How to schedule multiple processes
Why do I need multi process scheduling
Let's first find out the reason for multi process scheduling. Let me summarize it. First, the CPU can only run one process at a time, and the number of CPUs is always less than the number of processes. This requires that multiple processes share a CPU, and each process runs on this CPU for a period of time. The second reason is that when a process cannot obtain certain resources, so that it cannot continue to run, it should give up the CPU. Of course, you can also summarize the CPU time in the first point as a resource, which is combined into one point: if the process can't get the resource, it should give up the CPU. I'll draw a picture for you, as shown below.
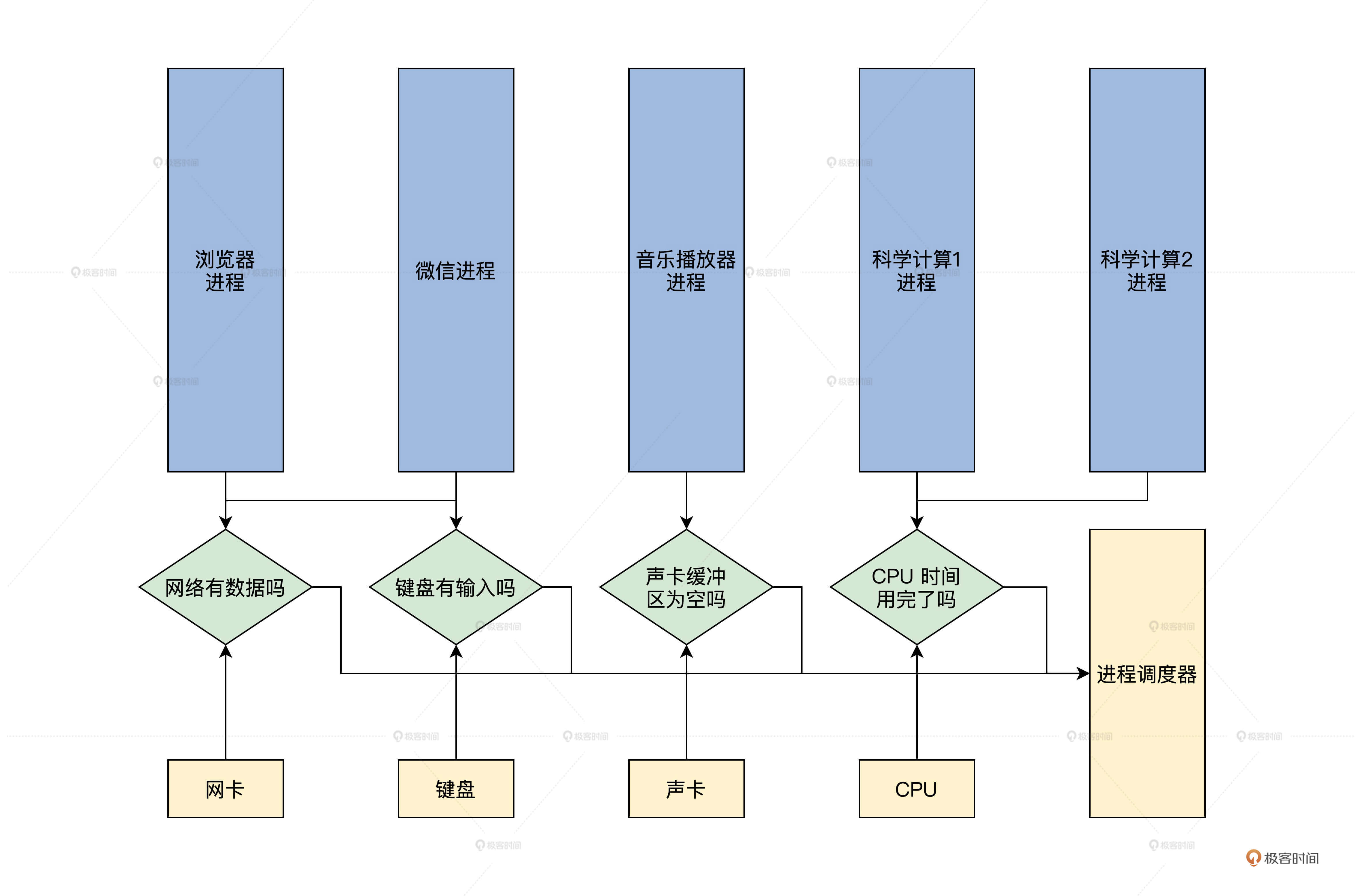
In the figure above, there are five processes, among which the browser process and wechat process depend on the data resources of the network and keyboard. If they cannot be met, they should give up the CPU through process scheduling.
The two scientific computing processes rely more on the CPU, but if one of them runs out of CPU time, it has to give up the CPU with the help of process scheduling, otherwise it will occupy the CPU for a long time, resulting in the inability of other processes to run. It should be noted that each process depends on a resource, that is, CPU time. You can understand CPU time as it is CPU. A process must have a CPU to run. Here we only need to understand why multiple processes need to be scheduled.
