In the face of computing intensive tasks, in addition to multi process, it is distributed computing. How to use Python to realize distributed computing? A very simple way to share today is to use Ray.
What is Ray
Ray is a distributed computing framework based on python. It adopts the dynamic graph computing model and provides a simple and general API to create distributed applications. It is very convenient to use. You can use decorators to easily realize distributed computing by modifying very little code, so that Python code originally running on a single machine can easily realize distributed computing. At present, it is mostly used for machine learning.
Ray features:
1. Provides simple primitives for building and running distributed applications.
2. Enables users to parallelize stand-alone code with little or no code changes.
3. Ray Core includes a large ecosystem of applications, libraries, and tools to support complex applications. For example, Tune, RLlib, RaySGD, Serve, Datasets, and Workflows.
Installing Ray
The easiest way to install the official version:
pip install -U ray pip install 'ray[default]'
For Windows systems, Visual C++ runtime must be installed
See official documents for other installation methods.
Using Ray
One decorator can handle distributed computing:
import ray ray.init() @ray.remote def f(x): return x * x futures = [f.remote(i) for i in range(4)] print(ray.get(futures)) # [0, 1, 4, 9]
Execute ray first Init(), and then add a decorator @ ray. Before the function to execute the distributed task Remote implements distributed computing. Decorator @ ray Remote can also decorate a class:
import ray ray.init() @ray.remote class Counter(object): def __init__(self): self.n = 0 def increment(self): self.n += 1 def read(self): return self.n counters = [Counter.remote() for i in range(4)] tmp1 = [c.increment.remote() for c in counters] tmp2 = [c.increment.remote() for c in counters] tmp3 = [c.increment.remote() for c in counters] futures = [c.read.remote() for c in counters] print(ray.get(futures)) # [3, 3, 3, 3]
Of course, the above distributed computing is still carried out on their own computers, but in a distributed form. During the execution of the program, you can enter http://127.0.0.1:8265/#/ To view the execution of distributed tasks:
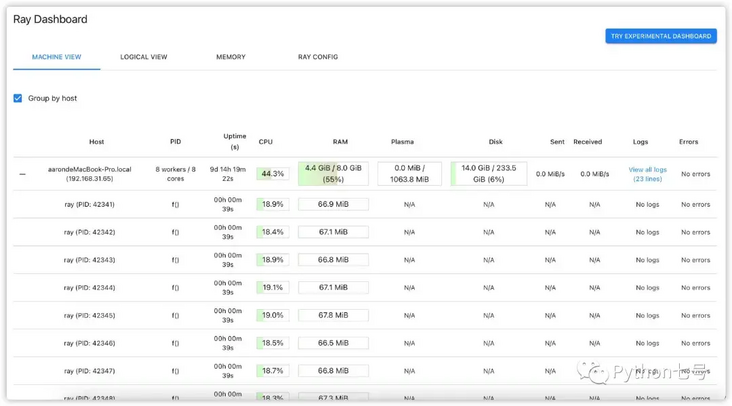
So how to implement Ray cluster computing? Then look down.
Using Ray clustering
One of Ray's advantages is the ability to utilize multiple machines in the same program. Of course, ray can run on one machine, because usually you have only one machine. But the real power is to use ray on a set of machines.
The Ray cluster consists of a head node and a set of working nodes. You need to start the head node first and give the worker node the head node address to form a cluster:
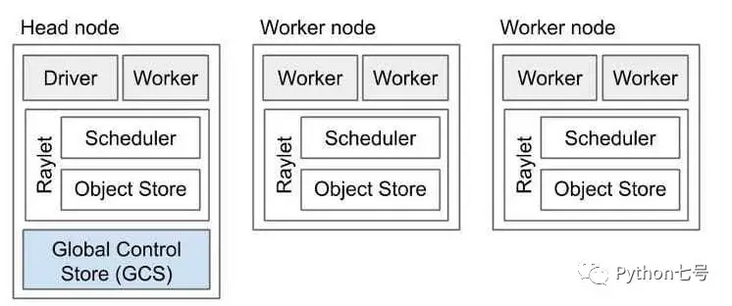
You can use the Ray Cluster Launcher to configure the machine and start a multi node Ray cluster. You can use cluster initiators on AWS, GCP, Azure, Kubernetes, alicloud, on premises and Staroid, and even on your custom node provider.
Ray clusters can also leverage Ray Autoscaler, which allows ray to interact with cloud providers to request or publish instances according to specifications and application workloads.
