catalogue
Import libraries used by the project
Set up training and validation
abstract
I have written a lot about the actual combat of models in the previous article. This is the last one of the actual combat. I didn't add visualization or decorate the code too much. I just want to let you know how the classification model is implemented in the simplest way.
Today, we use DenseNet to classify baldness. I put the data set on Baidu online disk. Address: link: https://pan.baidu.com/s/177ethB_1ZLyl8_Ef1lJxSA Extraction code: 47fo. This data set may upset the majority of programmers.



Here is an example of a dataset.

They are all bald. Their common feature is that they are all men. Why don't women be bald?
Import libraries used by the project
import torch.optim as optim import torch import torch.nn as nn import torch.nn.parallel import torch.utils.data import torch.utils.data.distributed import torchvision.transforms as transforms import torchvision.datasets as datasets from torch.autograd import Variable from torchvision.models import densenet121
Set global parameters
Set BatchSize, learning rate and epochs to judge whether there is cuda environment. If not, set it as cpu
# Set global parameters
modellr = 1e-4
BATCH_SIZE = 32
EPOCHS = 5
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')Image preprocessing
During image and processing, the transform of the train data set and the transform of the verification set are done separately. In addition to resizing and normalization, the image enhancement can also be set, such as rotation, random erasure and a series of operations. The verification set does not need image enhancement. In addition, do not enhance blindly, Unreasonable enhancement methods are likely to bring negative effects, and even Loss does not converge.
# Data preprocessing
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])Read data
The author has adjusted this data set and can directly read the data in the default way of Python. The data directory is shown in the figure below:
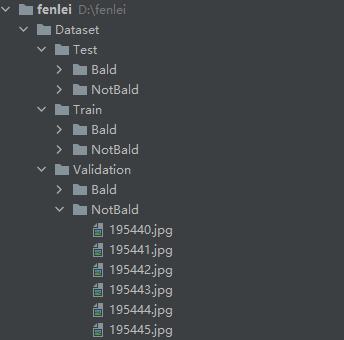
There are 16000 pictures in the training set, of which more than 3000 are bald. There are more than 20000 in the verification set, of which 470 are bald. The number difference is too large. I deleted some at random. Then, write the code to read the data.
dataset_train = datasets.ImageFolder('Dataset/Train', transform)
dataset_test = datasets.ImageFolder('Dataset/Validation',transform_test)
# Read data
print(dataset_train.imgs)
# Import data
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)Set model
The cross entropy is used as the loss, and the densenet121 is used as the model. It is recommended to use the pre training model. In the process of debugging, I can quickly get a convergent model by using the pre training model, and set the pre trained to True by using the pre training model. Change the full connection of the last layer, set the category to 2, and then put the model into DEVICE. Adam is selected as the optimizer.
# Instantiate the model and move to GPU
criterion = nn.CrossEntropyLoss()
model_ft = densenet121(pretrained=True)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, 2)
model_ft.to(DEVICE)
# Choose the simple and violent Adam optimizer and lower the learning rate
optimizer = optim.Adam(model_ft.parameters(), lr=modellr)
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
modellrnew = modellr * (0.1 ** (epoch // 50))
print("lr:", modellrnew)
for param_group in optimizer.param_groups:
param_group['lr'] = modellrnew
Set up training and validation
The outermost layer is the loop. Each epoch is trained first and then verified. Here are the training and verification processes.
Steps that the training process must go through:
Step 1: propagate the input forward and obtain the output after operation. Code: output = model(data)
Step 2: input output into the loss function and calculate the loss value (a scalar). Code: loss = criterion(output, target)
Step 3: back propagate the gradient to each parameter, code: loss backward()
Step 4: initialize the grad value of the parameter to 0, code: optimizer zero_ grad()
Step 5: update the weight, code: optimizer step()
The verification process is basically similar to the training process.
# Define training process
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print_loss = loss.data.item()
sum_loss += print_loss
if (batch_idx + 1) % 50 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
print('epoch:{},loss:{}'.format(epoch, ave_loss))
# Verification process
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
with torch.no_grad():
for data, target in test_loader:
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
_, pred = torch.max(output.data, 1)
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
# train
for epoch in range(1, EPOCHS + 1):
adjust_learning_rate(optimizer, epoch)
train(model_ft, DEVICE, train_loader, optimizer, epoch)
val(model_ft, DEVICE, test_loader)
torch.save(model_ft, 'model.pth')
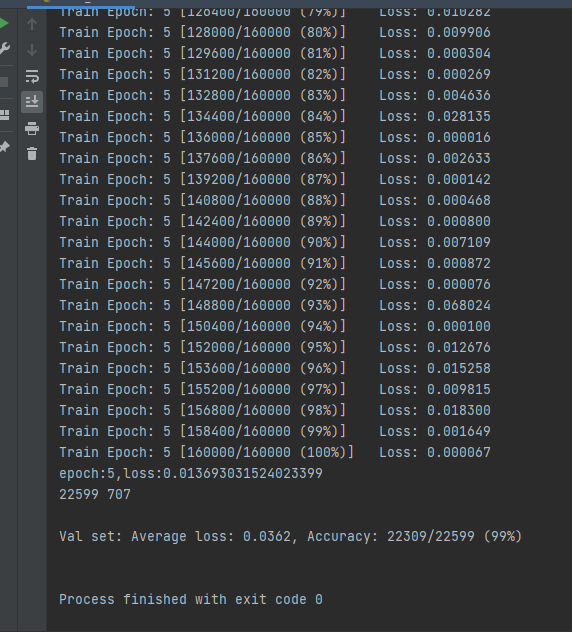
After completion, you can run. The running results are as follows:
test
The directory where the test set is stored is shown in the following figure:
The first step is to define the category. The order of this category corresponds to the category order during training. Do not change the order!!!! During our training, the Bald category is 0 and the NoBald category is 1, so I define classes as ('Bald','NoBald ').
