Original text connection: https://blog.ihypo.net/15763910382218.html
This article is based on reading the source code of Kubernetes v1.16. The article has a certain source code, but I will try to describe it clearly through the drawings
In the Kubernetes Master node, there are three important components: ApiServer, ControllerManager and Scheduler, which together undertake the management of the whole cluster. This paper attempts to sort out the workflow and principle of controller manager.
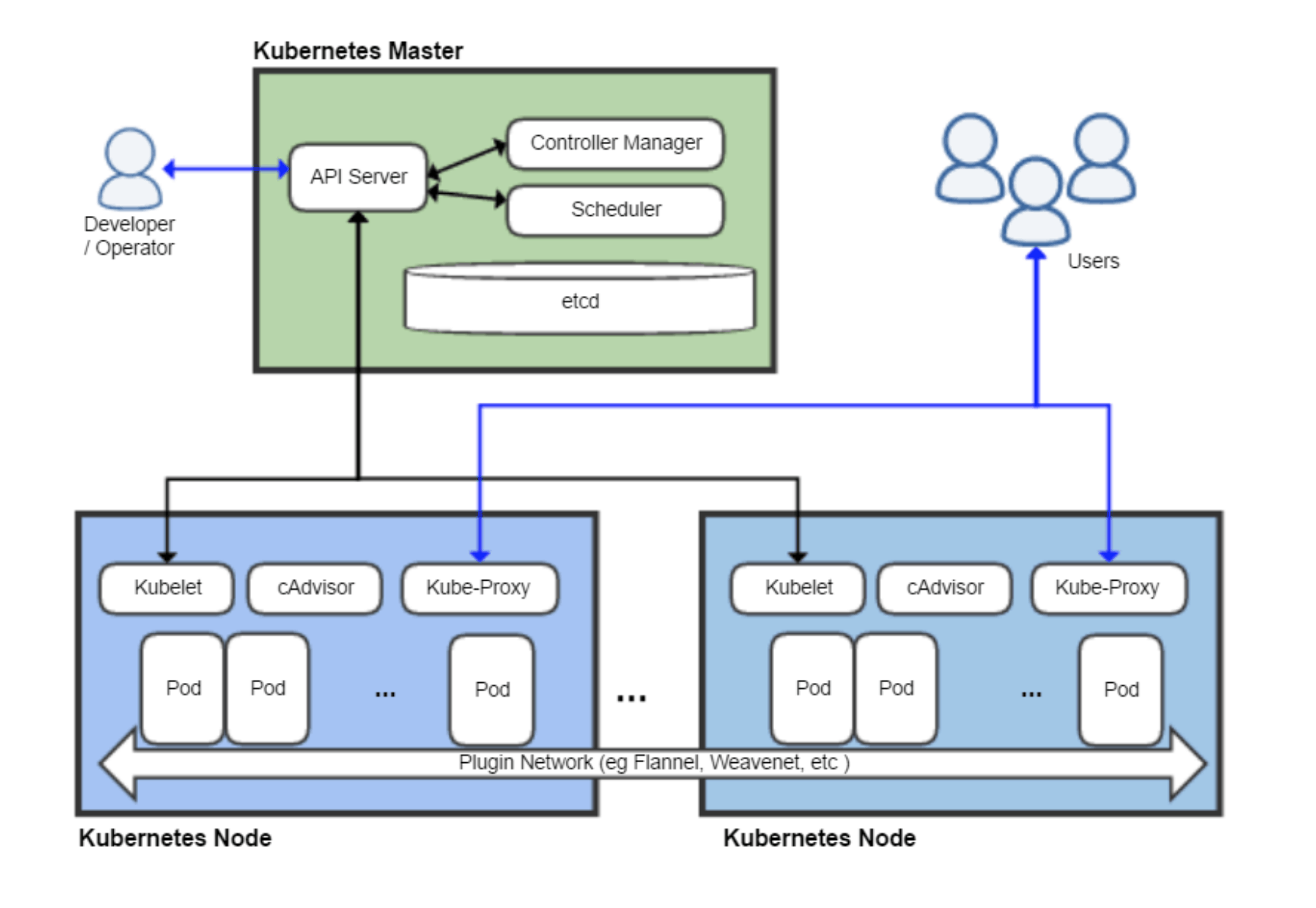
What is Controller Manager
According to the official documentation, Kube controller manager runs controllers, which are background threads that handle routine tasks in the cluster.
To put it bluntly, the Controller Manager is the management control center within the cluster. It is composed of multiple controllers responsible for different resources. It is jointly responsible for the management of all resources such as nodes and pods in the cluster. For example, when a Pod created through Deployment exits abnormally, the RS Controller will accept and handle the exit event, And create a new Pod to maintain the expected number of copies.
Almost every specific resource has a specific Controller maintenance and management to maintain the expected state, and the responsibility of the Controller Manager is to aggregate all controllers:
- Provide infrastructure to reduce the implementation complexity of Controller
- Start and maintain the normal operation of the Controller
It can be said that the Controller ensures that the resources in the cluster remain in the expected state, while the Controller Manager ensures that the Controller remains in the expected state.
