This article is the sixth in the "malicious web page identification using PaddleNLP" series, which is continuously updated
Series background: Malicious web page identification using PaddleNLP A series of projects focus on one of the biggest challenges in current network security management - how to prevent users from accessing malicious web pages beneficially / unintentionally, thus causing losses to enterprises, and try to use artificial intelligence technology to put forward corresponding solutions to this problem.
There is also a sister article in the series, Identifying spam using PaddleNLP , interested readers are welcome to click in and exchange comments
Series catalog
- Malicious web page identification using PaddleNLP (I)
- Using the text classification model of paddelnlp, make a simple binary classification of normal web pages and black web pages, and judge whether the web pages are normal according to the HTML web page content processing results.
- Malicious web page identification using PaddleNLP (2)
- Fine tune, the Ernie pre training model of PaddleNLP, is used to greatly improve the accuracy of judging web pages according to the results of HTML web page content processing.
- Malicious web page identification using PaddleNLP (3)
- Use the text classification model of PaddleNLP to do the simple binary classification of normal web pages and malicious web pages, extract HTML tag information and judge whether the web pages are normal.
- Malicious web page identification using PaddleNLP (4)
- Try to use manual judgment conditions to design the process of extracting HTML tag information and identifying malicious web pages.
- Fine tune, a pre training model of PaddleNLP, is used to improve the effect of extracting HTML tag information to judge whether the web page is normal.
- Export the web page classification model trained by dynamic graph and deploy it in Python.
- Malicious web page identification using PaddleNLP (V)
- The project directly benchmarked the second part of the series to compare the differences between BERT Chinese pre training model and Ernie pre training model in the process and effect of HTML web page content classification.
- The project further improved and optimized the HTML web page content extraction and data cleaning process.
- The accuracy of the model on the validation set can easily reach more than 91.5%, up to 95%. finetune on the BERT pre training model has obtained the best performance in the HTML web page content classification task.
- Malicious web page identification using PaddleNLP (6)
- The project directly benchmarked the fourth part of the series to compare the difference between BERT Chinese pre training model and Ernie pre training model in the classification effect of HTML web page tags.
- The project further improves and optimizes the HTML tag content extraction and data cleaning process.
- The accuracy of the model on the validation set can easily reach more than 96.5%, and the accuracy on the test set is close to 97%. The best performance in the HTML web page tag sequence classification task is obtained by finetune on the BERT pre training model.
- Malicious web page identification using PaddleNLP (7)
- This paper introduces the method of web page snapshot capture using selenium, an automatic testing tool.
- This paper introduces the method of locating and parsing two-dimensional code of web page snapshot using zxing open source library.
- This paper introduces the idea of identifying and classifying the url web links contained in the QR code using the model trained in the sixth part of the series.
Project introduction
The data sets used in this project are from Malware Analysis Based on data science by Joshua Saxe and Hillary Sanders
In Chapter 11 of the book, there is a set of about 100000 normal and malicious HTML files.
The dataset includes two folders:
- Normal HTML file ch11/data/html/benign_files/
- Malicious HTML file ch11/data/html/malicious_files/
Remember not to open these files in the browser!
The original data set has been carefully prepared and the data distribution is as follows:
- Training set
- 45000 normal HTML web page files
- 45000 malicious HTML web page files
- Validation set
- 5000 normal HTML web page files
- 5000 malicious HTML web page files
The contents of these HTML files cover English, Chinese, Russian and other languages. If you try to classify malicious web pages from the perspective of web content, you will face the great challenge of multilingual processing.
Therefore, in the project Malicious web page identification using PaddleNLP (3) By trying to extract the "Commonness" - HTML tag sequence of multilingual HTML pages and then classify the text, a good effect is achieved (the demo accuracy is greater than 84%).
In project Malicious web page identification using PaddleNLP (4) Based on Ernie pre training model, the recognition accuracy of HTML tag sequence classification is further improved to more than 94%.
