOp for parallel processing.
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
The parallel processing here means that the Stream combines the ForkJoin framework to segment the Stream processing, and the estimateSize method in the splitter will estimate the amount of segmented data.
The ForkJoin framework and estimation algorithm are not specifically explained here. If you are interested, you can go deep into the source code to analyze the implementation of the algorithm.
The threshold of the minimum processing unit is obtained through the estimated amount of data. If the current slice size is greater than the threshold of the minimum processing unit, the set will continue to be segmented. Each shard will generate a Sink linked list. When all shard operations are completed, the ForkJoin framework will merge any result set of Shards.
Rational use of Stream
See here, you should have a clear understanding of how the stream API optimizes collection traversal. Stream API is simple to use and can be processed in parallel. Is it better to use stream API? Through a set of tests, let's find out.
We will test and compare the performance of conventional iteration, Stream serial iteration and Stream parallel iteration. In the iteration cycle, we will filter and group the data. Perform the following groups of tests:
- In the multi-core CPU server configuration environment, compare the performance of int array with length of 100;
- In the multi-core CPU server configuration environment, compare the performance of int array with length of 1.00E+8;
- In the multi-core CPU server configuration environment, compare the performance of filtering packets of object array with length of 1.00E+8;
- In the single core CPU server configuration environment, compare the performance of filtering packets of object arrays with a length of 1.00E+8.
Due to the limited space, I will directly give the statistical results here. You can also verify it yourself. The specific test code can be viewed on Github. Through the above tests, the test results I calculated are as follows (iteration use time):
- Conventional iteration < stream parallel iteration < stream serial iteration
- Stream parallel iteration < regular iteration < stream serial iteration
- Stream parallel iteration < regular iteration < stream serial iteration
- Conventional iteration < stream serial iteration < stream parallel iteration
Through the above test results, we can see that the performance of the conventional iteration method is better when the number of loop iterations is less; In the single core CPU server configuration environment, the conventional iterative method has more advantages; In the big data loop iteration, if the server is a multi-core CPU, the parallel iteration advantage of Stream is obvious. Therefore, when dealing with the collection of big data, we should try our best to deploy the application in the multi-core CPU environment and use the parallel iterative method of Stream for processing.
Speaking from the facts, we can see that using Stream may not make the system performance better, but it should be selected in combination with the application scenario, that is, using Stream reasonably.
summary
Throughout the design and implementation of Stream, it is very worth learning. From the large design direction, Stream decomposes the whole operation into a chain structure, which not only simplifies the traversal operation, but also lays a foundation for the realization of parallel computing.
From the small classification direction, Stream divides the operation of traversing elements and the calculation of elements into intermediate operation and termination operation, and the intermediate operation is divided into stateful and stateless operation according to whether there is interference between elements, realizing different stages in the chain structure.
In the serial processing operation, when the Stream executes each intermediate operation, it will not do the actual data operation processing, but connect these intermediate operations in series, and finally trigger by the end operation to generate a data processing linked list, which will process the data through the splitter iterator in Java 8; At this time, data processing is performed for all stateless intermediate operations every iteration, while for stateful intermediate operations, all data needs to be processed iteratively before processing; The last is the data processing of termination operation.
In the parallel processing operation, the intermediate operation of Stream is basically the same as the serial processing method, but in the termination operation, Stream will slice the collection in combination with the ForkJoin framework, which combines the processing results of each slice. Finally, pay attention to the usage scenario of Stream.
Thinking questions
Here is a simple parallel processing case. Please find out the problems.
//Use a container to load 100 numbers, and transfer the singular numbers in the container to the container parallelList through Stream parallel processing
List<Integer> integerList= new ArrayList<Integer>();
for (int i = 0; i <100; i++) {
integerList.add(i);
}
List<Integer> parallelList = new ArrayList<Integer>() ;
integerList.stream()
.parallel()
.filter(i->i%2==1)
.forEach(i->parallelList.add(i));
Look forward to seeing your answer in the message area.