Image fusion
Compilation environment: Python 3.0 8.3,OpenCV4.5.2,
Project code: https://download.csdn.net/download/zao_chao/20554332
Scale invariant feature transform (SIFT) is used for image matching and stitching. The image registration process based on SIFT point features includes feature extraction, feature description, feature matching, solving transformation model parameters and image transformation registration. The reference map is shown in Figure 1 below, and the map to be registered is figure 2.

Fig. 1 ^ reference diagram

Figure 2 # to be registered
The registration steps are:;
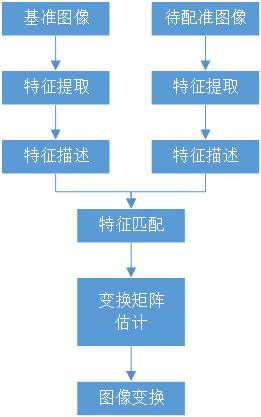
1. SIFT feature extraction and feature description. An image local invariant description operator based on scale space, which keeps the image scaling, rotation and even affine transformation unchanged. Its code is as follows:
def detect(image):
# Convert to grayscale
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# Create SIFT generator
# descriptor is an object. SIFT algorithm is used here
descriptor = cv2.xfeatures2d.SIFT_create()
# Detect feature points and their descriptors (128 dimensional vector)
kps, features = descriptor.detectAndCompute(image, None)
return (kps,features)
2. SIFT rough matching is defined by Euclidean distance measure. Lowe matches by comparing the ratio of the nearest neighbor Euclidean distance to the next nearest neighbor Euclidean distance. When the ratio of the nearest neighbor Euclidean distance to the next nearest neighbor Euclidean distance is less than a threshold, it is the matching point. The threshold is generally 0.8. The simple code of SIFT rough matching is as follows:
# Create violence matcher
matcher = cv2.DescriptorMatcher_create("BruteForce")
# Use knn detection to match the feature points of left and right graphs
raw_matches = matcher.knnMatch(features_left, features_right, 2)
print('Coarse matching points;',len(raw_matches))
matches = [] # Save coordinates for the back
good = [] # Save object for later demonstration
# Filter matching points
for m in raw_matches:
# Screening conditions
# print(m[0].distance,m[1].distance)
if len(m) == 2 and m[0].distance < m[1].distance * ratio:
good.append([m[0]])
matches.append((m[0].queryIdx, m[0].trainIdx))
"""
queryIdx: Subscript of feature point descriptor of test image==>img_keft
trainIdx: Subscript of feature point descriptor of sample image==>img_right
distance: It represents the Euclidean distance of the feature point descriptor matched by yicui. The smaller the value, the closer the two feature points are.
"""
# If the logarithm of characteristic points is greater than 4, it is enough to construct the transformation matrix
kps_left = np.float32([kp.pt for kp in kps_left])
kps_right = np.float32([kp.pt for kp in kps_right])
print('Fine matching points:',len(matches))
The results are:

Figure 3 # feature points
3. There are many mismatched points in SIFT feature matching based on Euclidean distance measure. These mismatched points will seriously affect the solution of the parameters of the later transformation model. Therefore, we need to use the robust estimation method to eliminate these mismatched points. Here, we use the most conventional RANSAC method for robust estimation.
if len(matches) > 4:
# Get matching point coordinates
pts_left = np.float32([kps_left[i] for (i, _) in matches])
pts_right = np.float32([kps_right[i] for (_, i) in matches])
# Calculate the transformation matrix (select some points from pts by ransac algorithm)
H, status = cv2.findHomography(pts_right, pts_left, cv2.RANSAC, threshold)
return (matches, H, good)
return None
The results are:

Figure 4 # picture matching and splicing
4. Image transformation. After obtaining the image transformation parameter matrix, using the affine transformation parameters and image interpolation, the image to be registered can be transformed into the coordinate system of the reference image. The code is as follows:
def drawMatches(img_left, img_right, kps_left, kps_right, matches, H):
# Get picture width and height
h_left, w_left = img_left.shape[:2]
h_right, w_right = img_right.shape[:2]
"""yes imgB Perform perspective transformation
Because the perspective transformation will change the size of the picture scene, some picture contents cannot be seen
So expand the picture:The height is the highest and the width is the sum of the two"""
image = np.zeros((max(h_left, h_right), w_left+w_right, 3), dtype='uint8')
# initialization
image[0:h_left, 0:w_left] = img_right
"""The homography matrix is used to carry out the variational perspective transformation"""
image = cv2.warpPerspective(image, H, (image.shape[1], image.shape[0]))#(w,h
"""Splice the perspective transformed picture with another picture"""
image[0:h_left, 0:w_left] = img_left
return image
Finally, the image to be registered is spliced with the reference image after registration:
