
Tutorial address: http://www.showmeai.tech/tutorials/84
Article address: http://www.showmeai.tech/article-detail/170
Notice: All Rights Reserved. Please contact the platform and the author for reprint and indicate the source
1. Introduction
This tutorial ShowMeAI will explain in detail the method of Hadoop using map reduce for data statistics. For the basic knowledge of Hadoop and map reduce, you can review the basic knowledge of ShowMeAI Detailed explanation of distributed platform Hadoop and map reduce.
Although most people use Hadoop in java, Hadoop programs can be completed in python, C + +, ruby, etc. This example teaches you to use python to complete the MapReduce instance to count the word frequency of the words in the input file.
- Importing: text files
- Output: word and word frequency information, separated by \ t
2. MapReduce code implemented in Python
To complete MapReduce using python, you need to use the API of Hadoop stream to transfer data between Map function and Reduce function through stdin (standard input) and stdout (standard output).
We will use Python's sys Stdin reads the input data and sends our output to sys stdout. Hadoop flow will do other work.
An abstract Hadoop big data processing flow is shown in the figure below:
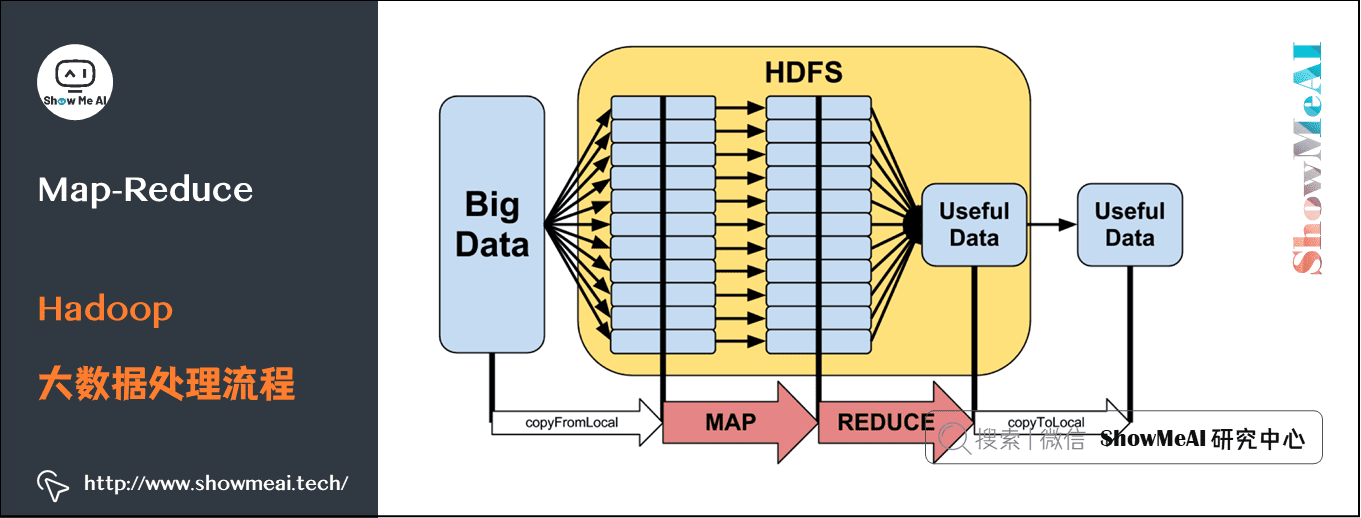
For the tasks mentioned in this article, we will do a more detailed disassembly. The whole Hadoop map reduce process is shown in the figure below:
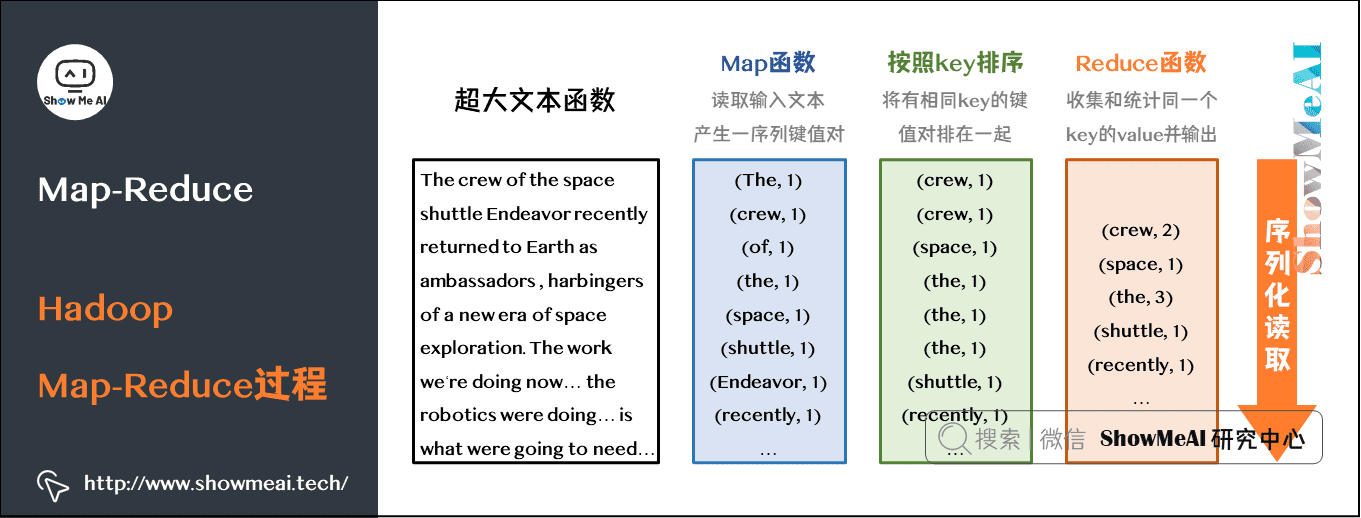
From the above figure, we can see that the steps we need to complete through core code in our current task are:
- Map: generate word and number tag key value pairs
- Reduce: aggregate the values of the same word (key) to complete statistics
Let's take a look at how to complete the Map and Reduce phases here through python.
2.1 Map stage: mapper py
Here, we assume that the python script storage address used in the map phase is showmeai / Hadoop / code / mapper py
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print "%s\t%s" % (word, 1)Explain the above code:
- File reads the file from STDIN.
- Cut the word and output the word and word frequency STDOUT.
