The purpose of this article is to help more people understand rosedb. I will implement a simple k-v storage engine including PUT, GET and DELETE operations from scratch. You can regard it as a simple version of rosedb, just call it minidb (mini version of rosedb).
Whether you are a beginner of Go language, want to advance Go language, or are interested in k-v storage, you can try to implement it yourself. I believe it will be of great help to you.
When it comes to storage, a core problem to be solved is how to store data and how to take out data. In the computer world, this problem will be more diverse.
There are memory and disk in the computer. The memory is volatile. All the data stored after power failure is lost. Therefore, if you want the system to crash and restart and still use normally, you have to store the data in non-volatile media. The most common is disk.
Therefore, for a stand-alone version of k-v, we need to design how data should be stored in memory and on disk.
Of course, many excellent predecessors have explored it and have made a classic summary. The data storage models are mainly divided into two categories: B + tree and LSM tree.
The focus of this paper is not on these two models, so it is only a brief introduction.
B + tree
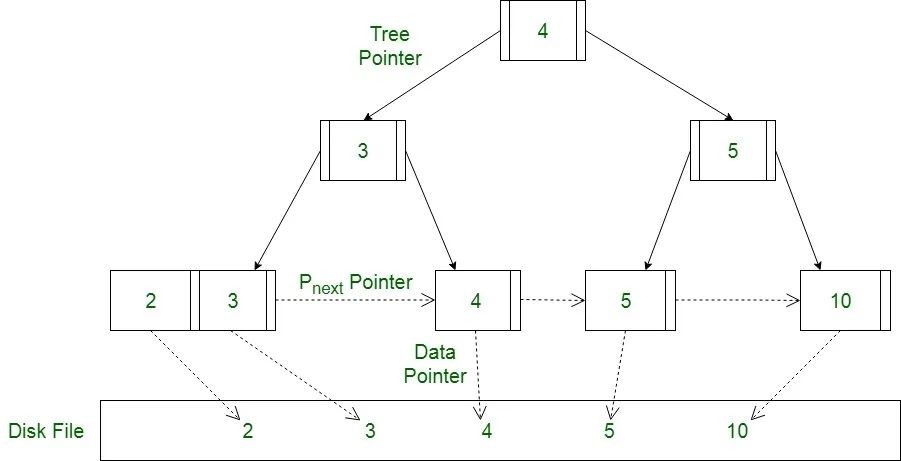
B + tree is evolved from binary lookup tree. By increasing the number of nodes in each layer, the height of the tree is reduced, the disk pages are adapted, and the disk IO operations are minimized.
The B + tree query performance is relatively stable. When writing or updating, it will find and locate the location in the disk and perform in-situ operations. Note that this is random IO, and a large number of inserts or deletions may trigger page splitting and merging. The writing performance is average. Therefore, the B + tree is suitable for scenarios with more reads and less writes.
LSM tree

LSM Tree (Log Structured Merge Tree) is not a specific tree type data structure, but a data storage model. Its core idea is based on the fact that sequential IO is much faster than random io.
Unlike the B + tree, in LSM, the insertion, update and deletion of data will be recorded as a log, and then added to the disk file, so that all operations are sequential IO.
LSM is more suitable for scenarios with more write and less read.
After looking at the previous two basic storage models, I believe you have a basic understanding of how to access data. minidb is based on a simpler storage structure, which is generally similar to LSM.
I will not talk about the concept of this model directly, but take a simple example to see the data PUT, GET and DELETE processes in minidb, so as to let you understand this simple storage model.
PUT
We need to store a piece of data, namely key and value. First, to prevent data loss, we will package the key and value into a record (here, this record is called Entry) and append it to the disk file. The contents of the Entry are roughly key, value, key size, value size, and writing time.
