Atomicity of operation
Ten threads perform + + on the count variable at the same time, and each thread performs + + 100000 times. The ideal result is 1 million, but the final result is less than 1 million.
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define THREAD_COUNT 10
void *func(void *arg) {
volatile int *pcount = (int *)arg;
int i = 0;
for (i = 0; i < 100000; i++) {
(*pcount)++;
usleep(1);
}
}
int main() {
pthread_t tid[THREAD_COUNT] = {0};
int count = 0;
int i = 0;
for (i = 0; i < THREAD_COUNT; i++) {
pthread_create(&tid[i], NULL, func, &count);
}
for (i = 0; i < 100; i++) {
printf("count --> %d\n", count);
sleep(1);
}
for (i = 0; i < THREAD_COUNT; i++) {
pthread_join(tid[i], NULL);
}
}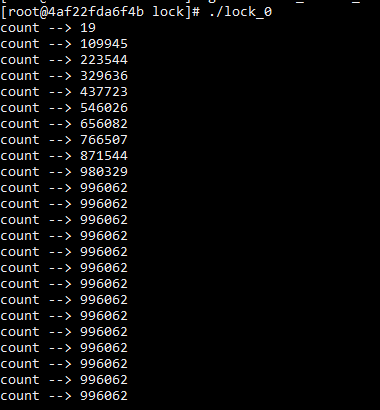
Why is the result less than 1 million? Because i + + is not an atomic operation.
#include <stdio.h>
int i = 0;
// gcc -S 1_test_i++.c
int main(int argc, char **argv)
{
i++;
return 0;
}i + + is not an atomic operation
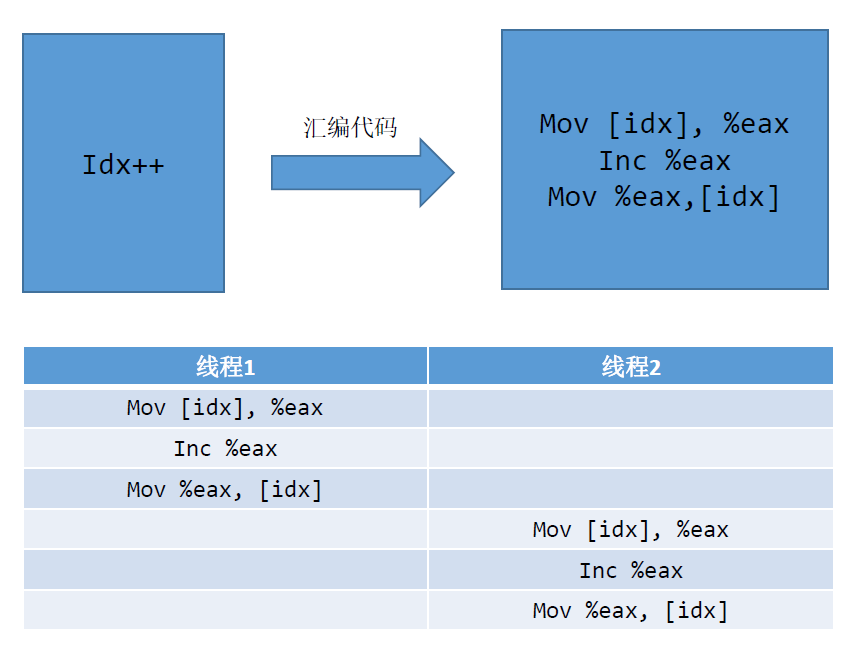
i + + assembly code
movl i(%rip), %eax //Load i from memory into register addl $1, %eax //Add 1 to the value of the register movl %eax, i(%rip) //Write the value of the register back to memory
Multiple threads count + + at the same time. Most of the time, the three instructions of thread 1 are executed and thread 2 is executed
However, sometimes the first or the first two instructions of thread 1 are executed, thread 2 is executed again, and finally the third instruction of thread 1 is executed, which will cause the final result to be less than 1 million.
