Have you ever focused on throughput when using message queuing?
Have you considered the factors affecting throughput?
Have you considered how to improve it?
Have you summarized best practices?
This article takes you to discuss the implementation of Go framework with high throughput on the consumer side of message queue. Let’s go!
Some thoughts on throughput
Write message queue throughput depends on the following two aspects
- network bandwidth
- Write speed of message queue (such as Kafka)
The best throughput is to make one of them full. In general, the intranet bandwidth will be very high and it is unlikely to be full. Therefore, it is natural to say that the write speed of the message queue is full, which needs to be balanced between two points
- What is the message size or number of bytes written in batch
- How long is the write delay
Go zero's periodic executor and ChunkExecutor are designed for this situation
The throughput of consuming messages from the message queue depends on the following two aspects
- The reading speed of the message queue. Generally, the reading speed of the message queue itself is fast enough compared with the speed of processing messages
- Processing speed, which depends on the business
The core problem here is that we cannot read too many messages into memory without considering the business processing speed, otherwise two problems may be caused:
- The memory occupation is too high. Even OOM and pod have memory limit
- When stopping pod, the accumulated messages are too late to be processed, resulting in message loss
Solution and Implementation
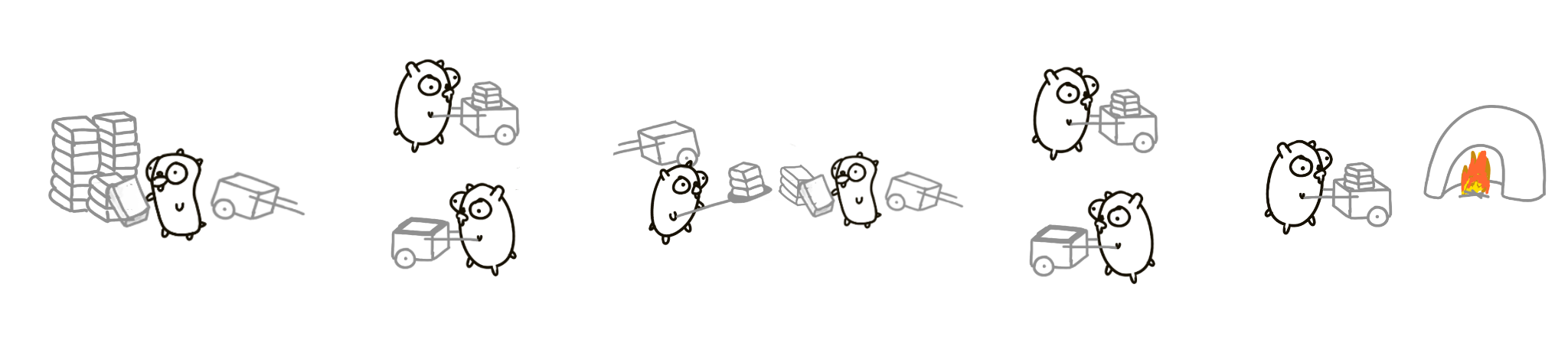
Borrow a picture from Rob Pike, which is similar to queue consumption. The four gophers on the left are taken from the queue, and the four gophers on the right are connected for processing. The ideal result is that the left and right speeds are basically the same, no one wastes, no one waits, and there is no accumulation at the middle exchange.
Let's see how go zero is implemented:
- Producer side
for {
select {
case <-q.quit:
logx.Info("Quitting producer")
return
default:
if v, ok := q.produceOne(producer); ok {
q.channel <- v
}
}
}If there is no exit event, a message will be read through produceOne and written to channel after success. The connection between reading and consumption can be well solved by using chan.
- Consumer end
for {
select {
case message, ok := <-q.channel:
if ok {
q.consumeOne(consumer, message)
} else {
logx.Info("Task channel was closed, quitting consumer...")
return
}
case event := <-eventChan:
consumer.OnEvent(event)
}
}Here, if you get the message, you can process it. When ok is false, it means that the channel has been closed and you can exit the whole processing cycle. At the same time, we also support pause/resume on redis queue. We used to use such a queue in social scenes, which can notify consumer s to pause and continue.
- Start the queue. With these, we can optimize the throughput by controlling the number of producers / consumers
func (q *Queue) Start() {
q.startProducers(q.producerCount)
q.startConsumers(q.consumerCount)
q.producerRoutineGroup.Wait()
close(q.channel)
q.consumerRoutineGroup.Wait()
}It should be noted here that the producer should be stopped first, and then wait for the consumer to finish processing.
Here, the core control code is basically finished. In fact, it looks very simple, and you can also go to https://github.com/tal-tech/go-zero/tree/master/core/queue See the complete implementation.
How to use
Basic usage process:
- Create producer or consumer
- Start queue
- Production news / consumption news
Corresponding to the queue, roughly as follows:
Create queue
// Producers create factories
producer := newMockedProducer()
// Consumers create factories
consumer := newMockedConsumer()
// Pass the creation factory functions of producers and consumers to NewQueue()
q := queue.NewQueue(func() (Producer, error) {
return producer, nil
}, func() (Consumer, error) {
return consumer, nil
})Let's see what parameters NewQueue needs:
- producer factory method
- consumer factory method
Pass the factory function of Producer & Consumer to queue, which is responsible for creating. The framework provides the interface between producer and Consumer and factory method definition, and then the control queue implementation of the whole process will be completed automatically.
