Datawhale dry
Author: Chen Xinda, member of Datawhale, Shanghai University of science and technology
AI technology has been applied to all aspects of our life, and target detection is one of the most widely used algorithms. There is the shadow of target detection algorithm in epidemic temperature measuring instruments, inspection robots and even he's airdesk. The following figure is airdesk. Mr. He locates the position of the mobile phone through the target detection algorithm, and then controls the wireless charging coil to move under the mobile phone to automatically charge the mobile phone. Behind this seemingly simple application is actually a complex theory and iterative AI algorithm. Today, the author will teach you how to quickly start the target detection model YOLOv5 and apply it to emotion recognition.
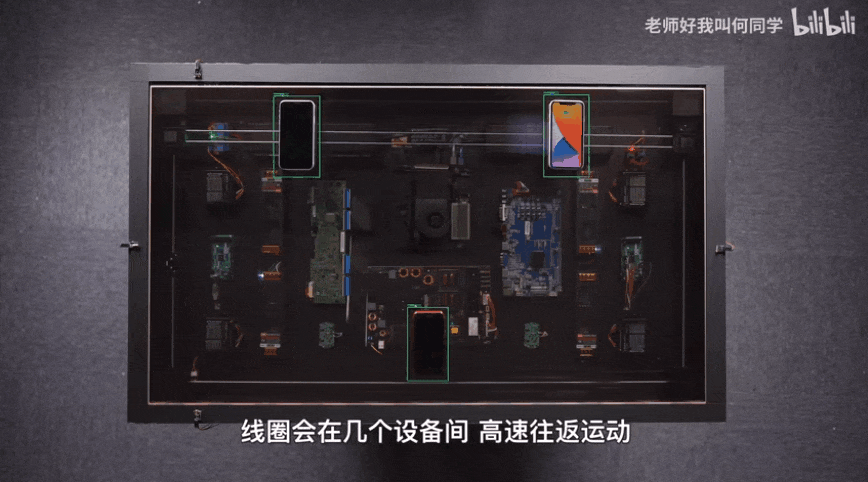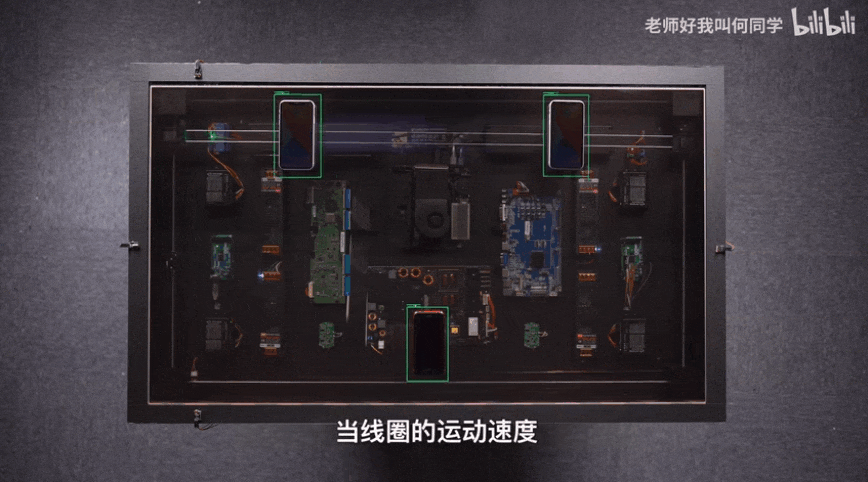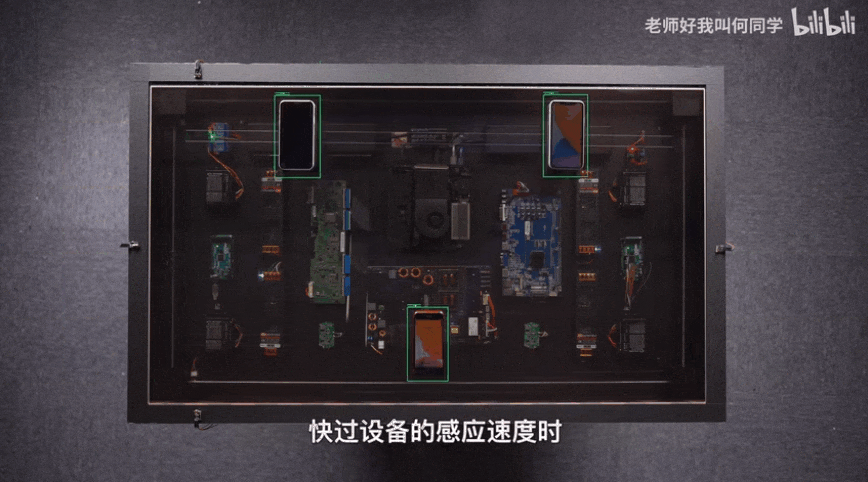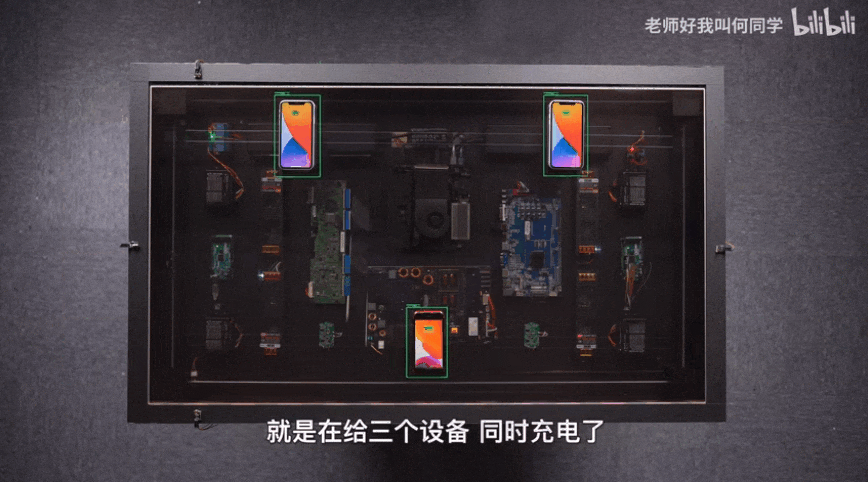
1, Background
Today's content comes from an article published on T-PAMI in 2019 [1]. Before that, a large number of researchers have recognized human emotions through AI algorithms. However, the author of this paper believes that people's emotions are not only related to facial expressions and body movements, but also closely related to the current environment. For example, the boy in the figure below should be a surprised expression:

However, after adding the surrounding environment, the emotion we just think is inconsistent with the real emotion:

The main idea of this paper is to combine the background picture with the character information detected by the target detection model to recognize emotion.
Among them, the author divides emotion into discrete and continuous dimensions. The following explanation will be made to facilitate understanding. Students who have made it clear can quickly row and skip.
Continuous emotion | explain |
|---|---|
Valence (V) | measures how positive or pleasant an emotion is, ranging from negative to positive |
Arousal (A) | Measures the excitement level of the person, ranging from non active / in call to excited / ready to act |