So, if you change to BERT, what will the effect be? This project will be discussed.
# Unzip and extract the dataset !unzip data/data69222/64652.zip !mv malware_data_science/ch11/chapter_11_UNDER_40/data/html ./
1, Environment configuration
!pip install bs4 !pip install html5lib !pip install HTMLParser
import os import sys import codecs import chardet import shutil import time from tqdm import tqdm, trange from bs4 import BeautifulSoup import re from html.parser import HTMLParser from functools import partial import numpy as np import paddle import paddlenlp as ppnlp from paddlenlp.data import Stack, Pad, Tuple import paddle.nn.functional as F import paddle.nn as nn from visualdl import LogWriter import random
2, Prepare dataset
2.1 optimize HTML tag extraction results
Running previous project Malicious web page identification using PaddleNLP (3) It is found that in fact, the label extraction results of individual samples are not ideal in the project Malicious web page identification using PaddleNLP (4) Yes. The treatment is too simple and rough.
In this project, a simpler and more accurate label extraction method is found:
text = []
# Find a web page to analyze
html = BeautifulSoup(open('html/malicious_files/validation/99f756bfa3f3c3be65550b2d27abccb90496089b24252130ce16edc7b83c1ba5'),'html.parser', from_encoding='utf-8')
for tag in html.find_all(True):
text.append(tag.name)
print(','.join(text))
html,head,meta,title,body,script,script
2.2 character encoding processing
def change_code(input_path, output_path):
for filename in tqdm(os.listdir(input_path)):
# Let's make a judgment first. There's a file_ The file in the list does not exist
if os.path.exists(input_path+filename):
# Read the file and get the character set
content = codecs.open(input_path+filename,'rb').read()
source_encoding = chardet.detect(content)['encoding']
# Source of individual files_ Encoding is None. You need to filter here first
if source_encoding is None:
pass
# Try transcoding a file whose character set is not in utf-8 format
elif source_encoding != 'utf-8':
# If transcoding fails, skip the file
try:
content = content.decode(source_encoding).encode('utf-8')
codecs.open(output_path+filename,'wb').write(content)
except UnicodeDecodeError:
print(filename + "read failure")
pass
# The character set is saved directly in utf-8 format
else:
codecs.open(output_path+filename,'wb').write(content)
else:
pass
!mkdir -p change_code/benign_files/training/ !mkdir -p change_code/benign_files/validation/ !mkdir -p change_code/malicious_files/training/ !mkdir -p change_code/malicious_files/validation/
change_code('html/benign_files/validation/', 'change_code/benign_files/validation/')
change_code('html/benign_files/training/', 'change_code/benign_files/training/')
change_code('html/malicious_files/training/', 'change_code/malicious_files/training/')
change_code('html/malicious_files/validation/', 'change_code/malicious_files/validation/')
2.3 batch extraction of HTML tag sequence of web pages
# Create extracted training sets
def creat_trainset(path, label):
for i, filename in enumerate(tqdm(os.listdir(path))):
tag_list = []
text = ''
html = BeautifulSoup(open(path + filename),'html.parser', from_encoding='utf-8')
for tag in html.find_all(True):
tag_list.append(tag.name)
text = ','.join(tag_list)
with open("webtrain.txt","a+") as f:
f.write(text + '\t' + label + '\n')
creat_trainset('change_code/benign_files/training/', '1')
creat_trainset('change_code/malicious_files/training/', '0')
# Create extracted training sets
def creat_valset(path, label):
for i, filename in enumerate(tqdm(os.listdir(path))):
tag_list = []
text = ''
html = BeautifulSoup(open(path + filename),'html.parser', from_encoding='utf-8')
for tag in html.find_all(True):
tag_list.append(tag.name)
text = ','.join(tag_list)
with open("webval.txt","a+") as f:
f.write(text + '\t' + label + '\n')
creat_valset('change_code/benign_files/validation/', '1')
creat_valset('change_code/malicious_files/validation/', '0')
2.4 out of order processing and re dividing the data set
#Count the total number of original training set and test set respectively
train_num = 0
non_train_num = 0
all_train_list = []
all_non_train_list = []
f = open("webval.txt","r")
lines = f.readlines() #Read all the contents and return as a list
for line in lines:
all_non_train_list.append(line)
non_train_num +=1
f = open("webtrain.txt","r")
lines = f.readlines() #Read all the contents and return as a list
for line in lines:
all_train_list.append(line)
train_num +=1
data_list_path="./"
all_data_path=data_list_path + "all_data.txt"
all_data_list = all_train_list + all_non_train_list
random.shuffle(all_data_list)
#Generating all_ Before data.txt, empty it first
with open(all_data_path, 'w') as f:
f.seek(0)
f.truncate()
with open(all_data_path, 'a') as f:
for data in all_data_list:
f.write(data)
with open(os.path.join(data_list_path, 'eval_list.txt'), 'w', encoding='utf-8') as f_eval:
f_eval.seek(0)
f_eval.truncate()
with open(os.path.join(data_list_path, 'train_list.txt'), 'w', encoding='utf-8') as f_train:
f_train.seek(0)
f_train.truncate()
with open(os.path.join(data_list_path, 'test_list.txt'), 'w', encoding='utf-8') as f_test:
f_test.seek(0)
f_test.truncate()
with open(os.path.join(data_list_path, 'all_data.txt'), 'r', encoding='utf-8') as f_data:
lines = f_data.readlines()
i = 0
with open(os.path.join(data_list_path, 'eval_list.txt'), 'a', encoding='utf-8') as f_eval, open(os.path.join(data_list_path, 'test_list.txt'), 'w', encoding='utf-8') as f_test,open(os.path.join(data_list_path, 'train_list.txt'), 'a', encoding='utf-8') as f_train:
for line in lines:
label= line.split('\t')[-1].replace('\n', '')
words= line.split('\t')[0]
labs = ""
if len(words) > 0:
if i % 10 == 0:
labs = words + '\t' + label + '\n'
f_eval.write(labs)
elif i % 10 ==1:
labs = words + '\t' + label + '\n'
f_test.write(labs)
else:
labs = words + '\t' + label + '\n'
f_train.write(labs)
i += 1
print("Data list generation completed!")
2.5 custom dataset
class SelfDefinedDataset(paddle.io.Dataset):
def __init__(self, data):
super(SelfDefinedDataset, self).__init__()
self.data = data
def __getitem__(self, idx):
return self.data[idx]
def __len__(self):
return len(self.data)
def get_labels(self):
return ["0", "1"]
def txt_to_list(file_name):
res_list = []
for line in open(file_name):
res_list.append(line.strip().split('\t'))
return res_list
trainlst = txt_to_list('train_list.txt')
devlst = txt_to_list('eval_list.txt')
testlst = txt_to_list('test_list.txt')
train_ds, dev_ds, test_ds= SelfDefinedDataset.get_datasets([trainlst, devlst, testlst])
# Prepare label
label_list = train_ds.get_labels()
print(label_list)
#See what the data looks like, and print the first data of training set, verification set and test set respectively.
print("Training set data:{}\n".format(train_ds[0:1]))
print("Validation set data:{}\n".format(dev_ds[0:1]))
print("Test set data:{}\n".format(test_ds[0:1]))
print("Number of training set samples:{}".format(len(train_ds)))
print("Number of validation set samples:{}".format(len(dev_ds)))
print("Number of test set samples:{}".format(len(test_ds)))
['0', '1'] Training set data:[['html,head,script,script', '0']] Validation set data:[['html,head,meta,title,script,title,base,link,body,table,tr,td,a,img,td,a,img,a,img,a,img,a,img,table,tr,td,a,a,a,td,a,a,a,table,tr,td,table,tr,td,table,tr,td,img,td,td,img,table,tr,td,table,tr,td,img,tr,td,a,br,a,br,a,br,a,br,a,br,a,br,a,br,a,br,a,br,a,br,a,br,a,br,a,br,tr,td,img,tr,td,table,tr,td,img,td,td,img,table,tr,td,table,tr,td,img,tr,td,form,select,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,option,input,tr,td,img,tr,td,table,tr,td,img,td,td,a,img,img,table,tr,td,table,tr,td,img,tr,td,a,img,br,a,br,tr,td,img,tr,td,table,tr,td,img,td,td,img,table,tr,td,table,tr,td,img,tr,td,form,input,input,input,br,br,a,b,tr,td,img,tr,td,table,tr,td,img,td,td,img,table,tr,td,table,tr,td,img,tr,td,a,br,a,tr,td,img,td,table,tr,td,table,tr,td,td,img,tr,td,img,tr,td,table,tr,td,tr,td,img,tr,td,table,tr,td,table,tr,td,img,td,a,img,td,img,td,table,tr,td,table,tr,td,img,td,td,a,img,img,table,tr,td,table,tr,td,img,tr,td,tr,td,img,tr,td,table,tr,td,img,td,td,img,table,tr,td,table,tr,td,img,tr,td,table,tr,td,td,a,tr,td,td,a,tr,td,td,a,tr,td,td,a,tr,td,td,a,tr,td,td,a,tr,td,td,a,tr,td,td,a,tr,td,td,a,tr,td,td,a,tr,td,img,tr,td,table,tr,td,img,td,td,a,img,img,table,tr,td,table,tr,td,img,tr,td,tr,td,img,tr,td,table,tr,td,img,td,td,img,table,tr,td,table,tr,td,img,tr,td,a,img,a,img,tr,td,img,tr,td,table,tr,td,img,td,td,img,table,tr,td,table,tr,td,img,tr,td,form,select,option,option,option,input,tr,td,img,table,tr,td,td,br,table,tr,td,br,table,tr,td,br', '0']] Test set data:[['html,head,meta,title,script,link,link,link,link,link,body,style,div,a,div,div,div,div,div,div,div,div,div,div,script,br,br,br,br,a,br,br,br,br,script,script,script,script,script,script,script,script,script,script,script,script,script', '1']] Number of training set samples:78075 Number of validation set samples:9767 Number of test set samples:9760
2.6 data preprocessing
#Call ppnlp.transformers.BertTokenizer for data processing. tokenizer can convert the original input text into the input data format acceptable to the model.
tokenizer = ppnlp.transformers.BertTokenizer.from_pretrained("bert-base-cased")
#Data preprocessing
def convert_example(example,tokenizer,label_list,max_seq_length=256,is_test=False):
if is_test:
text = example
else:
text, label = example
#The tokenizer.encode method can segment tokens, map token ID S, and splice special tokens
encoded_inputs = tokenizer.encode(text=text, max_seq_len=max_seq_length)
input_ids = encoded_inputs["input_ids"]
#Note that in the earlier PaddleNLP version, token_type_ids is called segment_ids
segment_ids = encoded_inputs["token_type_ids"]
if not is_test:
label_map = {}
for (i, l) in enumerate(label_list):
label_map[l] = i
label = label_map[label]
label = np.array([label], dtype="int64")
return input_ids, segment_ids, label
else:
return input_ids, segment_ids
#Construction method of data iterator
def create_dataloader(dataset, trans_fn=None, mode='train', batch_size=1, use_gpu=False, pad_token_id=0, batchify_fn=None):
if trans_fn:
dataset = dataset.apply(trans_fn, lazy=True)
if mode == 'train' and use_gpu:
sampler = paddle.io.DistributedBatchSampler(dataset=dataset, batch_size=batch_size, shuffle=True)
else:
shuffle = True if mode == 'train' else False #If it is not a training set, the order is not disrupted
sampler = paddle.io.BatchSampler(dataset=dataset, batch_size=batch_size, shuffle=shuffle) #Generate a sampler
dataloader = paddle.io.DataLoader(dataset, batch_sampler=sampler, return_list=True, collate_fn=batchify_fn)
return dataloader
#Use partial() to fix the convert_ Tokenizer and label of example function_ list, max_ seq_ length, is_ Test isoparametric value
trans_fn = partial(convert_example, tokenizer=tokenizer, label_list=label_list, max_seq_length=128, is_test=False)
batchify_fn = lambda samples, fn=Tuple(Pad(axis=0,pad_val=tokenizer.pad_token_id), Pad(axis=0, pad_val=tokenizer.pad_token_id), Stack(dtype="int64")):[data for data in fn(samples)]
#Training set iterator
train_loader = create_dataloader(train_ds, mode='train', batch_size=64, batchify_fn=batchify_fn, trans_fn=trans_fn)
#Validation set iterator
dev_loader = create_dataloader(dev_ds, mode='dev', batch_size=64, batchify_fn=batchify_fn, trans_fn=trans_fn)
#Test set iterator
test_loader = create_dataloader(test_ds, mode='test', batch_size=64, batchify_fn=batchify_fn, trans_fn=trans_fn)
Three, model training
3.1 loading BERT pre training model
#The fine tune network Bert forsequenceclassification, which loads the pre training model Bert for text classification tasks, is followed by a full connection layer after the Bert model for classification.
#Since the identification of malicious web pages in this task is a binary classification problem, set num_classes is 2
model = ppnlp.transformers.BertForSequenceClassification.from_pretrained("bert-base-cased", num_classes=2)
3.2 start training
#Set training parameters
#Learning rate
learning_rate = 5e-5
#Training rounds
epochs = 10
#Learning rate preheating rate
warmup_proption = 0.1
#Weight attenuation coefficient
weight_decay = 0.01
num_training_steps = len(train_loader) * epochs
num_warmup_steps = int(warmup_proption * num_training_steps)
def get_lr_factor(current_step):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
else:
return max(0.0,
float(num_training_steps - current_step) /
float(max(1, num_training_steps - num_warmup_steps)))
#Learning rate scheduler
lr_scheduler = paddle.optimizer.lr.LambdaDecay(learning_rate, lr_lambda=lambda current_step: get_lr_factor(current_step))
#optimizer
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
])
#loss function
criterion = paddle.nn.loss.CrossEntropyLoss()
#Evaluation function
metric = paddle.metric.Accuracy()
#Evaluate the function and set the return value for visual DL recording
def evaluate(model, criterion, metric, data_loader):
model.eval()
metric.reset()
losses = []
for batch in data_loader:
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels)
losses.append(loss.numpy())
correct = metric.compute(logits, labels)
metric.update(correct)
accu = metric.accumulate()
print("eval loss: %.5f, accu: %.5f" % (np.mean(losses), accu))
model.train()
metric.reset()
return np.mean(losses), accu
#Start training
global_step = 0
max_acc = 0
with LogWriter(logdir="./log") as writer:
for epoch in range(1, epochs + 1):
for step, batch in enumerate(train_loader, start=1): #Fetch data from training data iterator
input_ids, segment_ids, labels = batch
logits = model(input_ids, segment_ids)
loss = criterion(logits, labels) #Calculate loss
probs = F.softmax(logits, axis=1)
correct = metric.compute(probs, labels)
metric.update(correct)
acc = metric.accumulate()
global_step += 1
if global_step % 100 == 0 :
print("global step %d, epoch: %d, batch: %d, loss: %.5f, acc: %.5f" % (global_step, epoch, step, loss, acc))
#Record the training process
writer.add_scalar(tag="train/loss", step=global_step, value=loss)
writer.add_scalar(tag="train/acc", step=global_step, value=acc)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_gradients()
eval_loss, eval_acc = evaluate(model, criterion, metric, dev_loader)
#Document the evaluation process
writer.add_scalar(tag="eval/loss", step=epoch, value=eval_loss)
writer.add_scalar(tag="eval/acc", step=epoch, value=eval_acc)
# Save best model
if eval_loss>max_acc:
max_acc = eval_loss
print('saving the best_model...')