Controller workflow
Before explaining how the Controller Manager provides the infrastructure and running environment for the Controller, let's first understand the workflow of the Controller.
From a high-dimensional perspective, the Controller Manager mainly provides the ability to distribute events, while different controllers only need to register the corresponding Handler to wait for receiving and processing events.
Take Deployment Controller as an example, in PKG / controller / deployment / deployment_ The NewDeploymentController method of controller.go includes the registration of Event Handler. For the Deployment Controller, it only needs to implement different processing logic according to different events to realize the management of corresponding resources.
dInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addDeployment,
UpdateFunc: dc.updateDeployment,
// This will enter the sync loop and no-op, because the deployment has been deleted from the store.
DeleteFunc: dc.deleteDeployment,
})
rsInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: dc.addReplicaSet,
UpdateFunc: dc.updateReplicaSet,
DeleteFunc: dc.deleteReplicaSet,
})
podInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
DeleteFunc: dc.deletePod,
})
You can see that with the help of the Controller Manager, the logic of the Controller can be very pure. You only need to implement the corresponding EventHandler. What specific work has the Controller Manager done?
Controller Manager architecture
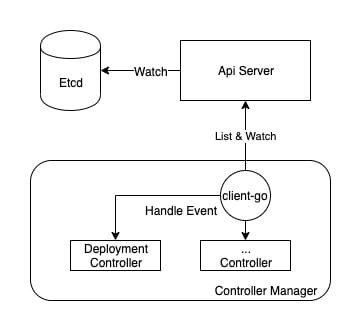
Client go assists the Controller Manager in event distribution, and the key module is informer.
kubernetes provides a client go architecture diagram on github, from which we can see that the Controller is exactly the content described in the lower part (CustomController), and the Controller Manager mainly completes the upper part.
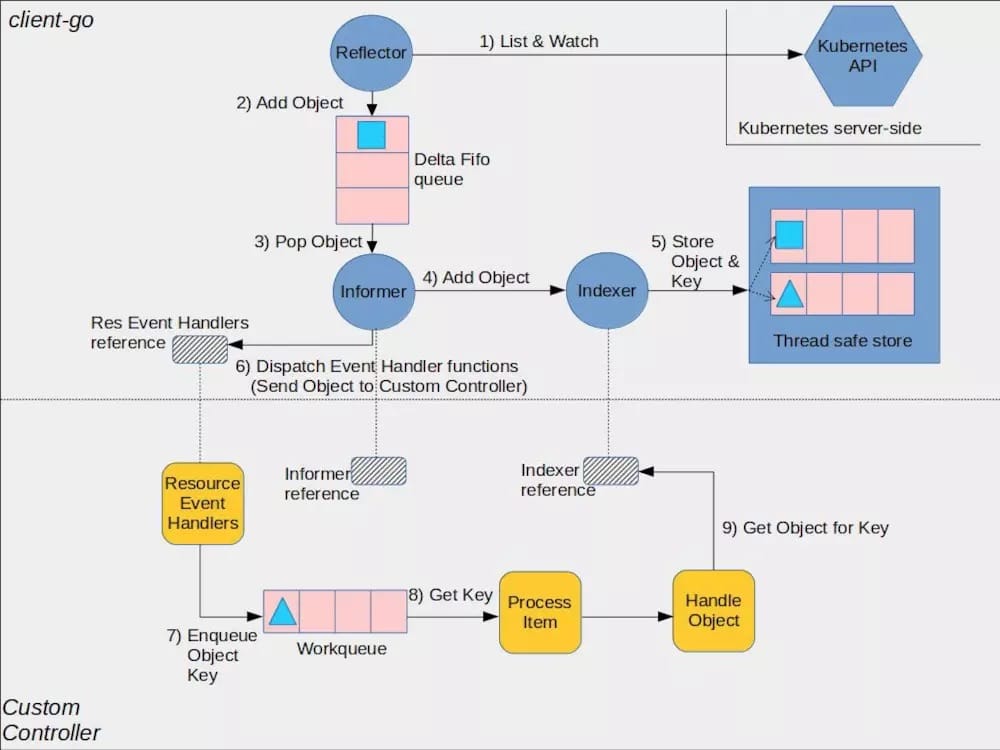
Informer factory
As can be seen from the above figure, Informer is a very key "bridge" role, so the management of Informer is the first thing that the Controller Manager needs to do.
When the Controller Manager starts, a singleton factory named sharedintermerfactory will be created. Because each Informer will maintain a long watch connection with the Api Server, this singleton factory ensures that each type of Informer is instantiated only once by providing a unique access to Informer for all controllers.
