How to optimize and improve the performance of the interface? Although this question is asked widely and there is no standard answer, the respondent needs to answer according to previous work experience or learning experience. According to the depth of the answer, it can reflect the general level of a programmer.
There are many reasons for interface performance problems. Different projects may have different interfaces for different reasons.
In this paper, I have summarized some effective methods to optimize interface performance:
1, Optimize index
First of all, you may first think of optimizing the index. Yes, the cost of optimizing the index is the smallest. You can view the time-consuming sql statements used by an interface by viewing the log or monitoring platform report. You may have the following questions:
1,This one sql Did you index it? 2,Does the added index take effect? 3,mysql Did you choose the wrong index?
The problem of verifying the index from several latitudes
1.1 no index
The key field of the where condition in the sql statement, or the sorting field after order by, forgets to add an index. This problem is very common in projects.
At the beginning of the project, due to the small amount of data in the table, there is little difference in sql query performance with or without index.
Later, with the development of business, there were more and more data in the table, so we had to add indexes.
//View the index of the table show index from `tb_order`; //View the table creation statement of the whole table and the index show create table `tb_order`;
You can see the index of the table through the above statement. Generally, if there is no index, you need to establish an index.
//alter table add index ALTER TABLE `tb_order` ADD INDEX idx_name (name); //create index add index CREATE INDEX idx_name ON `tb_order` (name);
You can add an index through the above method. It is worth noting that you can't modify the index through the command. You need to delete the index in mysql and add a new index again.
//Delete index method 1 ALTER TABLE `tb_order` DROP INDEX idx_name; //Delete index mode 2 DROP INDEX idx_name ON `tb_order`;
1.2. The index is not effective
Through the above method, you can query whether the index has been established, but has it taken effect? How to determine whether the index is effective? You can use the explain command to view the mysql execution plan, which will display the usage of the index.
//explain check index usage explain select * from `tb_order` where code='002';

Meaning of table fields:
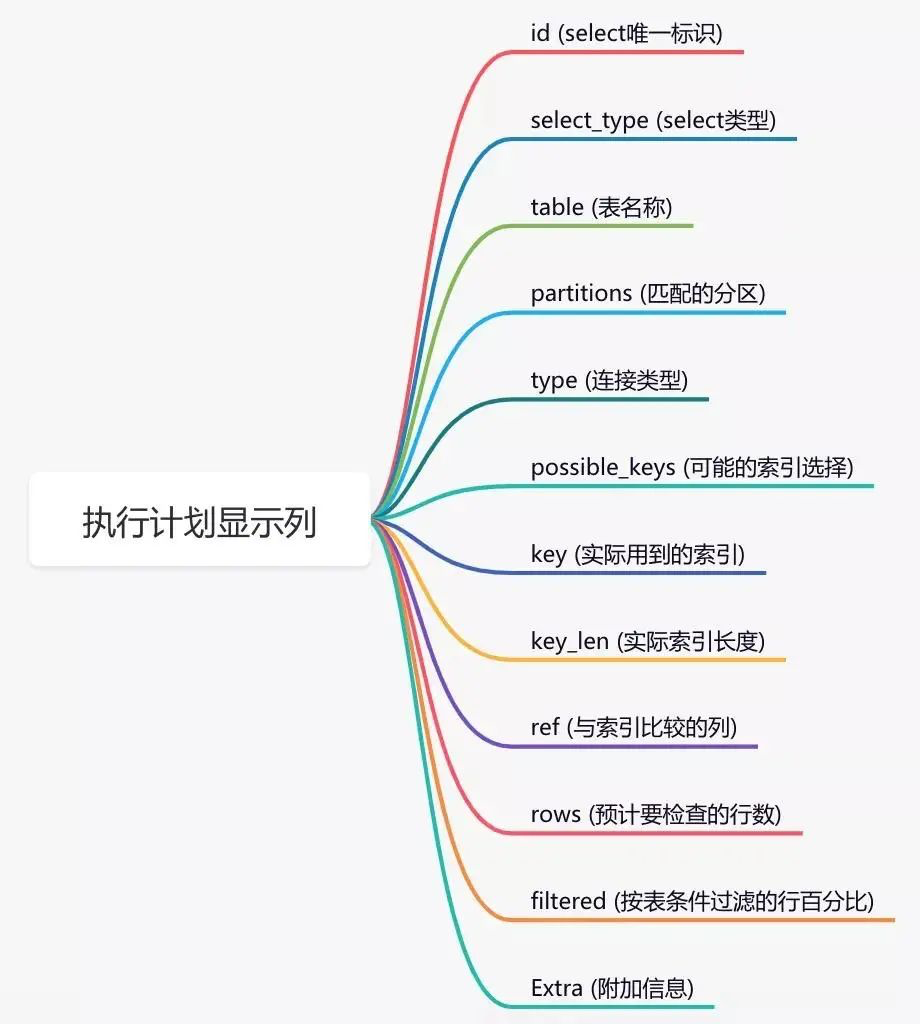
Experience summary: the sql statement does not take the index. Excluding the failure to build the index, the greatest possibility is that the index fails.
Soul torture: what are the reasons for the failure of the index?
