This article can quickly teach you how to crawl Sina News. I hope this article can help you! If you have any knowledge or suggestions you want to learn, please leave a message to the author~
How to quickly crawl Sina News and save it locally
- 1, Crawling scene
- 2, API traversal method crawling news
- 1. API found
- 2. Analyze key API parameters
- 3. Design crawler logic according to API parameters
- 4. Test use
- 3, Code implementation
- 1. Try to get dynamic pages
- 2. Watch URL
- 3. Procedure
- 3.1. Import required packages
- 3.2 write extraction module
- 1. The function is to obtain the news title, content, source, time and other information in the detail page through the incoming URL parameter.
- 2. Use lxml, write extraction module to write a function, use lxml to extract module, use xpath method to extract the news title, content, source, time and other information in the detail page.
- 3.3. Write storage module
- 3.4. Write reptile theme
- 4, Full code
-
This is a series and will be continuously updated:
Column link: Quick start crawler
1, Crawling scene
1. Web loading mode
- Dynamic web page
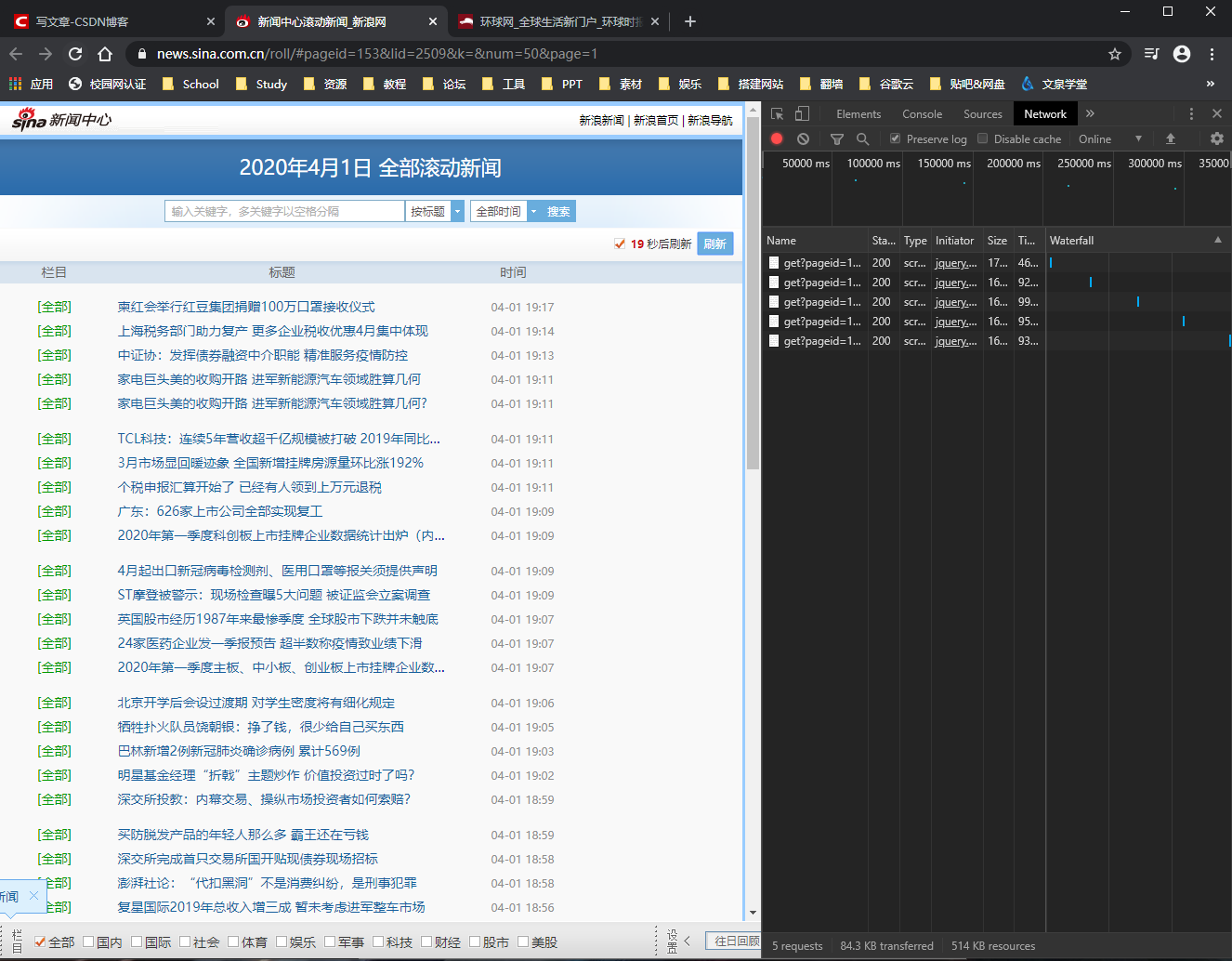
Dynamic web pages are different from traditional static web pages. If you want to crawl in the traditional way, you will make mistakes.