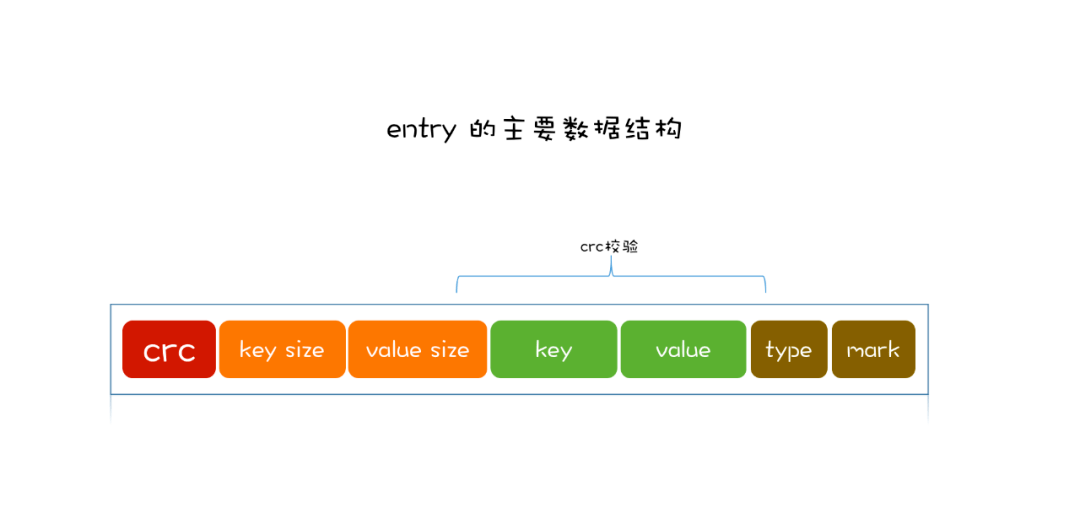
Therefore, the structure of disk files is very simple, that is, a collection of multiple entries.
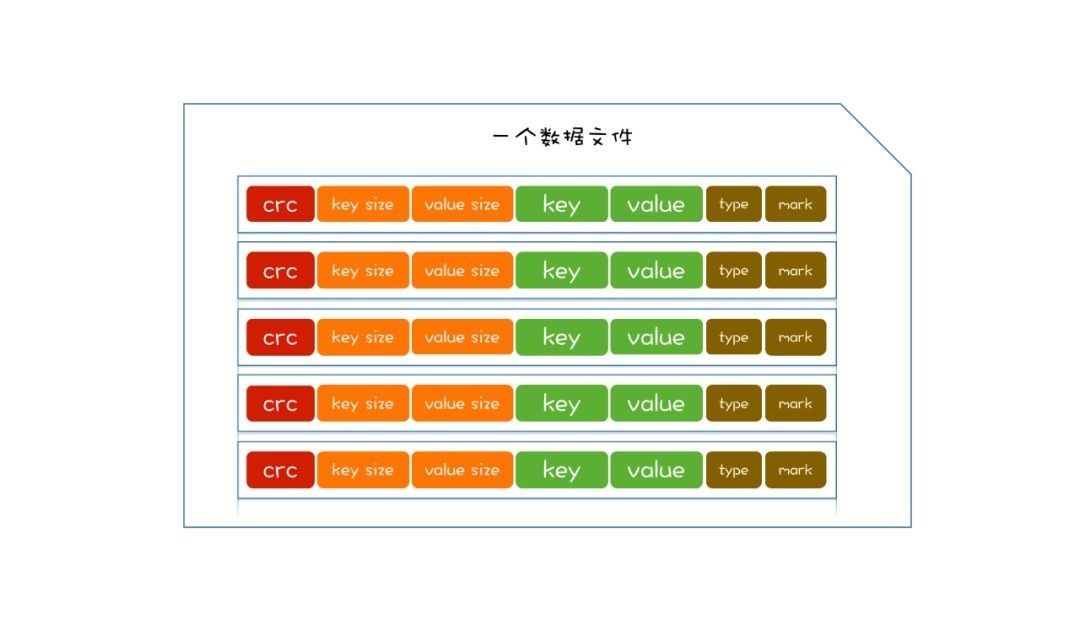
After the disk is updated, the memory can be updated. A simple data structure, such as hash table, can be selected in the memory. The key of the hash table corresponds to the location of the Entry in the disk, which is easy to obtain when searching.
In this way, in minidb, the data storage process is completed once, with only two steps: an addition of disk records and an index update in memory.