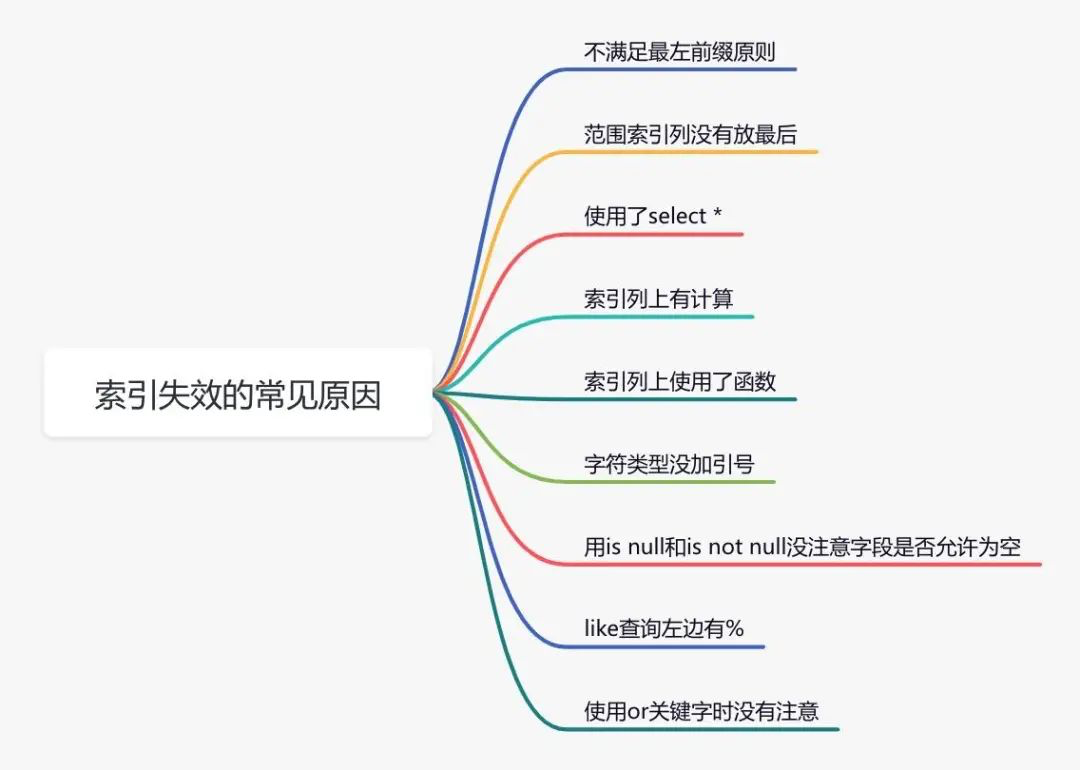
1.2. Wrong index
Have you ever encountered such a situation: it is obviously the same sql with different input parameters. Sometimes it's index a, but sometimes it's index b? This is because mysql will select the wrong index. If necessary, you can use force index to force the query sql to follow a certain index.
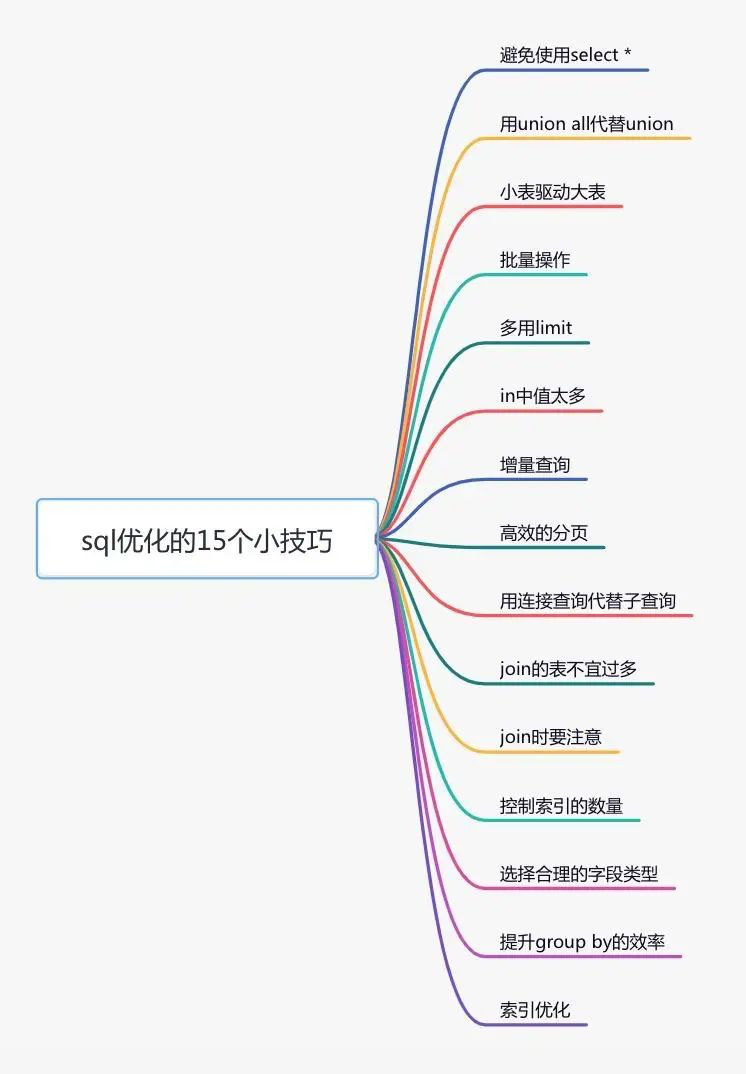
2, Optimize sql statements
After optimizing the index, there is no effect. What shall we do? Next, you can optimize sql statements. Compared with transforming code, the cost of optimizing sql is the smallest.
