This paper mainly explains the code and clarifies the code structure and ideas
1, Experimental purpose
Master the basic principle of dictionary coding, program LZW decoder with C/C + + language, and analyze the encoding and decoding algorithm.
2, Experimental principle
1. Code
(1) Code 0-255 is used to store the characters with Ascii code [0255] and put them in the dictionary.
(2) The encoding starts at 256 and the characters that appear are included in the dictionary
(3) Core idea: using the reusability of characters, whenever a code is output to the result, a new string is stored in the dictionary
2. Decoding
The process of establishing and decompressing a dictionary is not the same as the process of decompressing a dictionary. After decompression, the dictionary created when compressing the file is exactly the same as the dictionary created by decompression.
3, Experimental steps
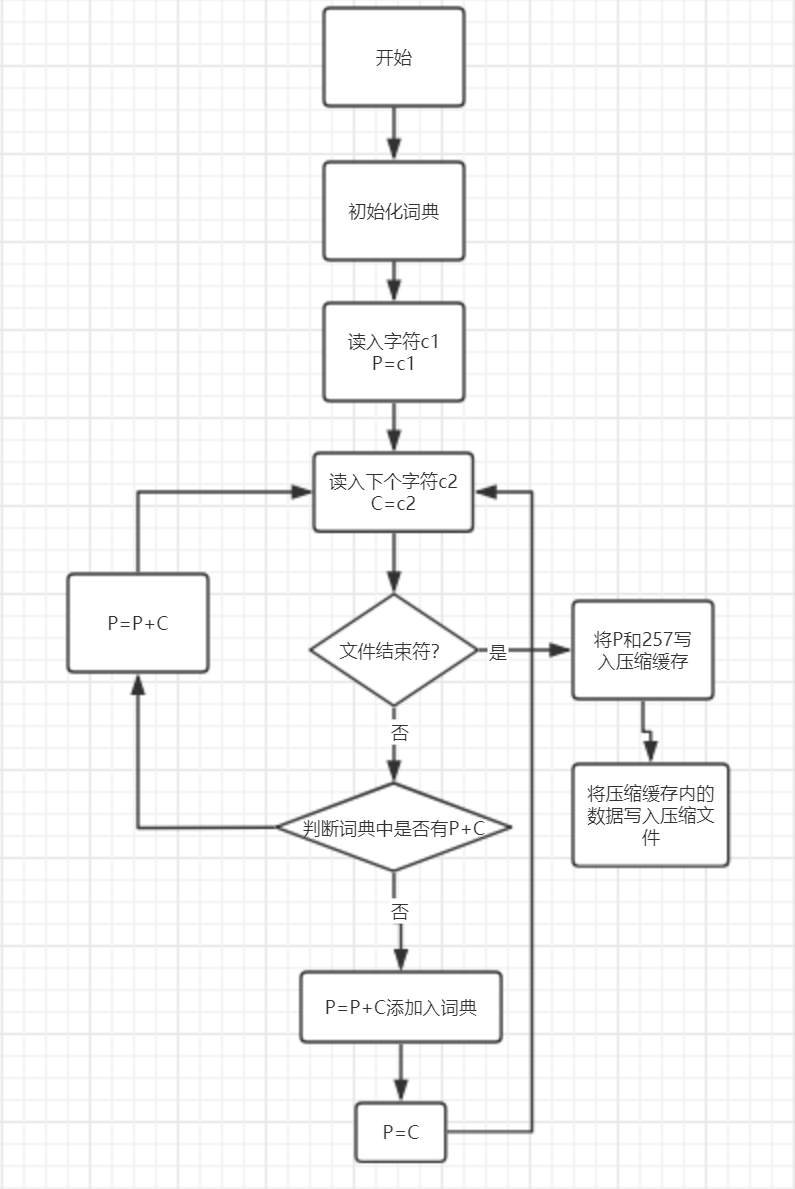
1. Code
Step 1: initialize the dictionary to include all possible single characters, and initialize the current prefix P to null.
Step 2: the current character C = the next character in the character stream.
Step 3: judge whether P + C is in the dictionary
(1) If "yes", expand P with C, that is, let P=P + C, and return to step 2.
(2) If "no", the codeword W corresponding to the current prefix P is output; Add P + C to the dictionary; Let P=C and return to step 2
2. Decoding
Step 1: at the beginning of decoding, the dictionary contains all possible prefix roots.
3
Step 2: make CW: = the first codeword in the codeword stream.
Step 3: output the current suffix string CW to codeword stream.
Step 4: Previous codeword PW: = current codeword CW.
Step 5: current codeword CW: = next codeword of codeword stream.
Step 6: determine the prefix string Whether CW is in the dictionary.
(1) If "yes", the prefix string string CW output to character stream; Current prefix P: = prefix string first PW; Current character c: = current prefix string The first character of CW; Add the suffix string P+C to the dictionary.
(2) If "no", the current prefix P: = prefix string first PW; Prefix string - current character string The first character of CW; Output the suffix string P+C to the character stream, and then add it to the dictionary.
Step 7: judge whether there are still codewords to be translated in the codeword stream.
(1) If yes, go back to step 4.
(2) If "no", end
4, Code implementation and comments
Header file:
typedef struct {//A custom structure variable used as a file stream
FILE* fp;
unsigned char mask;
int rack;
}BITFILE;
BITFILE* OpenBitFileInput(char* filename);//Structure variables are used to store input files
BITFILE* OpenBitFileOutput(char* filename);//Structure variables are used to store the output file
void CloseBitFileInput(BITFILE* bf); //Close bitstream file
void CloseBitFileOutput(BITFILE* bf);//Close bitstream file
int BitInput(BITFILE* bf);
unsigned long BitsInput(BITFILE* bf, int count);//Input bitstream
void BitOutput(BITFILE* bf, int bit);
void BitsOutput(BITFILE* bf, unsigned long code, int count);//Map the encoding corresponding to the character to a fixed length encoding
Source file:
struct {
int suffix;
int parent, firstchild, nextsibling;
} dictionary[MAX_CODE + 1];
int next_code;
int d_stack[MAX_CODE]; // stack for decoding a phrase
#define input(f) ((int)BitsInput( f, 16)) #define output(f, x) BitsOutput( f, (unsigned long)(x), 16)
int DecodeString(int start, int code);
void InitDictionary(void);
void PrintDictionary(void) {
//Print out a custom dictionary
int n;
int count;
for (n = 256; n < next_code; n++) {
count = DecodeString(0, n);
printf("%4d->", n);
while (0 < count--) printf("%c", (char)(d_stack[count]));
printf("\n");
}
}
int DecodeString(int start, int code) {
//Decode the string from the code to d_stack in this stack
int count;
count = start;
while (0 <= code) {
d_stack[count] = dictionary[code].suffix;
code = dictionary[code].parent;
count++;
}
return count;
}
void InitDictionary(void) {
//Initialize the dictionary, set the structure with the logical data structure of the tree, and the storage structure of the array
int i;
for (i = 0; i < 256; i++) {
dictionary[i].suffix = i;
dictionary[i].parent = -1;
dictionary[i].firstchild = -1;
dictionary[i].nextsibling = i + 1;
}
dictionary[255].nextsibling = -1;
next_code = 256;
}
/*
* Input: string represented by string_code in dictionary,
* Output: the index of character+string in the dictionary
* index = -1 if not found
*/
int InDictionary(int character, int string_code) {
//Query whether the string added with the new character is in the dictionary
int sibling;
if (0 > string_code) return character;
sibling = dictionary[string_code].firstchild;
while (-1 < sibling) {
if (character == dictionary[sibling].suffix) return sibling;
sibling = dictionary[sibling].nextsibling;
}
return -1;
}
void AddToDictionary(int character, int string_code) {
//Adds a newly formed string to the dictionary
int firstsibling, nextsibling;
if (0 > string_code) return;
dictionary[next_code].suffix = character;
dictionary[next_code].parent = string_code;
dictionary[next_code].nextsibling = -1;
dictionary[next_code].firstchild = -1;
firstsibling = dictionary[string_code].firstchild;
if (-1 < firstsibling) { // the parent has child
nextsibling = firstsibling;
while (-1 < dictionary[nextsibling].nextsibling)
nextsibling = dictionary[nextsibling].nextsibling;