Dominance (D) | Measures the level of control a person feels of the situation, ranging from submit / non control to dominant / in control |
Discrete emotion | explain |
|---|---|
Affection | fond feelings; love; tenderness |
Anger | intense displeasure or rage; furious; resentful |
Annoyance | bothered by something or someone; irritated; impatient; frustrated |
Anticipation | state of looking forward; hoping on or getting prepared for possible future events |
Aversion | feeling disgust, dislike, repulsion; feeling hate |
Confidence | feeling of being certain; conviction that an outcome will be favorable; encouraged; proud |
Disapproval | feeling that something is wrong or reprehensible; contempt; hostile |
Disconnection | feeling not interested in the main event of the surrounding; indifferent; bored; distracted |
Disquietment | nervous; worried; upset; anxious; tense; pressured; alarmed |
Doubt/Confusion | difficulty to understand or decide; thinking about different options |
Embarrassment | feeling ashamed or guilty |
Engagement | paying attention to something; absorbed into something; curious; interested |
Esteem | feelings of favourable opinion or judgement; respect; admiration; gratefulness |
Excitement | feeling enthusiasm; stimulated; energetic |
Fatigue | weariness; tiredness; sleepy |
Fear | feeling suspicious or afraid of danger, threat, evil or pain; horror |
Happiness | feeling delighted; feeling enjoyment or amusement |
Pain | physical suffering |
Peace | well being and relaxed; no worry; having positive thoughts or sensations; satisfied |
Pleasure | feeling of delight in the senses |
Sadness | feeling unhappy, sorrow, disappointed, or discouraged |
Sensitivity | feeling of being physically or emotionally wounded; feeling delicate or vulnerable |
Suffering | psychological or emotional pain; distressed; anguished |
Surprise | sudden discovery of something unexpected |
Sympathy | state of sharing others emotions, goals or troubles; supportive; compassionate |
Yearning | strong desire to have something; jealous; envious; lust |
2, Preparation and model reasoning
2.1 quick start
Just complete the following five steps to identify emotions!
- Download the project locally through cloning or compressed package: git clone https://github.com/chenxindaaa/emotic.git
- Put the unzipped model file into emotic/debug_exp/models. (download address of model file: link: https://gas.graviti.com/dataset/datawhale/Emotic/discussion )
- New virtual environment (optional):
conda create -n emotic python=3.7 conda activate emotic
- Environment configuration
python -m pip install -r requirement.txt
- cd to the emotic folder, enter and execute:
python detect.py
After running, the results will be saved in the emotic/runs/detect folder.
2.2 basic principles
A little friend may ask: if I want to identify other pictures, how can I change them? Can I support video and camera? How to modify the code of YOLOv5 in practical application?
For the first two problems, YOLOv5 has helped us solve them. We only need to modify detect Line 158 of Py:
parser.add_argument('--source', type=str, default='./testImages', help='source') # file/folder, 0 for webcam
Will '/ Change 'testImages' to the path of the image and video you want to recognize, or the path of the folder. For calling the camera, just put '/ If 'testImages' is changed to' 0 ', camera 0 will be called for identification.
Modify YOLOv5:
In detect Py, the most important code is the following lines:
for *xyxy, conf, cls in reversed(det):
c = int(cls) # integer class
if c != 0:
continue
pred_cat, pred_cont = inference_emotic(im0, (int(xyxy[0]), int(xyxy[1]), int(xyxy[2]), int(xyxy[3])))
if save_img or opt.save_crop or view_img: # Add bbox to image
label = None if opt.hide_labels else (names[c] if opt.hide_conf else f'{names[c]} {conf:.2f}')
plot_one_box(xyxy, im0, pred_cat=pred_cat, pred_cont=pred_cont, label=label, color=colors(c, True), line_thickness=opt.line_thickness)
if opt.save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
Where det is the result recognized by YOLOv5. For example, tensor ([[121.00000, 7.00000, 480.00000, 305.00000, 0.67680, 0.00000], [278.00000, 166.00000, 318.00000, 305.00000, 0.66222, 27.00000]) recognizes two objects.
Xyxy is the coordinate of the object detection frame. For the first object in the above example, xyxy = [121.00000, 7.00000, 480.00000, 305.00000] corresponds to the coordinates (121, 7) and (480, 305). Two points can determine a rectangle, that is, the detection frame. conf is the confidence of the object, and the confidence of the first object is 0.67680. cls is the category corresponding to the object. Here 0 corresponds to "person". Because we only know other people's emotions, cls can skip the process if it is not 0. Here I use the reasoning model officially given by YOLOv5, which contains many categories. You can also train a model with only "people". For the detailed process, please refer to:
After identifying the object coordinates, the corresponding emotion can be obtained by inputting the emotic model, that is
pred_cat, pred_cont = inference_emotic(im0, (int(xyxy[0]), int(xyxy[1]), int(xyxy[2]), int(xyxy[3])))
Here I make some changes to the original image visualization and print the emotic results on the image:
def plot_one_box(x, im, pred_cat, pred_cont, color=(128, 128, 128), label=None, line_thickness=3):
# Plots one bounding box on image 'im' using OpenCV
assert im.data.contiguous, 'Image not contiguous. Apply np.ascontiguousarray(im) to plot_on_box() input image.'
tl = line_thickness or round(0.002 * (im.shape[0] + im.shape[1]) / 2) + 1 # line/font thickness
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(im, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(im, c1, c2, color, -1, cv2.LINE_AA) # filled
#cv2.putText(im, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
for id, text in enumerate(pred_cat):
cv2.putText(im, text, (c1[0], c1[1] + id*20), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
Operation results:

After completing the above steps, we can start the whole work. As we all know, trump has conquered many voters with his unique speech charm. Let's take a look at Trump's speech in the eyes of AI:

It can be seen that self-confidence is one of the necessary conditions for convincing.
Three, model training
3.1 data preprocessing
Firstly, the data is preprocessed through grid titanium. Before processing the data, you need to find your own accessKey (developer tool \ rightarrow AccessKey\rightarrow new AccessKey):
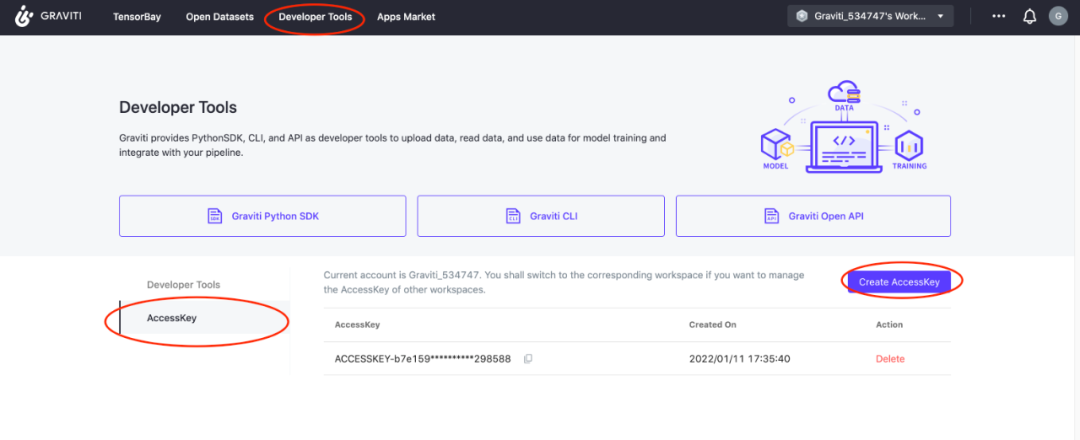
We can preprocess through grid titanium without downloading the data set, and save the results locally (the following code is not in the project, so we need to create a py file to run, and remember to fill in the AccessKey):
from tensorbay import GAS
from tensorbay.dataset import Dataset
import numpy as np
from PIL import Image
import cv2
from tqdm import tqdm
import os
def cat_to_one_hot(y_cat):
cat2ind = {'Affection': 0, 'Anger': 1, 'Annoyance': 2, 'Anticipation': 3, 'Aversion': 4,
'Confidence': 5, 'Disapproval': 6, 'Disconnection': 7, 'Disquietment': 8,
'Doubt/Confusion': 9, 'Embarrassment': 10, 'Engagement': 11, 'Esteem': 12,
'Excitement': 13, 'Fatigue': 14, 'Fear': 15, 'Happiness': 16, 'Pain': 17,
'Peace': 18, 'Pleasure': 19, 'Sadness': 20, 'Sensitivity': 21, 'Suffering': 22,
'Surprise': 23, 'Sympathy': 24, 'Yearning': 25}
one_hot_cat = np.zeros(26)
for em in y_cat:
one_hot_cat[cat2ind[em]] = 1
return one_hot_cat
gas = GAS('Fill in your AccessKey')
dataset = Dataset("Emotic", gas)
segments = dataset.keys()
save_dir = './data/emotic_pre'
if not os.path.exists(save_dir):
os.makedirs(save_dir)
for seg in ['test', 'val', 'train']:
segment = dataset[seg]
context_arr, body_arr, cat_arr, cont_arr = [], [], [], []
for data in tqdm(segment):
with data.open() as fp:
context = np.asarray(Image.open(fp))
if len(context.shape) == 2:
context = cv2.cvtColor(context, cv2.COLOR_GRAY2RGB)
context_cv = cv2.resize(context, (224, 224))
for label_box2d in data.label.box2d:
xmin = label_box2d.xmin
ymin = label_box2d.ymin
xmax = label_box2d.xmax
ymax = label_box2d.ymax
body = context[ymin:ymax, xmin:xmax]
body_cv = cv2.resize(body, (128, 128))
context_arr.append(context_cv)
body_arr.append(body_cv)
cont_arr.append(np.array([int(label_box2d.attributes['valence']), int(label_box2d.attributes['arousal']), int(label_box2d.attributes['dominance'])]))
cat_arr.append(np.array(cat_to_one_hot(label_box2d.attributes['categories'])))
context_arr = np.array(context_arr)
body_arr = np.array(body_arr)
cat_arr = np.array(cat_arr)
cont_arr = np.array(cont_arr)
np.save(os.path.join(save_dir, '%s_context_arr.npy' % (seg)), context_arr)
np.save(os.path.join(save_dir, '%s_body_arr.npy' % (seg)), body_arr)
np.save(os.path.join(save_dir, '%s_cat_arr.npy' % (seg)), cat_arr)
np.save(os.path.join(save_dir, '%s_cont_arr.npy' % (seg)), cont_arr)
After the program runs, you can see an additional folder emotic_pre, there are some npy files in it, which means that the data preprocessing is successful.
3.2 model training
Open main Py file, the beginning of line 35 is the training parameters of the model. Run this file to start training.
4, Detailed explanation of Emotic model
4.1 model structure
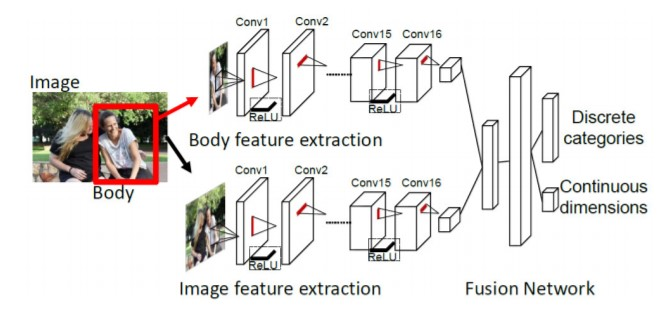
The idea of the model is very simple. The upper and lower networks in the flow chart are actually two resnet18. The upper network is responsible for extracting human body features. The input is 128 \times 128 color images, and the output is 512 1\times 1 feature images. The following network is responsible for extracting image background features. The pre training model uses the scene classification model places365. The input is 224\times 224 color images, and the output is also 512 1\times 1 feature images. Then the two output flatten are spliced into a 1024 vector. After two full connection layers, a 26 dimensional vector and a 3-dimensional vector are output. The 26 dimensional vector processes 26 discrete emotion classification tasks, and the 3-dimensional vector is three continuous emotion regression tasks.
import torch
import torch.nn as nn
class Emotic(nn.Module):
''' Emotic Model'''
def __init__(self, num_context_features, num_body_features):
super(Emotic,self).__init__()
self.num_context_features = num_context_features
self.num_body_features = num_body_features
self.fc1 = nn.Linear((self.num_context_features + num_body_features), 256)
self.bn1 = nn.BatchNorm1d(256)
self.d1 = nn.Dropout(p=0.5)
self.fc_cat = nn.Linear(256, 26)
self.fc_cont = nn.Linear(256, 3)
self.relu = nn.ReLU()
def forward(self, x_context, x_body):
context_features = x_context.view(-1, self.num_context_features)
body_features = x_body.view(-1, self.num_body_features)
fuse_features = torch.cat((context_features, body_features), 1)
fuse_out = self.fc1(fuse_features)
fuse_out = self.bn1(fuse_out)
fuse_out = self.relu(fuse_out)
fuse_out = self.d1(fuse_out)
cat_out = self.fc_cat(fuse_out)
cont_out = self.fc_cont(fuse_out)
return cat_out, cont_out
Discrete emotion is a multi classification task, that is, a person may have multiple emotions at the same time. The author's processing method is to manually set 26 thresholds corresponding to 26 emotions. If the output value is greater than the threshold, it is considered that the person has corresponding emotions. The threshold is as follows. It can be seen that the corresponding threshold of engagement is 0, that is, everyone will contain this emotion every time they recognize:
>>> import numpy as np
>>> np.load('./debug_exp/results/val_thresholds.npy')
array([0.0509765 , 0.02937193, 0.03467856, 0.16765128, 0.0307672 ,
0.13506265, 0.03581731, 0.06581657, 0.03092133, 0.04115443,
0.02678059, 0. , 0.04085711, 0.14374524, 0.03058549,
0.02580678, 0.23389584, 0.13780132, 0.07401864, 0.08617007,
0.03372583, 0.03105414, 0.029326 , 0.03418647, 0.03770866,
0.03943525], dtype=float32)
4.2 loss function:
For the classification task, the author provides two loss functions, one is the ordinary mean square error loss function (i.e. self. Weight_type = ='mean '), and the other is the weighted square error loss function (i.e. self. Weight_type = ='static'). Among them, the weighted square error loss function is as follows. The weights corresponding to 26 categories are [0.1435, 0.1870, 0.1692, 0.1165, 0.1949, 0.1204, 0.1728, 0.1372, 0.1620, 0.1540, 0.1987, 0.1057, 0.1482, 0.1192, 0.1590, 0.1929, 0.1158, 0.1907, 0.1345, 0.1307, 0.1665, 0.1698, 0.1797, 0.1657, 0.1520, 0.1537].
L(\hat y) = \sum^{26}_{i=1}w_i(\hat y_i - y_i)^2class DiscreteLoss(nn.Module):
''' Class to measure loss between categorical emotion predictions and labels.'''
def __init__(self, weight_type='mean', device=torch.device('cpu')):
super(DiscreteLoss, self).__init__()
self.weight_type = weight_type
self.device = device
if self.weight_type == 'mean':
self.weights = torch.ones((1,26))/26.0
self.weights = self.weights.to(self.device)
elif self.weight_type == 'static':
self.weights = torch.FloatTensor([0.1435, 0.1870, 0.1692, 0.1165, 0.1949, 0.1204, 0.1728, 0.1372, 0.1620,
0.1540, 0.1987, 0.1057, 0.1482, 0.1192, 0.1590, 0.1929, 0.1158, 0.1907,
0.1345, 0.1307, 0.1665, 0.1698, 0.1797, 0.1657, 0.1520, 0.1537]).unsqueeze(0)
self.weights = self.weights.to(self.device)
def forward(self, pred, target):
if self.weight_type == 'dynamic':
self.weights = self.prepare_dynamic_weights(target)
self.weights = self.weights.to(self.device)
loss = (((pred - target)**2) * self.weights)
return loss.sum()
def prepare_dynamic_weights(self, target):
target_stats = torch.sum(target, dim=0).float().unsqueeze(dim=0).cpu()
weights = torch.zeros((1,26))
weights[target_stats != 0 ] = 1.0/torch.log(target_stats[target_stats != 0].data + 1.2)
weights[target_stats == 0] = 0.0001
return weights
For the regression task, the author also provides two loss functions, L2 loss function:
L_2(\hat y) = \sum^3_{k=1}v_k(\hat y_k - y_k)^2Where, when | \ hat y_ k - y_ When k | < margin (default is 1), v_k=0, otherwise v_{k} = 1 .
L1 loss function:
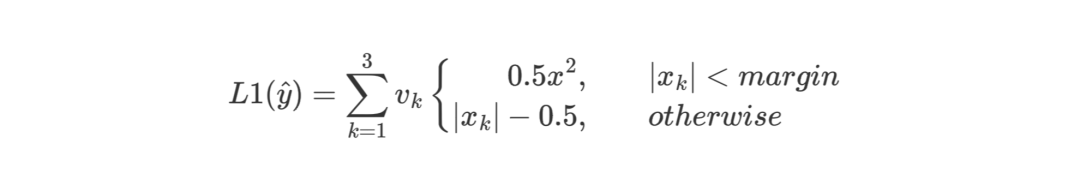
Where, when | \ hat y_ k - y_ When k | < margin (default is 1), v_k=0, otherwise v_{k} = 1 .
class ContinuousLoss_L2(nn.Module):
''' Class to measure loss between continuous emotion dimension predictions and labels. Using l2 loss as base. '''
def __init__(self, margin=1):
super(ContinuousLoss_L2, self).__init__()
self.margin = margin
def forward(self, pred, target):
labs = torch.abs(pred - target)
loss = labs ** 2
loss[ (labs < self.margin) ] = 0.0
return loss.sum()
class ContinuousLoss_SL1(nn.Module):
''' Class to measure loss between continuous emotion dimension predictions and labels. Using smooth l1 loss as base. '''
def __init__(self, margin=1):
super(ContinuousLoss_SL1, self).__init__()
self.margin = margin
def forward(self, pred, target):
labs = torch.abs(pred - target)
loss = 0.5 * (labs ** 2)
loss[ (labs > self.margin) ] = labs[ (labs > self.margin) ] - 0.5
return loss.sum()
Dataset link: https://gas.graviti.com/dataset/datawhale/Emotic
[1]Kosti R, Alvarez J M, Recasens A, et al. Context based emotion recognition using emotic dataset[J]. IEEE transactions on pattern analysis and machine intelligence, 2019, 42(11): 2755-2766.
YOLOv5 project address: https://github.com/ultralytics/yolov5
Emotic project address: https://github.com/Tandon-A/emotic