3, Remote call
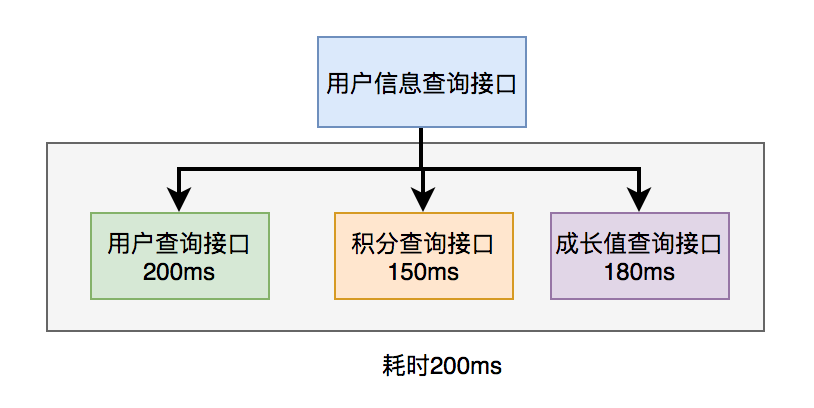
For example, there is such a business scenario: in the user information query interface, you need to return user name, gender, level, avatar, points, growth value and other information. The user name, gender, grade and avatar are in the user service, the points are in the point service, and the growth value is in the growth value service. In order to summarize these data and return them uniformly, another external interface service needs to be provided. Therefore, the user information query interface needs to call the user query interface, integral query interface and growth value query interface, and then the summary data is returned uniformly.
The calling process is as follows:
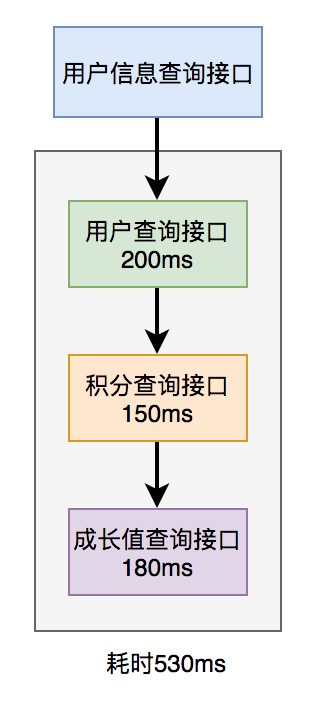
Obviously, the performance of this serial call to the remote interface is very poor. The total time-consuming of calling the remote interface is the sum of the time-consuming of all the remote interfaces. How to optimize the remote interface performance?
3.1 parallel call
Since the performance of serial calling multiple remote interfaces is very poor, why not change to parallel?
Before Java 8, the Callable interface can be implemented to obtain the results returned by the thread. Java 8 will implement this function through the CompleteFuture class. Take CompleteFuture as an example:
public UserInfo getUserInfo(Long id) throws InterruptedException, ExecutionException {
final UserInfo userInfo = new UserInfo();
CompletableFuture userFuture = CompletableFuture.supplyAsync(() -> {
getRemoteUserAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture bonusFuture = CompletableFuture.supplyAsync(() -> {
getRemoteBonusAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture growthFuture = CompletableFuture.supplyAsync(() -> {
getRemoteGrowthAndFill(id, userInfo);
return Boolean.TRUE;
}, executor);
CompletableFuture.allOf(userFuture, bonusFuture, growthFuture).join();
userFuture.get();
bonusFuture.get();
growthFuture.get();
return userInfo;
}
As a warm reminder, don't forget to use thread pool in these two ways. In the example, the executor is used to represent a custom thread pool. In order to prevent excessive threads in high concurrency scenarios.
3.2 data cache
The user information query interface mentioned above needs to call the user query interface, integral query interface and growth value query interface, and then the summary data is returned uniformly. Then, the data of user information, points and growth value can be stored in one place, such as redis. The stored data structure is the content required by the user information query interface. Then query the data directly from redis through the user id, and it's OK.
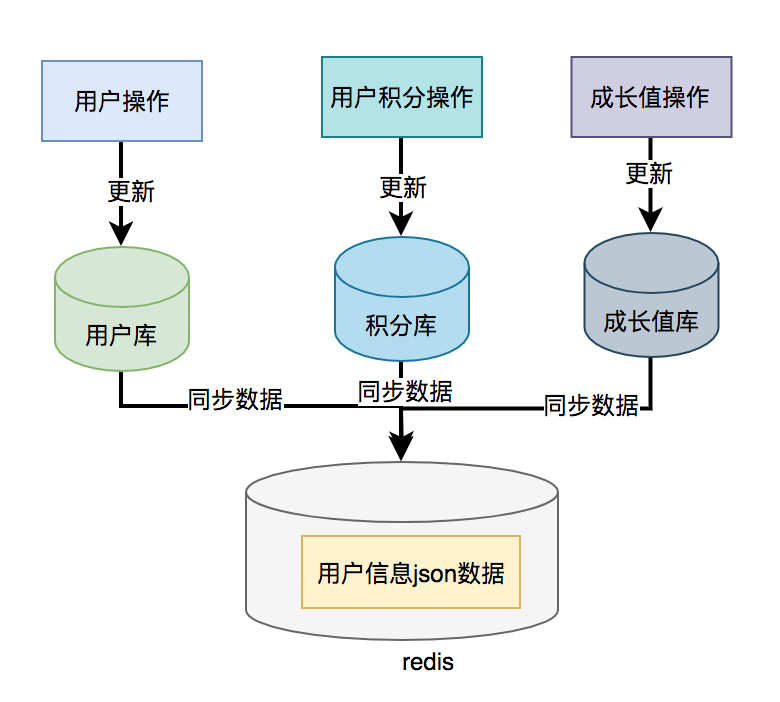
If a data caching scheme is used, data consistency problems may occur.