paddle.save(model.state_dict(), 'best_model')
# Save final model
paddle.save(model.state_dict(),'final_model')
3.3 save model and network structure
# Convert to static graph with specific input description
model = paddle.jit.to_static(
model,
input_spec=[
paddle.static.InputSpec(
shape=[None, None], dtype="int64"), # input_ids
paddle.static.InputSpec(
shape=[None, None], dtype="int64") # segment_ids
])
# Save in static graph model.
paddle.jit.save(model, './static_graph_params')
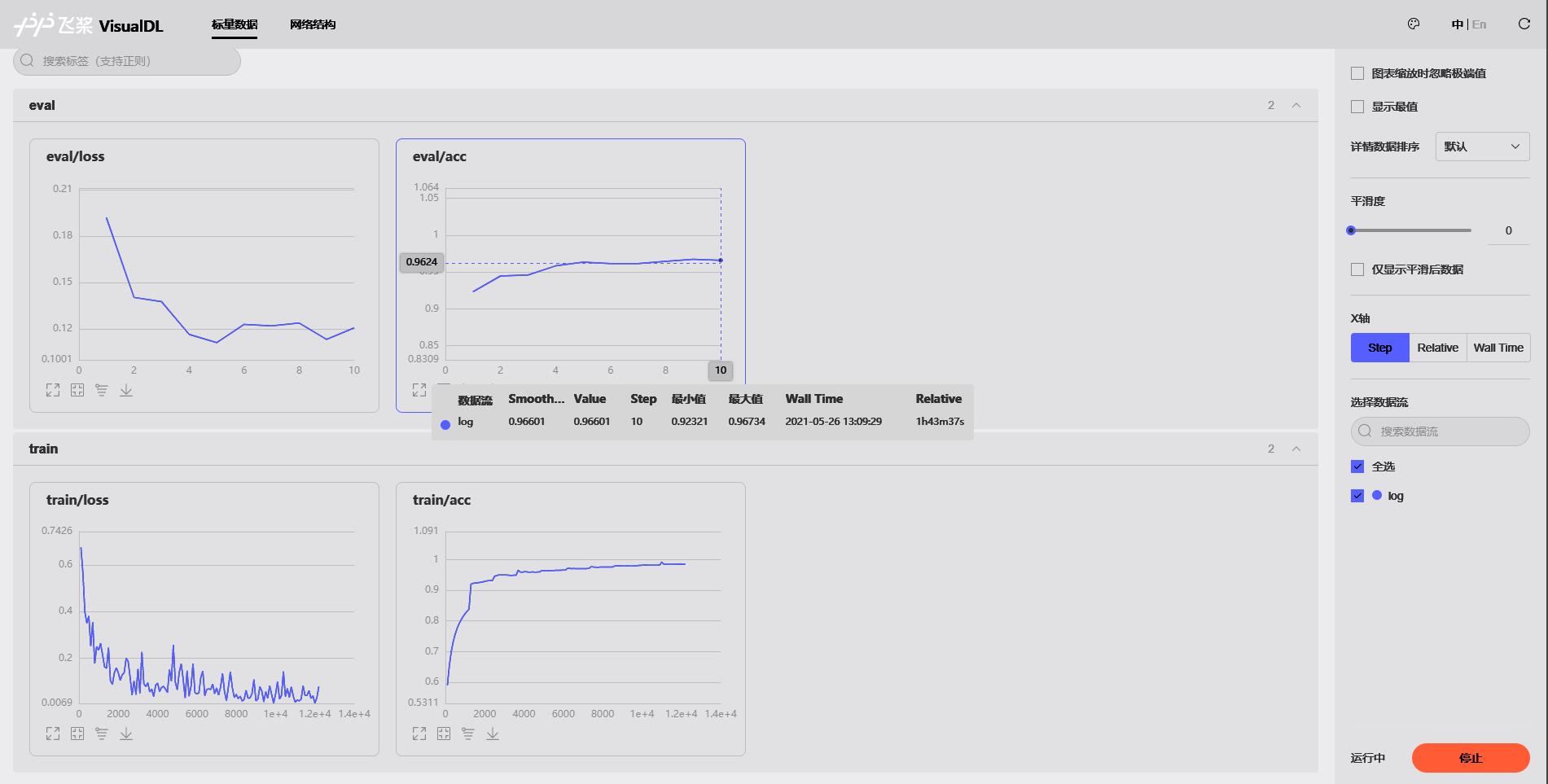
It can be seen that using the BERT pre training model for finetune, the accuracy of the validation set in 10 epoch s can reach more than 96.7%.