- Static web page

The image above is a traditional static web page.
2. Web page structure
List page - details page
API traversal
2, API traversal method crawling news
1. API found
- Use the developer tool network module to find the API
- API: https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.7210316507361691&callback=jQuery1112011987950839178185_1585738993071&_=1585738993083
2. Analyze key API parameters
- Pageid: should be the allocation parameter of sina API list
- Num: the number of news per page. You can change this parameter by
- Page: the number of pages in the news list. This parameter can be modified to traverse
3. Design crawler logic according to API parameters
- First, use APII to traverse the news URL
- Then get the detailed page according to the news URL and extract the data we want
4. Test use
3, Code implementation
1. Try to get dynamic pages
import requests print(requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.7210316507361691&callback=jQuery1112011987950839178185_1585738993071&_=1585738993083").content.decode("utf-8"))
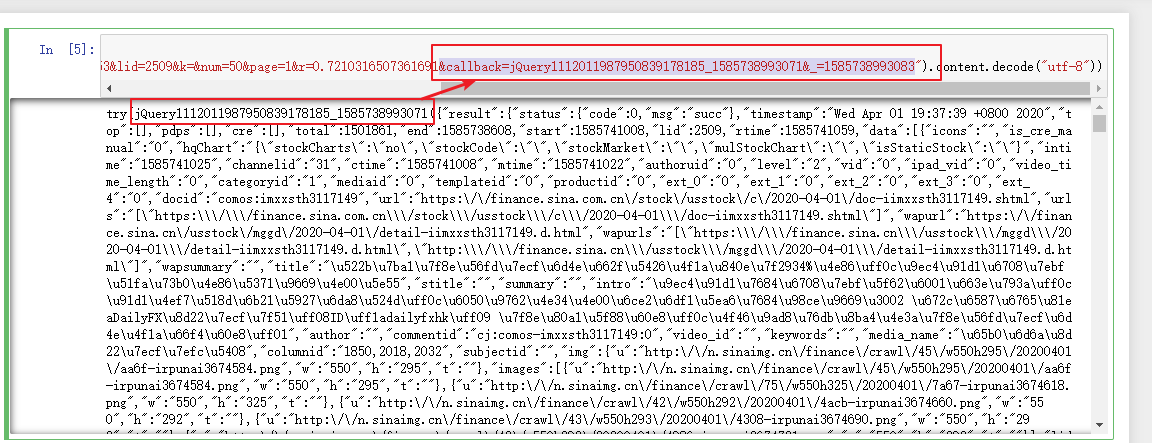
First of all, we can see that there is overlap between URL links and the results obtained. We can try to simplify URL links. At the same time, because the format itself is "utf-8", we can change the format to "Unicode"_ escape“
So we can get the modules we want.