Initialization logic of the singleton factory:
// NewSharedInformerFactoryWithOptions constructs a new instance of a SharedInformerFactory with additional options.
func NewSharedInformerFactoryWithOptions(client kubernetes.Interface, defaultResync time.Duration, options ...SharedInformerOption) SharedInformerFactory {
factory := &sharedInformerFactory{
client: client,
namespace: v1.NamespaceAll,
defaultResync: defaultResync,
informers: make(map[reflect.Type]cache.SharedIndexInformer),
startedInformers: make(map[reflect.Type]bool),
customResync: make(map[reflect.Type]time.Duration),
}
// Apply all options
for _, opt := range options {
factory = opt(factory)
}
return factory
}
As can be seen from the above initialization logic, the most important map in shared informerfactory is the map named informers, where key is the resource type and value is the Informer that pays attention to the resource type. Each type of Informer will only be instantiated once and stored in the map. When different controllers need informers with the same resources, they will only get the same Informer instance.
For Controller Manager, maintaining all informers and making them work normally is the basic condition to ensure the normal operation of all controllers. Shared informerfactory maintains all informer instances through this map. Therefore, shared informerfactory also undertakes the responsibility of providing a unified startup entry:
// Start initializes all requested informers.
func (f *sharedInformerFactory) Start(stopCh <-chan struct{}) {
f.lock.Lock()
defer f.lock.Unlock()
for informerType, informer := range f.informers {
if !f.startedInformers[informerType] {
go informer.Run(stopCh)
f.startedInformers[informerType] = true
}
}
}
When the Controller Manager starts, the most important thing is to run all informers through the Start method of the factory.
Creation of Informer
Let's take a look at how these informers were created. The controller manager first knows all controllers in the NewControllerInitializers function of CMD / Kube Controller Manager / APP / controllermanager.go. Because the code is lengthy, only the Deployment Controller is taken as an example.
The logic for initializing the Deployment Controller is in the startDeploymentController function of CMD / Kube Controller Manager / APP / apps.go:
func startDeploymentController(ctx ControllerContext) (http.Handler, bool, error) {
if !ctx.AvailableResources[schema.GroupVersionResource{Group: "apps", Version: "v1", Resource: "deployments"}] {
return nil, false, nil
}
dc, err := deployment.NewDeploymentController(
ctx.InformerFactory.Apps().V1().Deployments(),
ctx.InformerFactory.Apps().V1().ReplicaSets(),
ctx.InformerFactory.Core().V1().Pods(),
ctx.ClientBuilder.ClientOrDie("deployment-controller"),
)
if err != nil {
return nil, true, fmt.Errorf("error creating Deployment controller: %v", err)
}
go dc.Run(int(ctx.ComponentConfig.DeploymentController.ConcurrentDeploymentSyncs), ctx.Stop)
return nil, true, nil
}
The most critical logic is deployment.NewDeploymentController, which actually creates the Deployment Controller, and the first three parameters of the creation function are Deployment, ReplicaSet and Pod Informer. As you can see, Informer's singleton factory provides Informer creation entries of different resources with ApiGroup as the path.
However, it should be noted that although. Apps().V1().Deployments() returns an instance of deploymentInformer type, deploymentInformer is not a real Informer (although it is named after Informer). It is just a template class. Its main function is to provide the creation template of Informer focusing on the specific resource Deployment:
// Deployments returns a DeploymentInformer.
func (v *version) Deployments() DeploymentInformer {
return &deploymentInformer{factory: v.factory, namespace: v.namespace, tweakListOptions: v.tweakListOptions}
}
The real logic of creating informer is in deploymentInformer.Informer() (client-go/informers/apps/v1/deployment.go). f.defaultInformer is the default Deployment Informer template creation method. An informer that only focuses on Deployment resources is created by passing the resource instance and the template method into the InformerFor method of the informer factory:
func (f *deploymentInformer) Informer() cache.SharedIndexInformer {
return f.factory.InformerFor(&appsv1.Deployment{}, f.defaultInformer)
}
Simply sort it out:
- You can obtain a specific type of Informer template class (i.e. deploymentInformer here) through the Informer factory
- What really creates this particular resource is the Informer() method of the Informer template class
- The Informer() method simply creates a real Informer through the InformerFor of the Informer factory
The template method (design pattern) is used here. Although there is a detour, you can refer to the following figure to sort it out. The key is that Informer's differentiated creation logic is delegated to the template class:
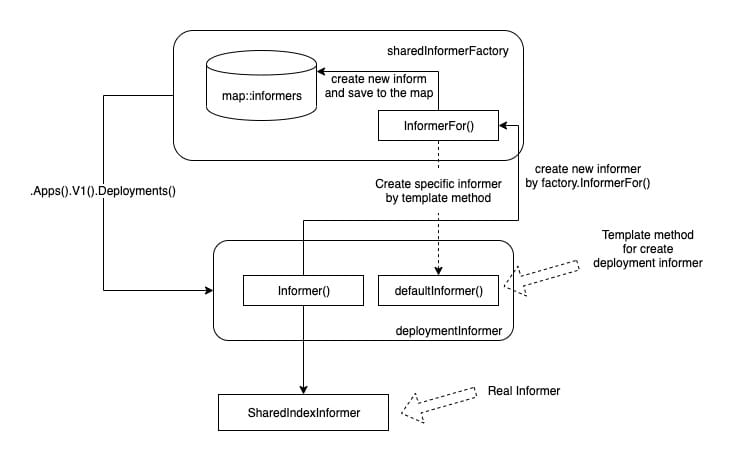
Finally, a structure named sharedIndexInformer will be instantiated and really assume the responsibility of Informer. This instance is also registered in the Informer factory map.
