🐱 Medical text generation based on CNN-RNN
This project uses resnet101 network pre trained by IMAGENET to extract image features,
The image features are input into LSTM to generate a text description of the image.
The simple generation from image to text is preliminarily realized.
📖 0 project background
With the rapid development of deep learning in recent years, deep learning shows great development potential in the medical industry. Therefore, if we can use computers to write mechanical image reports instead of doctors through in-depth learning, we can not only avoid the misdiagnosis of inexperienced doctors in film reading diagnosis, but also make more senior doctors free from heavy repetitive work and devote more time to the diagnosis and treatment of patients.
Automatic generation of medical image report is one of the emerging cross directions of computer and medical image in recent years. At present, the automatic generation model of image report mainly draws lessons from the encoder decoder framework in the field of machine translation
Neural network (CNN) extracts the image features, and then uses recurrent neural network (RNN) to generate the text description of the image
📌 1 data set
The Indiana University chest X-ray collection (IU X-ray) is a set of chest X-ray images and their corresponding diagnostic reports. The dataset contains 7470 pairs of images and reports (6470:500:500). Each report consists of the following parts: impression, discovery, labeling, comparison and indication. On average, each image is associated with 2.2 tags and 5.7 sentences, and each sentence contains 6.5 words.
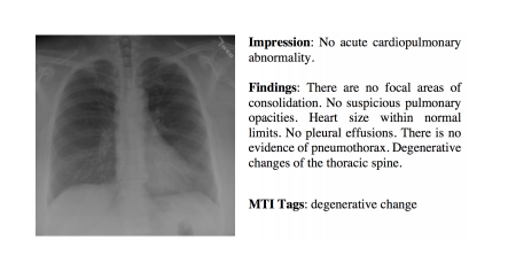
This project only uses the finding part as the image generation label
Reference code:
- https://github.com/chenyuntc/pytorch-book/tree/master/chapter10-image_caption
🐰 2 data set generation
🐅 2.1 medical text CSV generation
Decompress the original data, parse the data in xml format, extract the image file name and corresponding FINDINGS, and generate CSV file.
# Decompress data set !unzip -o data/data123482/IU data set.zip -d /home/aistudio/work/
# Cancel output of warning
import warnings
warnings.filterwarnings("ignore")
## Making CSV datasets
# The average number of characters is 31.64992700729927
import os
import glob
import pandas as pd
from xml.dom import minidom
import re
import numpy as np
LENGTH = []
def EmptyDrop(data):
for i in range(len(data)):
if data.loc[i,'dir'] ==[] or data.loc[i,'caption'] ==[]:
#If it is blank, delete the row
data.drop([i],axis = 0,inplace = True)
else:
data.loc[i,'dir'] = data.loc[i,'dir'][0]
data.loc[i,'caption'] = data.loc[i,'caption'][0]
data.reset_index(drop = True,inplace = True)
return data
def clean_text(origin_text):
# Remove punctuation and illegal characters
text = re.sub("^a-zA-Z"," ",origin_text)
#Change uppercase to lowercase
cleaned_text = text.lower()
return cleaned_text
def xml2csv(path):
num = 0
column_name = ['dir','caption']
xml_csv = pd.DataFrame(columns = column_name)
#Picture saving address
pic_path = 'work/IU data set/NLMCXR_png'
for xml_file in glob.glob(path+'/*.xml'):
#Record all the information fx addresses that need to be saved for each xml
xml_list = []
#Open xml document
dom = minidom.parse(xml_file)
#Get document element object
root = dom.documentElement
# f1 address
itemlists=root.getElementsByTagName('parentImage')
#Record address
dirAll = []
for itemlist in itemlists:
figureId=itemlist.getElementsByTagName('figureId')