In most cases, it will be updated to the database first, and then synchronized to redis. However, this cross database operation may lead to inconsistent data on both sides.
4, Repeat call
Repeated calls can be seen everywhere in the code, but if they are not well controlled, it will greatly affect the performance of the interface.
4.1 circular query database
It is not advisable to call the query database in the loop. Once querying the database once, it is a remote call.
public List<User> queryUser(List<User> searchList) {
if (CollectionUtils.isEmpty(searchList)) {
return Collections.emptyList();
}
List<User> result = Lists.newArrayList();
searchList.forEach(user -> result.add(userMapper.getUserById(user.getId())));
return result;
}
The above case is to call the query database every time in the forEach loop to add user information to the collection. This is unreasonable. How to optimize it? The user id set is used to query the user interface in batch, and all data can be queried only once remotely.
public List<User> queryUser(List<User> searchList) {
if (CollectionUtils.isEmpty(searchList)) {
return Collections.emptyList();
}
List<Long> ids = searchList.stream().map(User::getId).collect(Collectors.toList());
return userMapper.getUserByIds(ids);
}
The size of the id set should be limited. It is best not to request too much data at one time. Depending on the actual situation, it is recommended to control the number of records requested each time within 500.
4.2 dead cycle
Sometimes if we don't pay attention, it will cause the code to loop.
while(true) {
if(condition) {
break;
}
System.out.println("do samething");
}
Here, the loop call of while(true) is used, which is often used in CAS spin lock. When the condition is equal to true, the loop will exit automatically. However, if the condition conditions are complex, once the judgment is incorrect or some logical judgments are written less, the problem of dead circulation may occur in some scenarios.
4.3 infinite recursion
public void printCategory(Category category) {
if(category == null
|| category.getParentId() == null) {
return;
}
System.out.println("Parent category name:"+ category.getName());
Category parent = categoryMapper.getCategoryById(category.getParentId());
printCategory(parent);
}
Normally, there is no problem with this code. However, if someone misoperates and points the parentId of a category to itself, infinite recursion will occur. As a result, the interface cannot return data all the time, and eventually a stack overflow will occur.
It is recommended to set a recursive depth when writing recursive methods. For example, if the maximum classification level has 4 levels, the depth can be set to 4. Then make a judgment in the recursive method. If the depth is greater than 4, it will return automatically, so as to avoid the infinite loop.
5, Asynchronous processing
For interface performance optimization, you need to re sort out the business logic to see if there is anything unreasonable in the design.
For example, in a user request interface, you need to do business operations, send station notifications, and record operation logs. For the convenience of implementation, if these logic are executed synchronously in the interface, it is bound to have a certain impact on the interface performance.
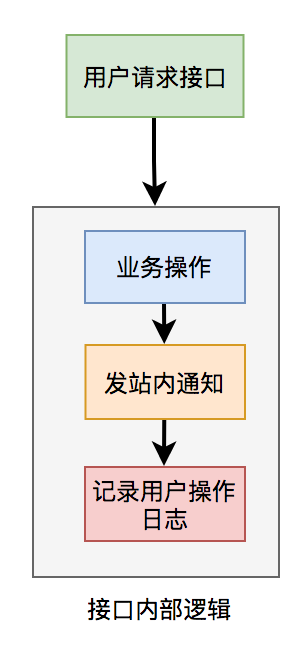
Follow a principle: the core logic can be executed synchronously and the library can be written synchronously. Non core logic, which can be executed asynchronously and written to the library asynchronously.
In the above example, the notification and user operation log functions in the sending station do not require high real-time performance. Even if the database is written later, the user receives the notification in the station or sees the user operation log later, which has little impact on the business, so it can be processed asynchronously.
Generally, there are two main types of asynchrony: multithreading and mq.
5.1 thread pool
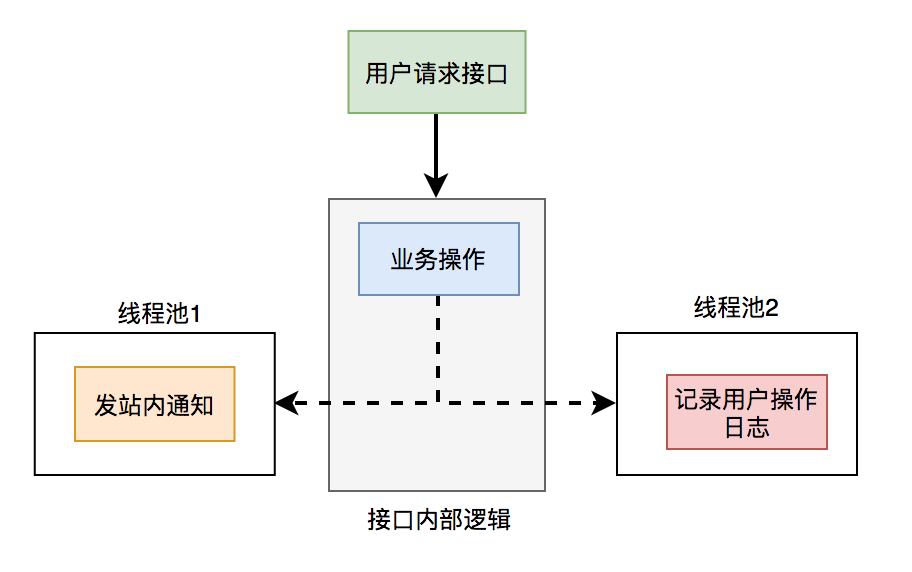
The notification and user operation log functions in the sending station are submitted to two separate thread pools for execution. The interface focuses on business operations. Other logic is handed over to threads for asynchronous execution, so that the performance of the interface can be improved instantly.
There is a problem with using thread pool: if the server restarts or the function to be executed is abnormal and cannot be retried, data will be lost. What about it? Middleware mq can be used.
5.1 mq
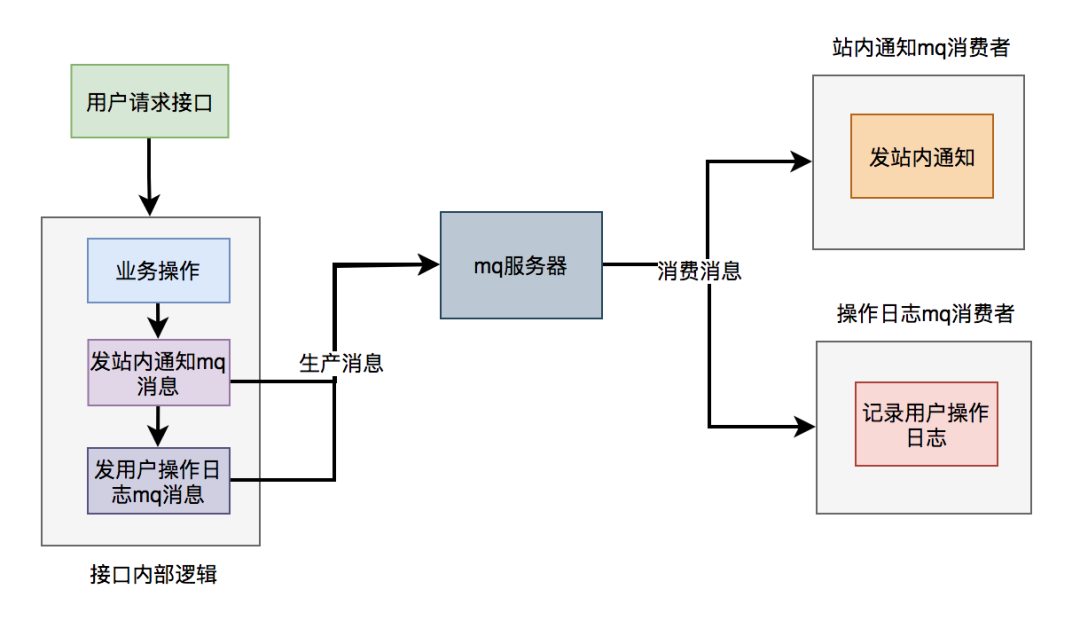
The functions of notification and user operation log in the sending station are not really implemented in the interface. It only sends mq messages to the mq server. Then, when mq consumers consume messages, they really perform these two functions.
6, Avoid big business
When developing projects using the spring framework, I like to use the @ Transactional annotation to provide transaction functions for convenience. Although this method can reduce a lot of code and improve development efficiency, it is also easy to cause big affairs and other problems.
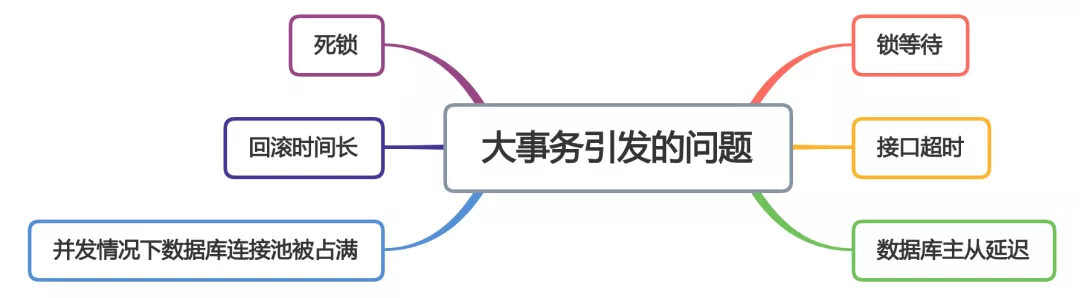
Large transaction problems may cause interface timeout and have a direct impact on the performance of the interface.
How to optimize major events? Use less@Transactional annotation Will query(select)Method is placed outside the transaction Avoid remote calls in transactions Avoid processing too much data at one time in a transaction Some functions can be non transactional Some functions can be processed asynchronously
7, Lock granularity
In some business scenarios, in order to prevent multiple threads from modifying a shared data concurrently and causing data exceptions, lock processing is usually selected. However, if the lock is not added well, the lock granularity will be too coarse, which will also greatly affect the interface performance.
7.1 synchronized
public synchronized doSave(String fileUrl) {
mkdir();
uploadFile(fileUrl);
sendMessage(fileUrl);
}
This method locks directly, and the granularity of the lock is a little coarse. Because the methods of uploading files and sending messages in doSave method do not need to be locked. Only when you create a directory method, you need to lock it.
The file upload operation is very time-consuming. If you lock the whole method, you need to wait until the whole method is executed before releasing the lock. Obviously, this will lead to poor performance of the method.
public void doSave(String path,String fileUrl) {
synchronized(this) {
if(!exists(path)) {
mkdir(path);
}
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}
After the transformation, the granularity of the lock suddenly became smaller. Only the concurrent directory creation function added the lock. Creating a directory is a very fast operation, and even locking has little impact on the performance of the interface.
Of course, there is no problem in the stand-alone service. However, in the currently deployed production environment, in order to ensure the stability of services, generally, the same service will be deployed in multiple nodes. Multi node deployment avoids the service unavailability caused by a node hanging. At the same time, it can also share the flow of the whole system to avoid excessive system pressure. But it brings a new problem: synchronized can only ensure that locking of one node is effective, but how to lock if there are multiple nodes?
Use distributed locks. At present, the mainstream distributed locks include redis distributed lock, zookeeper distributed lock and database distributed lock.
7.2 redis distributed lock
public void doSave(String path,String fileUrl) {
if(this.tryLock()) {
mkdir(path);
}
uploadFile(fileUrl);
sendMessage(fileUrl);
}
private boolean tryLock() {
try {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
} finally{
unlock(lockKey,requestId);
}
return false;
}
7.3 distributed database lock
There are three kinds of locks in mysql database:
- Table lock: fast locking, no deadlock. However, the locking granularity is large, the probability of lock conflict is the highest and the concurrency is the lowest.
- Row lock: deadlock occurs when locking is slow. However, the locking granularity is the smallest, the probability of lock conflict is the lowest, and the concurrency is the highest.
- Gap lock: the cost and locking time are bounded between table lock and row lock. It will have deadlock. The locking granularity is limited between table lock and row lock, and the concurrency is general.
The higher the concurrency, the better the interface performance. Therefore, the optimization direction of database lock is to use row lock first, gap lock second, and table lock second.
8, Paging processing
Sometimes, a certain interface is called to query data in batch, for example, batch query user information through user id. If too many users are queried at one time and the interface is called remotely, it will be found that the user query interface often times out.
List<User> users = remoteCallUser(ids);
How to optimize in this case? Paging processing
The request to obtain all data at one time is changed to multiple times, and only part of the user's data is obtained each time. Finally, it is merged and summarized.
8.1 synchronous call
List<List<Long>> allIds = Lists.partition(ids,200);
for(List<Long> batchIds:allIds) {
List<User> users = remoteCallUser(batchIds);
}
8.2 asynchronous call
List<List<Long>> allIds = Lists.partition(ids,200);
final List<User> result = Lists.newArrayList();
allIds.stream().forEach((batchIds) -> {
CompletableFuture.supplyAsync(() -> {
result.addAll(remoteCallUser(batchIds));
return Boolean.TRUE;
}, executor);
})
9, Add cache
To solve the interface performance problem, adding cache is a very efficient method. But you can't cache for caching. It depends on the specific business scenario. After all, adding cache will increase the complexity of the interface, which will lead to data inconsistency.
In some scenarios with low concurrency, for example, users can place an order without adding cache. There are also some scenarios, such as where the commodity classification is displayed on the home page of the mall. Suppose that the classification here is the data obtained by calling the interface, but the page is not static for the time being. If the interface for querying the classification tree does not use cache, but directly queries data from the database, the performance will be very poor.
How do I use caching?
9.1 redis cache
In relational databases, such as mysql, cascading menu query is a very time-consuming operation. At this time, if you want to use the cache, you can use jedis and redisson framework to get data directly from the cache.
String json = jedis.get(key);
if(StringUtils.isNotEmpty(json)) {
CategoryTree categoryTree = JsonUtil.toObject(json);
return categoryTree;
}
return queryCategoryTreeFromDb();
First, query whether there is menu data according to a key in redis. If there is, it will be converted into an object and returned directly. If no menu data is found in redis, query the menu data from the database again, and return if any.
In addition, we also need a job to query the menu data from the database and update it to redis every once in a while, so that we can directly obtain the menu data from redis every time in the future without accessing the database.