Running of Informer
Because the real Informer instance is an object of type sharedIndexInformer, when the Informer factory starts (execute the Start method), sharedIndexInformer is actually running.
sharedIndexInformer is a component in client go. Although its Run method is just dozens of lines, it undertakes a lot of work. This is the most interesting part of Controller Manager.
func (s *sharedIndexInformer) Run(stopCh <-chan struct{}) {
defer utilruntime.HandleCrash()
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, s.indexer)
cfg := &Config{
Queue: fifo,
ListerWatcher: s.listerWatcher,
ObjectType: s.objectType,
FullResyncPeriod: s.resyncCheckPeriod,
RetryOnError: false,
ShouldResync: s.processor.shouldResync,
Process: s.HandleDeltas,
}
func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.controller = New(cfg)
s.controller.(*controller).clock = s.clock
s.started = true
}()
// Separate stop channel because Processor should be stopped strictly after controller
processorStopCh := make(chan struct{})
var wg wait.Group
defer wg.Wait() // Wait for Processor to stop
defer close(processorStopCh) // Tell Processor to stop
wg.StartWithChannel(processorStopCh, s.cacheMutationDetector.Run)
wg.StartWithChannel(processorStopCh, s.processor.run)
defer func() {
s.startedLock.Lock()
defer s.startedLock.Unlock()
s.stopped = true // Don't want any new listeners
}()
s.controller.Run(stopCh)
}
The startup logic of sharedIndexInformer mainly does the following things:
- A queue named fifo was created
- An instance named controller was created and run
- cacheMutationDetector started
- Started the processor
These terms (or components) have not been mentioned before, and these four things are the core content of Controller Manager, so I will introduce them respectively below.
sharedIndexInformer
sharedIndexInformer is a shared Informer framework. Different controllers only need to provide a template class (such as deploymentInformer mentioned above) to create a specific Informer that meets their own needs.
sharedIndexInformer contains a bunch of tools to complete Informer's tasks. The main code is in client go / tools / cache / shared_ In Informer.go. Its creation logic is also included:
// NewSharedIndexInformer creates a new instance for the listwatcher.
func NewSharedIndexInformer(lw ListerWatcher, objType runtime.Object, defaultEventHandlerResyncPeriod time.Duration, indexers Indexers) SharedIndexInformer {
realClock := &clock.RealClock{}
sharedIndexInformer := &sharedIndexInformer{
processor: &sharedProcessor{clock: realClock},
indexer: NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers),
listerWatcher: lw,
objectType: objType,
resyncCheckPeriod: defaultEventHandlerResyncPeriod,
defaultEventHandlerResyncPeriod: defaultEventHandlerResyncPeriod,
cacheMutationDetector: NewCacheMutationDetector(fmt.Sprintf("%T", objType)),
clock: realClock,
}
return sharedIndexInformer
}
There are several things to pay attention to in creating logic:
- processor: provides the functions of EventHandler registration and event distribution
- indexer: provides the function of resource caching
- listerWatcher: provided by the template class, which contains the List and Watch methods of specific resources
- objectType: used to mark which specific resource type to focus on
- cacheMutationDetector: monitors the cache of Informer
In addition, it also includes the DeltaFIFO queue and controller mentioned in the startup logic above, which are introduced respectively below.
sharedProcessor
processor is a very interesting component in sharedIndexInformer. Controller Manager uses an Informer singleton factory to ensure that different controllers share the same Informer, but different controllers register different handlers for the shared Informer. How should Informer manage the registered handlers?
processor is a component used to manage registered handlers and distribute events to different handlers.
type sharedProcessor struct {
listenersStarted bool
listenersLock sync.RWMutex
listeners []*processorListener
syncingListeners []*processorListener
clock clock.Clock
wg wait.Group
}
The core work of sharedProcessor is around the Listener slice of listeners.
When we register a Handler to Informer, it will eventually be converted to an instance of a structure named processorListener:
func newProcessListener(handler ResourceEventHandler, requestedResyncPeriod, resyncPeriod time.Duration, now time.Time, bufferSize int) *processorListener {
ret := &processorListener{
nextCh: make(chan interface{}),
addCh: make(chan interface{}),
handler: handler,
pendingNotifications: *buffer.NewRingGrowing(bufferSize),
requestedResyncPeriod: requestedResyncPeriod,
resyncPeriod: resyncPeriod,
}
ret.determineNextResync(now)
return ret
}
This instance mainly contains two channel s and the Handler method registered outside. The processorListener object instantiated here will eventually be added to the sharedProcessor.listeners list:
func (p *sharedProcessor) addListener(listener *processorListener) {
p.listenersLock.Lock()
defer p.listenersLock.Unlock()
p.addListenerLocked(listener)
if p.listenersStarted {
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}
}
As shown in the figure, the Handler method in the Controller will eventually be added to the Listener, and the Listener will be append ed to the Listeners slice of the sharedProcessor.
