KNN (K-Nearest Neighbors) algorithm, also known as K-nearest neighbor algorithm, can be seen from the literal meaning alone. This algorithm must be related to distance.
The core idea of KNN algorithm:
In a feature space, if most of the K samples next to a sample belong to a category, the sample also belongs to this category to a large extent, and the sample also has the characteristics of this category.
In fact, it's just that "near the red, near the black". Most of the K people closest to you belong to a certain category, so you are likely to belong to this category (of course, it's not appropriate to use people as examples)
In the "classification decision", this method only judges the categories of the samples to be divided according to the categories of the nearest K samples. K is usually an integer no more than 20. How to select it is also very learned, which will be explained in detail later.
As mentioned above, the category of a sample to be divided largely depends on the category of its nearest K samples. So how can we calculate the "nearest" one? For example, a group of people standing together can easily calculate it
The distance between a person and everyone around him, what about the data? In fact, the truth is the same. We can use Euler distance to calculate. In fact, we have learned about the distance between two points in two-dimensional plane and two points in three-dimensional space in middle school geometry,
We can think of two-dimensional data as two features, and three-dimensional data as three features. When each data in a group has multiple features, we can also think of it as a point in multi-dimensional space,
It can also be calculated using Euler distance.

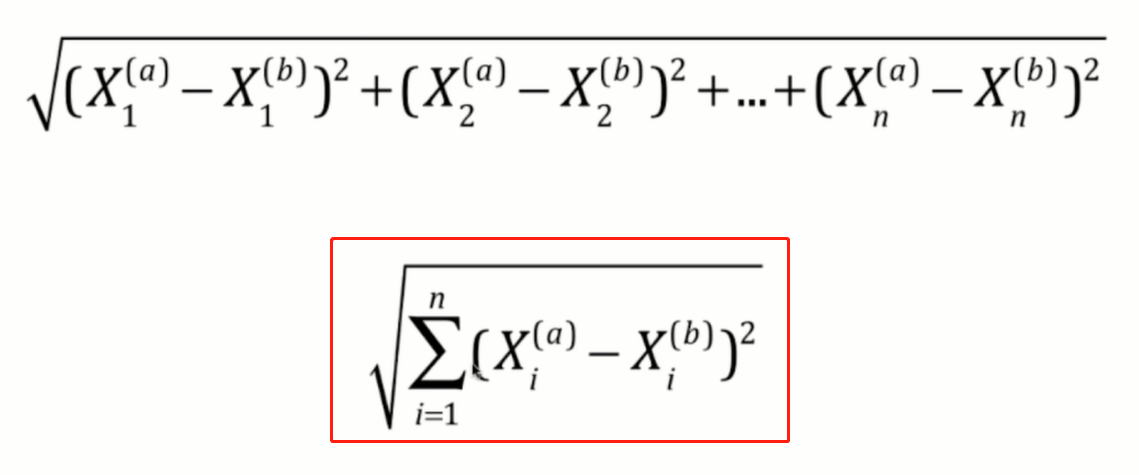
When extended to multiple features, it will be abbreviated to the formula in the upper red box, which is more common in machine learning algorithms.
Calculation steps of KNN algorithm:
(1) Calculate the distance between the data to be classified and each sample data
(2) Sort distances
(3) Select the first K points with the smallest distance
(4) Category of the first k points
(5) Return the category with the highest frequency of the first K points as the forecast classification of the data to be classified
Manually encapsulate a KNN algorithm:
import math import numpy as np from collections import Counter class NKKClass(object): def __init__(self, K): # Initialization KNN Class attribute assert K > 0, "constant K Positive integer required" self.K = K self._X_train = None # Private training feature array self._y_train = None # Private training label vector def fit(self, X_train, y_train): # According to training feature array X_train And label vector y_train To train the model(Of course, KNN There is no need to train the model in the algorithm) self._X_train = X_train self._y_train = y_train def predict(self, X_predict): # Incoming feature data set to be predicted X_predict,Returns the label vector corresponding to this feature data set y_predict = [self._predict(i) for i in X_predict] return y_predict def _predict(self, i): # Given a single feature data, according to the calculated Euler distance, return to the prediction label # Using Euler distance to calculate the distance between two points distances = [ math.sqrt(np.sum((x_train - i)**2)) for x_train in self._X_train] nearset = np.argsort(distances) #Sort the array in ascending order and extract the corresponding index index Proceed back # Extract the value in the label vector according to the index topK_y = [ self._y_train[index] for index in nearset[:self.K]] # Statistics array Frequency of each element in, n=1 Indicates the element with the highest frequency votes = Counter.most_common(n=1)[0][0] return votes
def accuracy_score(self, y_test, y_predict): # according to train_test_split Obtained y_test And predicted y_predict Calculate classification accuracy return sum(y_true == y_predict) / len(y_true)
def score(self, X_test, y_test): # according to train_test_split Split up X_test,y_test Direct calculation of classification accuracy y_predict = self.predict(X_test) return self.accuracy_score(y_test, y_predict)
The above class is actually written by imitating the kNN algorithm encapsulated in the scikit learn machine learning library.