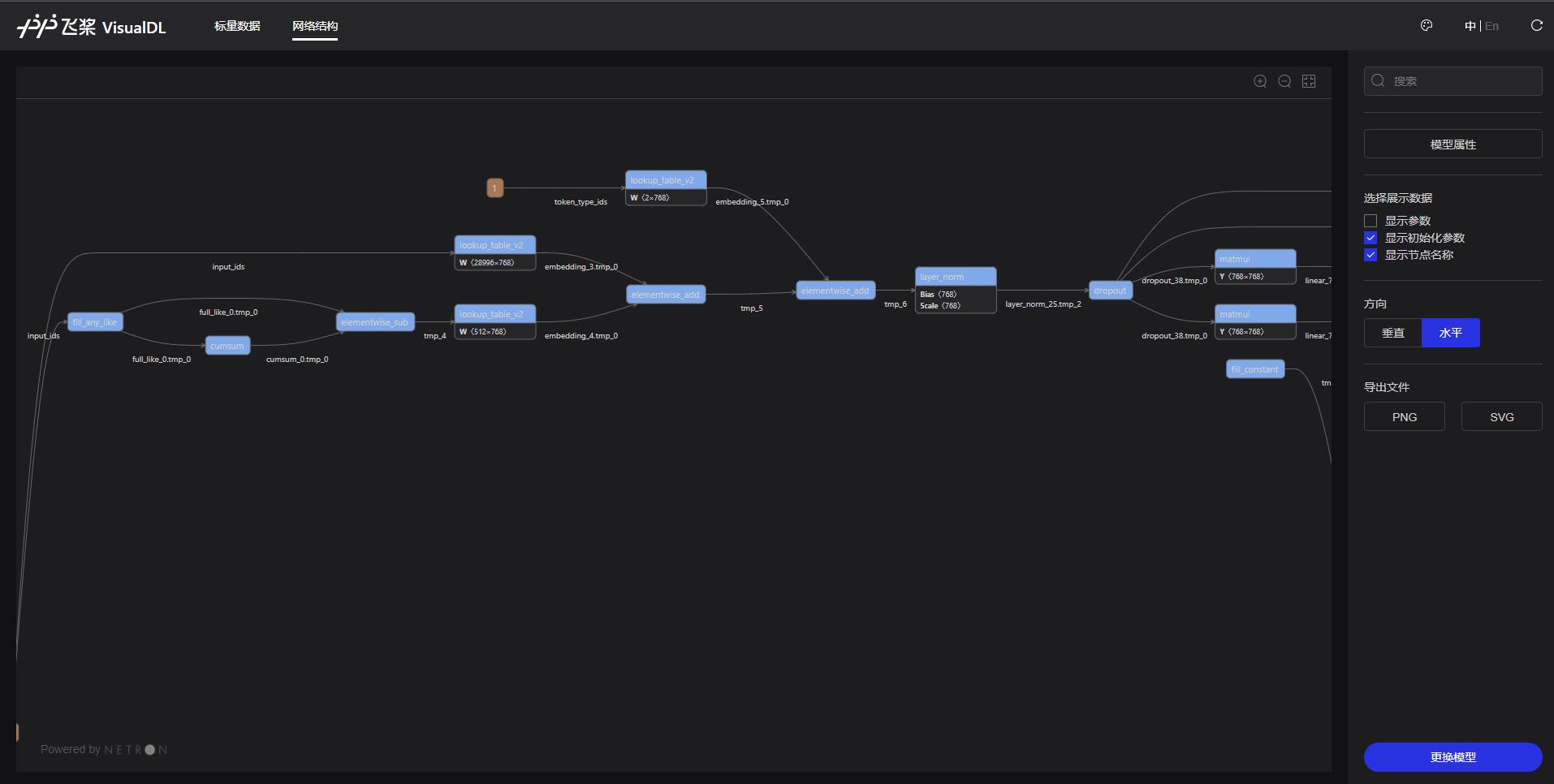
In VisualDL, you can also view the network structure of BERT model as follows:
4, Prediction effect
After completing the above model training, you can get a model that can identify whether there are malicious web pages through HTML tag sequences. Next, check the performance of the model on the test set, which is very close to 97%.
# Evaluate the performance of the model on the test set evaluate(model, criterion, metric, test_loader)
eval loss: 0.10088, accu: 0.96998 (0.10087659, 0.9699795081967213)
def predict(model, data, tokenizer, label_map, batch_size=1):
examples = []
for text in data:
input_ids, segment_ids = convert_example(text, tokenizer, label_list=label_map.values(), max_seq_length=128, is_test=True)
examples.append((input_ids, segment_ids))
batchify_fn = lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id), Pad(axis=0, pad_val=tokenizer.pad_token_id)): fn(samples)
batches = []
one_batch = []
for example in examples:
one_batch.append(example)
if len(one_batch) == batch_size:
batches.append(one_batch)
one_batch = []
if one_batch:
batches.append(one_batch)
results = []
model.eval()
for batch in batches:
input_ids, segment_ids = batchify_fn(batch)
input_ids = paddle.to_tensor(input_ids)
segment_ids = paddle.to_tensor(segment_ids)
logits = model(input_ids, segment_ids)
probs = F.softmax(logits, axis=1)
idx = paddle.argmax(probs, axis=1).numpy()
idx = idx.tolist()
labels = [label_map[i] for i in idx]
results.extend(labels)
return results
import requests
# Get a link to the home page of a well-known website
r = requests.get("https://www.csdn.net")
demo = r.text
soup=BeautifulSoup(demo,"html.parser")
tags = []
for tag in soup.find_all(True):
tags.append(tag.name)
data = []
data.append(','.join(tags))
label_map = {0: 'Malicious web page', 1: 'Normal web page'}
predictions = predict(model, data, tokenizer, label_map, batch_size=64)
for idx, text in enumerate(data):
ttps://www.csdn.net")
demo = r.text
soup=BeautifulSoup(demo,"html.parser")
tags = []
for tag in soup.find_all(True):
tags.append(tag.name)
data = []
data.append(','.join(tags))
label_map = {0: 'Malicious web page', 1: 'Normal web page'}
predictions = predict(model, data, tokenizer, label_map, batch_size=64)
for idx, text in enumerate(data):
print('Forecast web page: {} \n Web tag: {}'.format("https://www.csdn.net", predictions[idx]))
Forecast web page: https://www.csdn.net Web tag: Normal web page
Summary
- In this project, the extraction process of HTML tag sequence is further improved, and the writing mode of log file is also optimized. The training process will be continuously displayed in ViusalDL.
- After using the BERT pre training model Finetune, the prediction accuracy of the two classification models has been close to 97%.
- At the end of the project, the prototype of web page recognition Engineering (obtaining web page links - extracting tag sequences - judging web page types) has emerged, which will be further explored next.