Process lifecycle
People have birth, old age and death, which is the same for a process. A process starts from establishment, then runs, then has to pause due to resource problems, and finally exits the system. This process is called the process life cycle. In system implementation, the life cycle of a process is usually represented by the state of the process. The state of the process is defined by several macros, as shown below.
#define TDSTUS_RUN 0 / / process running status #define TDSTUS_SLEEP 3 / / process sleep status #define TDSTUS_WAIT 4 / / process waiting status #define TDSTUS_NEW 5 / / process creation status #define TDSTUS_ZOMB 6 / / the process is in a dead state
It can be found that our process has five states. The process is in a dead state, which means that the process will exit the system and will not be scheduled. So how do process states transition? Don't worry. Let me draw a picture to explain it, as shown below.
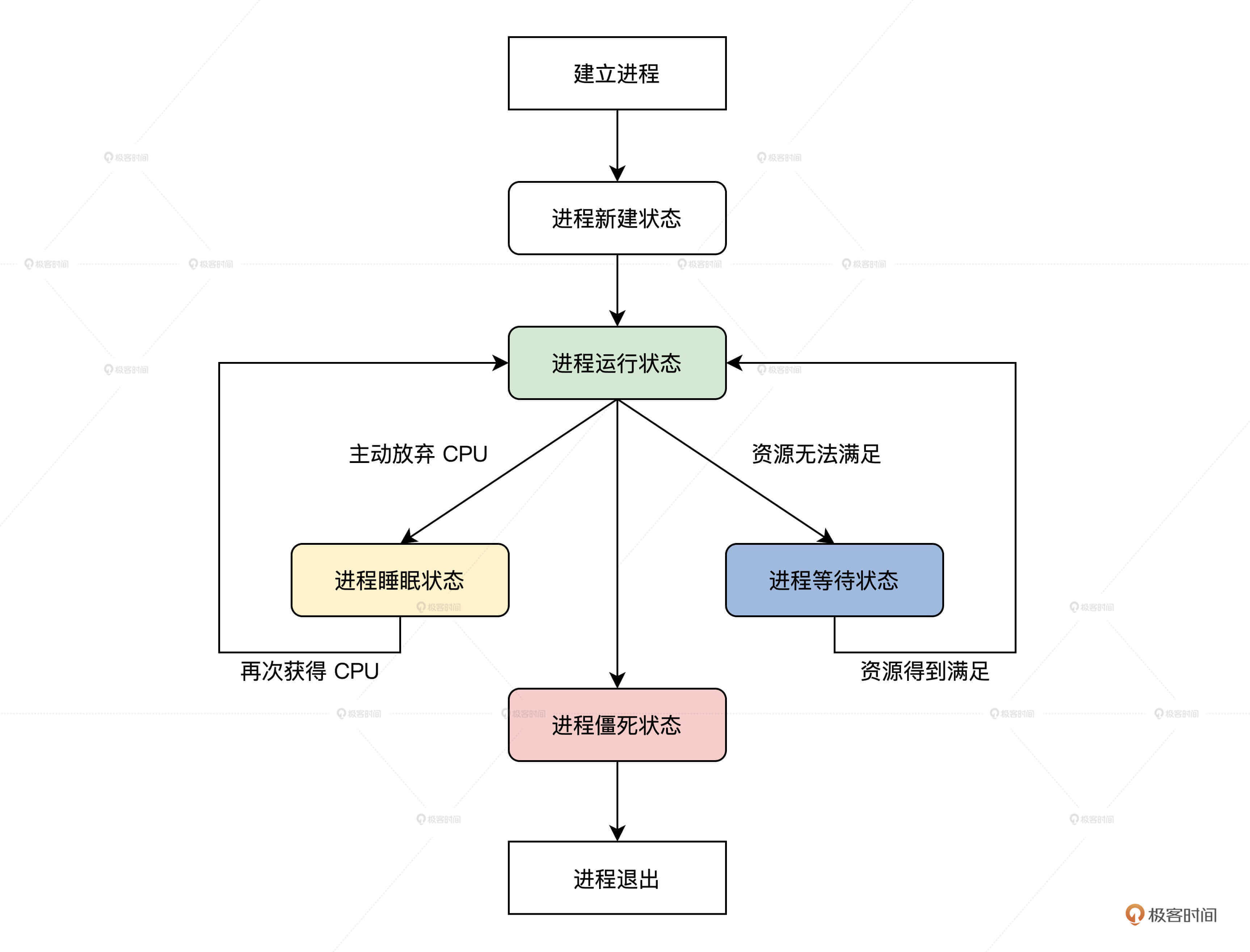
The above figure has shown you the transition relationship and conditions to be met from the establishment of the process to the exit of the process from the system.
How to organize processes
First, let's study how to organize the process. Since there are many processes in the system, we used thread in the last lesson_ The T structure represents a process, so there will be multiple threads_ T structure. According to our interpretation of the process life cycle just now, we know that the process can be established or exited at any time, so the system will allocate or delete threads at any time_ T structure.
The simplest way to deal with this situation is to use the linked list data structure, and our process has priority, so we can design a chain header for each priority.
Next, let's implement the design into a data structure. Since this is a scheduler module, we need to create several files krlsched.h and krlsched.c, and write code in them, as shown below.
typedef struct s_THRDLST
{
list_h_t tdl_lsth; //The chain header of the mount process
thread_t* tdl_curruntd; //Processes running on the linked list
uint_t tdl_nr; //Number of processes on the linked list
}thrdlst_t;
typedef struct s_SCHDATA
{
spinlock_t sda_lock; //Spin lock
uint_t sda_cpuid; //Current CPU id
uint_t sda_schdflgs; //sign
uint_t sda_premptidx; //Process preemption count
uint_t sda_threadnr; //Number of processes
uint_t sda_prityidx; //Current priority
thread_t* sda_cpuidle; //Idle process of current CPU
thread_t* sda_currtd; //Currently running process
thrdlst_t sda_thdlst[PRITY_MAX]; //Process linked list array
}schdata_t;
typedef struct s_SCHEDCALSS
{
spinlock_t scls_lock; //Spin lock
uint_t scls_cpunr; //Number of CPU s
uint_t scls_threadnr; //Number of all processes in the system
uint_t scls_threadid_inc; //Used to allocate process id
schdata_t scls_schda[CPUCORE_MAX]; //Scheduling data structure per CPU
}schedclass_t;
From the above code, we find schedclass_t is a global data structure, which contains a schdata_t structure array. The array size is determined according to the number of CPU s. In each schdata_t structure also contains a thrdlst of process priority size_ T structure array. I'll draw a picture and you'll understand. This picture allows you to thoroughly clarify the relationship between the above data structures.
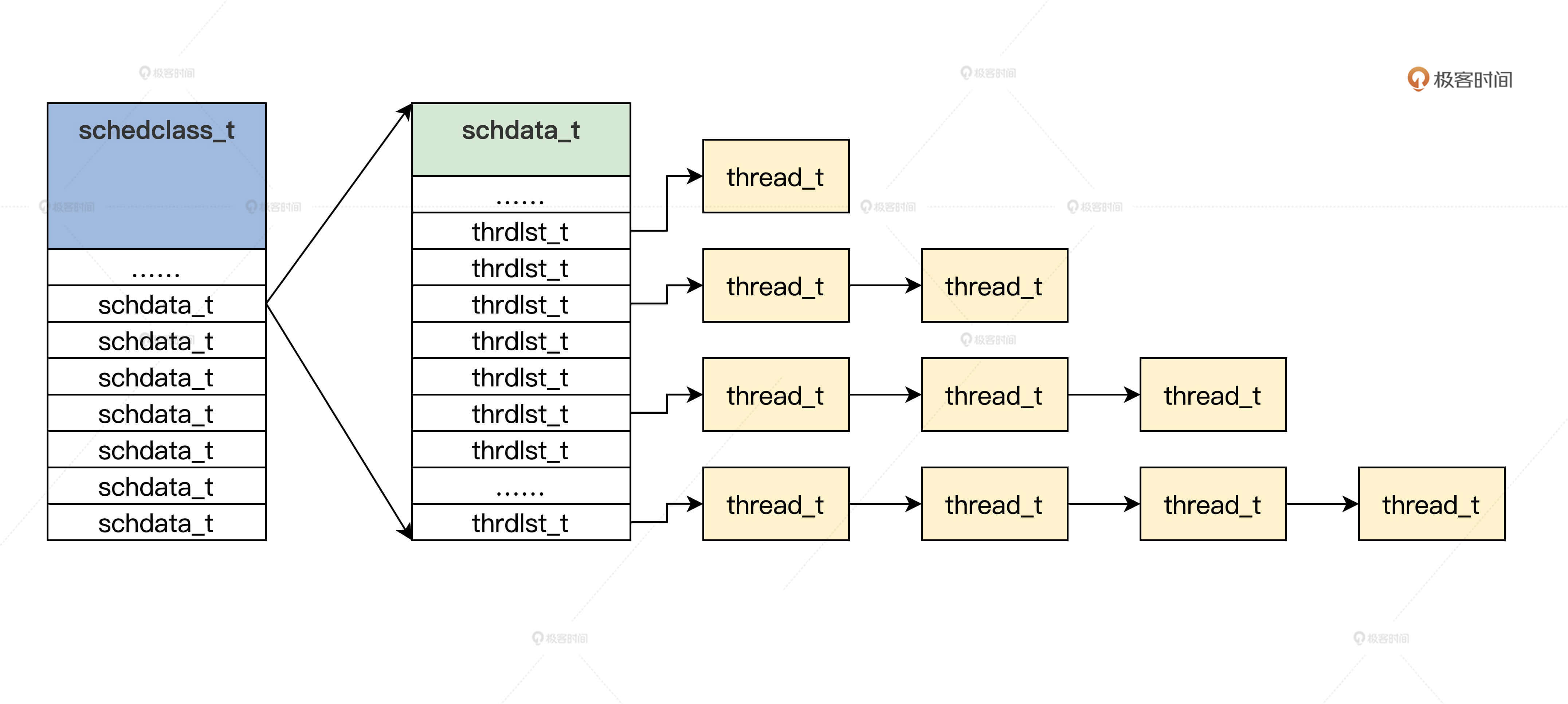
Let's define the schedclass_t data structure and initialize.
Initialization of management process
The initialization of the management process is very simple, that is, schedclass_ Initialization of variables of T structure. Through the previous study, you may have found that schedclass_ The variable of the T structure should be a global variable, so first define a schedclass in the Cosmos / kernel / krlgglobal. C file_ The global variables of the T structure are as follows.
KRL_DEFGLOB_VARIABLE(schedclass_t,osschedcls);
With schedclass_ The global variable osschedcls of the T structure. Then, we write the code to initialize the osschedcls variable in the cosmos/kernel/krlsched.c file, as shown below.
void thrdlst_t_init(thrdlst_t *initp)
{
list_init(&initp->tdl_lsth); //Initialize the linked list of the mounted process
initp->tdl_curruntd = NULL; //No process is running at the beginning
initp->tdl_nr = 0; //No process started
return;
}
void schdata_t_init(schdata_t *initp)
{
krlspinlock_init(&initp->sda_lock);
initp->sda_cpuid = hal_retn_cpuid(); //Get CPU id
initp->sda_schdflgs = NOTS_SCHED_FLGS;
initp->sda_premptidx = 0;
initp->sda_threadnr = 0;
initp->sda_prityidx = 0;
initp->sda_cpuidle = NULL; //Start a process without idling and running
initp->sda_currtd = NULL;
for (uint_t ti = 0; ti < PRITY_MAX; ti++)
{//Initialize schdata_ Each thrdlst in the T structure_ T structure
thrdlst_t_init(&initp->sda_thdlst[ti]);
}
return;
}
void schedclass_t_init(schedclass_t *initp)
{
krlspinlock_init(&initp->scls_lock);
initp->scls_cpunr = CPUCORE_MAX; //Maximum number of CPU s
initp->scls_threadnr = 0; //No process started
initp->scls_threadid_inc = 0;
for (uint_t si = 0; si < CPUCORE_MAX; si++)
{//Initialize each schdata in the osschedcls variable_ t
schdata_t_init(&initp->scls_schda[si]);
}
return;
}
void init_krlsched()
{ //Initialize osschedcls variable
schedclass_t_init(&osschedcls);
return;
}
The above code is very simple, which is written by init_ The krlsched function calls schedclass_ t_ The init function initializes the osschedcls variable, but init_ Who calls the krlsched function?
Init is called in this function_ Krlsched function, the code is as follows.
void init_krl()
{
init_krlsched();
die(0);//Control not to let init_krl function returns
return;
}
So far, the initialization of the management process is completed. In fact, this is also the initialization of our process scheduler. Is it that simple? Of course not. There are important process scheduling waiting for us to finish.
Design and implement process scheduler
The data structure of the management process has been initialized. Now we begin to design and implement the process scheduler. The process scheduler is to schedule the process at the appropriate time point and the appropriate code execution path. To put it bluntly, it is to switch from the current running process to another process, stop the current process, and the CPU starts to execute the code of another process. This is simple to say, but it is not easy to do. Next, I will lead you to implement the process scheduler step by step.
Process scheduler entry
First, please imagine what the process scheduler looks like. In fact, the process scheduler is just a function, which is not essentially different from other functions. You can call it on many other code execution paths. It just runs from one process to the next.
Then the function of this function can be determined: nothing more than determining the currently running process, then selecting the next process to run, and finally switching from the currently running process to the next process to run. Let's write the entry function of the process scheduler first, as shown below.
void krlschedul()
{
thread_t *prev = krlsched_retn_currthread(),//Returns the currently running process
*next = krlsched_select_thread();//Select the next running process
save_to_new_context(next, prev);//Switch from the current process to the next process
return;
}
We just need to call the functions in the above code wherever we need to schedule the process. Let's begin to implement other functional logic in the krlschedul function.
How to get the currently running process
Get the currently running process. The purpose is to save the running context of the current process and ensure that it can resume running when it is scheduled to the currently running process next time. As you will see later, each time we switch to the next process, we will set the next running process as the current running process. The code of this function to get the currently running process is as follows.
thread_t *krlsched_retn_currthread()
{
uint_t cpuid = hal_retn_cpuid();
//Obtain the scheduling data structure of the current cpu through cpuid
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
if (schdap->sda_currtd == NULL)
{//If the pointer of the currently running process in the scheduling data structure is null, an error will occur and the machine will crash
hal_sysdie("schdap->sda_currtd NULL");
}
return schdap->sda_currtd;//Returns the currently running process
}
The above code is very simple. If you carefully understand the data structure of the previous organization process, you will find that schdata_ SDA in T structure_ The currtd field is the address where the currently running process is saved. Return the value of this field to get the currently running process.
Select next process
According to the design of scheduler entry function, after obtaining the currently running process, the next step is to select the next process to be put into operation. In business systems, this process is extremely complex. Because this process is the core of the process scheduling algorithm. It is related to the throughput of the process, whether it can respond to requests in time, the utilization of CPU, and the fairness of running and obtaining resources between processes. These problems will affect the performance and reliability of the whole operating system.
As beginners, we don't have to be so complicated. We can use a simple priority scheduling algorithm, that is, always select the process with the highest priority as the next running process. The code to complete this function is as follows.
thread_t *krlsched_select_thread()
{
thread_t *retthd, *tdtmp;
cpuflg_t cufg;
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
krlspinlock_cli(&schdap->sda_lock, &cufg);
for (uint_t pity = 0; pity < PRITY_MAX; pity++)
{//Scan from highest priority
if (schdap->sda_thdlst[pity].tdl_nr > 0)
{//If the process linked list of current priority is not empty
if (list_is_empty_careful(&(schdap->sda_thdlst[pity].tdl_lsth)) == FALSE)
{//Take out the first process under the current priority process list
tdtmp = list_entry(schdap->sda_thdlst[pity].tdl_lsth.next, thread_t, td_list);
list_del(&tdtmp->td_list);//Off chain
if (schdap->sda_thdlst[pity].tdl_curruntd != NULL)
{//Put this SDA_ thdlst[pity].tdl_ The process of curruntd is hung at the end of the linked list
list_add_tail(&(schdap->sda_thdlst[pity].tdl_curruntd->td_list), &schdap->sda_thdlst[pity].tdl_lsth);
}
schdap->sda_thdlst[pity].tdl_curruntd = tdtmp;
retthd = tdtmp;//Put the selected process into sda_thdlst[pity].tdl_curruntd, and return
goto return_step;
}
if (schdap->sda_thdlst[pity].tdl_curruntd != NULL)
{//If sda_thdlst[pity].tdl_curruntd returns it directly if it is not empty
retthd = schdap->sda_thdlst[pity].tdl_curruntd;
goto return_step;
}
}
}
//If no process is found, the default idle process is returned
schdap->sda_prityidx = PRITY_MIN;
retthd = krlsched_retn_idlethread();
return_step:
//Unlock and return to process
krlspinunlock_sti(&schdap->sda_lock, &cufg);
return retthd;
}
The logic of the above code is very simple. Let me sort it out for you. First, scan the priority process list from high to low, and then if the current priority process list is not empty, take out the first process on the list and put it into thrdlst_ TDL in T structure_ Curruntd field and put the previous thrdlst_ TDL of T structure_ The process in the curruntd field hangs into the tail of the linked list and returns. Finally, when no process is found when the lowest priority is scanned, the default idle process is returned.
Get idle process
In the function of selecting the next process, if no suitable process is found, the default idle process is returned. You can think about why there should be an idle process. Can't you just return NULL? Not really, because the function of the scheduler must switch from one process to the next. If there is no next process and the previous process cannot run, the scheduler will have nowhere to go and the whole system will stop running. Of course, this is not the result we want, so we have to leave the last way for the system. Let's first implement the function to obtain the idle process, as shown below.
thread_t *krlsched_retn_idlethread()
{
uint_t cpuid = hal_retn_cpuid();
//Obtain the scheduling data structure of the current cpu through cpuid
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
if (schdap->sda_cpuidle == NULL)
{//If the pointer of the scheduling data structure to the process is null, an error will occur and the machine will crash
hal_sysdie("schdap->sda_cpuidle NULL");
}
return schdap->sda_cpuidle;//Return to idle process
}
Process switching
After the previous process, we have found the currently running process P1 and the next running process P2. Now we enter the most important process switching process.
Before process switching, we also need to understand another important problem: the function call path of the process in the kernel. What is the function call path.
For example, for example, the process P1 calls the function A, then the function B is called in function A, then the function C is invoked in function B, and finally the scheduler function S is called in function C. This function A to function S is the function call path of the process P1.
For example, the process P2 starts calling the function D, then the function E is called in function D, and then the function F is invoked in function E. Finally, the scheduler function S is called in function F, function D, E, F to function is the function call path of the process function.
The function call path is saved through the stack. For processes running in the kernel space, it is saved in the corresponding kernel stack. I have prepared a picture for you to help you understand.
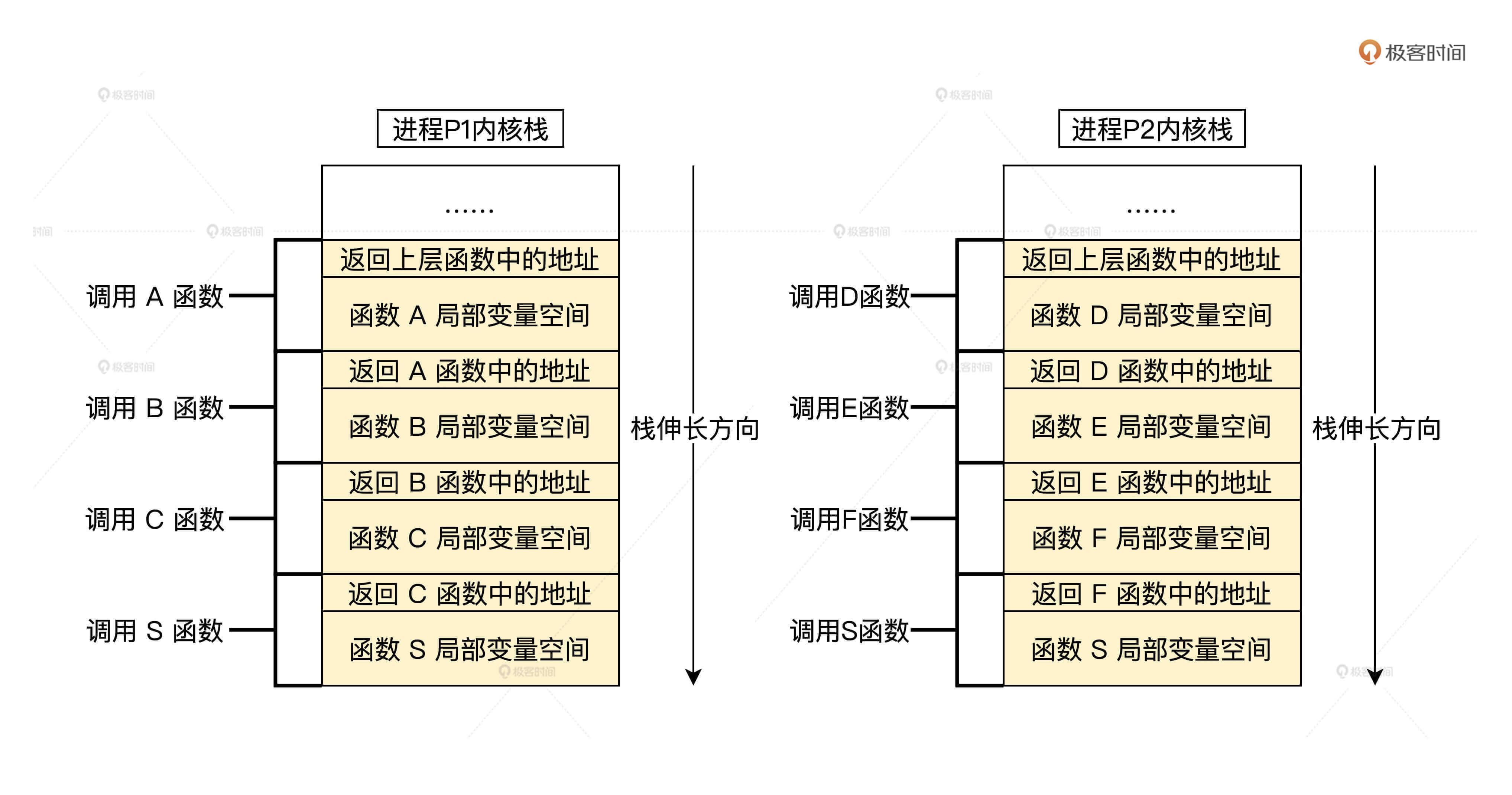
The above is the function call path of processes P1 and P2, and it is also the result of the change of their respective kernel stack space state when they call the function. To digress, did you find out. C language stack is the most efficient memory management, and the variable life cycle is also appropriate, which is better than the memory garbage collector of many high-level languages.
With the previous foundation, now let's start to implement the process switching function. In this function, we do these things.
Firstly, we save the general register of the current process to the kernel stack of the current process; Then, save the RSP register of the CPU into the machine context structure of the current process, read the value of the RSP stored in the machine context structure of the next process, and store it in the RSP register of the CPU; Then, call a function to switch the MMU page table; Finally, the general registers of the next process are recovered from the kernel stack of the next process.