We can use it json.loads() get string
import requests import json print(json.loads(requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.7210316507361691").content))

2. Watch URL
https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page=1&r=0.7210316507361691
At this time, we may use an online tool such as timestamp:
Address: https://tool.lu/timestamp/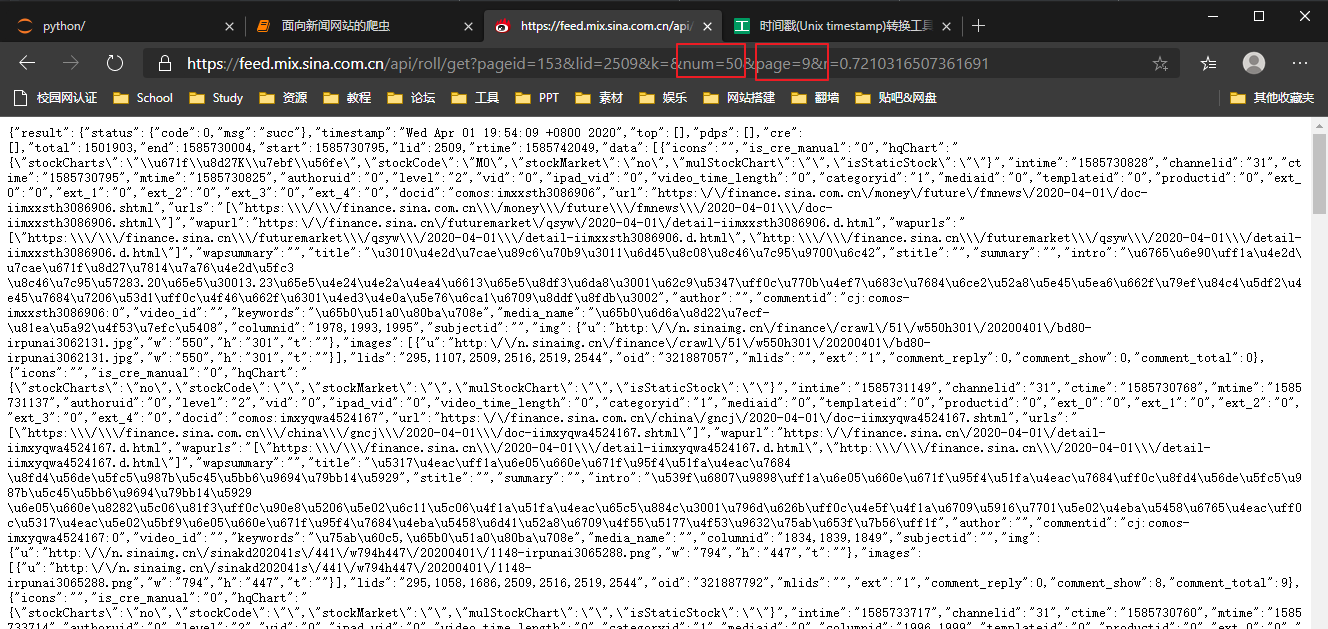
In the red box above, it is found through the test:
num controls the overall content of the page
Page shows the contents of the page
Let's start with the following test
The results are as follows: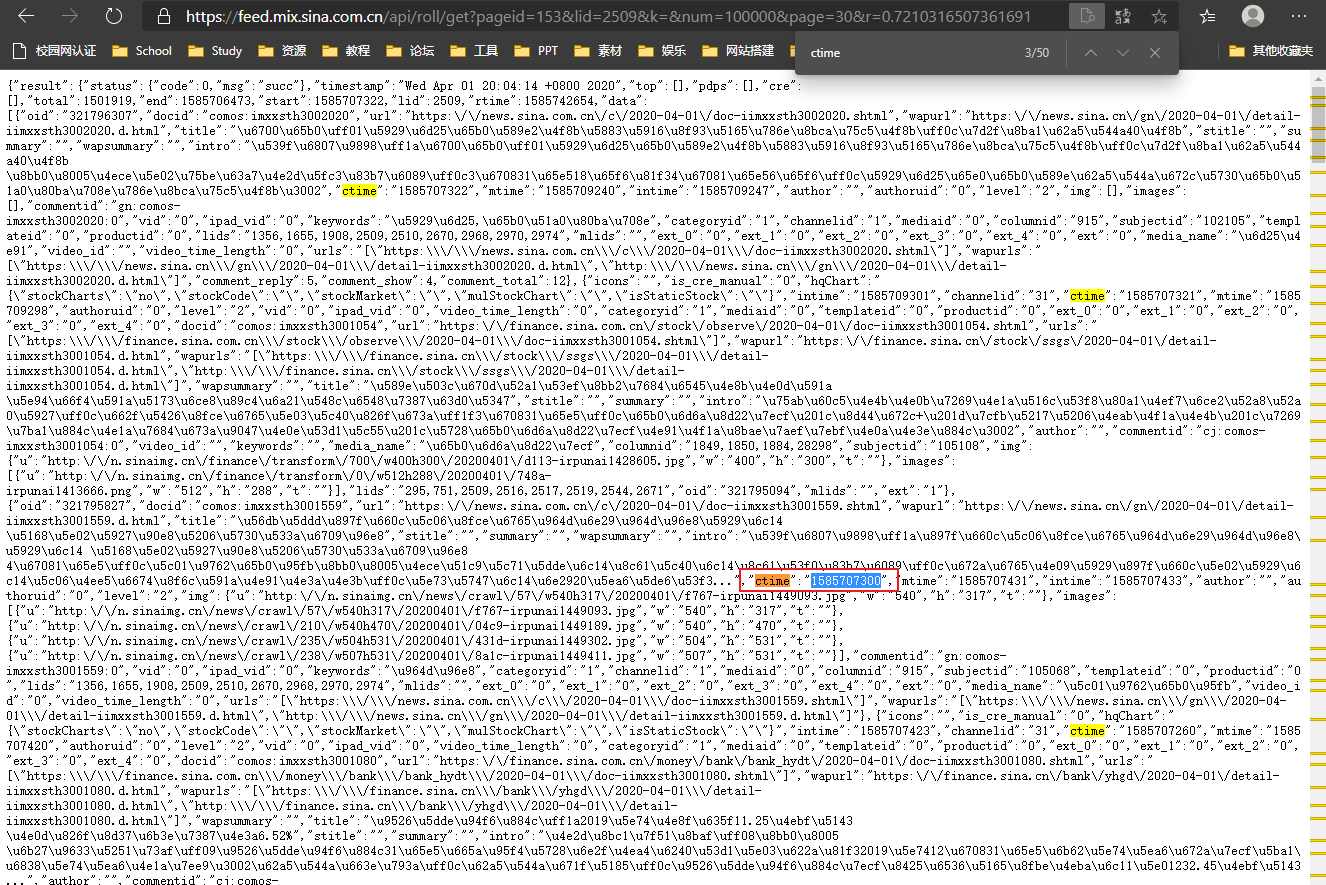
At this time, we look up the value of ctime and transform the time through the time stamp: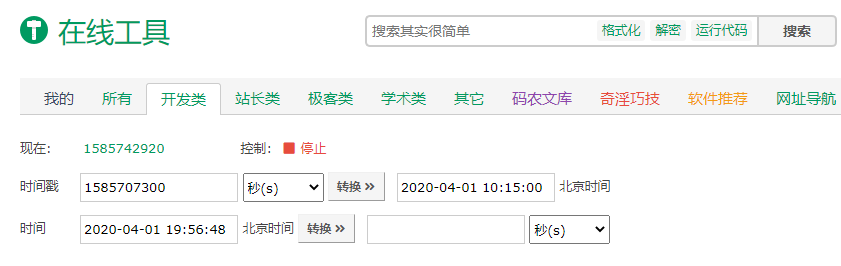
The following code is the key point
3. Procedure
3.1. Import required packages
#Import required packages import codecs #Used to store crawled information from pybloom_live import ScalableBloomFilter # For URL de duplication import requests #Used to initiate a request and obtain web page information import json #Processing data in json format from bs4 import BeautifulSoup as bs #For data extraction from lxml import etree #For data extraction import re #Regular language library
3.2 write extraction module
1. The function is to obtain the news title, content, source, time and other information in the detail page through the incoming URL parameter.
#Define a function. The function is to obtain the news title, content, source, time and other information in the detail page through the incoming URL parameter. #Function name: getdetailpagebybs; required parameter: URL def getdetailpagebybs(url): detail = {} #Create a dictionary to store URL, title, newstime and other information detail["url"] = url #Save the URL time into the corresponding key value in the detail dictionary page=requests.get(url).content #use requests.get Method to obtain the web page code. Since bs4 can automatically decode the URL code, no decode is needed here html=bs(page, "lxml") #Using the lxml parser title=html.find(class_="main-title") #Get