1. The Business Layer of MySQL Master-Slave Solution
In the previous articles, we mentioned that MySQL has brought some problems to the access of the upper business system under the mode of one master multi-slave cluster. In this article, we will analyze this problem in depth and introduce how to improve it. The main problem that MySQL master-slave cluster brings to the upper business system is that the upper business system needs to control which node in the MySQL cluster to access in this MySQL data operation. The main reason for this problem is that MySQL, a master-slave cluster, does not provide the existing performance by packaging the nodes in the cluster into a unified service and providing it to the outside world.
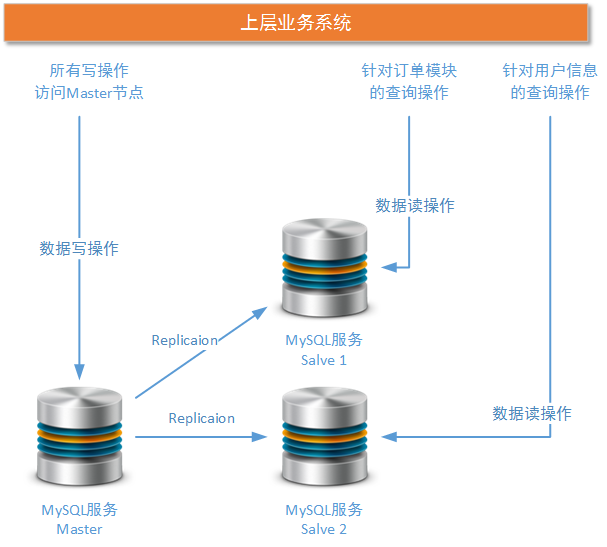
In the MySQL cluster shown above, one Master node is responsible for all the write transactions, and two Salve nodes are responsible for the read operations of the order module and the user module respectively. Because there is no middle management layer in this architecture, the decision of which MySQL service node to visit needs to be determined by the upper business system. Then the idea to solve this problem is clear: we need to add an intermediate layer for business layer access by some means to reduce the maintenance work of business developers.
2. Improvement 1: Shield details with Spring Suite
If your project uses Spring components, this problem can be improved with Spring configuration issues. But this way can only be regarded as a problem of improvement, not a complete solution to the problem. This is because although business developers do not need to worry about "which database node to access" after Spring configuration, Spring configuration file still exists in the business system. When the lower MySQL cluster node changes, the business system needs to change the configuration information and redeploy; when the existing MySQL cluster node fails, the upper business system Systems also need to change configuration information and redeploy. This configuration method can not achieve complete decoupling of data access logic.
Let's give an example, in which we use spring 3.X + hibernate 4.X + c3p0 + MySQL JDBC to implement the rule configuration of accessing database nodes in business systems.
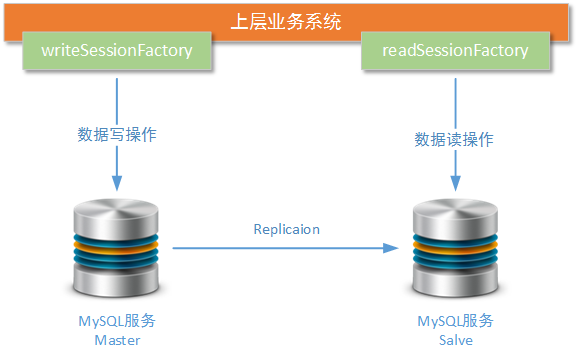
As shown in the figure above, we have established two data sources in the business system: writeSession Factory and readSession Factory, which are responsible for writing and reading business data respectively. When the following MySQL cluster adds new read nodes or the existing nodes in the cluster change, spring's configuration file also changes accordingly.
- Data Source and AOP Point Configuration for Write Operations
<!-- Engineering independent of separation of read and write data sources Spring Configuration information, not to be redundant here -->
......