- The Map script does not calculate the total number of words, but directly outputs 1 (the statistics will be completed in the Reduce phase).
To make the script executable, add mapper Executable permissions of Py:
chmod +x ShowMeAI/hadoop/code/mapper.py
2.2 Reduce phase: reducer py
Here, we assume that the python script storage address used in the reduce phase is showmeai / Hadoop / code / reducer py :
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError: #If count is not a number, ignore it directly
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word: #Don't forget the final output
print "%s\t%s" % (current_word, current_count)The file reads mapper Py results as reducer Py, count the total number of occurrences of each word, and output the final result to STDOUT.
To make the script executable, add reducer Executable permissions of PY
chmod +x ShowMeAI/hadoop/code/reducer.py
3. Local test MapReduce process
Usually, we will do a simple test locally before submitting the data processing flow to the cluster for operation. We will connect the data flow in series with the help of linux pipeline command (cat data | map | sort | reduce) to verify the mapper we write Py and reducer Check whether the PY script function is normal. This test method can ensure that the final output result is what we expect.
The test commands are as follows:
cd ShowMeAI/hadoop/code/ echo "foo foo quux labs foo bar quux" | python mapper.py echo ``"foo foo quux labs foo bar quux"` `| python mapper.py | sort -k1, 1 | python reducer.py
The sort process mainly completes the sorting based on the key, which is convenient for aggregation statistics in the reduce stage.
4. Running python code in Hadoop cluster
4.1 data preparation
We make word frequency statistics for the following three files. First, download them according to the following path:
- Plain Text UTF-8 http://www.gutenberg.org/ebooks/4300.txt.utf-8
- Plain Text UTF-8 http://www.gutenberg.org/ebooks/5000.txt.utf-8
- Plain Text UTF-8 http://www.gutenberg.org/ebooks/20417.txt.utf-8
Place the file in the showmeai / Hadoop / data / directory.
4.2 execution procedure
Copy the local data files to the distributed file system HDFS.