the title information in the news page. There is only one "class = main title" in the page, so use find print(title.text) #Show news headlines detail["title"] = title.text #Save the news title as text in the corresponding key value in the detail dictionary artibody=html.find(class_="article") #Using find method to get article information in news web page #print(artibody.text) detail["artibody"]=artibody.text#. . . . . . . date_source = html.find(class_="date-source") #Use find method to get date source information in news page #Because different tag elements are used between different news detail pages, direct extraction may result in errors, so judgment statements are used to distinguish crawling if date_source.a: #Determine whether the date source node contains the 'a' element #print(date_source.span.text) detail["newstime"]=date_source.span.text #Extract time information from 'span' tag #print(date_source.a.text) detail["newsfrom"] =date_source.a.text #Extract news source information from 'a' tag else: #print(date_source("span")[0].text) detail["newstime"] =date_source("span")[0].text #Extract the time information contained in the 'span' label #print(date_source("span")[1].text) detail["newsfrom"] =date_source("span")[1].text#Extract news source information contained in the 'span' tag #You can also use regular expressions to extract information #print(date_source.prettify()) r=re.compile("(\d{4}year\d{2}month\d{2}day \d{2}:\d{2})") #Writing regular expressions of time information re_newstime=r.findall(date_source.text) #Using findall method, according to the written regular statement, from date_ Time information contained in the source node detail["re_newstime"] =re_newstime.text #Save the news time into the corresponding key value in the detail dictionary return detail #The return value of the function is the dictionary where the extracted information is stored
2. Use lxml, write extraction module to write a function, use lxml to extract module, use xpath method to extract the news title, content, source, time and other information in the detail page.