<!-- This data source is connected to maseter Nodes, as data sources for write operations-->
<bean id="writedataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close">
<property name="driverClass"><value>${writejdbc.driver}</value></property>
<property name="jdbcUrl"><value>${writejdbc.url}</value></property>
<property name="user"><value>${writejdbc.username}</value></property>
<property name="password"><value>${writejdbc.password}</value></property>
<property name="minPoolSize"><value>${writec3p0.minPoolSize}</value></property>
<property name="maxPoolSize"><value>${writec3p0.maxPoolSize}</value></property>
<property name="initialPoolSize"><value>${writec3p0.initialPoolSize}</value></property>
<property name="maxIdleTime"><value>${writec3p0.maxIdleTime}</value></property>
<property name="acquireIncrement"><value>${writec3p0.acquireIncrement}</value></property>
</bean>
<!-- Mapping relationship between data layer session factory and data source -->
<bean id="writeSessionFactory" class="org.springframework.orm.hibernate4.LocalSessionFactoryBean">
<property name="dataSource" ref="writedataSource" />
<property name="namingStrategy">
<bean class="org.hibernate.cfg.ImprovedNamingStrategy" />
</property>
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">${writehibernate.dialect}</prop>
<prop key="hibernate.show_sql">${writehibernate.show_sql}</prop>
<prop key="hibernate.format_sql">${writehibernate.format_sql}</prop>
<prop key="hibernate.hbm2ddl.auto">${writehibernate.hbm2ddl.auto}</prop>
<prop key="hibernate.current_session_context_class">org.springframework.orm.hibernate4.SpringSessionContext</prop>
</props>
</property>
</bean>
<bean id="writetransactionManager" class="org.springframework.orm.hibernate4.HibernateTransactionManager">
<property name="sessionFactory" ref="writeSessionFactory" />
</bean>
<!--
AOP Set in templateSSHProject.dao.writeop In a package or subpackage
For methods with the following names, transaction hosting should be turned on.
And when any exception is thrown, spring Every transaction has to be rolled back
-->
<aop:config>
<aop:pointcut id="writedao" expression="execution(* templateSSHProject.dao.writeop..*.* (..))" />
<aop:advisor advice-ref="writetxAdvice" pointcut-ref="writedao" />
</aop:config>
<tx:advice id="writetxAdvice" transaction-manager="writetransactionManager">
<tx:attributes>
<tx:method name="save*" rollback-for="java.lang.Exception" propagation="REQUIRED" />
<tx:method name="update*" rollback-for="java.lang.Exception" propagation="REQUIRED" />
<tx:method name="delete*" rollback-for="java.lang.Exception" propagation="REQUIRED" />
<tx:method name="modify*" rollback-for="java.lang.Exception" propagation="REQUIRED" />
<tx:method name="create*" rollback-for="java.lang.Exception" propagation="REQUIRED" />
<tx:method name="remove*" rollback-for="java.lang.Exception" propagation="REQUIRED" />
<tx:method name="*" read-only="true" />
</tx:attributes>
</tx:advice>
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- Read operation involves data source and AOP point configuration, which is similar to write operation data source configuration. Readers only need to pay attention to different points.
......
<!-- This data source is connected to salve Nodes, as data sources for read operations -->
<bean id="readdataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close">
<property name="driverClass"><value>${readjdbc.driver}</value></property>
<property name="jdbcUrl"><value>${readjdbc.url}</value></property>
<property name="user"><value>${readjdbc.username}</value></property>
<property name="password"><value>${readjdbc.password}</value></property>
<property name="minPoolSize"><value>${readc3p0.minPoolSize}</value></property>
<property name="maxPoolSize"><value>${readc3p0.maxPoolSize}</value></property>
<property name="initialPoolSize"><value>${readc3p0.initialPoolSize}</value></property>
<property name="maxIdleTime"><value>${readc3p0.maxIdleTime}</value></property>
<property name="acquireIncrement"><value>${readc3p0.acquireIncrement}</value></property>
</bean>
<!-- The mapping relationship between the data layer session factory and the data source is basically and write The settings are consistent -->
<bean id="readSessionFactory" class="org.springframework.orm.hibernate4.LocalSessionFactoryBean">
<property name="dataSource" ref="readdataSource" />
<property name="namingStrategy">
<bean class="org.hibernate.cfg.ImprovedNamingStrategy" />
</property>
<property name="hibernateProperties">
<props>
<prop key="hibernate.dialect">${readhibernate.dialect}</prop>
<prop key="hibernate.show_sql">${readhibernate.show_sql}</prop>
<prop key="hibernate.format_sql">${readhibernate.format_sql}</prop>
<prop key="hibernate.hbm2ddl.auto">${readhibernate.hbm2ddl.auto}</prop>