Now, let's quickly demonstrate the function of Ray cluster. Here, we use Docker to start two Ubuntu containers to simulate the cluster:
- Environment 1: 172.17 0.2 as head node
- Environment 2: 172.17 0.3 as a worker node, there can be multiple worker nodes
Specific steps:
1. Download ubuntu image
docker pull ubuntu
2. Start the ubuntu container and install the dependency
Start first
docker run -it --name ubuntu-01 ubuntu bash
Start second
docker run -it --name ubuntu-02 ubuntu bash
Check their IP addresses:
$ docker inspect -f "{{ .NetworkSettings.IPAddress }}" ubuntu-01
172.17.0.2
$ docker inspect -f "{{ .NetworkSettings.IPAddress }}" ubuntu-02
172.17.0.3Then install python, pip and ray inside the container
apt update && apt install python3 apt install python3-pip pip3 install ray
3. Start the head node and the worker node
Select one of the containers as the head node. Here, select 172.17 0.2, execution:
ray start --head --node-ip-address 172.17.0.2
The default port is 6379. You can use the -- port parameter to modify the default port. The results after startup are as follows:
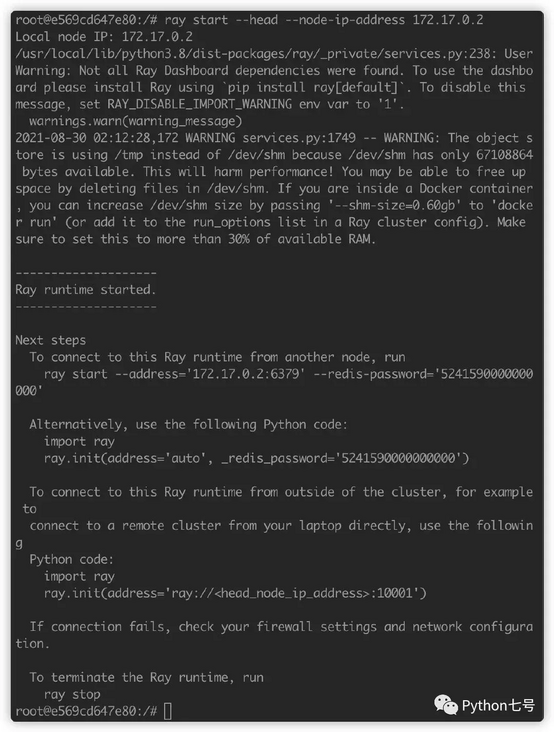
Ignoring the warning, you can see that a prompt is given. If you want to bind other nodes to the head, you can do the following:
ray start --address='172.17.0.2:6379' --redis-password='5241590000000000'
Execute the above command on another node to start the worker node:
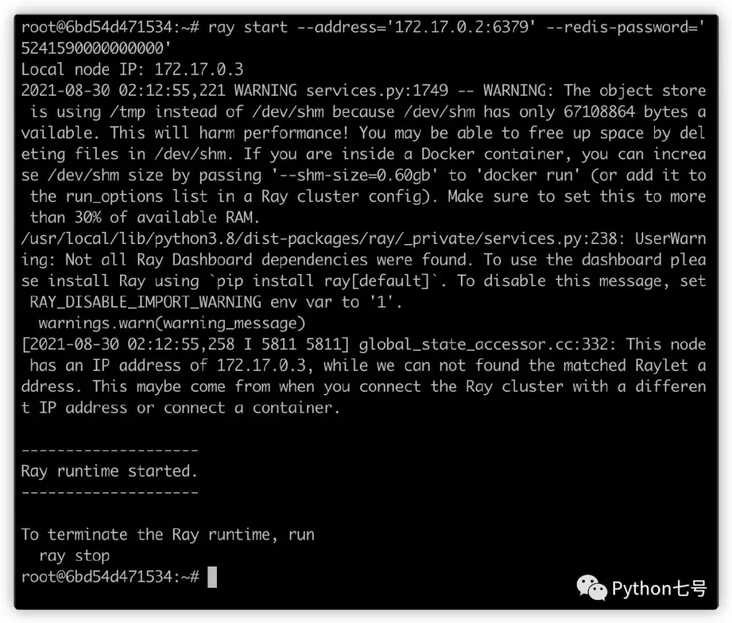
To close:
ray stop
4. Perform tasks
Select any node and execute the following script to modify ray Parameters of init() function:
from collections import Counter
import socket
import time
import ray
ray.init(address='172.17.0.2:6379', _redis_password='5241590000000000')
print('''This cluster consists o f
{} nodes in total
{} CPU resources in total
'''.format(len(ray.nodes()), ray.cluster_resources()['CPU']))
@ray.remote
def f():
time.sleep(0.001)
# Return IP address.
return socket.gethostbyname(socket.gethostname())
object_ids = [f.remote() for _ in range(10000)]
ip_addresses = ray.get(object_ids)
print('Tasks executed')
for ip_address, num_tasks in Counter(ip_addresses).items():
print(' {} tasks on {}'.format(num_tasks, ip_address))The results are as follows:
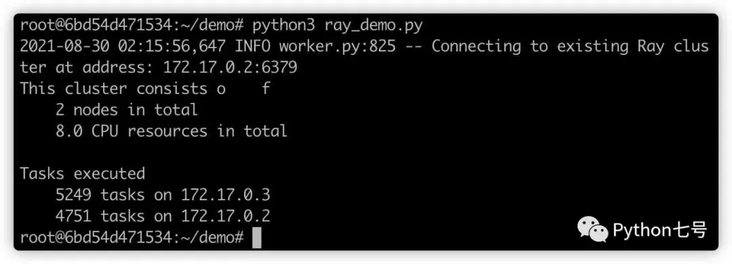
You can see 172.17 0.2 performed 4751 tasks, 172.17 0.3 implements 5249 tasks and realizes the effect of distributed computing.
Last words
With ray, you can implement parallel computing without using Python's multi process. Today's machine learning is mainly a computing intensive task. Without the help of distributed computing, the speed will be very slow. Ray provides a simple solution to realize distributed computing.