The article comes from WeChat official account: Go language circle.
1, Producer consumer model
Producer consumer model: a module (function, etc.) is responsible for generating data, which is processed by another module (the module here is generalized and can be class, function, collaboration, thread, process, etc.). The module that generates data is vividly called a producer; The module that processes data is called consumer.
Abstracting producers and consumers alone is not enough to be a producer consumer model. The model also needs a buffer between producers and consumers as an intermediary. The producer puts the data into the buffer, and the consumer takes the data out of the buffer.
The approximate structure is shown in the figure below.

Suppose you want to send an express, the general process is as follows
1. Seal the express - equivalent to the manufacturer's manufacturing data.
2. Deliver the express to the Express Center - equivalent to the producer putting the data into the buffer.
3. The postman takes the express out of the Express Center - which is equivalent to the consumer taking the data out of the buffer.
In this way, the buffer has the following benefits:
Decoupling: reduce the coupling between consumers and producers. With the Express Center, there is no need to directly hand over the express to the mailman. The mailman does not rely on the mailman. If the mailman changes one day, it will have no impact on the mailman.
Suppose that producers and consumers are two categories respectively. If the producer directly calls a method of the consumer, the producer will have a dependency on the consumer (that is, coupling). In the future, if the consumer's code changes, it may really affect the producer. If both depend on a buffer and there is no direct dependence between them, the coupling will be reduced accordingly.
Concurrency: the number of producers and consumers is not equal, and they can still maintain normal communication. Because the function calls are synchronous (or blocked), the producer has to wait there until the consumer's method does not return. If consumers are slow to process data, producers can only wait to waste time. After using producer consumer model, producer and consumer can be two independent concurrent subjects.
Once the producer throws the produced data into the buffer, he can produce the next data. Basically do not rely on the processing speed of consumers. The people who send the express directly throw the express into the Express Center and don't worry about it.
Cache: producer consumer speed mismatch, temporarily storing data. If the person who sends express mail sends more than one express at a time, the mailman can temporarily store other express in the express center if he can't send it. That is, the producer produces data too fast in a short time, and the consumer has no time to consume. The unprocessed data can be temporarily stored in the buffer.
2, Go language implementation
The most typical application of one-way channel is "producer consumer model". Channels are divided into buffered and unbuffered channels. When parameters in channel are passed, they are passed as references.
1. Unbuffered channel
Example code 1 is implemented as follows
package main
import "fmt"
func producer(out chan <- int) {
for i:=0; i<10; i++{
data := i*i
fmt.Println("Producer production data:", data)
out <- data // Buffer write data
}
close(out) //Close the pipe after writing
}
func consumer(in <- chan int){
// Also read the pipe
//for{
// val, ok := <- in
// if ok {
// fmt.Println("consumer gets data:", data)
// }else{
// fmt.Println("no data")
// break
// }
//}
// No synchronization mechanism is required. Do it first and then do it
// Blocking without data
for data := range in {
fmt.Println("Consumers get data:", data)
}
}
func main(){
// When passing parameters, explicit types are like implicit type conversion, and two-way pipes are converted to one-way pipes
ch := make(chan int) //Unbuffered channel
go producer(ch) // Subprocesses as producers
consumer(ch) // Main go process as consumer
}Here, the unbuffered channel is used. The producer produces data once and puts it into the channel, and then the consumer reads the data from the channel. If there is no data, he can only wait, that is, block until the pipeline is closed. Therefore, the macro is implemented simultaneously by producers and consumers.
In addition, only one go process execution producer is opened here, and the main go process executes the consumer. If a new go process is also used to execute the consumer, the go process in the main function needs to be blocked. Otherwise, the main go process exits without waiting for the consumer and producer to complete the execution, and the program ends directly, as shown in example code 3.