dictionary[nextsibling].nextsibling = next_code;
}
else {// no child before, modify it to be the first
dictionary[string_code].firstchild = next_code;
}
next_code++;
}
void LZWEncode(FILE* fp, BITFILE* bf) {
int character;
int string_code;//Dictionary encoding corresponding to character or string
int index;
unsigned long file_length;
fseek(fp, 0, SEEK_END);
file_length = ftell(fp);
fseek(fp, 0, SEEK_SET);
BitsOutput(bf, file_length, 4 * 8);
InitDictionary();//Initialize dictionary
string_code = -1;
while (EOF != (character = fgetc(fp))) {//Read characters from files
index = InDictionary(character, string_code);
if (0 <= index) { // string+character in dictionary
string_code = index;
}
else {
output(bf, string_code);// string+character not in dictionary
if (MAX_CODE > next_code) { //When there is room in the dictionary
AddToDictionary(character, string_code);// add string+character to dictionary
}
string_code = character;//Put the code of the current character after the existing code string
}
}
output(bf, string_code);// Write the code string to the corresponding binary file
}
void LZWDecode(BITFILE* bf, FILE* fp) {
int character;//Character code
int new_code, last_code;
int phrase_length;
unsigned long file_length;//file length
file_length = BitsInput(bf, 4 * 8);
if (-1 == file_length) file_length = 0;
/*Need to fill*/
InitDictionary();//Initialize dictionary
last_code = -1;
while (0 < file_length) {
new_code = input(bf);//Read in a character
if (new_code >= next_code) { // When the character code is greater than the character code in the dictionary
d_stack[0] = character;
phrase_length = DecodeString(1, last_code); //Solve the characters and store them in d_stack stack
}
else {//When the character code is smaller than the character code in the dictionary
phrase_length = DecodeString(0, new_code);//Solve the characters and store them in d_stack stack
}
character = d_stack[phrase_length - 1];
while (0 < phrase_length) {//Output string to text file
phrase_length--;
fputc(d_stack[phrase_length], fp);
file_length--;
}
if (MAX_CODE > next_code) {//When there is room in the dictionary
