Hudi Log file format and read / write process
background
Readers who have a certain understanding of Hudi should know that Hudi has two table types: COW and MOR. The MOR table records files through Log files. It can be observed that the data of an MOR table is stored in three files: Log file (* Log. *), partition metadata (. hoodie_partition_metadata), and data file (* parquet). During this period, I consulted a large number of relevant materials and found that few articles introduced the specific content and structure of Log data files in detail. One reason may be that although the Log file uses Avro serialized line storage, it only uses the native Avro standard when serializing records, and the encoding of the rest of the file is in Hudi's own format, which makes it unable to use Avro tools Jar to view it. The contents of this paper are as follows:
- Log file reading and writing process
- Log file structure analysis
Log file reading and writing process
This paper is based on Hudi 0.9 Version 0 for analysis. Log files such as log file (*. * log. *) cannot be viewed directly by tools, so they mainly analyze the write and read contents of log files from the level of source code.
Write process
The code of the whole writing process is implemented at: org apache. hudi. common. table. log. HoodieLogFormatWriter#appendBlocks
for (HoodieLogBlock block: blocks) {
long startSize = outputStream.size();
// 1. Write the magic header for the start of the block
outputStream.write(HoodieLogFormat.MAGIC);
// bytes for header
byte[] headerBytes = HoodieLogBlock.getLogMetadataBytes(block.getLogBlockHeader());
// content bytes
byte[] content = block.getContentBytes();
// bytes for footer
byte[] footerBytes = HoodieLogBlock.getLogMetadataBytes(block.getLogBlockFooter());
// 2. Write the total size of the block (excluding Magic)
outputStream.writeLong(getLogBlockLength(content.length, headerBytes.length, footerBytes.length));
// 3. Write the version of this log block
outputStream.writeInt(currentLogFormatVersion.getVersion());
// 4. Write the block type
outputStream.writeInt(block.getBlockType().ordinal());
// 5. Write the headers for the log block
outputStream.write(headerBytes);
// 6. Write the size of the content block
outputStream.writeLong(content.length);
// 7. Write the contents of the data block
outputStream.write(content);
// 8. Write the footers for the log block
outputStream.write(footerBytes);
// 9. Write the total size of the log block (including magic) which is everything written
// until now (for reverse pointer)
// Update: this information is now used in determining if a block is corrupt by comparing to the
// block size in header. This change assumes that the block size will be the last data written
// to a block. Read will break if any data is written past this point for a block.
outputStream.writeLong(outputStream.size() - startSize);
// Fetch the size again, so it accounts also (9).
sizeWritten += outputStream.size() - startSize;
}
The flow chart is summarized as follows:
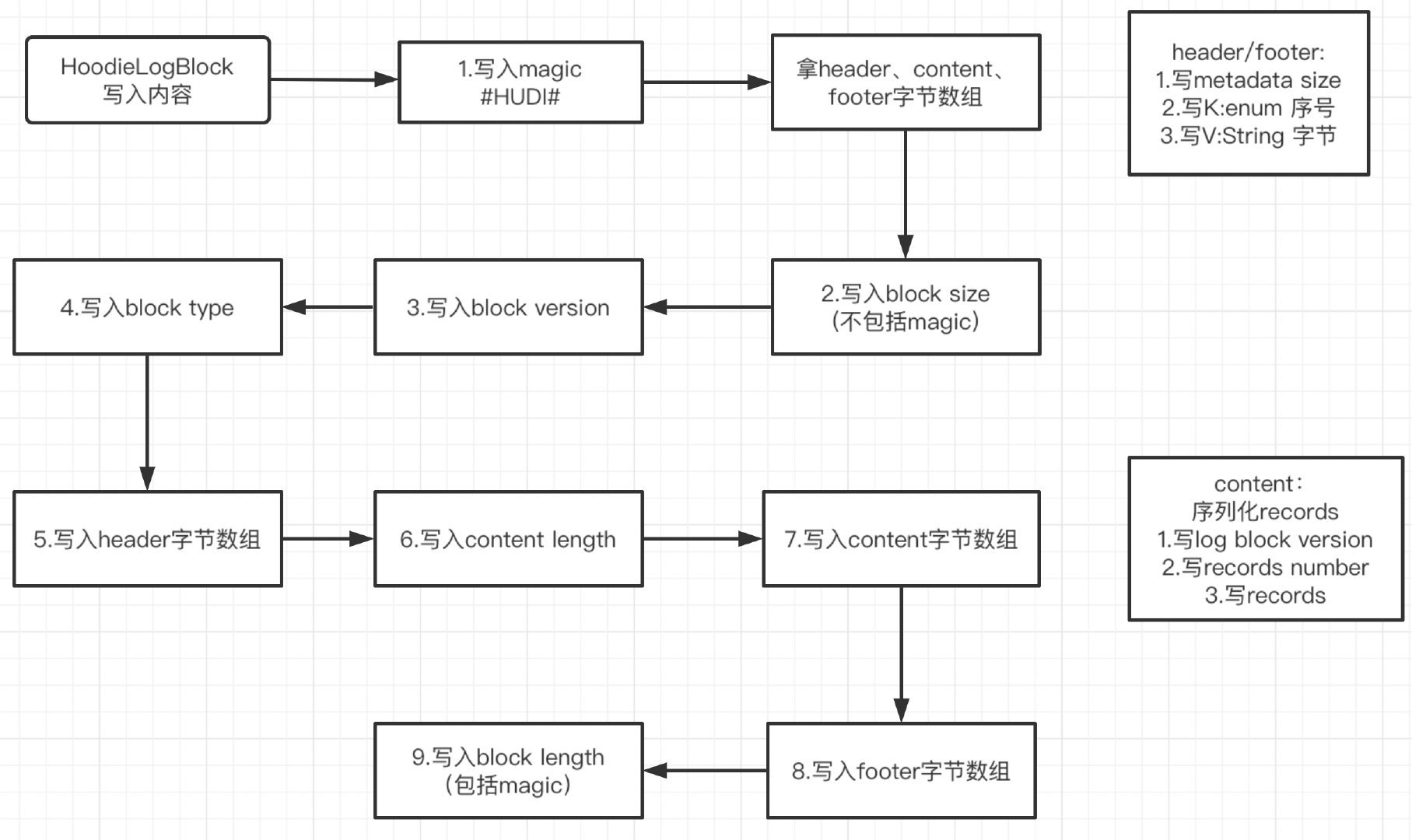
As can be seen from the figure, the logic of the written content is relatively clear:
- Write Magic with #HUDI#.
- Get the byte array of header and footer. The header/footer type is Map. The size of the Map, the sequence number of the Key (enum type) of the Map, and the Value of String type will be written in the byte array
- Get the byte array of content. Records will be serialized. log block version, number of records and records serialized by avro will be written in the byte array
- Write block size, excluding 6 bytes of Magic.
- Write log format version.
- Write block type, which is an enumeration type. Write the serial number of the enumeration and convert it into a byte array.
- Write header byte array.
- Write content length.
- Write content byte array.
- Writes the footer byte array.
- Write block length, including 6 bytes of Magic.
Read process
The code of the whole reading process is implemented at: org apache. hudi. common. table. log. HoodieLogFileReader#readBlock
The flow chart is summarized as follows:
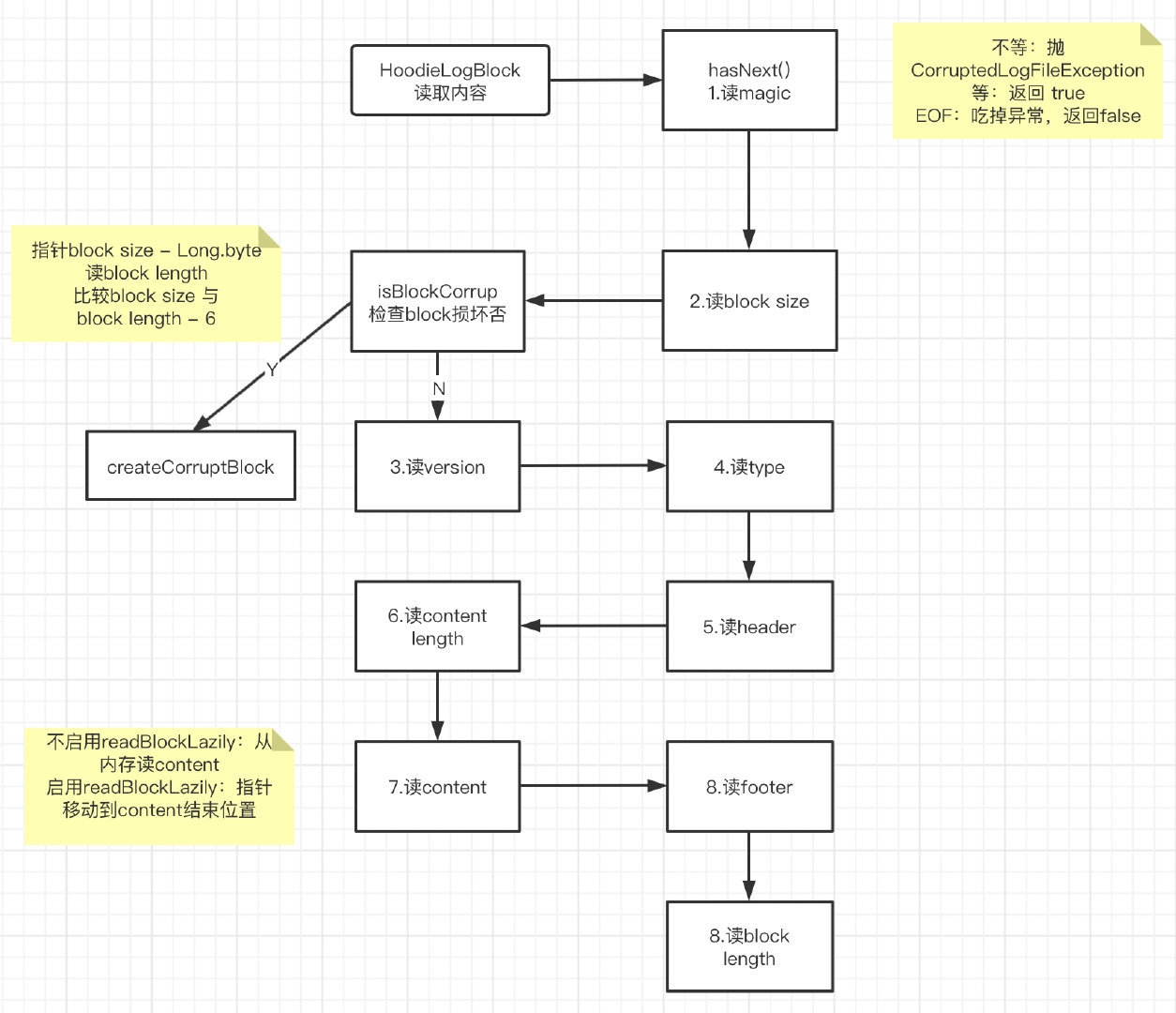
In the reading process, some verification actions will be involved:
- In the hasNext() method, read Magic.
- Verify Magic. If they are not equal, throw CorruptedLogFileException; Equal, return true; EOF reaches the end of the file, eats the exception and returns false.
- Read block size.
- Verify that the block is not damaged. The method is to move the pointer to the position where block size minus long type byte length, read block length, and compare whether block size and block length minus Magic byte length are equal. Unequal, createCorruptBlock; Equality continues.
- Read log format version.
- Read block type.
- Read the header.
- Read content length.
- Read content.
- Do not enable readBlockLazily and read content from memory; With readblock lazy enabled, the pointer moves to the end of the content.
- Read footer.
- Read block length.