Production message
We simulate by customizing a mockedProducer:
type mockedProducer struct {
total int32
count int32
// Use waitgroup to simulate the completion of tasks
wait sync.WaitGroup
}
// Method of implementing Producer interface: Produce()
func (p *mockedProducer) Produce() (string, bool) {
if atomic.AddInt32(&p.count, 1) <= p.total {
p.wait.Done()
return "item", true
}
time.Sleep(time.Second)
return "", false
}All producers in the queue must implement:
- Produce(): the logic of the production message is written by the developer
- AddListener(): adds an event listener
Consumption message
We simulate by customizing a mockedConsumer:
type mockedConsumer struct {
count int32
}
func (c *mockedConsumer) Consume(string) error {
atomic.AddInt32(&c.count, 1)
return nil
}Start queue
Start, and then verify whether the data transmission between the above producers and consumers is successful:
func main() {
// Create queue
q := NewQueue(func() (Producer, error) {
return newMockedProducer(), nil
}, func() (Consumer, error) {
return newMockedConsumer(), nil
})
// Starting panic also ensures that stop is executed to clean up resources
defer q.Stop()
// start-up
q.Start()
}The above is the simplest implementation example of queue. Through this core/queue framework, we have implemented message queue services based on redis and kafka, which have been fully tested in different business scenarios. You can also implement your own message queue service according to your actual business situation.
Overall design
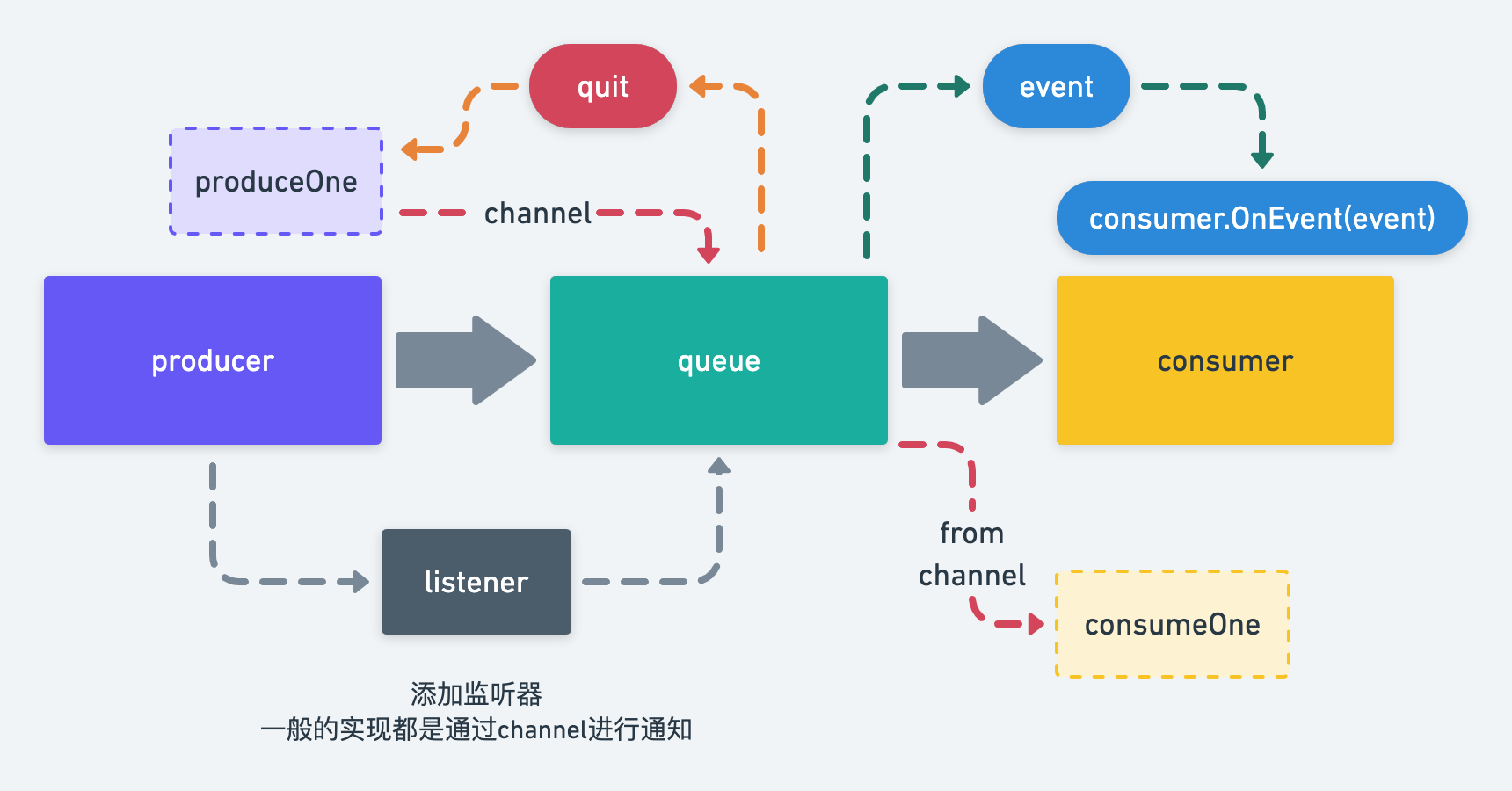
The overall process is shown in the figure above:
- All communication is carried out by the channel
- The number of producers and consumers can be set to match different business needs
- The specific implementation of Produce and consumption is defined by the developer, and queue is responsible for the overall process
summary
This article explains how to balance the speed of reading and processing messages from the queue through channel, and how to implement a general message queue processing framework. It also briefly shows how to implement a message queue processing service based on core/queue through mock example. You can implement a message queue processing service based on rocketmq in a similar way.
More articles about go-zero design and implementation can focus on the official account of "micro service practice".
Project address
https://github.com/tal-tech/go-zero
Welcome to go zero and star support us!
Wechat communication group
Focus on the "micro service practice" official account and click into the group to get the community community's two-dimensional code.
go-zero series articles see official account of "micro service practice".