I wrote a script for hxd the other day, because I haven't had time for the exam these days. After the exam, I took the time to share it.
Requirement: automatically crawl some field values of the static htm page and put them into the excel table. For example, a static page of someone's final exam results needs to automatically import tens of thousands of scores of a school directly into excel.
Analysis: my first thought is to write in C + +. The first reason is that the foundation of C + + is better than others, and python has not been used for a long time. The second is the main reason. Sending Python scripts to friends requires a python environment, and C + + generates exe, which can be sent directly for use.
Overall idea: put the generated exe executable file and htm page in the same file path, and double-click to run the program. First, we need to get the current directory of the file. Secondly, get all the files in the directory. Then read the contents of the specified file (here is the htm file), match the values of html language tags with regular expressions, and then write them to excel.
getcwd
The first problem is how to get the path where the current program is located. gcc provides getcwd to directly obtain the current path. It should be noted that when I want to view its underlying source code, I can only find the following code:
extern inline __attribute__((__always_inline__)) char *
getcwd (char *__buf, size_t __size)
{
if (__ssp_bos (__buf) != (size_t) -1 && __size > __ssp_bos (__buf))
__chk_fail ();
return __getcwd_alias (__buf, __size);
}
This is because getcwd is a built-in function provided by the compiler gcc, not a C library function.
Therefore, if we compile with other compilers such as llvm, such functions will not be used__ getcwd_ You can't see the specific functions of alias. You can only trace back to some macro definitions. However, we can probably understand what it means. The first parameter is a pointer, and then the second parameter is the size of the memory area pointed to. If the size is judged to be wrong, there will be no error. So my actual usage is:
char buffer[MAX_P];
getcwd(buffer, MAX_P);
extern char *__SSP_REDIRECT (__getcwd_alias, (char *__buf, size_t __size), getcwd); # define __SSP_REDIRECT(name, proto, alias) \ name proto __asm__ (__SSP_ASMNAME (#alias)) # define __SSP_ASMNAME(cname) __SSP_ASMNAME2 (__USER_LABEL_PREFIX__, cname) # define __SSP_ASMNAME2(prefix, cname) __SSP_ASMNAME3 (prefix) cname # define __SSP_ASMNAME3(prefix) #prefix
I don't understand the above code, but I feel that its underlying implementation has something to do with assembly. If you want to know more about it, you may have to take a look at the implementation of patch in gcc. After taking a glance, you don't want to see it again... Post a link
Portal
GetAllFiles
Then we need to get all the files in the current path
void GetAllFiles( string path, vector<string>& files)
{
long hFile = 0;
//file information
struct _finddata_t fileinfo;//A structure used to store file information
string p;
if((hFile = _findfirst(p.assign(path).append("\\*").c_str(),&fileinfo)) != -1)
{
do
{
if((fileinfo.attrib & _A_SUBDIR)) //If you find a folder
{
if(strcmp(fileinfo.name,".") != 0 && strcmp(fileinfo.name,"..") != 0) //It cannot be the current directory or the upper level directory
{
files.push_back(p.assign(path).append("\\").append(fileinfo.name) );
GetAllFiles( p.assign(path).append("\\").append(fileinfo.name), files ); //Recursively searching
}
}
else //If a folder is not found
{
files.push_back(p.assign(fileinfo.name) ); //Save file name
}
}while(_findnext(hFile, &fileinfo) == 0);
_findclose(hFile); //End lookup
}
}
The first need is to use_ finddata_t to store file information, which respectively represents: file type, file creation time, file last accessed time, file last modified time, file size and file name.
#define _finddata_t _finddata32_t
struct _finddata32_t {
unsigned attrib;
__time32_t time_create;
__time32_t time_access;
__time32_t time_write;
_fsize_t size;
char name[260];
};
Then use_ Findfirst finds the file_ Findfirst starts with_ The macro definition of findfirst32, and_ The first parameter of findfirst32 function is const char *, which is why a C is added when passing parameters_ Str () function is to convert string type into const char * type. This function returns the file handle that is successfully searched, stores the file information in the structure, and returns - 1 if the search fails
// io.h _CRTIMP intptr_t __cdecl _findfirst32(const char *_Filename,struct _finddata32_t *_FindData);
Here_ The Filename path can include the wildcard * so that you can easily represent all files in a directory. Obviously, the file type can be directly defined here, and there is no need to add conditions to judge the htm file. However, in order to maintain the unity of the function, there is no change or parameter added to the function. In addition, unfortunately, the content defined in io.h cannot be searched for its source implementation.
At the same time, in io.h, macros define some values to represent the type of file.
#define _A_NORMAL 0x00 / / normal file #define _A_RDONLY 0x01 / / read only #define _A_HIDDEN 0x02 / / hidden #define _A_SYSTEM 0x04 / / system #define _A_SUBDIR 0x10 / / folder #define _A_ARCH 0x20 / / archive
So the overall idea is to use_ findfirst searches for the first file, then determines whether it is a folder for recursive query, and then uses the obtained file handle_ FindText continues the search, and finally uses_ findclose ends the query.
Regular expression matching
Then read these files and match them with regular expressions.
I won't talk about how to match regular rules. A lot of them can be found on the Internet. Here is an example.
regex tableReg("<SPAN style=\"COLOR: teal\">full name </SPAN>[^ -~]{2,}");
auto ret = regex_search(p,m,tableReg);
if(ret2){
string oo = m2[0];
e.WriteCell(ans, 1, oo.substr(19).data());
cout << oo.substr(19).data() << endl;
}
I use the above method to match specific tag values. Because I checked the source code of all htm pages in advance, they all use the same format, so in order to facilitate me to directly calculate the number of characters and intercept the desired value, but obviously this is not a smart method. There are better methods. Welcome to discuss.
Write excel
At first, to tell the truth, I didn't expect that writing excel would be so troublesome. Later, after reading around the Internet, I realized that excel can not be read and written directly like ordinary files. Most schemes on the Internet are to import excel libraries, such as odbe, ole and so on. But in fact, it is very troublesome to do so. I don't want to explore it in depth in a short time. So I think of a plan to save the country by curve. Write csv, and then copy csv files into excel. Anyway, it's just a small script to realize the function of automation.
So you can directly write a class that reads and writes csv, which is much simpler than writing excel directly.
class ExcelProcess
{
public:
ExcelProcess(){pf=NULL;};
~ExcelProcess(void){ if (pf) EndWrite(); };
void WriteCell(ushort row, ushort col, const char *value)
{
ushort iLen = (ushort)strlen(value);
ushort clData[] = { 0x0204, ushort(8 + iLen), row, col, 0, iLen };
WriteArray(clData, 12);
WriteArray(value, iLen);
}
void WriteCell(ushort row, ushort col, int value)
{
ushort clData[] = { 0x027E, 10, row, col, 0 };
WriteArray(clData, 10);
int iValue = (value << 2) | 2;
WriteArray(&iValue, 4);
}
void WriteCell(ushort row, ushort col, double value)
{
ushort clData[] = { 0x0203, 14, row, col, 0 };
WriteArray(clData, 10);
WriteArray(&value, 8);
}
void WriteCell(ushort row, ushort col)
{
ushort clData[] = { 0x0201, 6, row, col, 0x17 };
WriteArray(clData, 10);
}
bool BeginWrite(const char *fileName)
{
pf = fopen(fileName, "wb+");
if (!pf) return false;
ushort clBegin[] = { 0x0809, 0x08, 0x0, 0x10, 0x0, 0x0 };
WriteArray(clBegin, 12);
return true;
}
void EndWrite()
{
ushort clEnd[] = { 0x0A, 0x0 };
WriteArray(clEnd, 4);
fclose(pf);
pf = 0;
}
bool IsOpen()
{
if (pf!=NULL)
{
return true;
}
else
{
return false;
}
}
void WriteArray(const void *value, ushort len)
{
if (pf)
fwrite(value, 1, len, pf);
}
private:
FILE *pf;
};
This class can be used directly.
Coding problem
When I thought all the problems were solved, I compiled and ran, but found that the written value was garbled, so I first output the read file content in the console, and found that garbled code appeared here.
In order to solve this problem, we first need some basic knowledge of coding. After reading many articles, we can directly summarize it here:
- Start with ascii encoding. ascii uses 7 bits to represent 128 basic characters, such as uppercase and lowercase English letters
- By extending ascii coding, the Chinese invented GB2312 coding to represent more than 6000 commonly used Chinese characters.
- However, there are many Chinese characters, including traditional and various characters, so GBK coding is produced, which includes the coding in GB2312 and expands a lot at the same time. Therefore, GB2312 is a subset of GBK coding.
- China is a multi-ethnic country. Almost all ethnic groups have their own independent language system. In order to express those characters, GBK code continues to be expanded to GB18030 code.
- Then iso puts forward UNICODE coding for unification. But to be exact, UNICODE is a character set that can represent any character, but it only provides the binary code of the character, and does not specify how to encode it.
- Then there are three ways to encode unicode, namely utf-8, utf-16le and utf-16be. To put it simply, there are three unicode codes, namely utf-8, utf-16le and utf-16be.
- It must be mentioned that the BOM flag, byte order mask, is placed at the beginning of the file to represent the coding order, which is an easy to understand way of thinking.
- Utf-16 here 16 refers to 16 bits, that is, 2 bytes. That is, one character is encoded every two bytes. (absurdly, even English characters need two bytes). Then utf-16 must have BOM, which are LE(0xFF 0xFE) and BE(0xFE 0xFF). This is why utf-16 has be and le. Be and Le here mean big endian and low endian, that is, large segment and small end.
- utf-8 is divided into those with BOM and those without BOM. utf-8 is of variable length and may be 1-3 bytes. The BOM of utf-8 with BOM is a 3-byte prefix 0xEE BB EF.
- In fact, under normal circumstances, utf-8 coding does not include BOM, but it is Microsoft's habit. In order to distinguish between uft-8 and ascii codes, one reason is that basic letters such as English case are the same in utf-8 and ascii codes. At the same time, it is also Microsoft's habit to make utf-16le unicode by default.
With the above basic knowledge, I believe I must have a macro understanding of coding, at least not messy. Then we return to our question. Based on the above knowledge, we can make the following analysis:
- vscode defaults to utf-8 when writing code, which can be seen in the lower right corner.
- The reasons for the garbled code problem are:
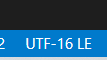
When I tried to open the htm file with vscode, I found that the code was utf-16le. Take a closer look at the garbled code above. In fact, it is the reason for two byte coding, which leads to the widening of characters.
The coding of the code is utf-8, which leads to the problem that the Chinese characters in the regular expression cannot be matched, and the coding of the console terminal is the cause of gbk, so the display of garbled code and the garbled code of Chinese characters written to csv appear.
- Unified coding to solve the problem of garbled code. The first idea is that since the default code for opening the htm file is utf-16le, it is better to change the code code and console code to utf-16le. It's easy to change the code in vscode. Change it directly in the lower right corner, and then rewrite the Chinese in the code. But it's hard to change in the terminal window. The two online change methods are essentially the same, that is, using the chcp command to change. The disadvantage is that they are not automatic enough. When I give the script to my friend, I can't directly use the code to change the code of the console on his environment. Therefore, a better way is to unify all gbk codes since windows defaults to gbk.
- How to convert files from utf-16le to gbk? The simplest way is to open the file with windows Notepad and select the code when saving.
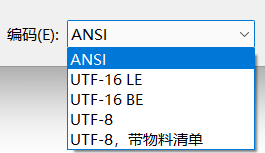
You can see that the codes here correspond to the codes mentioned above. utf-8 with BOM is utf-8 with BOM header
So what is ANSI code?

----Reference [what is ANSI code]( https://blog.csdn.net/imxiangzi/article/details/77370160 )In fact, we can temporarily think that in our environment, ANSI coding is GBK coding, but we can't open the file to convert the coding one by one. We need to convert the file coding by code** Convert file encoding to ANSI encoding**
/*
* Convert the file referred to by path fpath from various encoding formats to ANSI format
*
* Copyright (c) 2013 Zhao Ziqing, All rights reserved
*
*/
#include <bits/stdc++.h>
#include <windows.h>
#define CODE_FORMAT_ANSI 1
#define CODE_FORMAT_UTF8 2
#define CODE_FORMAT_UNICODE_LE 3
#define CODE_FORMAT_UNICODE_BE 4
typedef int ErrorCode;
#define ERR_OK 0
#define ERR_FILE_OPEN_FAILED 1001
#define SWAP16(x) \
((((x) & 0x00ff) << 8) | \
(((x) & 0xff00) >> 8) )
#define SWAP32(x) \
((((x) & 0x000000ff) << 24) | \
(((x) & 0x0000ff00) << 8) | \
(((x) & 0x00ff0000) >> 8) | \
(((x) & 0xff000000) >> 24) )
#define SAFE_DELETE(x) if((x)!=0) {delete[] (x); (x) = 0; }
ErrorCode ConvertFormat(const char* fpath)
{
assert(fpath != 0);
FILE* fp = ::fopen(fpath, "rb");
if(fp == NULL)
return ERR_FILE_OPEN_FAILED;
int fmtFlag;
int fmt = CODE_FORMAT_ANSI;
::fread(&fmtFlag, sizeof(int), 1, fp);
::fclose(fp);
fmtFlag = SWAP32(fmtFlag);
if((fmtFlag & 0xffffff00) == 0xefbbbf00)
fmt = CODE_FORMAT_UTF8;
else if((fmtFlag & 0xffff0000) == 0xfffe0000)
fmt = CODE_FORMAT_UNICODE_LE;
else if((fmtFlag & 0xffff0000) == 0xfeff0000)
fmt = CODE_FORMAT_UNICODE_BE;
if(fmt == CODE_FORMAT_ANSI)
return ERR_OK;
fp = ::fopen(fpath, "rb");
char* txt = 0;
wchar_t* wtxt = 0;
long flen = 0L;
::fseek(fp, 0L, SEEK_END);
flen = ftell(fp);
::rewind(fp);
if(fmt == CODE_FORMAT_UTF8)
{
txt = new char[flen+1];
::fread(txt, 1, flen, fp);
txt[flen] = '\0';
}
else if(fmt == CODE_FORMAT_UNICODE_LE || fmt == CODE_FORMAT_UNICODE_BE)
{
wtxt = new wchar_t[flen/2 +1];
::fread(wtxt, 2, flen/2, fp);
if(fmt == CODE_FORMAT_UNICODE_BE)
{
for(int i=0; i < flen/2; i++)
wtxt[i] = SWAP16(wtxt[i]);
}
wtxt[flen/2] = L'\0';
}
::fclose(fp);
int nLen;
wchar_t* pwstr = 0;
char* pstr = 0;
switch (fmt)
{
case CODE_FORMAT_UTF8:
nLen = ::MultiByteToWideChar(CP_UTF8, 0, txt+3, -1, NULL, 0);
pwstr = new wchar_t[nLen+1];
nLen = ::MultiByteToWideChar(CP_UTF8, 0, txt+3, -1, pwstr, nLen);
nLen = ::WideCharToMultiByte(CP_ACP, 0, pwstr, -1, NULL, 0, NULL, NULL);
pstr = new char[nLen];
::memset(pstr, 0, nLen);
nLen = ::WideCharToMultiByte(CP_ACP, 0, pwstr, -1, pstr,
nLen, NULL, NULL);
break;
case CODE_FORMAT_UNICODE_LE:
case CODE_FORMAT_UNICODE_BE:
nLen = ::WideCharToMultiByte(CP_ACP, 0, wtxt+1, -1, NULL, 0, NULL, NULL);
pstr = new char[nLen];
::memset(pstr, 0, nLen);
nLen = ::WideCharToMultiByte(CP_ACP, 0, wtxt+1, -1, pstr,
nLen, NULL, NULL);
break;
default:
break;
}
fp = ::fopen(fpath, "wb");
::fwrite(pstr, 1, nLen-1, fp);
::fclose(fp);
SAFE_DELETE(txt);
SAFE_DELETE(wtxt);
SAFE_DELETE(pstr);
SAFE_DELETE(pwstr);
return ERR_OK;
}
Code reference from Zhao Ziqing's blog
Its essence is to use the WideCharToMultiByte function, which is not universal in the header file of windows.h.
First of all, you need to know that:: can represent the global scope. This is because it is possible to define local functions or variables with the same name as the global, and the compiler may not find them. Therefore, add:: to determine the global functions and variables.
Secondly, read the content of the first byte of the file and judge which encoding method it is according to the content of the BOM.
#define SWAP32(x) \
((((x) & 0x000000ff) << 24) | \
(((x) & 0x0000ff00) << 8) | \
(((x) & 0x00ff0000) >> 8) | \
(((x) & 0xff000000) >> 24) )
fmtFlag = SWAP32(fmtFlag);
if((fmtFlag & 0xffffff00) == 0xefbbbf00)
fmt = CODE_FORMAT_UTF8;
else if((fmtFlag & 0xffff0000) == 0xfffe0000)
fmt = CODE_FORMAT_UNICODE_LE;
else if((fmtFlag & 0xffff0000) == 0xfeff0000)
fmt = CODE_FORMAT_UNICODE_BE;
Here, SWAP32 is actually exchanging the high and low 16 bits of 32 bits. For ex amp le, 0xABCDEF00 will be converted to 0x00EFCDAB, which is the conversion of the large and small ends. But in fact, I think it's OK here without conversion. It's OK to judge the low order in the later & operation.
Next, find the file size of the file. Where fseek locates seek_end is the end of the file, and then use ftell to find the position of the fp pointer, that is, flen is the size of the file.
::fseek(fp, 0L, SEEK_END);
flen = ftell(fp);
Then use rewind to say fp to point to the beginning of the file again.
::rewind(fp);
Then you need to read the file. If the read file is in the form of utf-8, read it directly, one byte at a time, the length of flen.
if(fmt == CODE_FORMAT_UTF8)
{
txt = new char[flen+1];
::fread(txt, 1, flen, fp);
txt[flen] = '\0';
}
If it is in the form of unicode, wchar is used because two bytes are encoded_ T to save, because wchar_ In fact, t is unsigned short two bytes, and the length is halved. Then, the size end is converted, and all large segments are converted into small ends. In this way, utf-16be is also converted into utf-16le, which is treated as small ends.
typedef unsigned short wchar_t; //unsigned short two bytes
else if(fmt == CODE_FORMAT_UNICODE_LE || fmt == CODE_FORMAT_UNICODE_BE)
{
wtxt = new wchar_t[flen/2 +1];
::fread(wtxt, 2, flen/2, fp);
if(fmt == CODE_FORMAT_UNICODE_BE)
{
for(int i=0; i < flen/2; i++)
wtxt[i] = SWAP16(wtxt[i]);
}
wtxt[flen/2] = L'\0';
}
After reading the contents of the file, the transcoding starts, which is to convert using WideCharToMultiByte, an api provided by windows. To convert utf-8 to ansi is to convert utf-8 to utf16, and then to ansi, so let's look at utf-16 directly
case CODE_FORMAT_UNICODE_LE:
case CODE_FORMAT_UNICODE_BE:
nLen = ::WideCharToMultiByte(CP_ACP, 0, wtxt+1, -1, NULL, 0, NULL, NULL);
pstr = new char[nLen];
::memset(pstr, 0, nLen);
nLen = ::WideCharToMultiByte(CP_ACP, 0, wtxt+1, -1, pstr,
nLen, NULL, NULL);
break;
To put it simply, WideCharToMultiByte(CP_ACP) means that I am already utf-16 and I want to convert it into cp_acp (ansi).
Similarly, in the steps of utf-8, the last two steps are the same as this. The first two steps are to convert utf-8 to utf-16 (WideChar, as the name implies, is a wide character, which is two bytes, and utf-16 is two byte encoding).:: MultiByteToWideChar(CP_UTF8 means: I am already utf-8 and want to convert to utf-16
At this point, after all, the corresponding attribute values in the htm file can be extracted without random code. Relevant resources have also been uploaded and can be used for reference. Click download
References:
- https://www.cnblogs.com/zzqcn/archive/2013/04/25/3043730.html
- https://www.cnblogs.com/ranjiewen/p/5770639.html
- http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
- https://blog.csdn.net/imxiangzi/article/details/77370160
- https://blog.csdn.net/yu704645129/article/details/79907625
- https://blog.csdn.net/qq1623803207/article/details/89398435