When we write a crawler, we may need to generate a new url based on the current url in the crawler. For example, the following pseudo code:
import re current_url = 'https://www.kingname.info/archives/page/2/' current_page = re.search('/(\d+)', current_url).group(1) next_page = int(current_page) + 1 next_url = re.sub('\d+', str(next_page), current_url) make_request(next_url)
The operation effect is shown in the figure below:
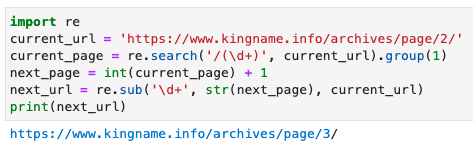
But sometimes, the page turning parameter is not necessarily a number. For example, some websites visit a URL:
https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD
When you visit this url, it returns a JSON string, and the JSON has the following fields:
... "paging": { "cursors": { "before": "MTA3NDU0NDExNDEzNTgz", "after": "MTE4OTc5MjU0NDQ4NTkwMgZDZD" }, } ...
This situation is more common in information flow websites. It can only slide down indefinitely to see the next page, and cannot jump directly through the number of pages. Each time a request is made, the parameter after of the next page is returned. When you want to access the next page, replace the parameter after after = in the current url with this parameter.
In this way, it is not easy to replace the parameters in the url. Because the website may have four situations:
- On the first page, there is no after parameter: https://xxx.com/articlelist?category=technology
- On the first page, there is an after parameter name but no value: https://xxx.com/articlelist?category=technology&after=
- On subsequent pages, there is no content after the after parameter value: https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD
- On subsequent pages, the following contents follow the aster parameter value: https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD&other=abc
You can try, if you use regular expressions, how to cover these four cases and generate the web address of the next page.
In fact, we don't need to use regular expressions. Python's own urllib module has provided a solution to this problem. Let's start with a piece of code:
from urllib.parse import urlparse, urlunparse, parse_qs, urlencode def replace_field(url, name, value): parse = urlparse(url) query = parse.query query_pair = parse_qs(query) query_pair[name] = value new_query = urlencode(query_pair, doseq=True) new_parse = parse._replace(query=new_query) next_page = urlunparse(new_parse) return next_page url_list = [ 'https://xxx.com/articlelist?category=technology', 'https://xxx.com/articlelist?category=technology&after=', 'https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD', 'https://xxx.com/articlelist?category=technology&after=asdrtJKSAZFD&other=abc' ] for url in url_list: next_page = replace_field(url, 'after', '0000000') print(next_page)
The operation effect is shown in the figure below:
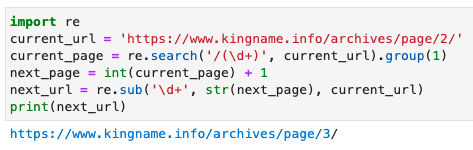
As can be seen from the figure, these four cases can be successfully added by us. The parameter after= 0000000 on the next page. There is no need to think about how regular expressions fit all situations.
urlparse , and urlunparse , are a pair of opposite functions. The former converts the web address into a ParseResult object, and the latter converts the ParseResult object back to the web address string.
ParseResult object The query attribute is a string, that is, the content after the question mark in the web address. The format is as follows:

parse_qs and urlencode are also opposite functions. Among them, the former The string output from query is converted into a dictionary, which converts the field into a dictionary String in the form of query:
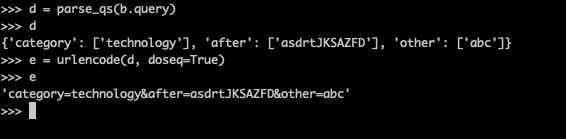
When using Parse_ After QS turns query into a dictionary, you can modify the value of the parameter and then turn it back again.
Due to the of ParseResult object The query attribute is read-only and cannot be overwritten, so we need to call an internal method_ replace the new one replace the query field to generate a new ParseResult object. Finally, transfer it back to the website.
The above is how to use urllib's own functions to replace the fields in the web address.
Official account: WeChat public No. code