The second step is to define transforms, which is the same as the transforms of the verification set, without data enhancement.
Step 3: load the model and put it in DEVICE,
Step 4: read the picture and predict the category of the picture. Here, note that the Image of PIL library is used to read the picture. Don't use cv2. transforms doesn't support it.
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import os
classes=('Bald','NoBald')
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load("model.pth")
model.eval()
model.to(DEVICE)
path='Dataset/Test/Bald/'
testList=os.listdir(path)
for file in testList:
img=Image.open(path+file)
img=transform_test(img)
img.unsqueeze_(0)
img = Variable(img).to(DEVICE)
out=model(img)
# Predict
_, pred = torch.max(out.data, 1)
print('Image Name:{},predict:{}'.format(file,classes[pred.data.item()]))The operation results are as follows: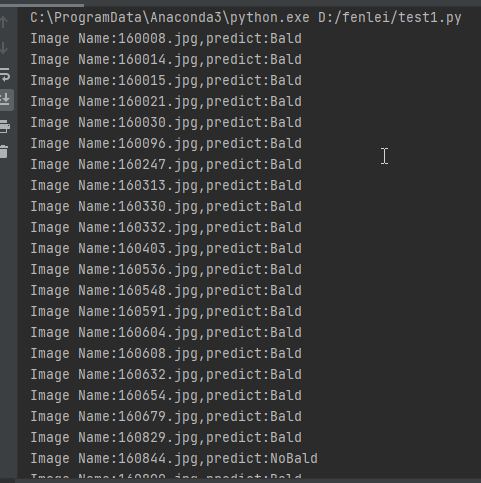
The second method can use pytorch to load the dataset by default.
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.autograd import Variable
classes=('Bald','NoBald')
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = torch.load("model.pth")
model.eval()
model.to(DEVICE)
dataset_test = datasets.ImageFolder('Dataset/Test',transform_test)
print(len(dataset_test))
# label of corresponding folder
for index in range(len(dataset_test)):
item = dataset_test[index]
img, label = item
img.unsqueeze_(0)
data = Variable(img).to(DEVICE)
output = model(data)
_, pred = torch.max(output.data, 1)
print('Image Name:{},predict:{}'.format(dataset_test.imgs[index], classes[pred.data.item()]))
index += 1
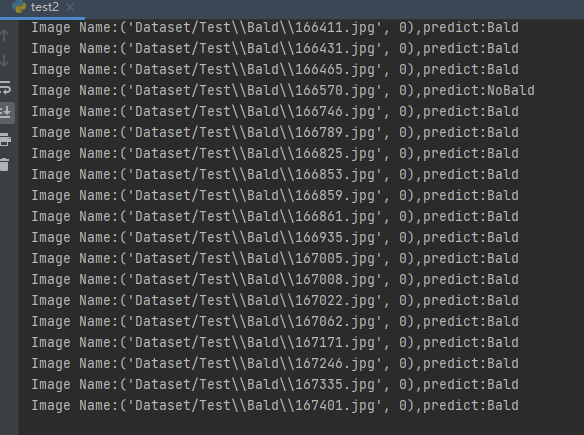
Operation results:
Complete code
import torch.optim as optim
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from torch.autograd import Variable
from torchvision.models import densenet121
# Set global parameters
modellr = 1e-4
BATCH_SIZE = 32
EPOCHS = 5
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Data preprocessing
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
transform_test = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
dataset_train = datasets.ImageFolder('Dataset/Train', transform)
dataset_test = datasets.ImageFolder('Dataset/Validation',transform_test)
# Read data
print(dataset_train.imgs)
# Import data
train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
# Instantiate the model and move to GPU
criterion = nn.CrossEntropyLoss()
model_ft = densenet121(pretrained=True)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, 2)
model_ft.to(DEVICE)
# Choose the simple and violent Adam optimizer and lower the learning rate
optimizer = optim.Adam(model_ft.parameters(), lr=modellr)
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
modellrnew = modellr * (0.1 ** (epoch // 50))
print("lr:", modellrnew)
for param_group in optimizer.param_groups:
param_group['lr'] = modellrnew
# Define training process
def train(model, device, train_loader, optimizer, epoch):
model.train()
sum_loss = 0
total_num = len(train_loader.dataset)
print(total_num, len(train_loader))
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
print_loss = loss.data.item()
sum_loss += print_loss
if (batch_idx + 1) % 50 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),
100. * (batch_idx + 1) / len(train_loader), loss.item()))
ave_loss = sum_loss / len(train_loader)
print('epoch:{},loss:{}'.format(epoch, ave_loss))
# Verification process
def val(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
total_num = len(test_loader.dataset)
print(total_num, len(test_loader))
with torch.no_grad():
for data, target in test_loader:
data, target = Variable(data).to(device), Variable(target).to(device)
output = model(data)
loss = criterion(output, target)
_, pred = torch.max(output.data, 1)
correct += torch.sum(pred == target)
print_loss = loss.data.item()
test_loss += print_loss
correct = correct.data.item()
acc = correct / total_num
avgloss = test_loss / len(test_loader)
print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
avgloss, correct, len(test_loader.dataset), 100 * acc))
# train
for epoch in range(1, EPOCHS + 1):
adjust_learning_rate(optimizer, epoch)
train(model_ft, DEVICE, train_loader, optimizer, epoch)
val(model_ft, DEVICE, test_loader)
torch.save(model_ft, 'model.pth')