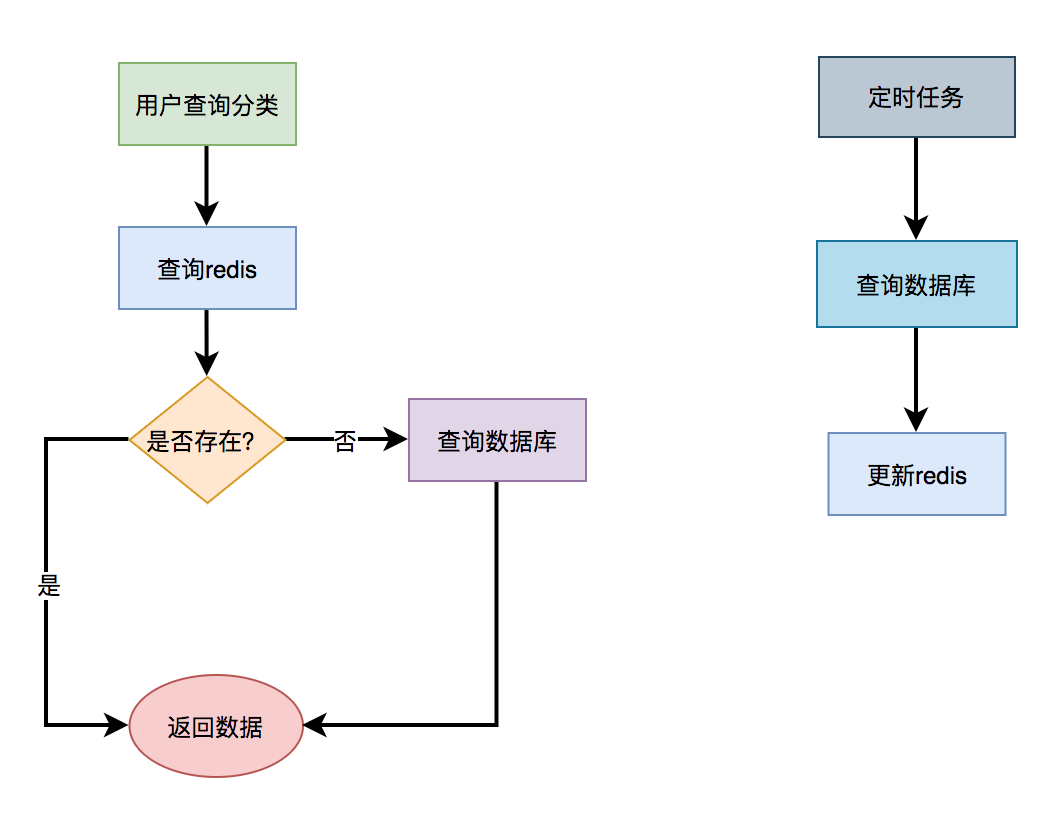
9.2 L2 cache
The above scheme is based on redis cache, although redis access speed is very fast. But after all, it is a remote call, and there are a lot of data in the menu tree, which is time-consuming in the process of network transmission. Is there any way to obtain data directly without remote request? Use L2 cache, that is, memory based cache. In addition to their own handwriting memory cache, the currently used memory cache frameworks include guava, Ehcache, caffeine, etc.
Take caffeine as an example, which is officially recommended by spring.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>2.6.0</version>
</dependency>
Step 2: configure the CacheManager and enable EnableCaching.
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager(){
CaffeineCacheManager cacheManager = new CaffeineCacheManager();
//Caffeine configuration
Caffeine<Object, Object> caffeine = Caffeine.newBuilder()
//Expires after a fixed time after the last write
.expireAfterWrite(10, TimeUnit.SECONDS)
//Maximum number of cache entries
.maximumSize(1000);
cacheManager.setCaffeine(caffeine);
return cacheManager;
}
}
Step 3: use the Cacheable annotation to get the data
@Service
public class CategoryService {
@Cacheable(value = "category", key = "#categoryKey")
public CategoryModel getCategory(String categoryKey) {
String json = jedis.get(categoryKey);
if(StringUtils.isNotEmpty(json)) {
CategoryTree categoryTree = JsonUtil.toObject(json);
return categoryTree;
}
return queryCategoryTreeFromDb();
}
}
Call categoryservice When using the getcategory () method, first get the data from the cafe cache. If you can get the data, you will directly return the data without entering the method body. If the data cannot be obtained, check the data from redis again. If it is found, the data is returned and put into the cafe. If no data is found, the data is directly obtained from the database and put into the cafe cache.
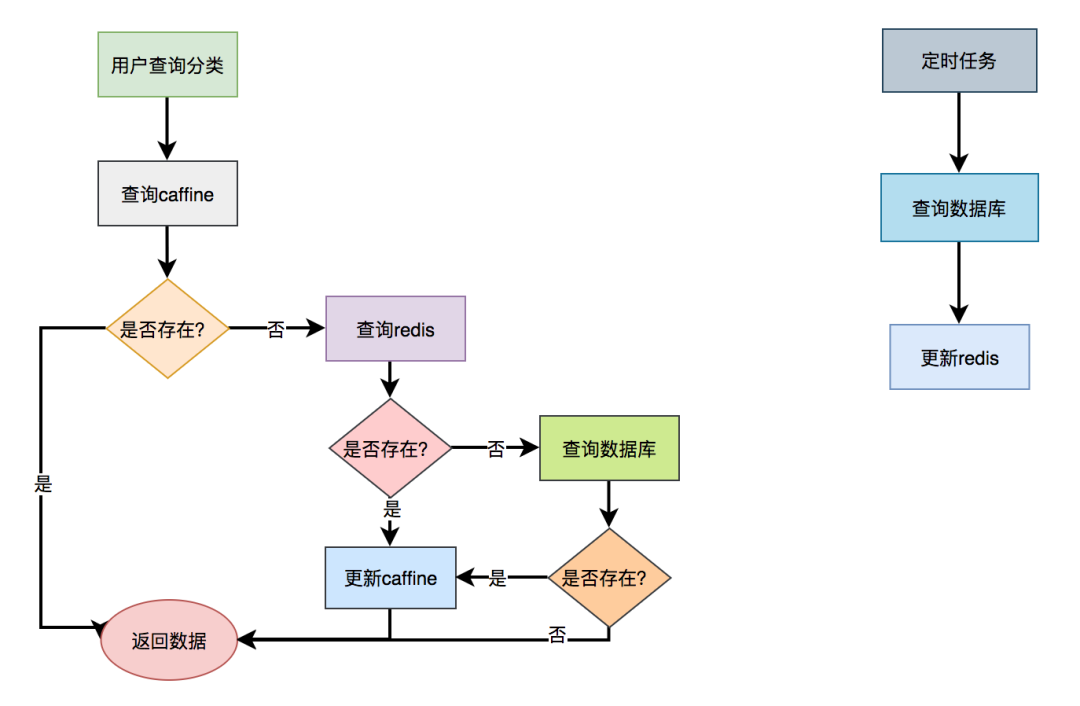
The performance of this scheme is better, but one disadvantage is that if the data is updated, the cache cannot be refreshed in time. In addition, if there are multiple server nodes, there may be different data on each node.
