ConcurrentHashMap
In jdk1 The specific implementation in 7 and 1.8 is slightly different
jdk1.7
As shown in the figure, it is composed of Segment array and HashEntry. Like HashMap, it is still array plus linked list.
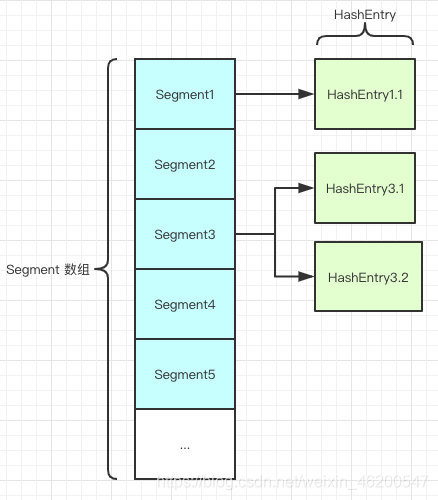
Segment is an internal class of ConcurrentHashMap. Its main components are as follows:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// The function of HashEntry in HashMap is the same as that of the bucket for storing data
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
// size
transient int threshold;
// Load factor
final float loadFactor;
}
The initialization of ConcurrentHashMap initializes the size of the Segment through bit and operation, represented by ssize. The source code is as follows
private static final int DEFAULT_CONCURRENCY_LEVEL = 16;
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
// For serialization compatibility
// Emulate segment calculation from previous version of this class
int sshift = 0;
int ssize = 1;
while (ssize < DEFAULT_CONCURRENCY_LEVEL) {
++sshift;
ssize <<= 1;
}
int segmentShift = 32 - sshift;
int segmentMask = ssize - 1;
It can be seen that ssize is calculated by location operation (ssize < < = 1), so the size of the Segment is taken to the nth power of 2, regardless of the value of concurrency level. Of course, the maximum concurrency level can only be expressed in 16 bit binary, that is, 65536. In other words, the maximum size of the Segment is 65536, and the concurrency level element initialization is not specified. The size of the Segment ssize defaults to DEFAULT_CONCURRENCY_LEVEL =16
HashEntry is similar to HashMap, but the difference is that it uses volatile to modify its data Value and the next node.
In principle, ConcurrentHashMap adopts Segment lock technology, in which Segment inherits ReentrantLock.
Unlike HashTable, both put and get operations need to be synchronized. Theoretically, ConcurrentHashMap supports thread concurrency of currencylevel (number of segment arrays).
Every time a thread accesses a Segment using a lock, it will not affect other segments.
public V put(K key, V value) {
Segment<K,V> s;
//Value cannot be empty
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
He first locates the Segment and then performs the put operation.
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// Locate the table in the current Segment to the HashEntry through the hashcode of the key
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// Traverse the HashEntry. If it is not empty, judge whether the passed key is equal to the currently traversed key. If it is equal, overwrite the old value.
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// If it is not empty, you need to create a HashEntry and add it to the Segment. At the same time, you will first judge whether you need to expand the capacity.
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//Release lock
unlock();
}
return oldValue;
}
First, in the first step, you will try to obtain the lock. If the acquisition fails, there must be competition from other threads. Then you can use scanAndLockForPut() to spin to obtain the lock.
Try to acquire the lock.
If the number of retries reaches max_ SCAN_ Restries is changed to block lock acquisition to ensure success.
The get logic is relatively simple. You only need to locate the Key to the specific Segment through the Hash, and then locate the Key to the specific element through the Hash.
Because the value attribute in HashEntry is decorated with volatile keyword to ensure memory visibility, it is the latest value every time it is obtained.
The get method of ConcurrentHashMap is very efficient because the whole process does not need to be locked.
Advantages and disadvantages of this structure
benefit
During the write operation, you can lock only the Segment where the element is located without affecting other segments. In this way, in the most ideal case, ConcurrentHashMap can support the maximum number and size of segments at the same time (just these write operations are evenly distributed among all segments).
Therefore, through this structure, the concurrency of ConcurrentHashMap can be greatly improved.
Disadvantages
The side effect of this structure is that the process of Hash is longer than that of ordinary HashMap
jdk1.8
The original Segment lock is abandoned and CAS + synchronized is used to ensure concurrency security.
Much like HashMap, it also changes the previous HashEntry to Node, but the function remains unchanged. It modifies the value and next with volatile to ensure visibility. It also introduces red black tree, which will be converted when the linked list is greater than a certain value (8 by default).
The put operation of ConcurrentHashMap is still complex, which can be roughly divided into the following steps:
Calculate the hashcode according to the key.
Determine whether initialization is required.
That is, the Node located by the current key. If it is empty, it means that data can be written in the current position. If CAS attempts to write, it will be successful.
If hashcode == MOVED == -1 in the current location, capacity expansion is required.
If they are not satisfied, the synchronized lock is used to write data.
If the quantity is greater than tree_ Threshold is converted to a red black tree.
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
//Calculate the hashcode according to the key.
int hash = spread(key.hashCode());
int binCount = 0;
//Iterate over this table
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh;
//Here, the above construction method is not initialized. Judge here. If it is null, call initTable for initialization, which belongs to lazy mode initialization
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//That is, the Node located by the current key. If it is empty, it means that data can be written in the current position. If CAS attempts to write, it will be successful.
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
//If hashcode == MOVED == -1 in the current location, capacity expansion is required.
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//If they are not satisfied, then the lock operation must be carried out, that is, there is a hash conflict to lock the head node of the linked list or red black tree
synchronized (f) {
if (tabAt(tab, i) == f) {
//Indicates that the node is a linked list structure
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//If the same key is involved, put ting will overwrite the original value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
//Insert end of linked list
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
//Red black tree structure
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
//Red black tree structure rotation insertion
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) {
// If the quantity is greater than tree_ Threshold is converted to a red black tree.
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
//Count the size and check whether it needs to be expanded
addCount(1L, binCount);
return null;
}
get method
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode());
//According to the calculated hashcode addressing, if it is on the bucket, the value is returned directly.
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//If it is a red black tree, get the value as a tree.
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//A negative hash value indicates that the capacity is being expanded. At this time, the find method of ForwardingNode is queried to locate the nextTable
//Find, find and return
//If it is not satisfied, traverse and obtain the value according to the linked list.
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}