GET
Let's look at getting data. First, find the index information corresponding to the key in the hash table in memory, which includes the location where value is stored in the disk file, and then directly GET value from the disk according to this location.
DEL
Then there is the delete operation. Here, the original record will not be located for deletion, but the deleted operation will be encapsulated as an Entry and appended to the disk file. Only here, it is necessary to identify the type of Entry as delete.
Then delete the index information of the corresponding key in the hash table in memory, and the deletion operation is completed.
It can be seen that there are only two steps to insert, query and delete: an index update in memory and an additional record of disk file. Therefore, regardless of the data size, the writing performance of minidb is very stable.
Merge
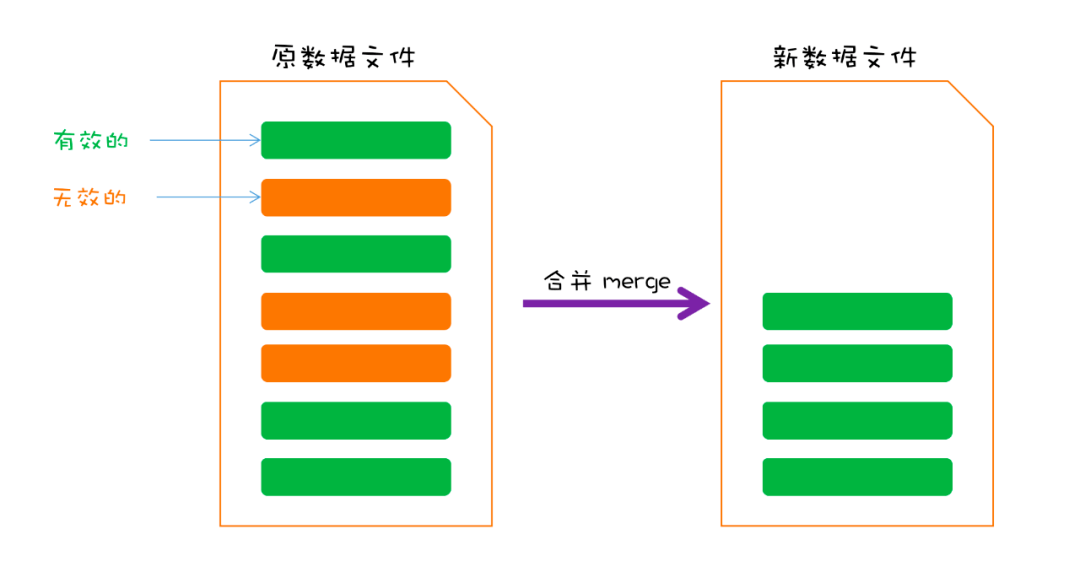
Finally, let's look at a more important operation. As mentioned earlier, the records of disk files have been added and written all the time, which will lead to the increase of file capacity all the time. Moreover, for the same key, there may be multiple entries in the file (recall that updating or deleting the key content will also add records). In fact, there are redundant Entry data in the data file.
Take a simple example. For example, if the value of key A is set to 10, 20 and 30 successively, there are three records in the disk file:
At this time, the latest value of A is 30, so the first two records are invalid.
In this case, we need to merge data files regularly and clean up invalid Entry data. This process is generally called merge.
The idea of merge is also very simple. You need to take out all the entries of the original data file, re write the valid entries into a new temporary file, and finally delete the original data file. The temporary file is the new data file.
This is the underlying data storage model of minidb. Its name is bitask. Of course, rosedb adopts this model. It is essentially an LSM like model. Its core idea is to use sequential IO to improve write performance, but its implementation is much simpler than LSM.
After introducing the underlying storage model, you can start the code implementation. I put the complete code implementation on my Github, address:
The article intercepts some key code.