#Define a function. The function is to obtain the news title, content, source, time and other information in the detail page through the incoming URL parameter. #Function name: getdetailpagebylxml; required parameter: URL def getdetailpagebylxml(url): detail={} #Create a dictionary to store URL, title, newstime and other information detail["url"]=url #Store the URL in the corresponding key value in the dictionary page = requests.get(url).content.decode("utf-8") #Get the source code of the web page and use utf-8 encoding #Because the structure of the web page may change with the update of the web site and other reasons, when using xpath method to extract information, the xpath of copying elements from the web page may not be directly used #For example, the xpath of the date source element copied from the web page in this example is "/ / * [@ id="top_bar"]/div/div[2]", according to the directly copied xpath, the element information cannot be obtained normally #You need to modify and adjust manually. After adjusting to "/ / div [@ class = \" date source \ ", you can get the element information normally html = etree.HTML(page) title = html.xpath("/html/head/title/text()")[0] #Extracting title information using xpath method detail["title"]=title #Store the title in the corresponding key value in the dictionary print(title) artibody = html.xpath("//div[@class=\"article\"]/p//text()") #Extract article information using xpath method detail["artibody"]=''.join(artibody) # The article body is an original list object, which is connected by the join method date_source = html.xpath("//div[@class=\"date-source\"]//text()") detail["newstime"]=date_source[1] detail["newsfrom"]=date_source[3] #Regular expressions can also be used to extract information and parse regular modules in the same function as 2.1 #print(date_source.prettify()) r=re.compile("(\d{4}year\d{2}month\d{2}day \d{2}:\d{2})") re_newstime=r.findall(date_source.text) detail["re_newstime"] =re_newstime.text return detail
3.3. Write storage module
Write a function, use codecs package to store the extracted information into a file in a specified location
#Function name: savenews; required parameters: data, new def savenews(data,new): fp = codecs.open('.\\sinaNews\\'+new+'.txt', 'a+', 'utf-8') fp.write(json.dumps(data, ensure_ascii=False)) fp.close()
3.4. Write reptile theme
Use the above two modules to run the crawler
1. Set global variables
#Initialize global variables #Use ScalableBloomFilter module to de reprocess the obtained URL urlbloomfilter=ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH) page = 1 #Set page number for initial crawling error_url=set() #Create a collection for error URL links
2. Get URL
- Get URL due to Sina News page in this case
It's a dynamic web page, so it can't be crawled directly. You need to view the NetWork of the web page through the developer tool, find the API URL of the web page, and use it as the initial URL for crawling. The number of pages to be crawled is controlled by splicing parameter 'page'. - Use the loop to control the crawler, and call the extraction module and storage module written before to run the crawler
1. Extract modules and enclosures with beautifulsop