bin/hadoop dfs -copyFromLocal ShowMeAI/hadoop/datas hdfs_in
see:
bin/hadoop dfs -ls
View specific files:
bin/hadoop dfs -ls /user/showmeai/hdfs_in
Execute MapReduce job:
bin/hadoop jar contrib/streaming/hadoop-*streaming*.jar \ -file ShowMeAI/hadoop/code/mapper.py -mapper ShowMeAI/hadoop/code/mapper.py \ -file ShowMeAI/hadoop/code/reducer.py -reducer ShowMeAI/hadoop/code/reducer.py \ -input /user/showmeai/hdfs_in/* -output /user/showmeai/hdfs_out
Instance output:
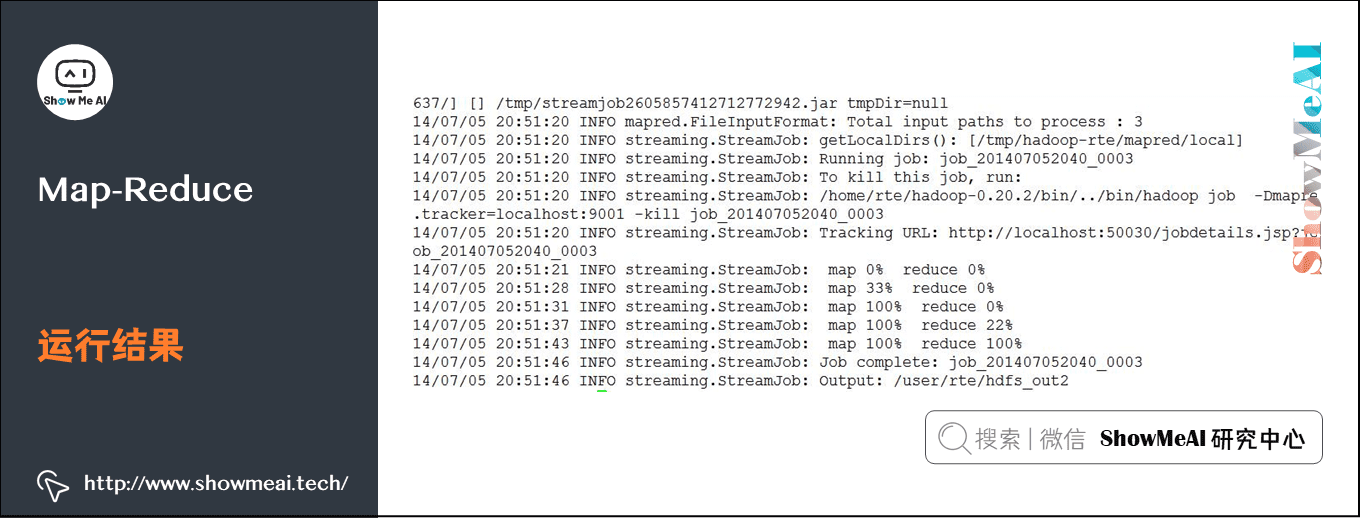
Check whether the output result is in the target directory / user/showmeai/hdfs_out:
bin/hadoop dfs -ls /user/showmeai/hdfs_out
View results:
bin/hadoop dfs -cat /user/showmeai/hdfs_out2/part-00000
Output:

5.Mapper and Reducer code optimization
5.1 iterators and generators in Python
The code optimization of map reduce here is mainly based on iterators and generators. Students unfamiliar with this part can refer to the python part of ShowMeAI → Graphical python iterators and generators .
5.2 optimizing Mapper and Reducer code
mapper.py
#!/usr/bin/env python
import sys
def read_input(file):
for line in file:
yield line.split()
def main(separator='\t'):
data = read_input(sys.stdin)
for words in data:
for word in words:
print "%s%s%d" % (word, separator, 1)
if __name__ == "__main__":
main()
reducer.py
#!/usr/bin/env python
from operator import itemgetter
from itertools import groupby
import sys
def read_mapper_output(file, separator = '\t'):
for line in file:
yield line.rstrip().split(separator, 1)
def main(separator = '\t'):
data = read_mapper_output(sys.stdin, separator = separator)
for current_word, group in groupby(data, itemgetter(0)):
try:
total_count = sum(int(count) for current_word, count in group)
print "%s%s%d" % (current_word, separator, total_count)
except valueError:
pass
if __name__ == "__main__":
main()Let's give a simple demonstration of the functions of groupby in the code, as follows:
from itertools import groupby
from operator import itemgetter
things = [('2009-09-02', 11),
('2009-09-02', 3),
('2009-09-03', 10),
('2009-09-03', 4),
('2009-09-03', 22),
('2009-09-06', 33)]
sss = groupby(things, itemgetter(0))
for key, items in sss:
print key
for subitem in items:
print subitem
print '-' * 20result:
2009-09-02
('2009-09-02', 11)
('2009-09-02', 3)
--------------------
2009-09-03
('2009-09-03', 10)
('2009-09-03', 4)
('2009-09-03', 22)
--------------------
2009-09-06
('2009-09-06', 33)
--------------------In the code:
- Group by (things, itemsetter (0)) takes column 0 as the sorting target
- Group by (things, itemsetter (1)) takes column 1 as the sorting target
- Group by (things) sorts the targets in the whole row
6. References
- Parameter problem in split function in python http://segmentfault.com/q/1010000000311861
- Writing an Hadoop MapReduce Program in Python http://www.michael-noll.com/tutorials/writing-an-hadoop-mapreduce-program-in-python/
- The - k parameter of the shell's sort command http://blog.chinaunix.net/uid-25513153-id-200481.html