First, open the database. You need to load the data file first, then take out the Entry data in the file and restore the index state. The key codes are as follows:
func Open(dirPath string) (*MiniDB, error) {
// If the database directory does not exist, create a new one
if _, err := os.Stat(dirPath); os.IsNotExist(err) {
if err := os.MkdirAll(dirPath, os.ModePerm); err != nil {
return nil, err
}
}
// Load data file
dbFile, err := NewDBFile(dirPath)
if err != nil {
return nil, err
}
db := &MiniDB{
dbFile: dbFile,
indexes: make(map[string]int64),
dirPath: dirPath,
}
// Load index
db.loadIndexesFromFile(dbFile)
return db, nil
}Let's look at the PUT method. The process is the same as the above description. First update the disk, write a record, and then update the memory:
func (db *MiniDB) Put(key []byte, value []byte) (err error) {
offset := db.dbFile.Offset
// Encapsulate as Entry
entry := NewEntry(key, value, PUT)
// Append to data file
err = db.dbFile.Write(entry)
// Write to memory
db.indexes[string(key)] = offset
return
}The GET method needs to first take out the index information from the memory to judge whether it exists. If it does not exist, it will return directly. If it exists, it will take out the data from the disk.
func (db *MiniDB) Get(key []byte) (val []byte, err error) {
// Fetch index information from memory
offset, ok := db.indexes[string(key)]
// key does not exist
if !ok {
return
}
// Read data from disk
var e *Entry
e, err = db.dbFile.Read(offset)
if err != nil && err != io.EOF {
return
}
if e != nil {
val = e.Value
}
return
}The DEL method is similar to the PUT method, except that the Entry is identified as DEL, then encapsulated as an Entry and written to the file:
func (db *MiniDB) Del(key []byte) (err error) {
// Fetch index information from memory
_, ok := db.indexes[string(key)]
// key does not exist, ignore
if !ok {
return
}
// Encapsulate as an Entry and write
e := NewEntry(key, nil, DEL)
err = db.dbFile.Write(e)
if err != nil {
return
}
// Delete key in memory
delete(db.indexes, string(key))
return
}The last is the important operation of merging data files. The process is the same as that described above. The key codes are as follows:
func (db *MiniDB) Merge() error {
// Read the Entry in the original data file
for {
e, err := db.dbFile.Read(offset)
if err != nil {
if err == io.EOF {
break
}
return err
}
// The index status in memory is up-to-date, and valid entries are filtered out by direct comparison
if off, ok := db.indexes[string(e.Key)]; ok && off == offset {
validEntries = append(validEntries, e)
}
offset += e.GetSize()
}
if len(validEntries) > 0 {
// New temporary file
mergeDBFile, err := NewMergeDBFile(db.dirPath)
if err != nil {
return err
}
defer os.Remove(mergeDBFile.File.Name())
// Re write a valid entry
for _, entry := range validEntries {
writeOff := mergeDBFile.Offset
err := mergeDBFile.Write(entry)
if err != nil {
return err
}
// Update index
db.indexes[string(entry.Key)] = writeOff
}
// Delete old data files
os.Remove(db.dbFile.File.Name())
// The temporary file is changed to a new data file
os.Rename(mergeDBFile.File.Name(), db.dirPath+string(os.PathSeparator)+FileName)
db.dbFile = mergeDBFile
}
return nil
}Apart from the test files, the core code of minidb is only 300 lines. Although the sparrow is small and has all kinds of internal organs, it already contains the main idea of bitask, which is also the underlying foundation of rosedb.
After understanding minidb, you can basically fully master the bitask storage model, spend more time, and I believe you can be comfortable with rosedb.
Further, if you are interested in k-v storage, you can study more relevant knowledge more deeply. Bitask is simple and easy to understand, but there are many problems. rosedb has optimized it in the process of practice, but there are still many problems.
Some people may wonder if the bitask model is simple. Is it just a toy and can it be used in the actual production environment? The answer is yes.
Bitask was originally derived from the underlying storage model of the project Riak, which is a distributed k-v storage and ranks first in NoSQL:

The distributed k-v storage used by Douban is actually based on the bitask model, and it has been optimized a lot. At present, there are not many k-vs based solely on bitask model, so you can take a look at rosedb's code and put forward your own opinions and suggestions to improve the project together.
Finally, attach the relevant project address:
minidb: github.com/roseduan/minidb
rosedb: github.com/roseduan/rosedb
reference material: