===What is a collaborative process===
In short, a coroutine is an existence based on threads, but more lightweight than threads. For the system kernel, the co process has invisible characteristics, so it is controlled by Programmers write their own programs to manage Lightweight threads are often referred to as "user space threads".
===What's better about coroutine than multithreading===
- 1. The control of the thread is in the hands of the operating system, and The control of the collaborative process is completely in the hands of the user, so the use of the collaborative process can reduce the context switching during the program running and effectively improve the program running efficiency.
- 2. When creating a thread, the stack size allocated to the thread by default is 1 M, while the coroutine is lighter, close to 1 K. Therefore, more coprocesses can be opened in the same memory.
- 3. Since the essence of a collaborative process is not multithreading but single thread, multithreaded locking mechanism is not required. Because there is only one thread, there is no conflict caused by writing variables at the same time. Controlling shared resources in the collaboration process does not need to be locked, but only needs to judge the status. Therefore, the execution efficiency of cooperative process is much higher than that of multithreading, and it also effectively avoids the competitive relationship in multithreading.
Applicable scenario: the collaboration process is applicable to the scenario that is blocked and requires a large number of concurrency.
Not applicable scenario: the collaboration process is not applicable to scenarios with a large number of calculations (because the essence of the collaboration process is single thread switching back and forth). If this situation is encountered, other means should be used to solve it.
I believe that those who have used Python to cut crawlers and interface tests are no strangers to the requests library. The http requests implemented in requests are synchronous requests, but in fact, based on the IO blocking characteristics of http requests, it is very suitable to implement "asynchronous" http requests with coprocedures, so as to improve the test efficiency.
After a lot of exploration, Github finally found an open source library that supports "asynchronous" calls to http: httpx.
Httpx is an open source library that inherits almost all the features of requests and supports "asynchronous" http requests. Simply put, httpx can be considered an enhanced version of requests.
Installation: pip install httpx
Single thread synchronous http request time consuming:
1 import asyncio 2 import httpx 3 import threading 4 import time 5 6 def async_main(url, time): 7 response = httpx.get(url).status_code # Request status code 8 print(f'function async_main Current thread{threading.current_thread()}: Number of requests{time} + Status code {response}') 9 10 # start time 11 startTime = time.time() 12 # Start function execution 13 [async_main(url='https://www.baidu.com', time=i) for i in range(20)] # Test 20 times 14 endTime = time.time() 15 16 print('The total time is:', endTime-startTime)
The output result is:
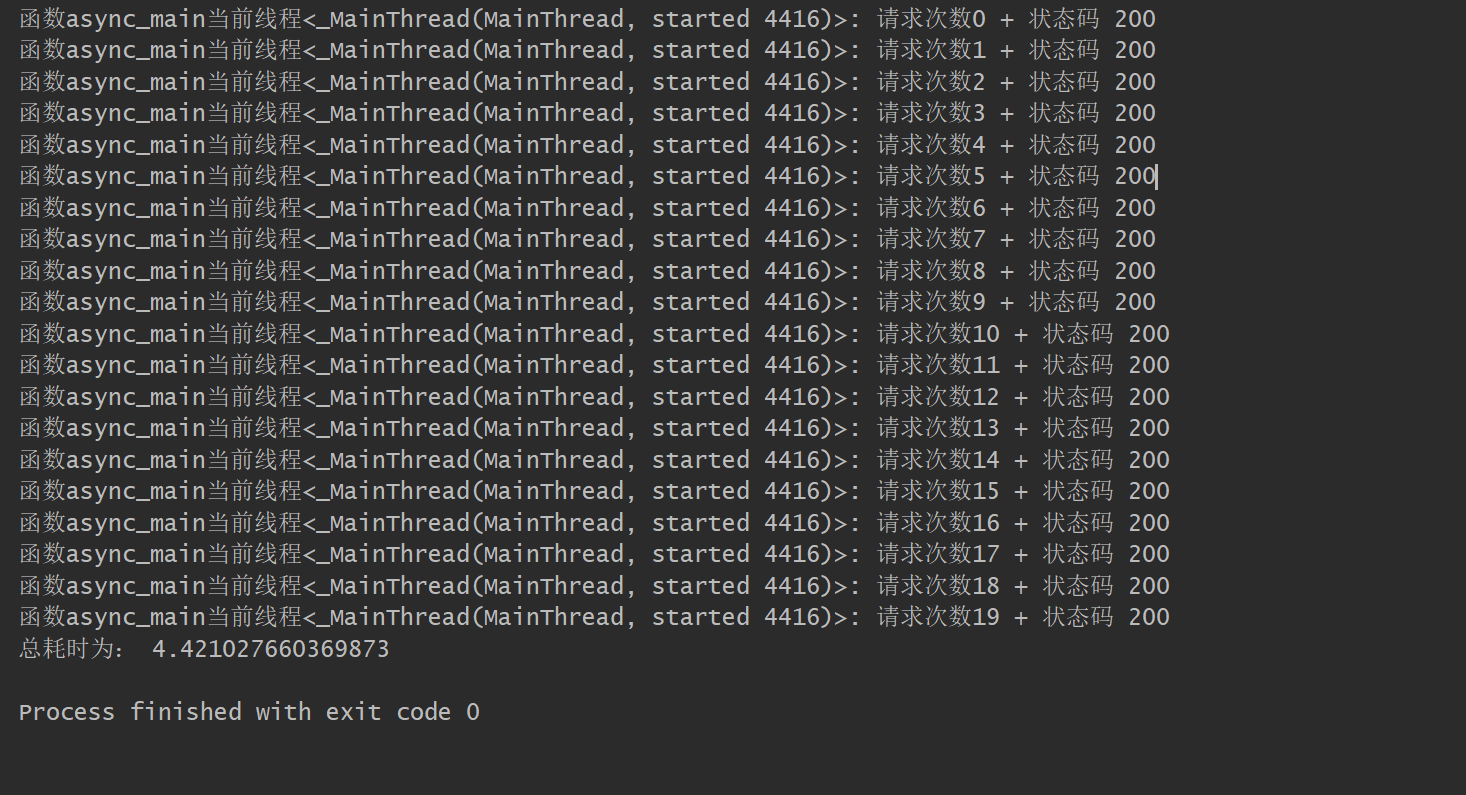
No unexpected, single threaded sequential synchronization request.
Next is a single threaded "asynchronous" request:
1 import asyncio 2 import httpx 3 import threading 4 import time 5 6 client = httpx.AsyncClient() # Asynchronous request 7 8 # Main function 9 async def async_main(url, time): 10 response = await client.get(url) # call client request url 11 status_code = response.status_code # Request status code 12 print(f'function async_main Current thread{threading.current_thread()}: Number of requests{time} + Status code{status_code}') 13 14 loop = asyncio.get_event_loop() # Get event 15 # print(loop) # <ProactorEventLoop running=False closed=False debug=False> 16 17 # Establish task 18 tasks = [async_main(url='https://www.baidu.com', time=i) for i in range(20)] # Or 20 times 19 startTime = time.time() # start time 20 loop.run_until_complete(asyncio.wait(tasks)) # Asynchronous events run until tasks The task in the is completed 21 endTime = time.time() # end event 22 loop.close() # Close time cycle 23 print('The total time is: ', endTime-startTime)
The output results are as follows:
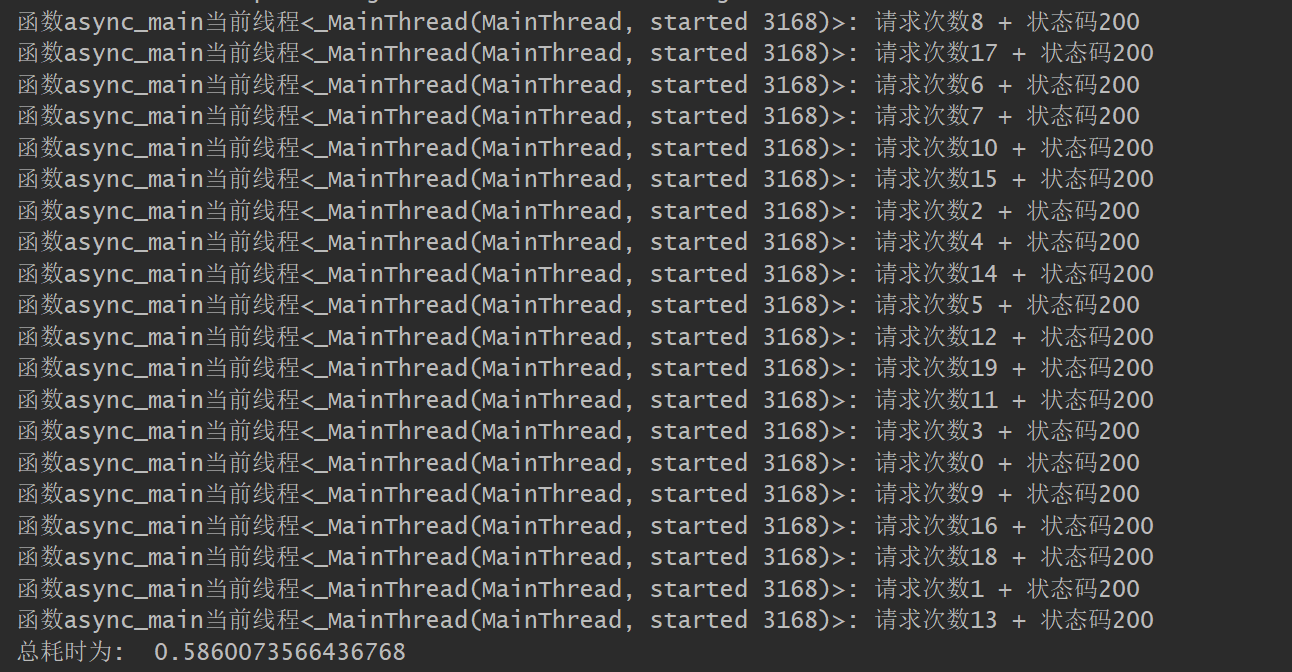
Asynchronous or fast, the total time is nearly 10 minutes 1 of synchronous. It can be seen that although the sequence is chaotic 16, 18, 1... This is because the program keeps switching between coroutines, but the main thread does not switch. The essence of the coroutine is still a single thread.