#Find the figureID of the picture
figure = figureId[0].childNodes[0].nodeValue
#Find the name of the picture
ID= itemlist.getAttribute('id')
IdPath = ID
#Front & side view
figurePath = [figure+' '+IdPath]
dirAll.extend(figurePath)
xml_list.append(dirAll)
#Records FINDINGS and IMPRESSION
#Record content
CaptionAll = []
itemlists=root.getElementsByTagName('AbstractText')
for i in range(len(itemlists)):
Label= itemlists[i].getAttribute('Label')
if Label == 'FINDINGS': # or Label == 'IMPRESSION':
# Content cannot be empty
if len(itemlists[i].childNodes)!=0:
text = itemlists[i].childNodes[0].nodeValue
#Convert to lowercase, filter invalid characters
text = clean_text(text)
text = text.replace('.','')
text = text.replace(',','')
text = [text+'']
CaptionAll.extend(text)
if len(CaptionAll)>=1:
LENGTH.append(len(CaptionAll[0].split(' ')))
xml_list.append(CaptionAll)
xml_csv.loc[num] = [item for item in xml_list]
num = num + 1
print('epoch[{}/{}]'.format(num,len(glob.glob(path+'/*.xml'))))
# print(np.mean(LENGTH))
return xml_csv
def main():
xml_path = os.path.join('work','IU data set','NLMCXR_reports','ecgen-radiology')
csv = xml2csv(xml_path)
csv1 = EmptyDrop(csv)
csv1.to_csv('work/IUxRay.csv',index=None)
if __name__ == '__main__':
main()
🐅 2.2 image feature extraction
-
The resnet101 model pre trained by ImageNet is used to extract image features (delete the last full connection layer and change it to identity mapping).
-
Save data as h5 file
## resnet101 pre training model is used to extract image features
import paddle
from paddle.vision.models import resnet101
import h5py
import cv2
csv_file = pd.read_csv('work/IUxRay.csv')
h5_png_file =list(csv_file['dir'])
# Create save directory
save_path = 'work/util_IUxRay'
if not os.path.exists(save_path):
os.makedirs(save_path)
# Import model resnet101 using Google pre training
model = resnet101(pretrained=True)
# Delete the last full connection layer
del model.fc
model.fc = lambda x:x
h5f = h5py.File(os.path.join(save_path,'resnet101_festures.h5'), 'w')
for idx,item in enumerate(h5_png_file):
# Read all PNG S (F1,F2...)
print(idx,len(h5_png_file))
item_all = item.split(',')
for item_t in item_all:
item_t = item_t.replace('\'','').replace('[','').replace(']','')
# Distinguish the diagrams with different orientations
for orie in ['F1','F2','F3','F4']:
if orie in item_t:
orie_fin = orie
item_fin = item_t.replace(orie,'').replace(' ','')
item_fin_png = item_fin + '.png'
print(orie_fin + '_' + item_fin)
# Read the file, send it to the model, extract the features and save it as h5
img = cv2.imread(os.path.join('work/IU data set/NLMCXR_png',item_fin_png))
# BGR to RGB and HWC to CHW
img = img[:,:,::-1].transpose((2,0,1))
# Extended dimension
img = np.expand_dims(img, 0)
img_tensor = paddle.to_tensor(img,dtype='float32' ,place=paddle.CUDAPinnedPlace())
# Feature extraction
out = model(img_tensor)
data = out.numpy().astype('float32')
# The saved data is h5
save_path_h5 = data[0]
h5f.create_dataset(orie_fin + '_' + item_fin, data=save_path_h5)
h5f.close()
# Read h5 file
import h5py
h5f = h5py.File('work/util_IUxRay/resnet101_festures.h5','r')
data = h5f['F1_CXR3027_IM-1402-1001'] # The first underline is the orientation of the image before it, and then the original name of the image
print(np.array(data).shape) # Each picture is saved as a vector of 2048 dimensions
h5f.close()
🐅 2.3 dictionary generation
-
Statistics training data, according to word segmentation, create dictionary.
-
Dictionary correction: delete words that appear only once in the dataset
# Statistics training data, create dictionary with word granularity
import pandas as pd
import numpy as np
import re
csv_file = pd.read_csv('work/IUxRay.csv')
csv_file.head()
CaptionWordAll = []
CaptionWordLength = []
for idx,data_ in enumerate(csv_file.iterrows()):
caption = data_[1][1]
CaptionWordLength.append(len(caption.split(' ')))
CaptionWordAll.extend(caption.split(' '))
print('The average sentence length is:',np.mean(CaptionWordLength))
print('The maximum sentence length is:',np.max(CaptionWordLength))
print('The minimum sentence length is:',np.min(CaptionWordLength))
print('The total number of words is:',len(CaptionWordAll))
print('Dictionary length:',len(set(CaptionWordAll)))
# 100
from collections import Counter
# The statistics frequency is sorted from high to bottom. The dictionary constructed in this way uses the most frequently used symbols in the front, which is fast to find
counts = Counter(CaptionWordAll)
count_sorted = counts.most_common()
count_sorted_ = {k: v for k, v in count_sorted if v > 1}
# Construct dictionary
# Add < pad > 0 < unk > 1 < start > 2 < end > 3 as common symbols
word2id_dict={'<pad>':0,'<unk>':1,'<start>':2,'<end>':3}
id2word_dict={0:'<pad>',1:'<unk>',2:'<start>',3:'<end>'}
for idx,item in enumerate(count_sorted_):
idx_ = idx+4 # Four are reserved as records
item_ = item
word2id_dict[item_] = idx_
id2word_dict[idx_] = item_
# Delete words that appear only once
print('The corrected dictionary length is:',len(word2id_dict))
Average sentence length: 31.45519928079113 Maximum sentence length: 173 Minimum sentence length: 7 Total words: 104966 Dictionary length: 1754 The corrected dictionary length is 1151
🥝 3. Define data reading class
-
The data are divided into training set and verification set according to 8:2.
-
The text data is mapped through the dictionary. Unlike the translation task, this task uses image features instead of (85 lines).
## Complete dataload
import paddle
from paddle.io import Dataset
import numpy as np
from sklearn.model_selection import train_test_split
# Rewrite data reading class
class CaptionDataset(Dataset):
# Constructor, defining function parameters
def __init__(self,csvData,word2id_dict,h5f,maxlength = 40,mode = 'train'):
self.mode = mode
self.w2i_dict = word2id_dict
self.maxlength = maxlength # Maximum number of characters entered
self.padid = 0 # 0 is the fill symbol
self.h5f = h5f
# Process the data in proportion according to train/test
train,test =csvData.iloc[:int(0.8*len(csvData)),:],csvData.iloc[int(0.8*len(csvData)):,:] #train_test_split(csvData,train_size=0.8,random_state=10)
if self.mode == 'train':
train.reset_index(drop=True)
self.data = train
else:
test.reset_index(drop=True)
self.data = test
# Realize__ getitem__ Method to define how to obtain data when specifying index and return a single piece of data (training data, corresponding label)
def __getitem__(self, index):
path_name, trg_ = self.data.iloc[index,:]
# Read image features
temp = path_name.split(' ')
names = '_'.join(temp)
img_feature = np.array(self.h5f[names]) # The first underline is the orientation of the image before it, and then the original name of the image
# Convert input to idx
trg,trg_length = self.generIdxList(trg_) # data
img_name = temp[-1]
return img_feature,trg,trg_length,img_name
# Realize__ len__ Method to return the total number of data sets
def __len__(self):
return len(self.data)
def generIdxList(self,tdata):
# Generate a List of idx from the input String
data = tdata.split(' ')
data_out = []
# To limit the length, enter '< start >' and '< end >'
data = ['<start>'] + data
if len(data)>self.maxlength-1:
data = data[:self.maxlength-1] # Leave a place for '< end >
data = data + ['<end>']
else:
# placeholder
occupy_ = ['<pad>'] * (self.maxlength - 1 - len(data))
data = data + ['<end>']
data = data + occupy_
# word 2 index
for word in data:
if self.w2i_dict.get(word)!= None: # Can you find word