L2 cache not only improves our performance, but also brings the problem of data inconsistency. The use of L2 cache must be combined with the actual business scenarios. Not all business scenarios are applicable.
10, Sub database and sub table
Sometimes, the performance of the interface is limited not by others, but by the database. When the system develops to a certain stage, the user concurrency is large, there will be a large number of database requests, which need to occupy a large number of database connections. At the same time, it will bring the performance bottleneck of disk IO.
In addition, with more and more users, more and more data will be generated, and a table may not be saved. Due to the large amount of data, it will be very time-consuming even if the index is taken when querying data in sql statement.
What should I do at this time? It needs to be processed by database and table.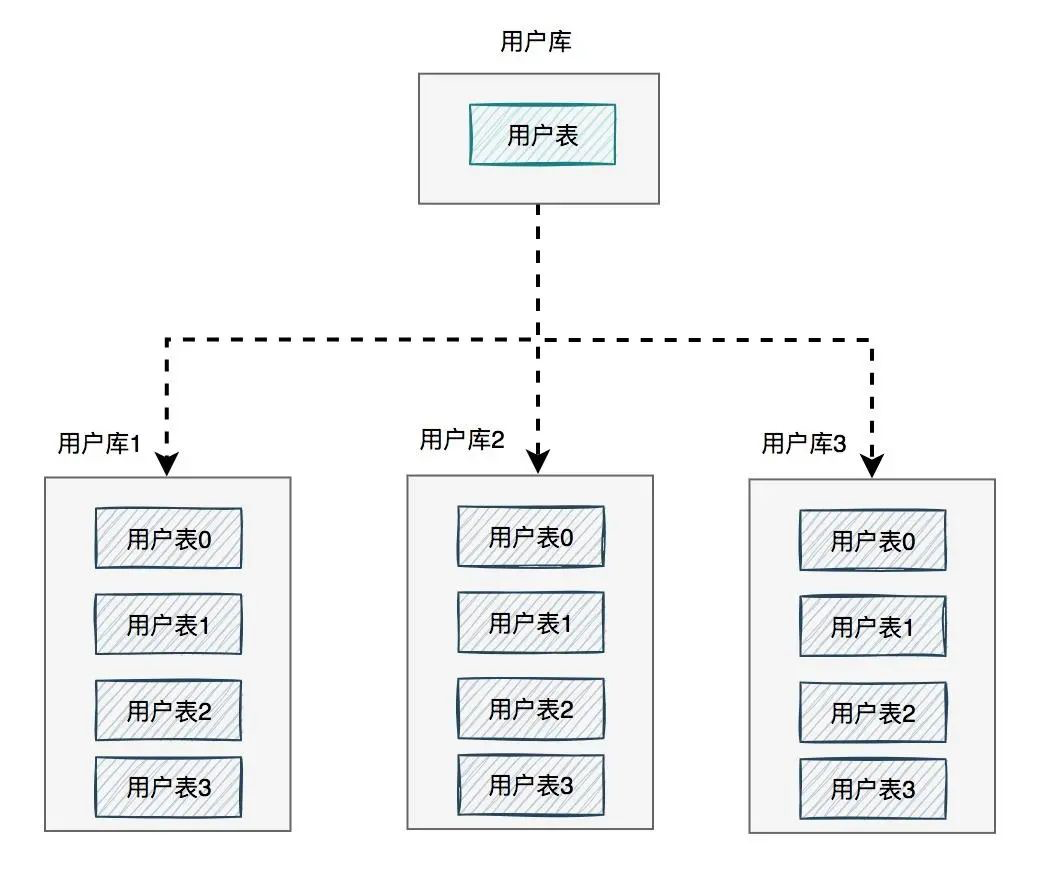
In the figure, the user library is divided into three libraries, and each library contains four user tables. If a user requests to come, first route to one of the user libraries according to the user id, and then locate to a table.
There are many routing algorithms:
- Take the module according to the ID, for example: id=7, there are 4 tables, then 7% 4 = 3, the module is 3, and route to user table 3.
- Specify an interval range for id. for example, if the value of id is 0-100000, the data will be stored in user table 0, and if the value of id is 100000-200000, the data will be stored in user table 1.
- Consistent hash algorithm
There are two main directions for sub database and sub table: vertical and horizontal.
To be honest, the vertical direction (i.e. business direction) is simpler.
In the horizontal direction (i.e. data direction), the functions of sub database and sub table are different and can not be confused.
- Sub database: to solve the problem of insufficient database connection resources and the performance bottleneck of disk IO.
- Split table: This is to solve the problem that the amount of data in a single table is too large. When querying data in sql statement, even if the index is taken, it is very time-consuming. In addition, it can also solve the problem of consuming cpu resources.
- Sub database and sub table: it can solve the problems of insufficient database connection resources, performance bottleneck of disk IO, time-consuming data retrieval and cpu resource consumption.
In some business scenarios, if the amount of concurrent users is large, but the amount of data to be saved is small, you can only divide the database, not the table.
In some business scenarios, if the number of concurrent users is not large, but a large number of users need to be saved, you can only divide tables, not databases. In some business scenarios, if there is a large amount of user concurrency and a large number of users need to be saved, you can divide databases and tables.