Then the next process starts running, and the code is as follows.
void save_to_new_context(thread_t *next, thread_t *prev)
{
__asm__ __volatile__(
"pushfq \n\t"//Flag register that holds the current process
"cli \n\t" //Off interrupt
//General purpose register that holds the current process
"pushq %%rax\n\t"
"pushq %%rbx\n\t"
"pushq %%rcx\n\t"
"pushq %%rdx\n\t"
"pushq %%rbp\n\t"
"pushq %%rsi\n\t"
"pushq %%rdi\n\t"
"pushq %%r8\n\t"
"pushq %%r9\n\t"
"pushq %%r10\n\t"
"pushq %%r11\n\t"
"pushq %%r12\n\t"
"pushq %%r13\n\t"
"pushq %%r14\n\t"
"pushq %%r15\n\t"
//Save the RSP register of the CPU into the machine context structure of the current process
"movq %%rsp,%[PREV_RSP] \n\t"
//Write the RSP value in the machine context structure of the next process to the RSP register of the CPU
"movq %[NEXT_RSP],%%rsp \n\t"//In fact, it has been switched to the next process, because the kernel stack of the switching process
//Call__ to_ new_ The context function switches the MMU page table
"callq __to_new_context\n\t"
//Restores the general register of the next process
"popq %%r15\n\t"
"popq %%r14\n\t"
"popq %%r13\n\t"
"popq %%r12\n\t"
"popq %%r11\n\t"
"popq %%r10\n\t"
"popq %%r9\n\t"
"popq %%r8\n\t"
"popq %%rdi\n\t"
"popq %%rsi\n\t"
"popq %%rbp\n\t"
"popq %%rdx\n\t"
"popq %%rcx\n\t"
"popq %%rbx\n\t"
"popq %%rax\n\t"
"popfq \n\t" //Restores the flag register of the next process
//Output the kernel stack address of the current process
: [ PREV_RSP ] "=m"(prev->td_context.ctx_nextrsp)
//Read the kernel stack address of the next process
: [ NEXT_RSP ] "m"(next->td_context.ctx_nextrsp), "D"(next), "S"(prev)//Call for__ to_ new_ The context function passes parameters
: "memory");
return;
}
By switching the kernel stack of a process, the process is switched, because the function call path of the process is saved in the corresponding kernel stack. As long as the krlschedul function is called, the last function call path will stop in save_ to_ new_ In the context function, when save_ to_ new_ As soon as the context function returns, it will lead to a call back to save_ to_ new_ The next line of code of the context function starts to run. Here, it is returned to the krlschedul function, and finally returned layer by layer.
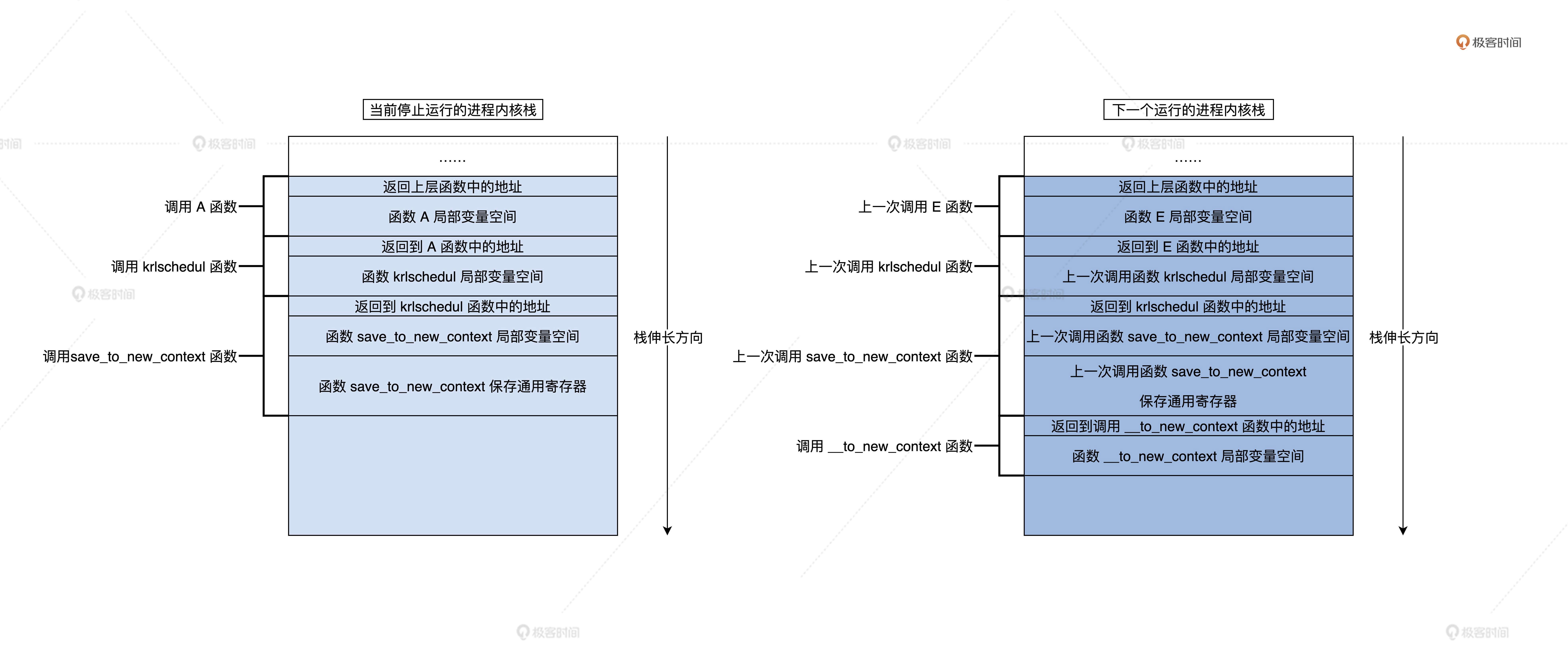
Combined with the above figure, you can understand the principle of process switching. At the same time, you will also find a problem that the switching mechanism can operate normally. You must ensure that the next process has been scheduled, that is, it has called and executed the krlschedul function. It is known that the new process has never called the krlschedul function, so it has to carry out special processing. We are__ to_ new_ This special processing is completed in the context function. The code is as follows.
void __to_new_context(thread_t *next, thread_t *prev)
{
uint_t cpuid = hal_retn_cpuid();
schdata_t *schdap = &osschedcls.scls_schda[cpuid];
//Set the current running process as the next running process
schdap->sda_currtd = next;
//Set the tss of the next running process to the tss of the current CPU
next->td_context.ctx_nexttss = &x64tss[cpuid];
//Set the R0 stack in the tss of the current CPU as the kernel stack of the next running process
next->td_context.ctx_nexttss->rsp0 = next->td_krlstktop;
//Load the MMU page table for the next running process
hal_mmu_load(&next->td_mmdsc->msd_mmu);
if (next->td_stus == TDSTUS_NEW)
{ //If the new process is running for the first time, it must be processed
next->td_stus = TDSTUS_RUN;
retnfrom_first_sched(next);
}
return;
}
The comments of the above code are clear__ to_new_context is responsible for setting the currently running process, dealing with the problem that the stack needs to be switched when the CPU is interrupted, and switching the MMU page table of a process (that is, using the address space of the new process). Finally, if the new process runs for the first time, retnfrom is called_ first_ The sched function. Let's write this function.
void retnfrom_first_sched(thread_t *thrdp)
{
__asm__ __volatile__(
"movq %[NEXT_RSP],%%rsp\n\t" //Set the RSP register of the CPU to the RSP in the machine context structure of the process
//The segment register saved by the recovery process in the kernel stack
"popq %%r14\n\t"
"movw %%r14w,%%gs\n\t"
"popq %%r14\n\t"
"movw %%r14w,%%fs\n\t"
"popq %%r14\n\t"
"movw %%r14w,%%es\n\t"
"popq %%r14\n\t"
"movw %%r14w,%%ds\n\t"
//The recovery process is stored in a general register in the kernel stack
"popq %%r15\n\t"
"popq %%r14\n\t"
"popq %%r13\n\t"
"popq %%r12\n\t"
"popq %%r11\n\t"
"popq %%r10\n\t"
"popq %%r9\n\t"
"popq %%r8\n\t"
"popq %%rdi\n\t"
"popq %%rsi\n\t"
"popq %%rbp\n\t"
"popq %%rdx\n\t"
"popq %%rcx\n\t"
"popq %%rbx\n\t"
"popq %%rax\n\t"
//The RIP, CS and RFLAGS (RSP and SS registers of the recovery process application may be required) of the recovery process stored in the kernel stack
"iretq\n\t"
:
: [ NEXT_RSP ] "m"(thrdp->td_context.ctx_nextrsp)
: "memory");
}
retnfrom_ first_ The sched function does not return to the__ to_new_context function, but directly run the relevant code of the new process (if you don't understand the principle of this code, you can review the previous lesson to see the initialization of the process kernel stack when establishing the process).
Key review
In this lesson, we start by understanding why we need multi process scheduling, then implement sub scheduling to manage multiple processes, and finally implement the process scheduler. There are many important knowledge points. Let me sort them out for you.
1. Why do you need multi process scheduling? We analyzed that there are always some resources in the system that can not meet the needs of each process, so some processes must go and stop, which requires different processes to switch back and forth to run on the CPU. In order to realize this mechanism, we need to talk about line scheduling.
2. Organize multiple processes. In order to realize process management, multiple processes must be organized. We design the scheduler data structure. In this structure, we use the priority linked list array to organize multiple processes, and initialize the variables of these data structures.
3. Process scheduling. When there are multiple processes, process scheduling is required. Our process scheduler is a function. In this function, the current running process and the next process to be run are selected. If there are no runnable processes, the idle process is selected. Finally, the key is inter process switching. We switch the function call path of the process by switching the kernel stack of the process, When the scheduler function returns, it is already another process.