id_ = self.w2i_dict[word]
data_out.append(id_)
else:
id_ = self.w2i_dict['<unk>']
data_out.append(id_)
length = len(data_out)-1
return data_out,length
def stackInput(inputs):
img_features = np.stack([inputsub[0] for inputsub in inputs], axis=0)
trg = np.stack([inputsub[1] for inputsub in inputs], axis=0)
trg_length = np.stack([inputsub[2] for inputsub in inputs], axis=0)
trg_mask =(trg[:,:-1]!=0).astype(paddle.get_default_dtype())
trg_ = trg[:,1:] # Change the tag to start times
return img_features,trg_length,trg_[:,:-1],trg[:,1:,np.newaxis],trg_mask
# Test data reading
import pandas as pd
import numpy as np
import h5py
from sklearn.model_selection import train_test_split
csvData = pd.read_csv('work/IUxRay.csv')
h5f = h5py.File('work/util_IUxRay/resnet101_festures.h5','r')
maxlength = 40
dataset=CaptionDataset(csvData,word2id_dict,h5f,maxlength,'train')
data_loader = paddle.io.DataLoader(dataset, batch_size=1,collate_fn = stackInput, shuffle=False)
for item in data_loader:
print(item[0].shape,item[1].shape,item[2].shape,item[3].shape,item[4].shape)
break
[1, 2048] [1] [1, 38] [1, 39, 1] [1, 39]
💡 4 definition model
-
Define LSTM model for text generation
-
Define beam search algorithm to optimize the generated results
# Define model
import paddle.nn as nn
import paddle
class CaptionModel(paddle.nn.Layer):
def __init__(self, vocab_size,embedding_dim,hidden_size,num_layers,word2id_dict,id2word_dict):
super(CaptionModel,self).__init__()
self.hidden_size=hidden_size
self.num_layers=num_layers
self.fc = paddle.nn.Linear(2048,embedding_dim)
self.embedding=paddle.nn.Embedding(vocab_size,embedding_dim)
self.rnn=paddle.nn.LSTM(input_size=embedding_dim,
hidden_size=hidden_size,
num_layers=num_layers)
self.word2ix = word2id_dict
self.ix2word = id2word_dict
self.classifier = paddle.nn.Linear(hidden_size,vocab_size)
def forward(self,img_features,trg,trg_length):
img_features = paddle.unsqueeze(self.fc(img_features),axis = 1)
embeddings = self.embedding(trg)
inputs = paddle.concat([img_features,embeddings],axis = 1)
outputs,state = self.rnn(inputs,sequence_length = trg_length)
predict = self.classifier(outputs)
return predict
def generate(self, img_feat, eos_token='<end>',
beam_size=2,
max_caption_length=40,
length_normalization_factor=0.0):
"""
Generate description from picture,Mainly use beam search Algorithm for better description
"""
cap_gen = CaptionGenerator(embedder=self.embedding,
rnn=self.rnn,
classifier=self.classifier,
eos_id=self.word2ix[eos_token],
beam_size=beam_size,
max_caption_length=max_caption_length,
length_normalization_factor=length_normalization_factor)
img_feat = paddle.unsqueeze(img_feat,axis = 0)
img = paddle.unsqueeze(self.fc(img_feat),axis = 0)
sentences, score = cap_gen.beam_search(img)
sentences = [' '.join([self.ix2word[int(idx)] for idx in sent])
for sent in sentences]
return sentences
# Beam Search
import paddle.nn as nn
import heapq
class TopN(object):
"""Maintains the top n elements of an incrementally provided set."""
def __init__(self, n):
self._n = n
self._data = []
def size(self):
assert self._data is not None
return len(self._data)
def push(self, x):
"""Pushes a new element."""
assert self._data is not None
if len(self._data) < self._n:
heapq.heappush(self._data, x)
else:
heapq.heappushpop(self._data, x)
def extract(self, sort=False):
"""
Extracts all elements from the TopN. This is a destructive operation.
The only method that can be called immediately after extract() is reset().
Args:
sort: Whether to return the elements in descending sorted order.
Returns:
A list of data; the top n elements provided to the set.
"""
assert self._data is not None
data = self._data
self._data = None
if sort:
data.sort(reverse=True)
return data
def reset(self):
"""Returns the TopN to an empty state."""
self._data = []
class Caption(object):
"""Represents a complete or partial caption."""
def __init__(self, sentence, state, logprob, score, metadata=None):
"""Initializes the Caption.
Args:
sentence: List of word ids in the caption.
state: Model state after generating the previous word.
logprob: Log-probability of the caption.
score: Score of the caption.
metadata: Optional metadata associated with the partial sentence. If not
None, a list of strings with the same length as 'sentence'.
"""
self.sentence = sentence
self.state = state
self.logprob = logprob
self.score = score
self.metadata = metadata
def __cmp__(self, other):
"""Compares Captions by score."""
assert isinstance(other, Caption)
if self.score == other.score:
return 0
elif self.score < other.score:
return -1
else:
return 1
# For Python 3 compatibility (__cmp__ is deprecated).
def __lt__(self, other):
assert isinstance(other, Caption)
return self.score < other.score
# Also for Python 3 compatibility.
def __eq__(self, other):
assert isinstance(other, Caption)
return self.score == other.score
class CaptionGenerator(object):
"""Class to generate captions from an image-to-text model."""
def __init__(self,
embedder,
rnn,
classifier,
eos_id,
beam_size=3,
max_caption_length=100,
length_normalization_factor=0.0):
"""Initializes the generator.
Args:
model: recurrent model, with inputs: (input, state) and outputs len(vocab) values
beam_size: Beam size to use when generating captions.
max_caption_length: The maximum caption length before stopping the search.
length_normalization_factor: If != 0, a number x such that captions are
scored by logprob/length^x, rather than logprob. This changes the
relative scores of captions depending on their lengths. For example, if
x > 0 then longer captions will be favored.
"""
self.embedder = embedder
self.rnn = rnn
self.classifier = classifier
self.eos_id = eos_id
self.beam_size = beam_size
self.max_caption_length = max_caption_length
self.length_normalization_factor = length_normalization_factor
def beam_search(self, rnn_input, initial_state=None):
"""Runs beam search caption generation on a single image.
Args:
initial_state: An initial state for the recurrent model
Returns:
A list of Caption sorted by descending score.
"""
def get_topk_words(embeddings, state):
output, new_states = self.rnn(embeddings, state)
output = self.classifier(paddle.squeeze(output,axis=0))
logprobs = nn.functional.log_softmax(output, axis=-1)
if len(logprobs.shape) == 3:
logprobs = paddle.squeeze(logprobs)
logprobs, words = logprobs.topk(self.beam_size, 1)
return words, logprobs, new_states
partial_captions = TopN(self.beam_size)
complete_captions = TopN(self.beam_size)
words, logprobs, new_state = get_topk_words(rnn_input, initial_state)
for k in range(self.beam_size):
cap = Caption(
sentence=[words[0, k]],
state=new_state,
logprob=logprobs[0, k],
score=logprobs[0, k])
partial_captions.push(cap)
# Run beam search.
for _ in range(self.max_caption_length - 1):
partial_captions_list = partial_captions.extract()
partial_captions.reset()
input_feed =[c.sentence[-1] for c in partial_captions_list]
input_feed = paddle.to_tensor(input_feed)
state_feed = [c.state for c in partial_captions_list]
if isinstance(state_feed[0], tuple):
state_feed_h, state_feed_c = zip(*state_feed)
state_feed = (paddle.concat(state_feed_h, 1),
paddle.concat(state_feed_c, 1))
else:
state_feed = paddle.concat(state_feed, 1)
embeddings = self.embedder(input_feed)
words, logprobs, new_states = get_topk_words(
embeddings, state_feed)
for i, partial_caption in enumerate(partial_captions_list):
if isinstance(new_states, tuple):
state = (paddle.slice(new_states[0],axes=[1],starts=[i],ends = [i+1]),
paddle.slice(new_states[1],axes=[1],starts=[i],ends = [i+1]))
else:
state = new_states[i]
for k in range(self.beam_size):
w = words[i, k]
sentence = partial_caption.sentence + [w]
logprob = partial_caption.logprob + logprobs[i, k]
score = logprob
if w == self.eos_id:
if self.length_normalization_factor > 0:
score /= len(sentence)**self.length_normalization_factor
beam = Caption(sentence, state, logprob, score)
complete_captions.push(beam)
else:
beam = Caption(sentence, state, logprob, score)
partial_captions.push(beam)
if partial_captions.size() == 0:
# We have run out of partial candidates; happens when beam_size
# = 1.
break
# If we have no complete captions then fall back to the partial captions.
# But never output a mixture of complete and partial captions because a
# partial caption could have a higher score than all the complete
# captions.
if not complete_captions.size():
complete_captions = partial_captions
caps = complete_captions.extract(sort=True)
return [c.sentence for c in caps], [c.score for c in caps]
🥝 5 define loss function
-
Using the basic cross entropy loss function
-
Use defined trg_mask avoid missing the padding part
# Define loss function
class CrossEntropy(paddle.nn.Layer):
def __init__(self):
super(CrossEntropy,self).__init__()
def forward(self,pre,real,trg_mask):
cost=paddle.nn.functional.softmax_with_cross_entropy(logits=pre,label=real)
# Delete the dimension with 1 on axis=2 shape
cost=paddle.squeeze(cost,axis=[2])
# trg_mask shape [batch_size,suqence_len]
masked_cost=cost*trg_mask
return paddle.mean(paddle.mean(masked_cost,axis=[0]))
🦃 6 define parameters and train
-
Increase the degree of confusion as the evaluation index
-
Set training parameters
# parameter
import h5py
epochs=60
word_size = 1151
eos_id=word2id_dict['<end>']
num_layers=32
hidden_size=512
embedding_dim=512
lr=1e-3
maxlength=40
model_path='./output'
csvData = pd.read_csv('work/IUxRay.csv')
h5f = h5py.File('work/util_IUxRay/resnet101_festures.h5','r')
import paddlenlp
model=CaptionModel(word_size,embedding_dim,hidden_size,num_layers,word2id_dict,id2word_dict)
optimizer=paddle.optimizer.Adam(learning_rate=lr,parameters=model.parameters())
# Confusion degree
ppl_metric=paddlenlp.metrics.Perplexity()
train_dataset=CaptionDataset(csvData,word2id_dict,h5f,maxlength,'train')
train_loader = paddle.io.DataLoader(train_dataset, batch_size=128,collate_fn = stackInput, shuffle=True)
val_dataset=CaptionDataset(csvData,word2id_dict,h5f,maxlength,'test')
val_loader = paddle.io.DataLoader(val_dataset, batch_size=64,collate_fn = stackInput, shuffle=True)
# Set optimizer
optimizer=paddle.optimizer.Adam(learning_rate=lr,parameters=model.parameters())
# Set loss function
loss_fn = CrossEntropy()
perplexity = paddlenlp.metrics.Perplexity()
model.train()
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
img_features,trg_length,inputs,label,label_mask = data[0],data[1],data[2],data[3], data[4] # data
predicts = model(img_features,inputs,trg_length) # Prediction results
# The calculated loss is equivalent to the loss setting in prepare
loss = loss_fn(predicts, label , label_mask)
# Calculating the confusion degree is equivalent to the setting of metrics in prepare
correct = perplexity.compute(predicts, label)
perplexity.update(correct.numpy())
ppl = perplexity.accumulate()
# The following back propagation, printing training information, updating parameters and gradient clearing are encapsulated in the model In fit()
# Back propagation
loss.backward()
if (batch_id+1) % 20 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, ppl is: {}".format(epoch+1, batch_id+1, loss.item(), ppl))
# Save the model parameters with the file name Unet_model.pdparams
paddle.save(model.state_dict(), 'work/LSTM_model.pdparams')
# Update parameters
optimizer.step()
# Gradient clearing
optimizer.clear_grad()
model.eval()
for batch_id, data in enumerate(val_loader()):
img_features,trg_length,inputs,label,label_mask = data[0],data[1],data[2],data[3], data[4] # data
predicts = model(img_features,inputs,trg_length) # Prediction results