Every time the producer produces, the consumer can only get the data once, and the buffer has little effect. The results are as follows:
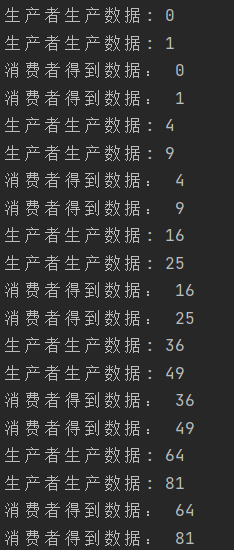
2. Buffered channel
Example code 2 is as follows
package main
import "fmt"
func producer(out chan <- int) {
for i:=0; i<10; i++{
data := i*i
fmt.Println("Producer production data:", data)
out <- data // Buffer write data
}
close(out) //Close the pipe after writing
}
func consumer(in <- chan int){
// No synchronization mechanism is required. Do it first and then do it
// Blocking without data
for data := range in {
fmt.Println("Consumers get data:", data)
}
}
func main(){
// When passing parameters, explicit types are like implicit type conversion, and two-way pipes are converted to one-way pipes
ch := make(chan int, 5) // Add buffer, 5
go producer(ch) // Subprocesses as producers
consumer(ch) // Main go process as consumer
}If there is a buffered channel, only modify ch: = make (channel int, 5) / / add a buffer sentence. As long as the buffer is not full, the producer can continue to put data into the buffer channel. As long as the buffer is not empty, the consumer can continue to read data from the channel. It has the characteristics of asynchrony and concurrency.
The results are as follows:
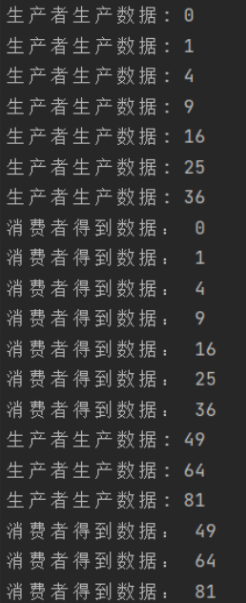
The reason why the terminal producer continuously prints data larger than the buffer capacity is that the terminal printing belongs to the system call and has delay. During IO operation, the producer writes to the pipeline and requests printing at the same time. The writing and reading of the pipeline does not match the printing speed of the terminal output.
3, Practical application
In practical application, the same public area is accessed at the same time and different operations are carried out at the same time. Can be divided into producer consumer models, such as order system.
After the orders of many users are released, they are put into the buffer or queue, and then the system reads them from the buffer for real processing. The system does not need to open up multiple threads to deal with multiple orders, so as to reduce the burden of system concurrency. Through the producer consumer mode, the order system is separated from the warehouse management system, and users can place orders (production data) at any time.
If the order system directly calls the warehouse system, the user must wait until the result of the warehouse system returns after clicking the place order button. This will be slow.
That is: the user becomes a producer, and the order processing management system becomes a consumer.
Code example 3 is as follows
package main
import (
"fmt"
"time"
)
// Simulated order object
type OrderInfo struct {
id int
}
// Production order - producer
func producerOrder(out chan <- OrderInfo) {
// Business generated order
for i:=0; i<10; i++{
order := OrderInfo{id: i+1}
fmt.Println("Generate order ID Is:", order.id)
out <- order // Write channel
}
// If it is not turned off, the consumer will be blocked and waiting for reading
close(out) // After the order is generated, close the channel
}
// Process order - Consumer
func consumerOrder(in <- chan OrderInfo) {
// Read the order from the channel and process it
for order := range in{
fmt.Println("Read order, order ID Is:", order.id)
}
}
func main() {
ch := make(chan OrderInfo, 5)
go producerOrder(ch)
go consumerOrder(ch)
time.Sleep(time.Second * 2)
}The logic here is similar to the above, except that an OrderInfo structure is used to simulate the order as the business processing object. The main thread uses time Sleep (time. Second * 2) blocks, otherwise the program stops immediately.
The results are as follows:

This is the end of this article about the implementation of a simple producer consumer model in Go language