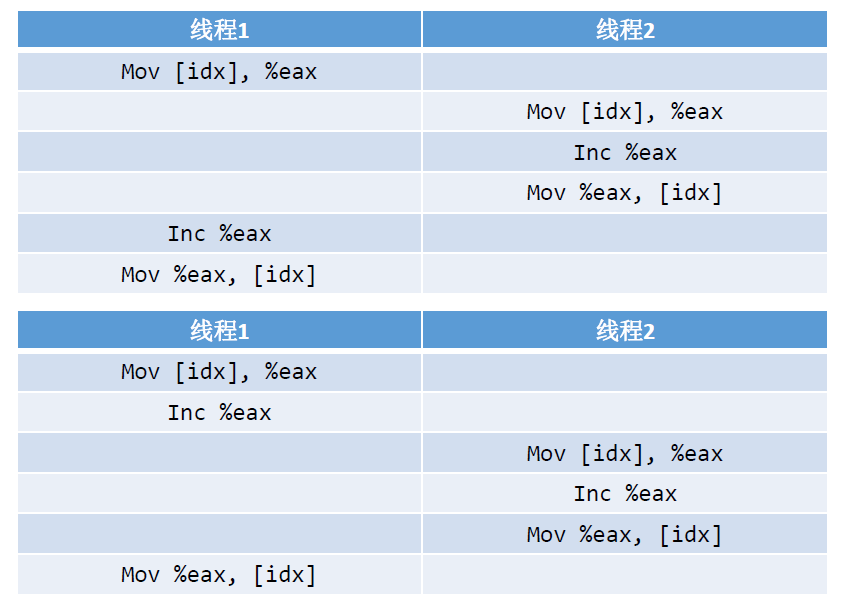
This will cause thread insecurity. To solve this problem, you need to lock or use atomic operations.
mutex
If the lock cannot be obtained, the CPU is released and the thread is added to the waiting queue.
The task takes longer than context switching. mutex can be used.
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define THREAD_COUNT 10
pthread_mutex_t mutex;
void *func(void *arg) {
int *pcount = (int *)arg;
int i = 0;
for (i = 0; i < 100000; i++) {
pthread_mutex_lock(&mutex);
(*pcount)++;
pthread_mutex_unlock(&mutex);
usleep(1);
}
}
int main() {
pthread_t tid[THREAD_COUNT] = {0};
int count = 0;
pthread_mutex_init(&mutex, NULL);
int i = 0;
for (i = 0; i < THREAD_COUNT; i++) {
pthread_create(&tid[i], NULL, func, &count);
}
for (i = 0; i < 100; i++) {
printf("count --> %d\n", count);
sleep(1);
}
for (i = 0; i < THREAD_COUNT; i++) {
pthread_join(tid[i], NULL);
}
}
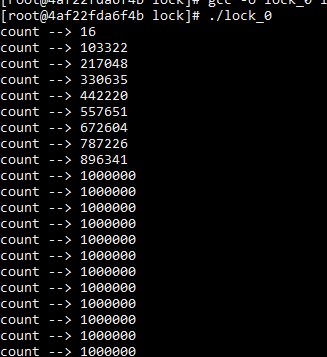
Spin lock
If the lock cannot be obtained, continue the dead cycle to check the lock status. If it is in lock status, continue the dead cycle. Otherwise, lock and end the dead cycle.
(1) The task cannot be blocked. (2) the task takes a short time and several instructions
PTHREAD_PROCESS_SHARED indicates that the processes fork ed out can be shared.
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define THREAD_COUNT 10
pthread_spinlock_t spinlock;
void *func(void *arg) {
int *pcount = (int *)arg;
int i = 0;
for (i = 0; i < 100000; i++) {
pthread_spin_lock(&spinlock);
(*pcount)++;
pthread_spin_unlock(&spinlock);
usleep(1);
}
}
int main() {
pthread_t tid[THREAD_COUNT] = {0};
int count = 0;
pthread_spin_init(&spinlock, PTHREAD_PROCESS_PRIVATE);
int i = 0;
for (i = 0; i < THREAD_COUNT; i++) {
pthread_create(&tid[i], NULL, func, &count);
}
for (i = 0; i < 100; i++) {
printf("count --> %d\n", count);
sleep(1);
}
for (i = 0; i < THREAD_COUNT; i++) {
pthread_join(tid[i], NULL);
}
}
Comparison of usage scenarios of mutex and spinlock
- The operation of critical resources is simple / there is no system call. Select spinlock
- Complex operation / system call, select mutex.
It mainly depends on whether the operation is simpler or more complex than thread switching.
Read write lock
It is applicable to the scenario of more reading and less writing. Generally, the use of read-write lock is not recommended
Atomic operation
Use assembly instructions to realize + + i, and realize + + operation in one instruction through CPU instructions.
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define THREAD_COUNT 10
int inc(int *value, int add) {
int old;
/*
xaddl
Swap the first operand (destination operand) with the second operand (source operand), and then load the sum of the two values into the destination operand. The destination operand can be a register or memory location; the source operand is a register.
This instruction can be used with the LOCK prefix.
TEMP SRC + DEST
SRC DEST
DEST TEMP
*/
__asm__ volatile (
"lock; xaddl %2, %1;" // lock indicates that the bus of CPU operation memory is locked,% 2 represents add and% 1 represents * value
: "=a" (old) // output old=eax
: "m" (*value), "a" (add) // input m is the original memory. Put the add value into eax
: "cc", "memory"
);
return old;
}
void *func(void *arg) {
int *pcount = (int *)arg;
int i = 0;
for (i = 0; i < 100000; i++) {
inc(pcount, 1);
usleep(1);
}
}
int main() {
pthread_t tid[THREAD_COUNT] = {0};
int count = 0;
int i = 0;
for (i = 0; i < THREAD_COUNT; i++) {
pthread_create(&tid[i], NULL, func, &count);
}
for (i = 0; i < 100; i++) {
printf("count --> %d\n", count);
sleep(1);
}
for (i = 0; i < THREAD_COUNT; i++) {
pthread_join(tid[i], NULL);
}
}
lock is the bus on which the CPU operates the memory
Atomic operations require CPU instruction set support.
CAS(Compare and Swap)
CAS comparison and exchange is a kind of atomic operation, which compares first and then assigns a value
Compare And Swap
if (a == b) {
a = c;
}
cmpxchg(a, b, c)
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
return false ;
}The specific assembly code implementation can refer to the cas implementation in zmq lockless queue.

Implementation of atomic operation
- gcc and g + + compilers provide a set of atomic operation APIs;
- C++11 also provides a set of atomic operation APIs;
- It can also be implemented by assembly
summary
For complex situations, including file reading, socket operation and system call, mutex can be used;
The operation is relatively simple. If atomic operation is not supported, spinlock can be used;
Atomic operations can be used if the CPU instruction set supports them.
Thread switching consumes resources and costs a lot. Where is it reflected?
If it is only mov register, the cost is very small; In addition to register operation, thread switching also requires file system and virtual memory switching, so the cost is relatively high.
mutex, mutex_ The granularity of trylock and spinlock locks decreases in turn.
mutex is suitable for a long piece of code between lock execution, with the largest granularity, such as locking the whole number of B + or red black trees. If the lock cannot be obtained, the thread will be switched;
mutex_trylock attempts to obtain a lock and returns immediately. It does not switch threads. In an application, it is usually driven by a while loop, but because it is in the application layer, there may be thread switching.
spinlock keeps trying to obtain locks in the kernel without thread switching, and the granularity of locks is the smallest. Lock the CPU. The implementation of the underlying core code is a loop instruction. Constantly check whether the conditions are met and return only when the conditions are met.
How to judge the lock granularity?
If the execution time of the content to be locked is greater than the cost of thread switching, even if it is of large granularity, mutex can be used; If the execution time of the contents of the lock is very short, such as adding a few lines of code to a queue, even if the granularity is small, spinlock can be used.
If deadlock occurs, neither mutex nor spinlock can be used.
Atomic operation, with smaller granularity, depends on whether a single assembly instruction is supported.
rwlock, read-write lock, suitable for scenarios with more reading and less writing.