AddToDictionary(character, last_code);//Add characters to dictionary
}
last_code = new_code;//Number of updated dictionaries last_code is the latest new_code
}
}
int main(int argc, char** argv) {
FILE* fp;//File pointer entered
BITFILE* bf; //Output binary stream pointer
if (4 > argc) {//Error in input parameters
fprintf(stdout, "usage: \n%s <o> <ifile> <ofile>\n", argv[0]);
fprintf(stdout, "\t<o>: E or D reffers encode or decode\n");
fprintf(stdout, "\t<ifile>: input file name\n");
fprintf(stdout, "\t<ofile>: output file name\n");
return -1;
}
if ('E' == argv[1][0]) { // do encoding
fp = fopen(argv[2], "rb");//Read in file
bf = OpenBitFileOutput(argv[3]);//Create output file
if (NULL != fp && NULL != bf) {
LZWEncode(fp, bf);//code
fclose(fp);//Close file pointer
CloseBitFileOutput(bf);//Close file stream pointer
fprintf(stdout, "encoding done\n");
}
}
else if ('D' == argv[1][0]) { // do decoding
bf = OpenBitFileInput(argv[2]);//Read in file stream
fp = fopen(argv[3], "wb");//Create output file
if (NULL != fp && NULL != bf) {
LZWDecode(bf, fp);//decode
fclose(fp);//Close file pointer
CloseBitFileInput(bf);//Close file stream pointer
fprintf(stdout, "decoding done\n");
}
}
else { // otherwise
fprintf(stderr, "not supported operation\n");
}
return 0;
}
5, Experimental results and analysis
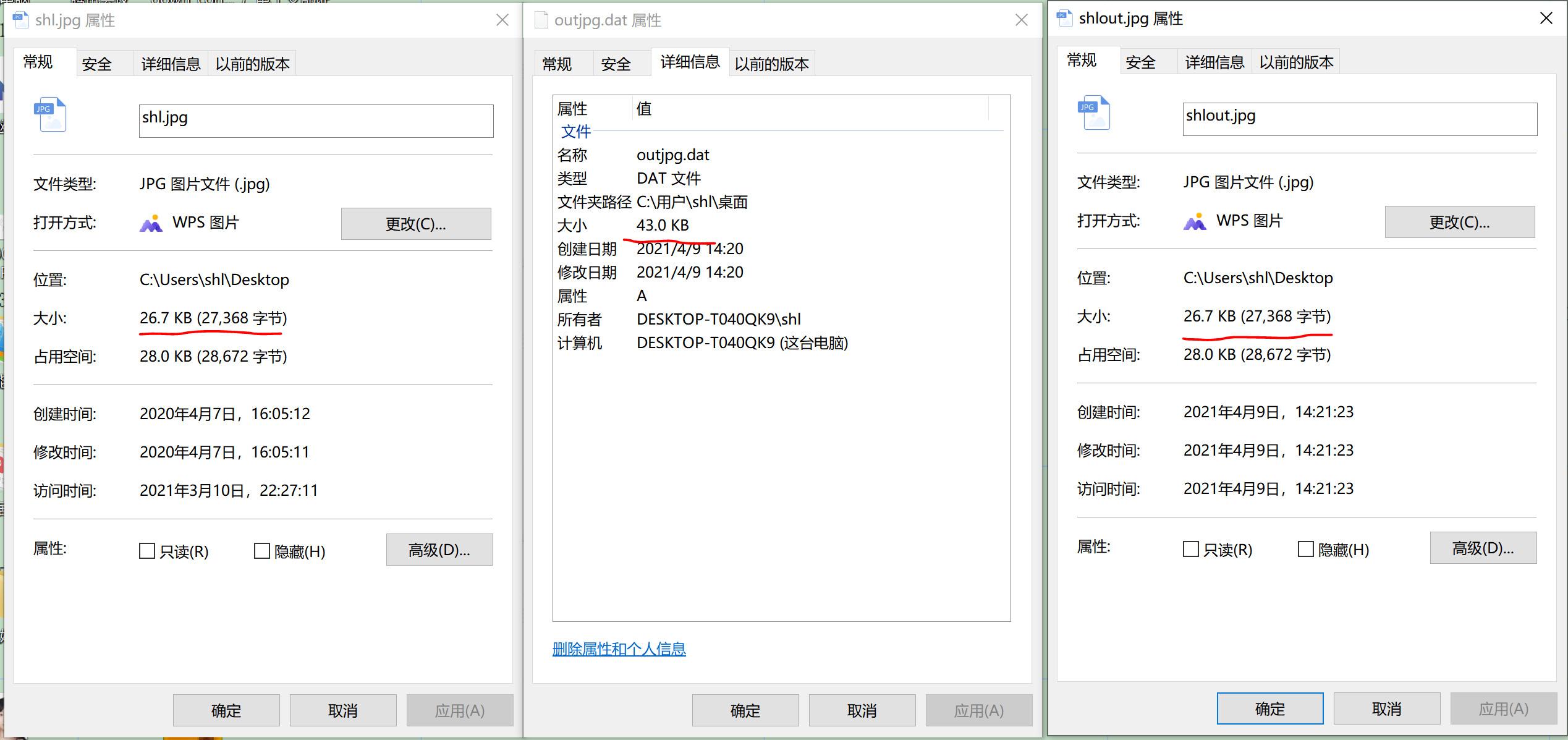
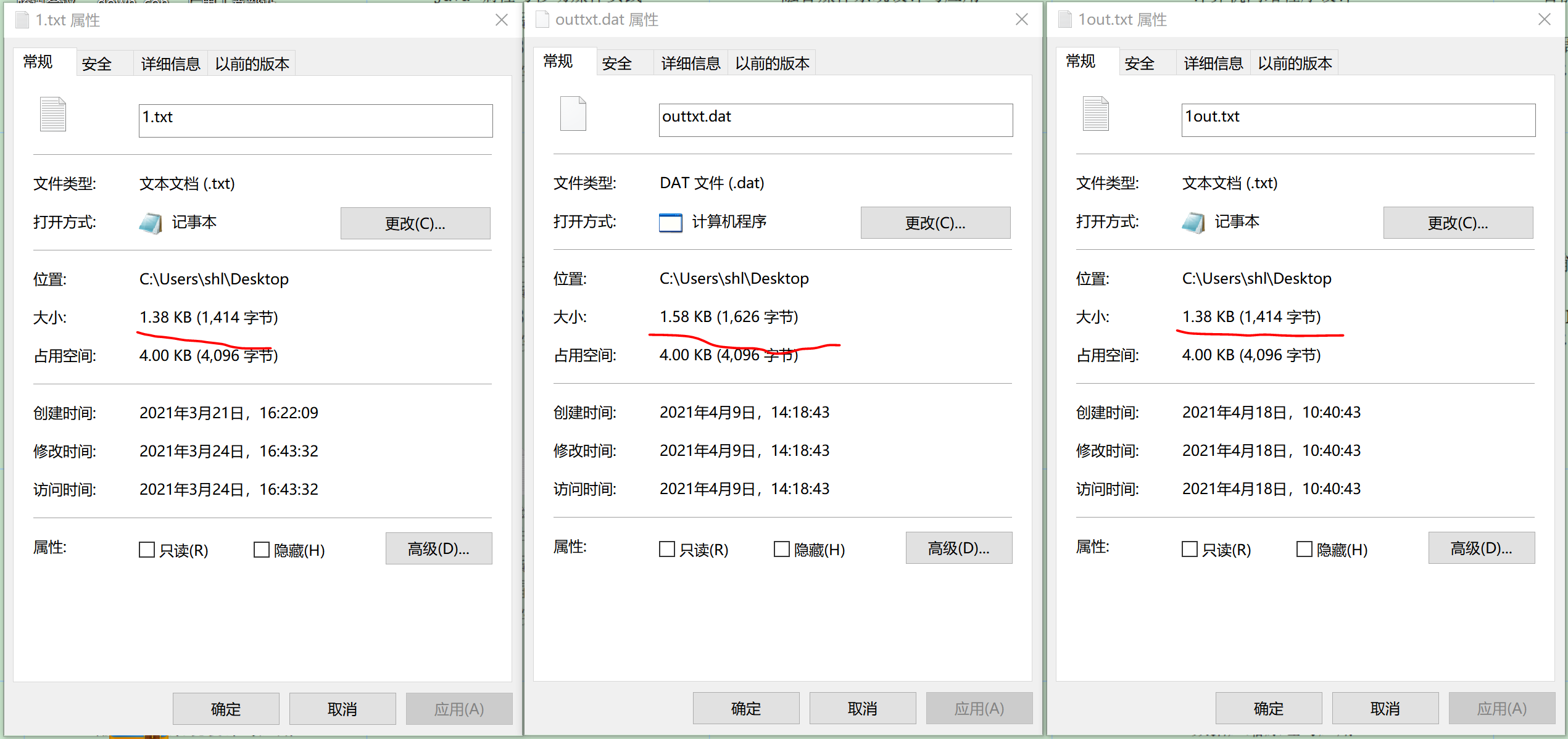
After comparing more than ten types of documents, it is concluded that:
The compression effect of text file is good, and the compression effect of image and video file is poor.
LZW coding principle is based on repeated characters, so for text files with low repetition rate in data, it is necessary to create a new string and store it in the dictionary, which will also lead to low compression efficiency.
However, this coding is mainly used for image data compression. For the signal source with simple image, smooth and low noise, it has high compression ratio and high compression and decompression speed.
There is no change when compressing yuv files.
summary
lzw compression is a lossless compression method that compresses files into small files based on table lookup algorithm.