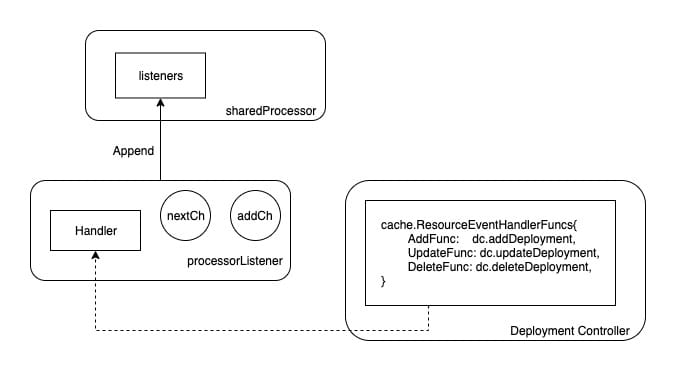
As mentioned earlier, sharedIndexInformer will run sharedProcessor when it is started, and the startup logic of sharedProcessor is related to these listener s:
func (p *sharedProcessor) run(stopCh <-chan struct{}) {
func() {
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
for _, listener := range p.listeners {
p.wg.Start(listener.run)
p.wg.Start(listener.pop)
}
p.listenersStarted = true
}()
<-stopCh
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
for _, listener := range p.listeners {
close(listener.addCh) // Tell .pop() to stop. .pop() will tell .run() to stop
}
p.wg.Wait() // Wait for all .pop() and .run() to stop
}
You can see that the run and pop methods of listener will be executed successively when sharedProcessor is started. Let's take a look at these two methods now.
Start of listener
Because the listener contains the handler methods registered by the Controller, the most important function of the listener is to trigger these methods when events occur, and the listener.run keeps getting events from the nextch channel and executing the corresponding handler:
func (p *processorListener) run() {
// this call blocks until the channel is closed. When a panic happens during the notification
// we will catch it, **the offending item will be skipped!**, and after a short delay (one second)
// the next notification will be attempted. This is usually better than the alternative of never
// delivering again.
stopCh := make(chan struct{})
wait.Until(func() {
// this gives us a few quick retries before a long pause and then a few more quick retries
err := wait.ExponentialBackoff(retry.DefaultRetry, func() (bool, error) {
for next := range p.nextCh {
switch notification := next.(type) {
case updateNotification:
p.handler.OnUpdate(notification.oldObj, notification.newObj)
case addNotification:
p.handler.OnAdd(notification.newObj)
case deleteNotification:
p.handler.OnDelete(notification.oldObj)
default:
utilruntime.HandleError(fmt.Errorf("unrecognized notification: %T", next))
}
}
// the only way to get here is if the p.nextCh is empty and closed
return true, nil
})
// the only way to get here is if the p.nextCh is empty and closed
if err == nil {
close(stopCh)
}
}, 1*time.Minute, stopCh)
}
As you can see, listener.run keeps getting events from the nextchchannel, but where do the events in the nextchchannel come from? The responsibility of listener.pop is to put events into nextchh.
listener.pop is a very delicate and interesting logic:
func (p *processorListener) pop() {
defer utilruntime.HandleCrash()
defer close(p.nextCh) // Tell .run() to stop
var nextCh chan<- interface{}
var notification interface{}
for {
select {
case nextCh <- notification:
// Notification dispatched
var ok bool
notification, ok = p.pendingNotifications.ReadOne()
if !ok { // Nothing to pop
nextCh = nil // Disable this select case
}
case notificationToAdd, ok := <-p.addCh:
if !ok {
return
}
if notification == nil { // No notification to pop (and pendingNotifications is empty)
// Optimize the case - skip adding to pendingNotifications
notification = notificationToAdd
nextCh = p.nextCh
} else { // There is already a notification waiting to be dispatched
p.pendingNotifications.WriteOne(notificationToAdd)
}
}
}
}
The reason why listener includes two channel s: addCh and nextchis because Informer cannot predict whether the event consumption speed of listener.handler is greater than that of event production. Therefore, a buffer queue named pendingNotifications is added to save future events.
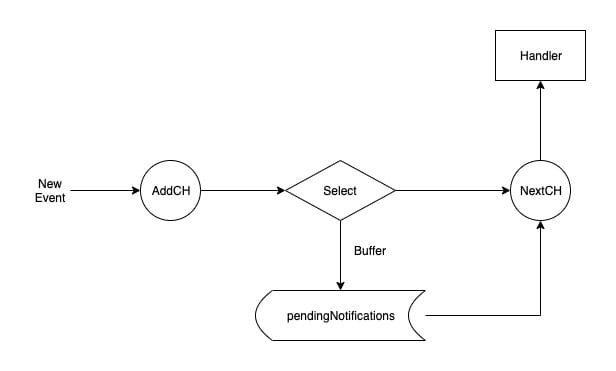
On the one hand, the pop method will keep getting the latest events from addCh to ensure that the producer will not block. Then judge whether there is a buffer. If so, add the event to the buffer. If not, try to push it to nextchh.
On the other hand, it will judge whether there are still events in the buffer. If there is still stock, it will be continuously passed to nextCh.