Let's load the iris data set in the sklearn library to test it
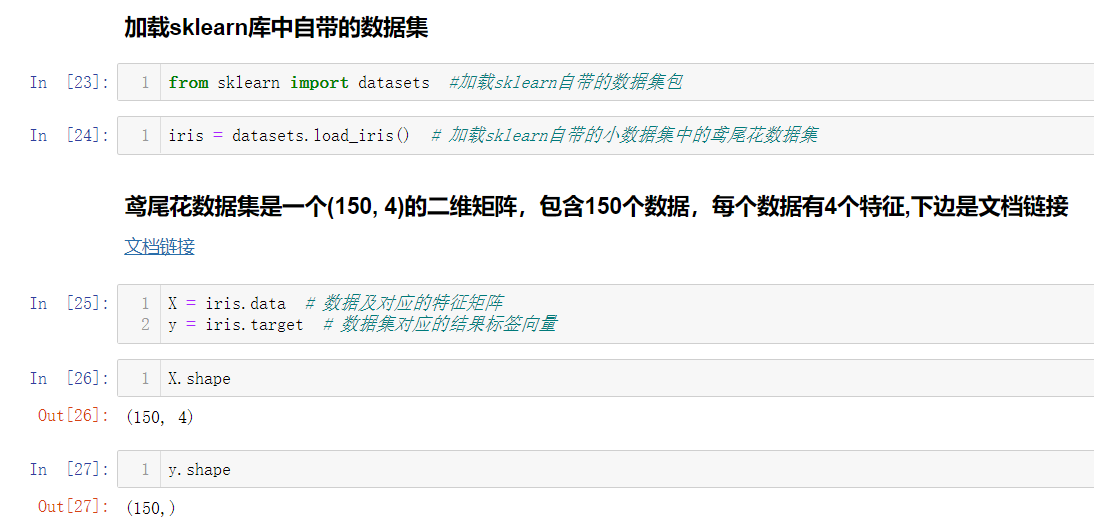
After we get the dataset, we can't directly treat all the datasets as training datasets, but we still need to leave a small part of them as test datasets. Therefore, it involves the problem of train ﹐ test ﹐ split, and the iris datasets have been arranged by default,
So we need to disorder the feature data set and label vector before we carry out the train test split.
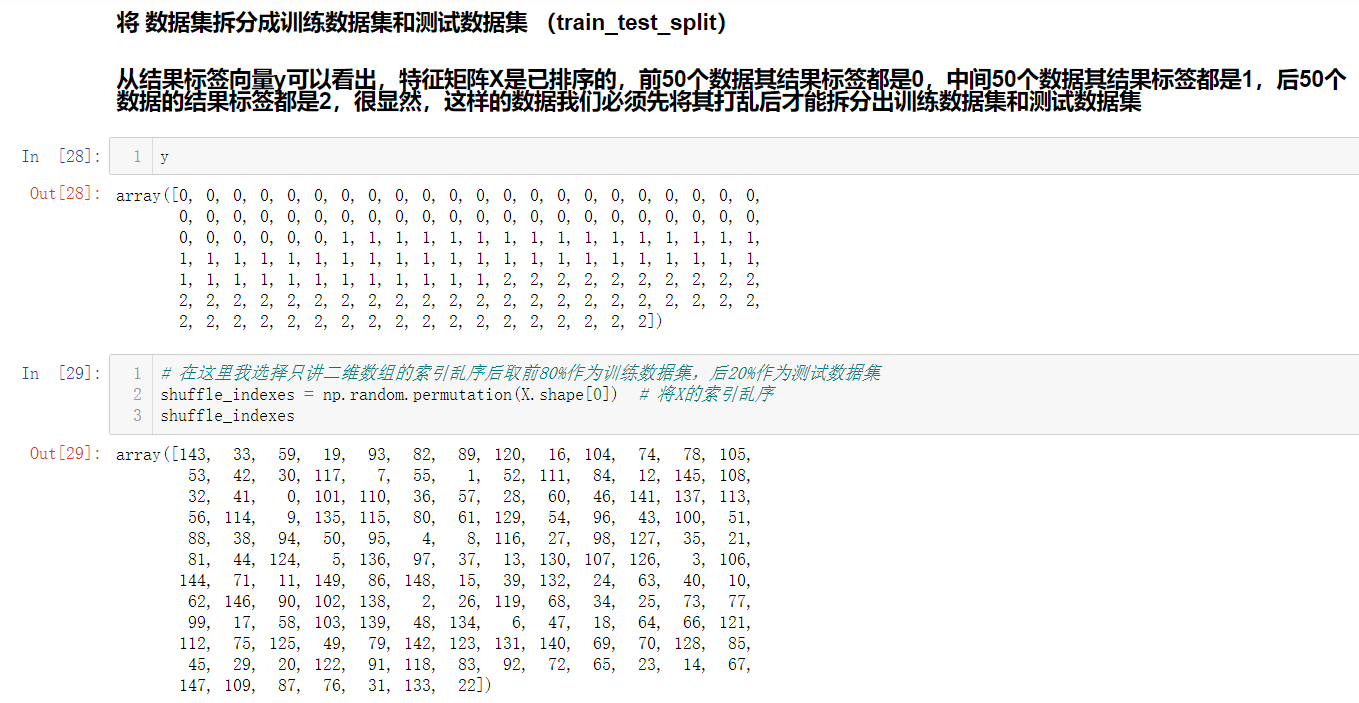
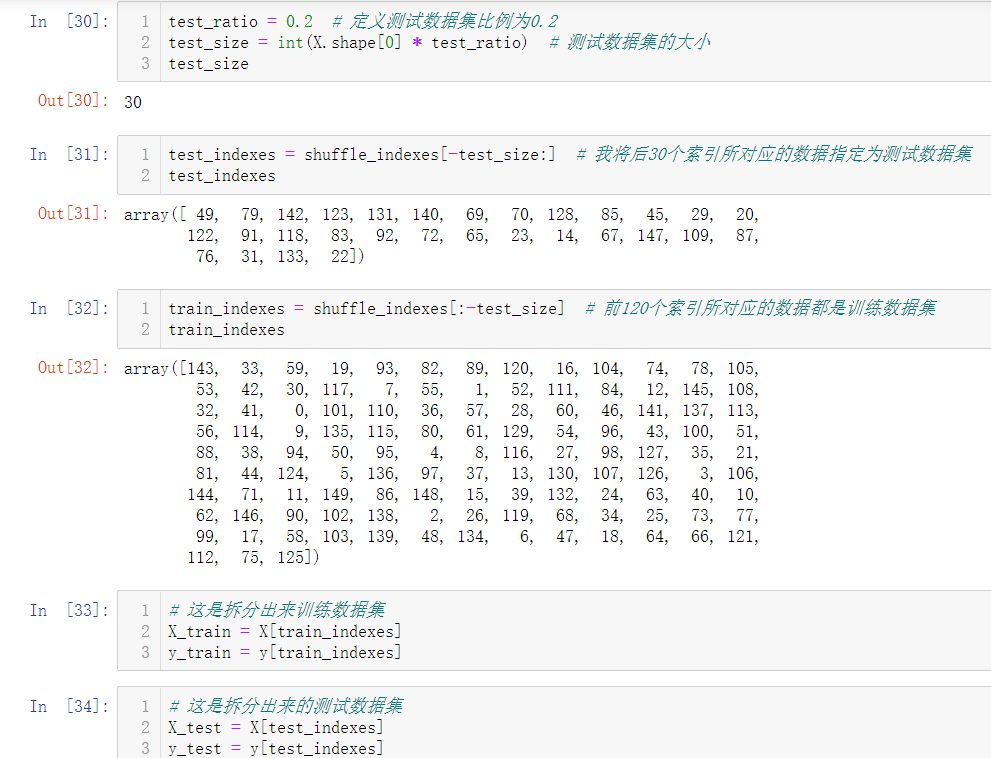
In fact, the train ﹐ test ﹐ split process has been encapsulated in sklearn and can be called directly.
from sklearn.model_selection import train_test_split
The train test split function has four parameters and returns four return values:
4 parameters:
Train? Data: array of features to be split
Train target: label vector to be split
test_size: if it is a floating-point number, between 0-1, it means the percentage of the test data set in the total data set; if it is an integer, it means the number of rows in the test data set.
Random state: random seed, default is None
4 return values:
X-train training feature array
X'u test test feature array
Y-train training label vector
Y'u test test label vector
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=666)
Next, the sklearn database is called, and KNN algorithm is directly used to predict the iris data set, and the classification accuracy is calculated:
# Load sklearn In Library KNN Class of algorithm from sklearn.neighbors import KNeighborsClassifier # Load sklearn Data package from sklearn import datasets # Load sklearn Self contained train_test_split function from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # Load the small data set in the package(Iris data set) iris = datasets.load_iris() X = iris.data # Characteristic matrix of data set y = iris.target # Label vector of dataset # Split the dataset, two eight X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=5) # Instantiation n_neighbors Namely KNN The one in the algorithm K KNN_classifier = KNeighborsClassifier(n_neighbors=6) KNN_classifier.fit(X_train, y_train) # Fit training data set predict_y_test = KNN_classifier.predict(X_test) # Predict the characteristic array of the test # In the light of train_test_split Obtained y_test And the predicted label vector to calculate the classification accuracy Classification_accuracy = accuracy_score(y_test, predict_y_test) print(Classification_accuracy) # In the light of train_test_split The obtained feature array and label vector are used to calculate the classification accuracy directly(You don't need to calculate the test tag vector first) Classification_accuracy = KNN_classifier.score(X_test, y_test) print(Classification_accuracy)
