Baidu sexy beauty wallpaper to understand, for nothing else, is to be able to better learn Python! Do you believe that?
As long as I see the website with photos of my sister, I just want to download them in bulk!
Why to learn about web crawlers
(1) Learning the web crawler, you can customize a search engine to better understand the principle of data collection
(2) Provide more high-quality data sources for big data analysis and obtain more valuable information
(3) It can understand the working principle of search engine crawler in a deeper level, so that search engine optimization can be carried out better
(4) From the employment point of view, reptile engineers are also in short supply, so learning online reptiles is very beneficial to employment
Big Internet companies
I used to work in an Internet company, and I thought it was so easy to get data. As long as you need, it seems that there are all kinds of data. When there are too many data, you have to age some unimportant data on time. Unimportant data will not be accepted.
Traditional industries and small companies
After leaving the big Internet companies, there are more companies contacted. Many companies have no data, but they still want to do big data. I didn't understand it. Don't you have any data for big data? This is not to let the horse run, but to give the horse grass.
But now I don't think so. In the boom of big data, we are afraid to miss this tuyere, so we must participate in it. No matter how big data changes the traditional industry, we can see it, such as uber's change to taxi, yu'ebao's change to finance, etc. So we need to find a way to get data, rather than we don't do big data without data.
data sources
On the one hand, to make their products Internet, data can be accumulated, but the journey is long.
On the other hand, get data from the Internet. But the data in the Internet is not open, so the crawler can be used, and also can get the data quickly.
Main contents of the topic
Reptile technology exchange
Data sharing
Give code to code. Good things must be shared and enjoyed!
1 Here's a system for you to share Python Learning resources 2 Plus what I built Python Technical study button skirt; 937667509, study together 3 # !/usr/bin/env python 4 # -*- coding:utf-8 -*- 5 import requests 6 import json 7 # Define a request function,Receive page parameters 8 def get_page(page): 9 # Add page parameters to url In the string of 10 url = 'https://image.baidu.com/search/acjson?tn=resultjson_ Com & IPN = RJ & CT = 201326592 & is = & FP = result & queryword = Beauty & CL = 2 & LM = - 1 & ie = UTF-8 & OE = UTF-8 & adpicid = & St = - 1 & z = & ic = 0 & word = Beauty & S = & SE = & tab = & width = & height = & face = 0 & istype = 2 & QC = & NC = 1 & fr = & CG = girl & PN = {} & RN = 30 & GSM = 1e'.format( 11 page) 12 # Request website,And get a response from the website 13 response = requests.get(url) 14 # Judge the status 15 if response.status_code == 200: 16 # Return text file information 17 return response.text 18 def json_load(text): 19 # Processing text files into dictionary format 20 jsondict = json.loads(text) 21 # Create an empty collection,The function is to remove weight 22 urlset = set() 23 # Check whether the dictionary contains data This value 24 if 'data' in jsondict.keys(): 25 # from jsondict Middle out data What's in this dictionary,Assign to items! 26 for items in jsondict.get('data'): 27 # exception handling,Not every row of data contains thumbURL This data 28 try: 29 urlset.add(items['thumbURL']) 30 except: 31 pass 32 return urlset 33 def down_cont(url): 34 response = requests.get(url) 35 name = url.split(',')[-1].split('&')[0] 36 if response.status_code == 200: 37 # express,If the file name is the same,Delete the current file,And then create a file with the same name 38 with open('./images/%s.jpg' % name, 'wb') as f: 39 print('Downloading current picture: ' + url) 40 # Write locally as binary 41 f.write(response.content) 42 def main(): 43 for p in range(5): 44 print('Downloading %s Picture of page' % p) 45 page = p * 30 46 text = get_page(page) 47 urlset = json_load(text) 48 for url in urlset: 49 down_cont(url) 50 if __name__ == '__main__': 51 main()
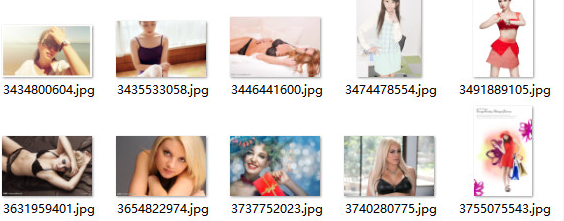
Operation rendering