The pop method implements a distribution mechanism with buffer, so that events can flow from addCh to nextCh. But the question is, where did the addCh incident come from.
In fact, the source is very simple. listener has an add method, and the input parameter is an event. This method will push the new event into addCh. The add method is called by the sharedProcessor that manages all listeners.
As mentioned above, the responsibility of sharedProcessor is to manage all handlers and distribution events, and the real distribution is the distribution method:
func (p *sharedProcessor) distribute(obj interface{}, sync bool) {
p.listenersLock.RLock()
defer p.listenersLock.RUnlock()
if sync {
for _, listener := range p.syncingListeners {
listener.add(obj)
}
} else {
for _, listener := range p.listeners {
listener.add(obj)
}
}
}
So far, we have some clear:
- The Controller registers the Handler with Informer
- Informer maintains all handlers (listener s) through the shared processor
- When Informer receives an event, it distributes the event through sharedProcessor.distribute
- The Controller is triggered by the corresponding Handler to process its own logic
So the remaining question is where did the Informer event come from?
DeltaFIFO
Before analyzing Informer acquisition events, we need to talk about a very interesting gadget in advance, that is, the fifo queue created during sharedIndexInformer.Run:
fifo := NewDeltaFIFO(MetaNamespaceKeyFunc, s.indexer)
DeltaFIFO is a very interesting queue. The relevant code is defined in client go / tools / cache / delta_ Fifo.go. For a queue, the most important methods must be the Add method and Pop method. DeltaFIFO provides multiple Add methods. Although different methods are distinguished according to different event types (add/update/delete/sync), they will eventually execute queueActionLocked:
// queueActionLocked appends to the delta list for the object.
// Caller must lock first.
func (f *DeltaFIFO) queueActionLocked(actionType DeltaType, obj interface{}) error {
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
// If object is supposed to be deleted (last event is Deleted),
// then we should ignore Sync events, because it would result in
// recreation of this object.
if actionType == Sync && f.willObjectBeDeletedLocked(id) {
return nil
}
newDeltas := append(f.items[id], Delta{actionType, obj})
newDeltas = dedupDeltas(newDeltas)
if len(newDeltas) > 0 {
if _, exists := f.items[id]; !exists {
f.queue = append(f.queue, id)
}
f.items[id] = newDeltas
f.cond.Broadcast()
} else {
// We need to remove this from our map (extra items in the queue are
// ignored if they are not in the map).
delete(f.items, id)
}
return nil
}
The first parameter actionType of the queueActionLocked method is the event type:
const (
Added DeltaType = "Added" // Creation event obtained from the watch api
Updated DeltaType = "Updated" // Update events obtained by the watch api
Deleted DeltaType = "Deleted" // Delete events obtained from the watch api
Sync DeltaType = "Sync" // The List Api is triggered and the cache needs to be refreshed
)
It can be seen from the event type and queue entry method that this is a queue with business functions, not a simple "first in, first out". There are two very exquisite designs in the queue entry method:
- For queued events, first judge whether there are events that are not consumed by the resource, and then handle them appropriately
- If the list method finds that the resource has been deleted, it will not be processed
The second point is easy to understand. If a List request is triggered and it is found that the resources to be processed have been deleted, there is no need to re-enter the queue for processing. The first point needs to be viewed in combination with the queue method:
func (f *DeltaFIFO) Pop(process PopProcessFunc) (interface{}, error) {
f.lock.Lock()
defer f.lock.Unlock()
for {
for len(f.queue) == 0 {
// When the queue is empty, invocation of Pop() is blocked until new item is enqueued.
// When Close() is called, the f.closed is set and the condition is broadcasted.
// Which causes this loop to continue and return from the Pop().
if f.IsClosed() {
return nil, ErrFIFOClosed
}
f.cond.Wait()
}
id := f.queue[0]
f.queue = f.queue[1:]
if f.initialPopulationCount > 0 {
f.initialPopulationCount--
}
item, ok := f.items[id]
if !ok {
// Item may have been deleted subsequently.
continue
}
delete(f.items, id)
err := process(item)
if e, ok := err.(ErrRequeue); ok {
f.addIfNotPresent(id, item)
err = e.Err
}
// Don't need to copyDeltas here, because we're transferring
// ownership to the caller.
return item, err
}
}
The Pop method of DeltaFIFO has an input parameter, that is, the processing function. When leaving the queue, DeltaFIFO will first obtain all events of the resource according to the resource id, and then give them to the processing function.
The work flow is shown in the figure:
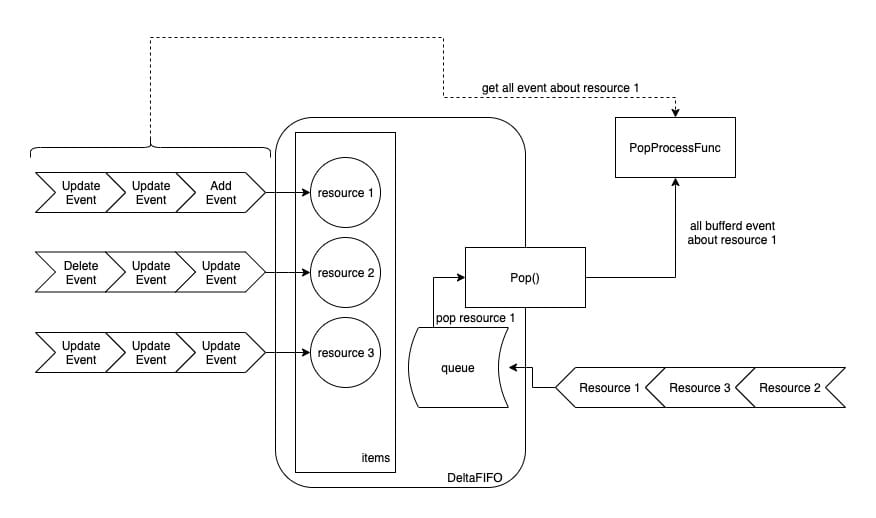
In general, the DeltaFIFO queue method will first judge whether the resource is already in items. If it already exists, it means that the resource has not been consumed (it is still queued in the queue), then directly append the event to items[resource_id]. If it is found that it is not in items, it will create items[resource_id] and append the resource ID to the queue.
The DeltaFIFO outgoing queue method gets the resource id from the queue, and then takes away all the events from the items, and finally calls the PopProcessFunc type processing function introduced by the Pop method.
Therefore, DeltaFIFO is characterized in that events (of resources) enter the queue and all events of the earliest resources enter the queue are obtained when leaving the queue. This design ensures that there will be no hunger due to the crazy manufacturing event of one resource, resulting in no opportunity for other resources to be processed.
controller
DeltaFIFO is a very important component, and the controller of Informer really makes it valuable.
Although the word controller is indeed used in the K8s source code, this controller is not a resource controller such as Deployment Controller. It is an event controller connecting the preceding and the following (events are obtained from the API Server and distributed to Informer for processing).
The controller has two responsibilities:
- Obtain the event from Api Server through list watch and push the event into DeltaFIFO
- Take the HandleDeltas method of sharedIndexInformer as a parameter to call the Pop method of DeltaFIFO
The definition of controller is very simple. Its core is Reflector:
type controller struct {
config Config
reflector *Reflector
reflectorMutex sync.RWMutex
clock clock.Clock
}
The code of Reflector is cumbersome, but its function is simple. It is to perform list watch through listerWatcher defined in sharedIndexInformer and push the obtained events into DeltaFIFO.
After the controller is started, the Reflector will be started first, and then the processLoop will be executed. Through an endless loop, the resource events to be processed will be read out from DeltaFIFO and handed over to the HandleDeltas method of sharedIndexInformer (assigned to config.Process when creating the controller).
func (c *controller) processLoop() {
for {
obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))
if err != nil {
if err == ErrFIFOClosed {
return
}
if c.config.RetryOnError {
// This is the safe way to re-enqueue.
c.config.Queue.AddIfNotPresent(obj)
}
}
}
}
If we check the HandleDeltas method of sharedIndexInformer again, we will find that the whole event consumption process has been opened:
func (s *sharedIndexInformer) HandleDeltas(obj interface{}) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
// from oldest to newest
for _, d := range obj.(Deltas) {
switch d.Type {
case Sync, Added, Updated:
isSync := d.Type == Sync
s.cacheMutationDetector.AddObject(d.Object)
if old, exists, err := s.indexer.Get(d.Object); err == nil && exists {
if err := s.indexer.Update(d.Object); err != nil {
return err
}
s.processor.distribute(updateNotification{oldObj: old, newObj: d.Object}, isSync)
} else {
if err := s.indexer.Add(d.Object); err != nil {
return err
}
s.processor.distribute(addNotification{newObj: d.Object}, isSync)
}
case Deleted:
if err := s.indexer.Delete(d.Object); err != nil {
return err
}
s.processor.distribute(deleteNotification{oldObj: d.Object}, false)
}
}
return nil
}
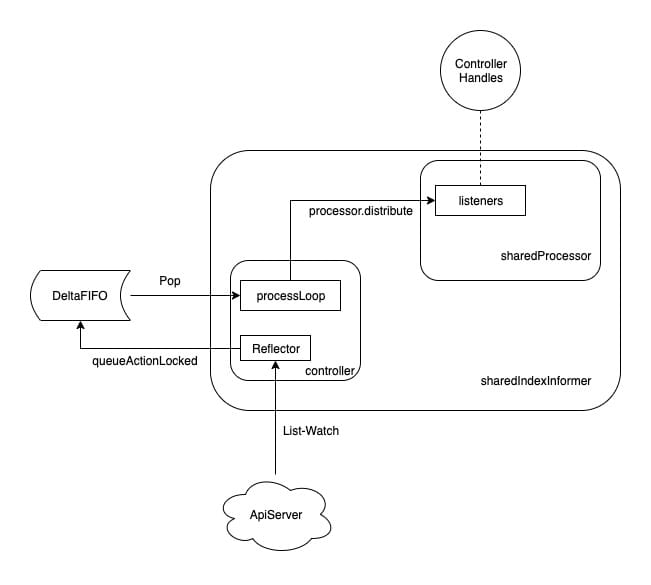
As we know earlier, the processor.distribute method can distribute events to all listener s, and the controller will use Reflector to get events from ApiServer and merge them into the queue, then take out all events of resources to be processed from the queue through processLoop, and finally call processor.distribute through the HandleDeltas method of sharedIndexInformer.