#Extract modules and enclosures with beautifulsop #Set the upper limit of crawling page. Because it is only used for case presentation, only the news data of the previous page will be crawled here while page <= 1: #Start to get url list with API as index data = requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page="+str(page)) #Splicing URL and obtaining index page information if data.status_code == 200: #Get the web page data when the request page returns 200 (correct) #json the acquired data data_json = json.loads(data.content) news=data_json.get("result").get("data") #Get the data in the data node under the result node, which is the information of the news details page #From the news detail page information list news, use for loop to traverse the information of each news detail page for new in news: # Duplicate check, extract the URL from new, and use scalable bloom filter to duplicate check if new["url"] not in urlbloomfilter: urlbloomfilter.add(new["url"]) #Put the crawled URL into urlbloom filter try: #print(new) #bs4 is used in extraction module detail = getdetailpagebybs(new["url"]) #Enclosure save to txt #savenews(detail,new['docid'][-7:])################################################################# except Exception as e: error_url.add(new["url"]) #Save the URL that failed to crawl normally to the collection error_url page+=1 #Page number plus 1
2. Extract modules and enclosures with lxml
while page <= 1: #Start to get url list with API as index data = requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page="+str(page)) #Splicing URL and obtaining index page information if data.status_code == 200: #Get the web page data when the request page returns 200 (correct) #json the acquired data data_json = json.loads(data.content) news=data_json.get("result").get("data") #Get the data in the data node under the result node, which is the information of the news details page #From the news detail page information list news, use for loop to traverse the information of each news detail page for new in news: # Duplicate check, extract the URL from new, and use scalable bloom filter to duplicate check if new["url"] not in urlbloomfilter: urlbloomfilter.add(new["url"]) #Put the crawled URL into urlbloom filter try: #print(new) #Using lxml for extraction module detail=getdetailpagebylxml(new["url"]) #Enclosure save to txt #savenews(detail,new['docid'][-7:])####################################################### except Exception as e: error_url.add(new["url"]) #Save the URL that failed to crawl normally to the collection error_url page+=1 #Page number plus 1
4, Full code
import codecs #Used to store crawled information from pybloom_live import ScalableBloomFilter # For URL de duplication import requests #Used to initiate a request and obtain web page information import json #Processing data in json format from bs4 import BeautifulSoup as bs #For data extraction import re #Regular language library def getdetailpagebybs(url): detail = {} # Create a dictionary to store URL, title, newstime and other information detail["url"] = url # Save the URL time into the corresponding key value in the detail dictionary page = requests.get(url).content # use requests.get Method to obtain the web page code. Since bs4 can automatically decode the URL code, no decode is needed here html = bs(page, "lxml") # Using the lxml parser title = html.find(class_="main-title") # Get the title information in the news page. There is only one "class = main title" in the page, so use find print(title.text) # Show news headlines detail["title"] = title.text # Save the news title as text in the corresponding key value in the detail dictionary artibody = html.find(class_="article") # Using find method to get article information in news web page print(artibody.text) detail["artibody"] = artibody.text # . . . . . . . date_source = html.find(class_="date-source") # Use find method to get date source information in news page # Because different tag elements are used between different news detail pages, direct extraction may result in errors, so judgment statements are used to distinguish crawling if date_source.a: # Determine whether the date source node contains the 'a' element print(date_source.span.text) detail["newstime"] = date_source.span.text # Extract time information from 'span' tag print(date_source.a.text) detail["newsfrom"] = date_source.a.text # Extract news source information from 'a' tag else: print(date_source("span")[0].text) detail["newstime"] = date_source("span")[0].text # Extract the time information contained in the 'span' label print(date_source("span")[1].text) detail["newsfrom"] = date_source("span")[1].text # Extract news source information contained in the 'span' tag return detail # The return value of the function is the dictionary where the extracted information is stored def savenews(data,new): fp = codecs.open('D:/sinaNews/'+new+'.txt', 'a+', 'utf-8') fp.write(json.dumps(data, ensure_ascii=False)) fp.close() #Use ScalableBloomFilter module to de reprocess the obtained URL urlbloomfilter=ScalableBloomFilter(initial_capacity=100, error_rate=0.001, mode=ScalableBloomFilter.LARGE_SET_GROWTH) page = 1 #Set page number for initial crawling error_url=set() #Create a collection for error URL links #Extract modules and enclosures with beautifulsop #Set the upper limit of crawling page, while page <= 10: #Start to get url list with API as index data = requests.get("https://feed.mix.sina.com.cn/api/roll/get?pageid=153&lid=2509&k=&num=50&page="+str(page)) #Splicing URL and obtaining index page information if data.status_code == 200: #Get the web page data when the request page returns 200 (correct) #json the acquired data data_json = json.loads(data.content) news=data_json.get("result").get("data") #Get the data in the data node under the result node, which is the information of the news details page #From the news detail page information list news, use for loop to traverse the information of each news detail page for new in news: # Duplicate check, extract the URL from new, and use scalable bloom filter to duplicate check if new["url"] not in urlbloomfilter: urlbloomfilter.add(new["url"]) #Put the crawled URL into urlbloom filter try: print(new) #bs4 is used in extraction module detail = getdetailpagebybs(new["url"]) #Enclosure save to txt savenews(detail,new['docid'][-7:])################################################################# except Exception as e: error_url.add(new["url"]) #Save the URL that failed to crawl normally to the collection error_url page+=1 #Page number plus 1
The results are as follows: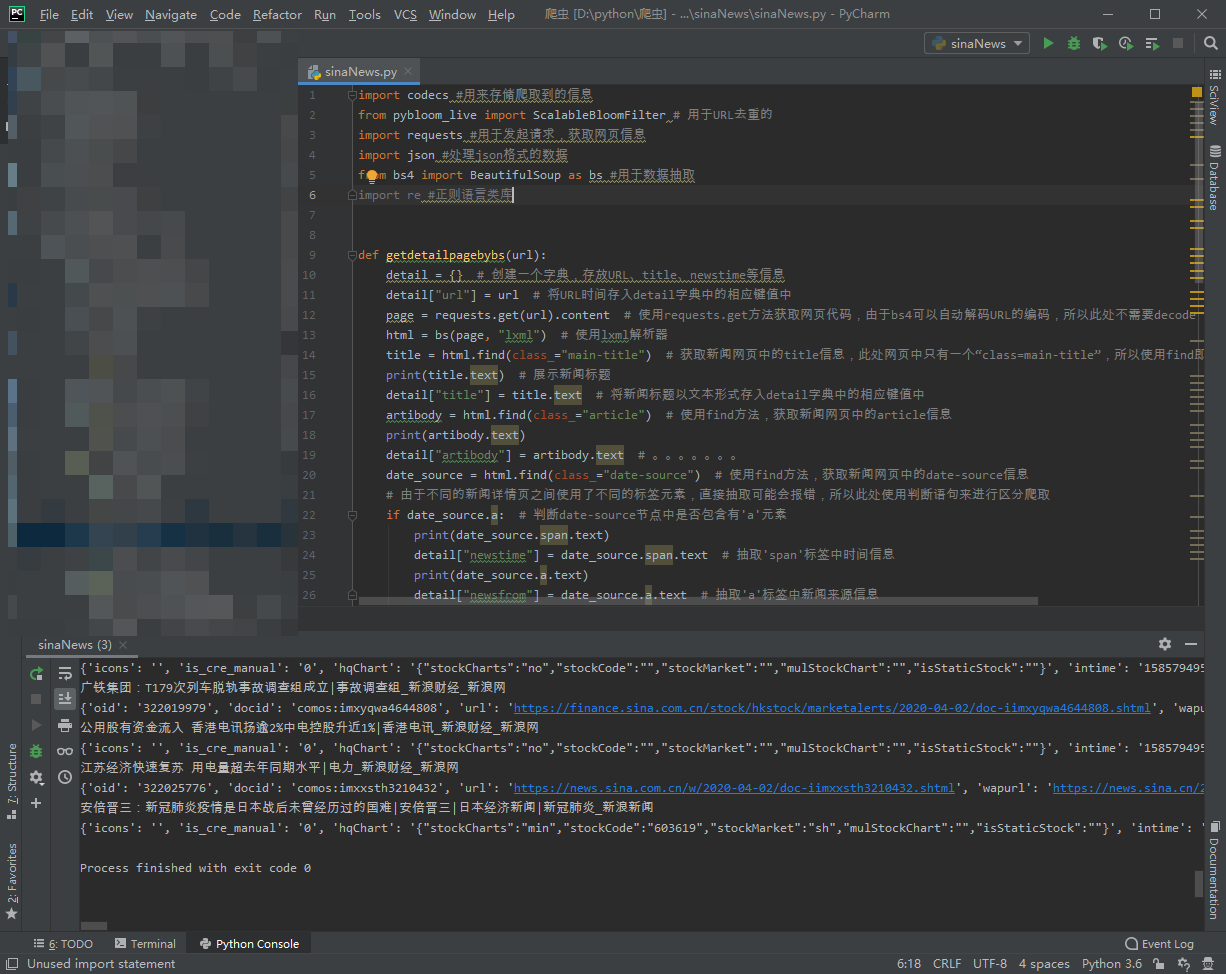
Friends passing by, if you think you can learn something, please click "like" before you go, welcome comments from the big guys passing by, correct the mistakes, and welcome comments from the small partners with problems, private letters. Everyone's attention is my motivation to update my blog!!!