# The calculated loss is equivalent to the loss setting in prepare
loss = loss_fn(predicts , label , label_mask)
# Calculating the confusion degree is equivalent to the setting of metrics in prepare
correct = perplexity.compute(predicts, label)
perplexity.update(correct.numpy())
ppl = perplexity.accumulate()
# The following back propagation, printing training information, updating parameters and gradient clearing are encapsulated in the model In fit()
if (batch_id+1) % 1 == 0:
print(" batch_id: {}, loss is: {}, ppl is: {}".format( batch_id+1, loss.item(), ppl))
🍓 7 model reasoning
# Validation dataset
from IPython.display import display
from PIL import Image
import numpy as np
from tqdm import tqdm
path = 'work/IU data set/NLMCXR_png/'
csvData = pd.read_csv('work/IUxRay.csv')
h5f = h5py.File('work/util_IUxRay/resnet101_festures.h5','r')
data = csvData.iloc[int(0.8*len(csvData)):,:]
scores = []
Beam_Size = 3
for idx,data_ in tqdm(enumerate(data.iterrows())):
F_name = data_[1][0]
F_text = data_[1][1]
img_name = F_name.split(' ')[-1]
h5f_name = '_'.join(F_name.split(' '))
img_feature = np.array(h5f[h5f_name])
img_path = path + img_name + '.png'
img_feature = paddle.to_tensor(img_feature)
results = model.generate(img_feature,beam_size=Beam_Size)
#print('forecast results: ', results[Beam_Size-1])
#print('correct result: ', F_text)
#img = Image.open(img_path).convert('RGB')
#display(img, Image.BILINEAR)
# Calculate BLUE
from nltk.translate.bleu_score import sentence_bleu
reference = [F_text.split(' ')]
candidate = results[Beam_Size-1].split(' ')
score = sentence_bleu(reference,candidate)
scores.append(score)
print('Prediction results:',results[Beam_Size-1])
print('Correct result:',F_text)
print('BLEU:',np.mean(scores))
img = Image.open(img_path).convert('RGB')
img_path = path + img_name + '.png'
img_feature = paddle.to_tensor(img_feature)
results = model.generate(img_feature,beam_size=Beam_Size)
#print('forecast results: ', results[Beam_Size-1])
#print('correct result: ', F_text)
#img = Image.open(img_path).convert('RGB')
#display(img, Image.BILINEAR)
# Calculate BLUE
from nltk.translate.bleu_score import sentence_bleu
reference = [F_text.split(' ')]
candidate = results[Beam_Size-1].split(' ')
score = sentence_bleu(reference,candidate)
scores.append(score)
print('Prediction results:',results[Beam_Size-1])
print('Correct result:',F_text)
print('BLEU:',np.mean(scores))
img = Image.open(img_path).convert('RGB')
display(img, Image.BILINEAR)
668it [04:45, 2.34it/s] Prediction results: the heart is normal in size no within normal normal no no are are no no no no no <end> Correct result: the heart size and pulmonary vascularity appear within normal limits the lungs are free of focal airspace disease no pleural effusion or pneumothorax is seen BLEU: 0.008670173413668955
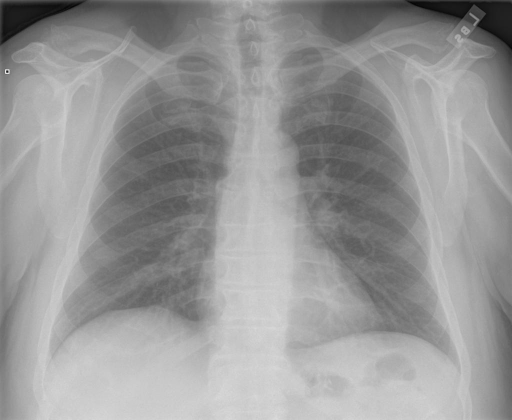
2
🎖️ 8 project summary
-
The project mainly uses CNN+RNN to demonstrate the generation of CT image report.
-
Due to a small bug in some code of BeamSearch, the maximum probability is actually used at present. It has been corrected and the Beam Size parameter can be passed in normally
-
The project is a simple implementation of ImageCaption task in the field of medical text,
-
All codes and data of this project are presented in notebook, which is easy to understand.
-
BLUE is used for effect evaluation of the project
Special note: the project is inspired by Chapter 10 of the introduction and practice of deep learning framework pytoch.
If you have any questions, please leave a message in the comment area.