<prop key="hibernate.current_session_context_class">org.springframework.orm.hibernate4.SpringSessionContext</prop>
</props>
</property>
</bean>
<bean id="readtransactionManager" class="org.springframework.orm.hibernate4.HibernateTransactionManager">
<property name="sessionFactory" ref="readSessionFactory" />
</bean>
<!--
AOP The difference between settings and write operation transactions is also here
There is no need to set any method to open transaction hosting
You don't even need to configure this section AOP section
-->
<aop:config>
<aop:pointcut id="readdao" expression="execution(* templateSSHProject.dao.readop..*.* (..))" />
<aop:advisor advice-ref="readtxAdvice" pointcut-ref="readdao" />
</aop:config>
<tx:advice id="readtxAdvice" transaction-manager="readtransactionManager">
<tx:attributes>
<tx:method name="*" read-only="true" />
</tx:attributes>
</tx:advice>
......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
-
To understand the Spring configuration information above, first make sure that you have been exposed to Spring components. The above configuration mainly uses XML file definition to specify the method names that need to use "write data source", and uses AOP aspect to open transaction hosting for these specified method names. In the actual use process, you can also use Java code annotations to mark the method that needs to open transaction hosting within the specified package scope. Simply add a note in the configuration file "<tx: annotation-driven transaction-manager=" writetransaction Manager" proxy-target-class="false"/>"
-
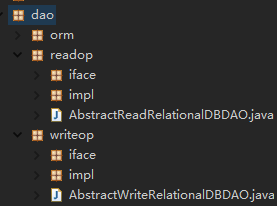
Such a way of separating read and write data sources will only affect the operation of business developers in the data layer, and has no impact on the display layer and business logic layer. This paper also gives the package structure of the data layer in the project, which is related to the expression of the section scanning point in AOP configuration. From the structure diagram given below, it can be seen that the data read and write operations in the data layer are separated, so as to avoid confusion when business developers write code (for example, write operations in the engineering package responsible for reading operations).
-
Of course, for each reader's own business form, you can also combine the two data sources, but this may aggravate the maintenance work of business developers. The way to merge read and write operation data sources is also simple, basically without changing any configuration, just injecting two sessionFactories into the same AbstractRelational DBDAO, the common parent set for the DAO layer.
...... public abstract class AbstractReadRelationalDBDAO ...... { // Other parts of the AbstractRelational DBDAO class are omitted ...... @Autowired @Qualifier("readSessionFactory") private SessionFactory readSessionFactory; @Autowired @Qualifier("writeSessionFactory") private SessionFactory sessionFactory; ...... } ......- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
-
The Spring configuration implemented in this example has only one data source responsible for write operations and one data source responsible for read operations. So theoretically, this Spring configuration can only be adapted to the MySQL cluster with one master and one slave. When a node in MySQL cluster occurs, such as adding a Salve slave node, business engineering adds a slave node's data source configuration information and adds new code packages to the data layer (DAO layer) of the project. This is obviously very problematic, and even the whole business engineering can hardly be maintained. This is because a stable MySQL cluster can only guarantee the availability of 5.9 systems (99.999%). In addition, the mainstream cluster idea is to assume that the nodes in the cluster may have problems at any time, while the business system obviously can not change the allocation at any time in unpredictable circumstances. Set up information and redeploy it.
3. Improvement Mode 2: Transparent Intermediate Layer
So is there any way to solve the above problems? It not only breaks through the bottleneck of the above Spring configuration mode only adapts to the MySQL cluster of one master and one slave, but also does not increase the maintenance difficulty of business developers. It also adapts to the node failures that occur at any time in the lower data group. Of course, there is a way. Using LVS, which we have already introduced in the load balancing topic, we can construct a transparent layer for multiple read nodes in MySQL cluster, so that they can be used as a whole, and provide data reading services to the upper business system with a unified access address.
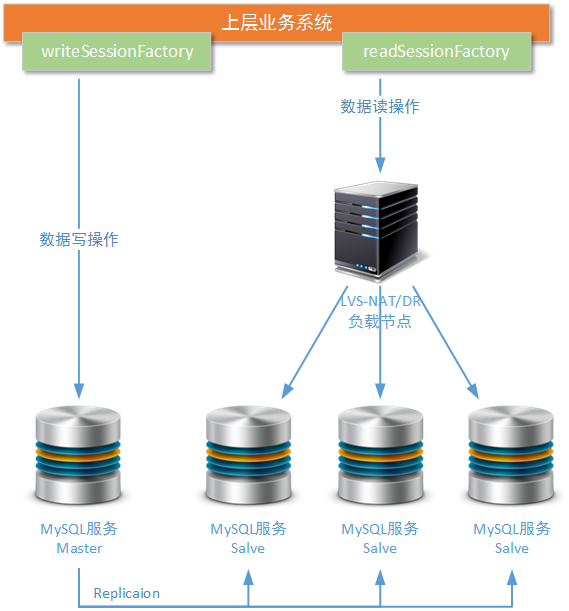
If you don't know how to configure LVS, you can refer to several articles in my other topic that specifically introduce LVS:< Architecture Design: Load Balancing Layer Design (4) - LVS Principle>,<Architecture Design: Load Balancing Layer Design (5) - LVS Single Node Installation " It should be noted that the load scheme chosen here should work in the lower layer of the network protocol, such as the link layer or the transport layer of the OSI seven-layer model. This is because most of MySQL client software (MySQL-Front, Navicat, etc.) uses MySQL native connection protocol, which is based on TCP/IP protocol, and most Java applications connect and invoke MySQL operations based on JDBC. API is also based on TCP/IP protocol. So the load balancing scheme used here can not use Nginx, which only supports Http protocol, while LVS components can meet the technical requirements very well.
In the above improvement scheme, we only improve the read operation nodes in MySQL cluster, but the whole cluster still does not have enough stability guarantee. This is because there is only a single node in the MySQL cluster for write operation, and only a single node for the newly added LVS load node. If these nodes fail to work in production environment, the whole MySQL cluster will collapse. Further improvement is to add hot standby schemes for write operation nodes and LVS load nodes in the cluster, as shown in the following figure:
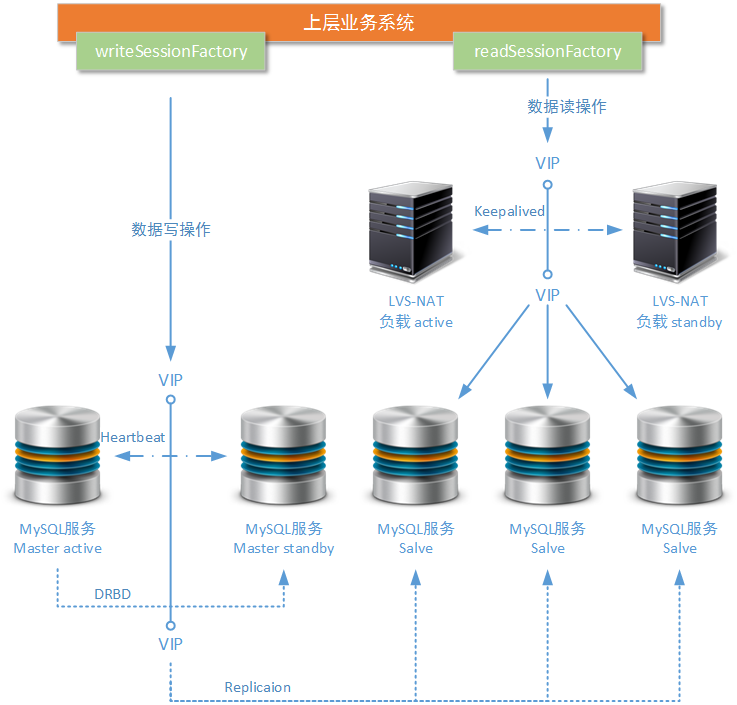
-
In the figure above, we use Heartbeat + DRBD third-party components to replicate a standby node in the "ready" state for MySQL Master nodes that can be switched instantly. The Heartbeat component is similar to the keepalived component we introduced before. It is used to monitor the working status of two (or more) nodes, and to complete the switching of floating IP and the start of standby services when the downtime condition is satisfied. DRBD component is a disk block mapping software which works under Linunx system and can complete real-time file differentiation and synchronization. Similar software is RSync.
-
With the support of Heartbeat + DRBD third-party component, it can ensure that when the write operation node in MySQL cluster can not provide services, another backup write operation node waiting for work can receive the work task in time, and the database table data on this backup node is consistent with the database table data on the previous crashed write operation node. This solution can also be replaced by Keepalived + RSync's third-party component solution.
-
High availability schemes for LVS nodes have been described in previous articles. An unclear reader may refer to another article of mine.< Architecture Design: Load Balancing Layer Design (7) - LVS+ Keepalived + Nginx Installation and Configuration It's just that the components in the article that need to be guaranteed high availability have been replaced by Nginx with MySQL services. However, there are also some problems in this way: although these read nodes can share their work pressure through load balancing, these read operation nodes can not provide independent and personalized query operation services according to the different business of the upper layer.