Log file structure analysis
The inheritance relationship of classes related to log files in Hudi can be seen in the following figure: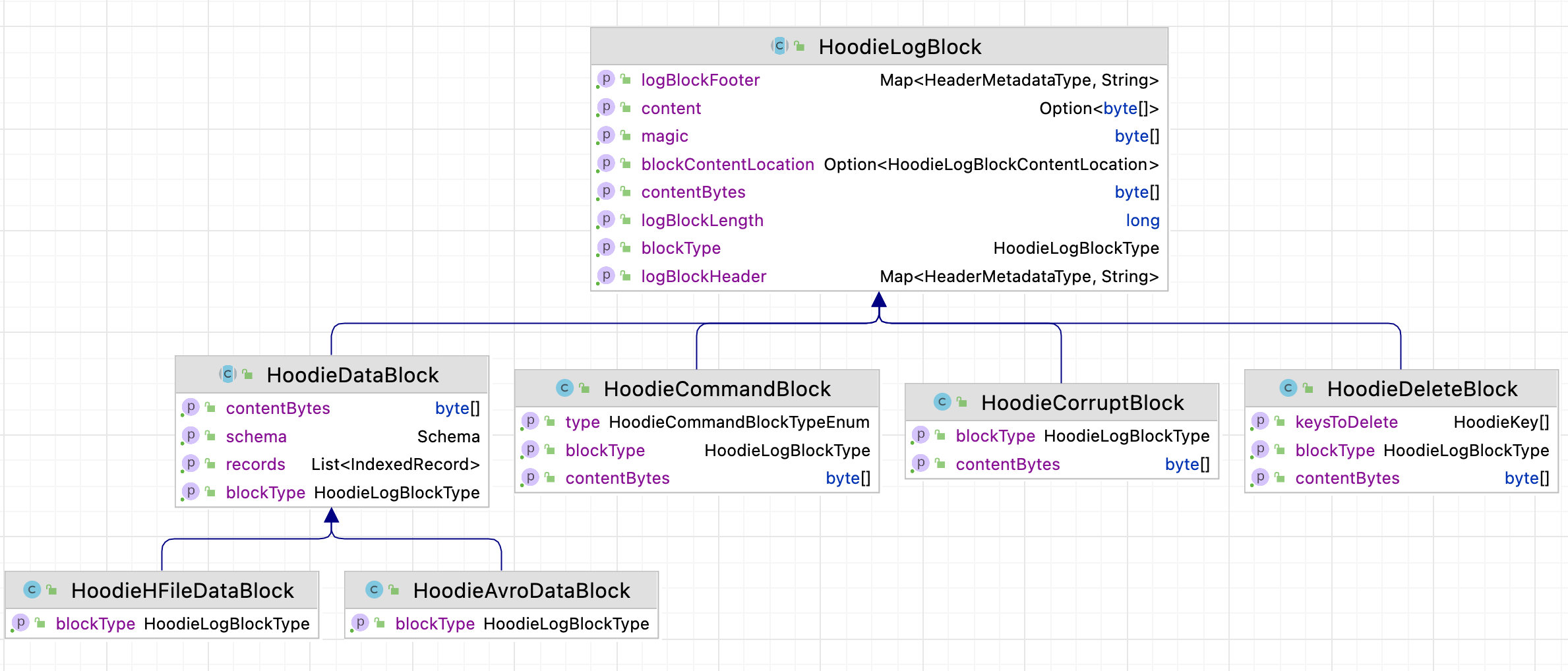
It can be seen that the attributes of the common part of the Log file are mainly defined in the houdielogblock, the attributes of the data part are mainly defined in the houdielogblock, and the serialization and deserialization of the content of the data part are defined in the houdieavrodatablock.
The Log file structure can also be summarized from the above reading and writing process:
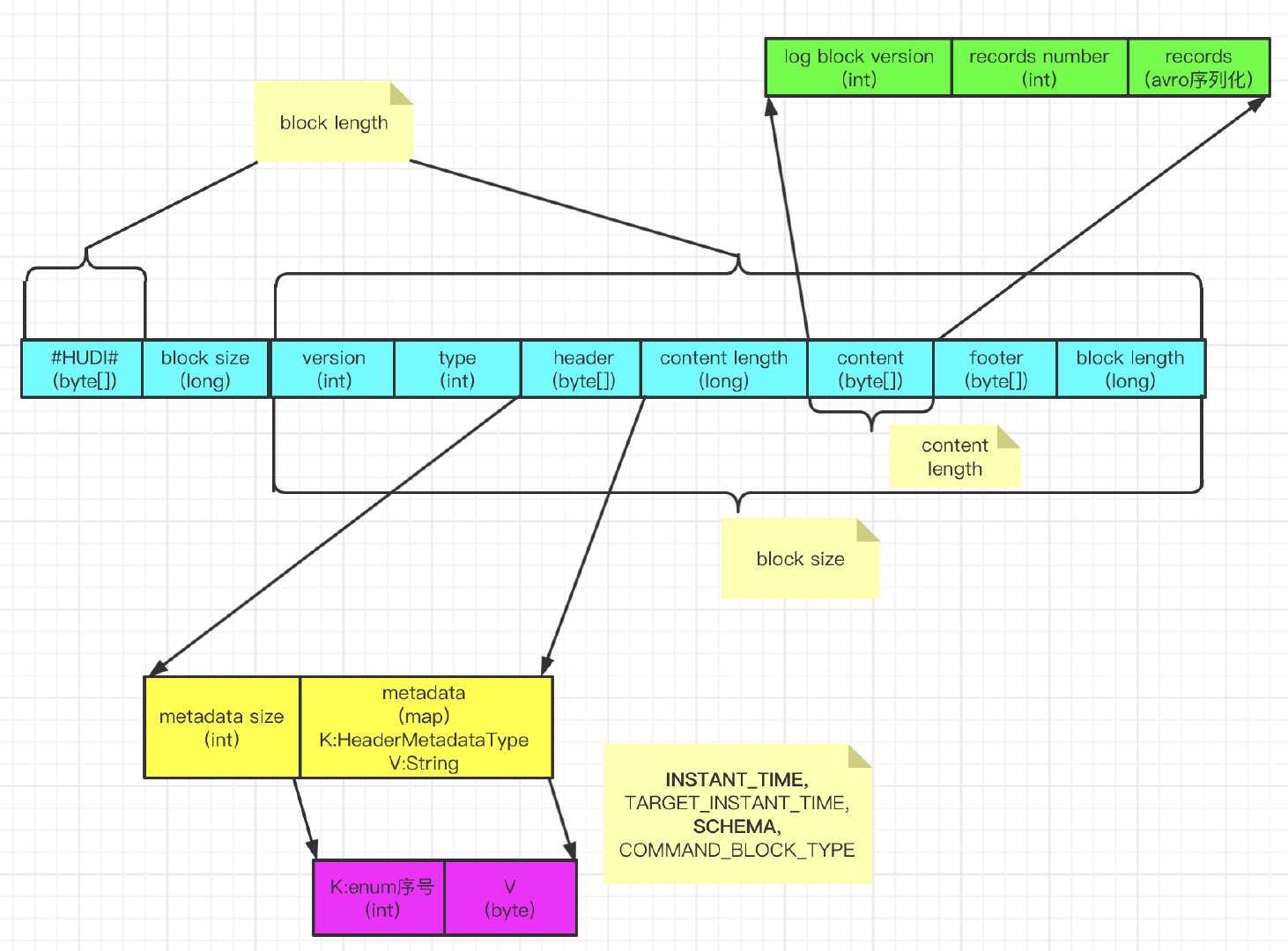
- Magic: #HUDI#, byte array type.
- blcok size: in addition to Magic's 6-byte length and its own 8-byte length, long type.
- Log format version: log format version, now 1, int type.
- block type: it is an enumeration type with a COMMAND_BLOCK, DELETE_BLOCK, CORRUPT_BLOCK, AVRO_DATA_BLOCK, HFILE_DATA_BLOCK, here is the sequence number of enumeration, int type.
- header: byte array. It is a map itself. When converted to byte array, the size of the map will be written to the byte array. The Key of map is of HeaderMetadataType type. It is an enumeration with install_ TIME, TARGET_ INSTANT_ TIME, SCHEMA, COMMAND_ BLOCK_ Type, Value is String type.
- content length: the length of the content byte array, of type long.
- content: byte array. The contents are log block version and int type; records number, int type; records is a serialized byte array.
- footer: byte array. Like the header, it is a Map. There is no content in the current version.
- block length: block size plus 6 (the byte array length of Magic), long type.
According to the reading logic of the Log file, it is not difficult to write the program code for parsing the Log file. After parsing the Log file, it can be observed that the value of block length is 8 bytes different from the size of the file itself. These 8 bytes are the byte length of block size itself, which further proves the correctness of the above analysis
summary
So far, the log file (*. * log. *) file analysis of MOR table has been completed. This paper focuses on the file structure and does not further deepen the additional exception handling in the read-write process. If there is any omission or error in the text, you are welcome to point out and discuss it.
If you have something to gain after reading, you are welcome to praise