Therefore, we can sort out the whole event flow into the following figure:
Indexer
In the above, we have sorted out all the logic in the process of receiving and distributing events. However, in the HandleDeltas method of sharedIndexInformer, some logic is more noteworthy, that is, all events will update the s.indexer first and then distribute them.
As mentioned earlier, Indexer is a thread safe storage used as a cache to reduce the pressure on ApiServer when the resource Controller queries resources.
When any event is updated, the cache in the Indexer will be refreshed first, and then the event will be distributed to the resource controller. When the resource controller needs to obtain the resource details, it will first obtain them from the Indexer, so as to reduce unnecessary query requests to APIServer.
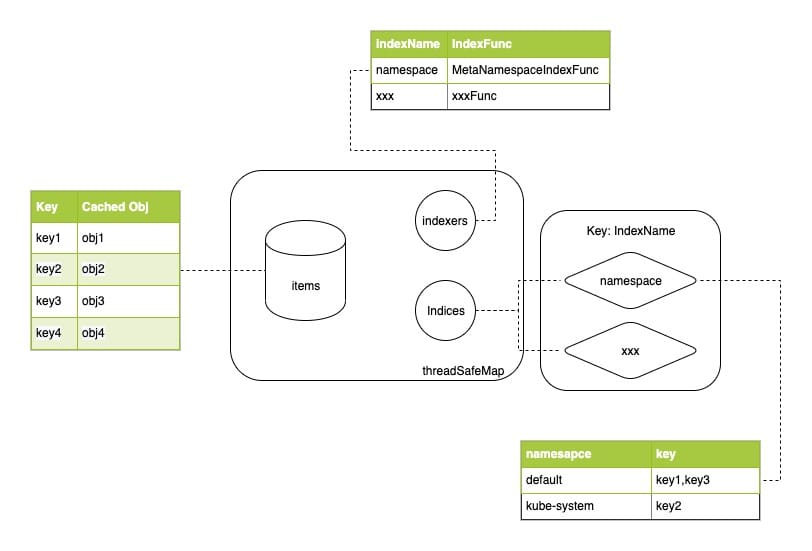
Indexer storage is implemented in client go / tools / cache / thread_ safe_ In store.go, the data is stored in threadSafeMap:
type threadSafeMap struct {
lock sync.RWMutex
items map[string]interface{}
// indexers maps a name to an IndexFunc
indexers Indexers
// indices maps a name to an Index
indices Indices
}
In essence, threadSafeMap is a map with a read-write lock. In addition, you can also define an index. The implementation of the index is very interesting. It is completed through two fields:
- Indexers is a map that defines several indexing functions. key is indexName and value is the function for indexing (calculating the index value of resources).
- Indexes saves the mapping relationship between index value and data key. Indexes is a two-layer map. The key of the first layer is indexName, which corresponds to Indexers to determine the method to calculate index value. Value is a map, which saves the association relationship between index value and resource key.
The related logic is relatively simple. Please refer to the following figure:
MutationDetector
In the HandleDeltas method of sharedIndexInformer, in addition to the data updated to s.indexer, the data is also updated to s.cacheMutationDetector.
At the beginning, when sharedIndexInformer is started, a cacheMutationDetector will be started to monitor the indexer cache.
Because the indexer cache is actually a pointer, multiple controllers access the indexer cache resources and actually obtain the same resource instance. If a Controller does not perform its duties and modifies the properties of resources, it will inevitably affect the correctness of other controllers.
The function of the MutationDetector is to regularly check whether the cache has been modified. When Informer receives a new event, the MutationDetector will save the pointer of the resource (like indexer) and the deep copy of the resource. By regularly checking whether the resource pointed to by the pointer is consistent with the deep copy to be stored, we can know whether the cached resource has been modified.
However, whether monitoring is enabled or not is determined by the environment variable Kube_ CACHE_ MUTATION_ If the environment variable is not set, the shared indexinformer instantiates the dummyMutationDetector and does nothing after startup.
If Kube_ CACHE_ MUTATION_ If the detector is true, the defaultCacheMutationDetector instantiated by sharedIndexInformer will periodically check the cache at an interval of 1s. If the cache is found to be modified, a failure processing function will be triggered. If the function is not defined, a panic will be triggered.
summary
This article explains the Controller Manager in a narrow sense. After all, it does not include a specific resource manager (Controller), but only explains how the Controller Manager "manages the Controller".
It can be seen that the Controller Manager has done a lot of work to ensure that the Controller can only focus on handling the events it cares about, and the core of these work is Informer. When you understand how Informer works together with other components, you can see what the Controller Manager has paved for the resource manager.