❤ Write in front
❤ Blog home page: Hard working Naruto
❤ Series column: Java basic learning 😋
❤ Welcome, friends, praise 👍 follow 🔎 Collection 🍔 Learning together!
❤ If there are mistakes, please correct them! 🌹
about [Chapter 10 Java collection] several brain maps take you into the brainstorming of Java collection 🔥 Extended analysis of

1, HashMap
Look at the portal 🔥 >>> In depth analysis of HashMap
2, LinkHashMap
HashMap is out of order. The order of elements obtained by iterating HashMap is not the order in which they were initially placed in HashMap. This disadvantage will cause a lot of inconvenience. In many scenarios, a Map that can maintain the insertion order is needed. JDK solves this problem and provides a subclass > > > LinkedHashMap for HashMap. By maintaining a two-way linked list running on all items, LinkedHashMap ensures the iterative order of elements, which can be insertion order or access order
In fact, LinkedHashMap is a HashMap plus a two-way linked list. It is a HashMap that links all Entry nodes into a two-way linked list. The entries of put are placed in the hash table and also in a two-way linked list with head as the head node (set the iteration order), as shown in the figure
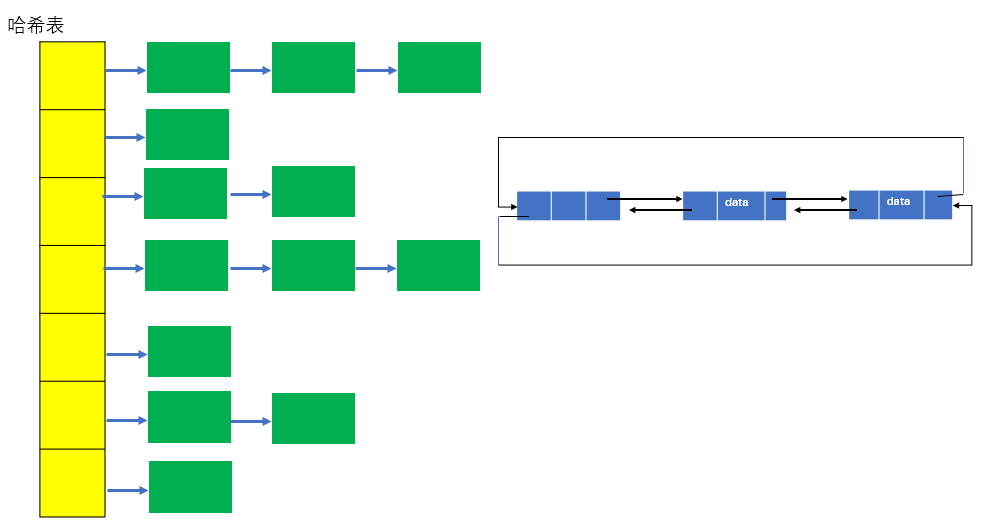
🔥 Basic structure
- class
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V> {
...
}
- Member variable
Two variables are added, the header of the two-way Chain header node and the flag bit accessOrder (when the value is true, it means to iterate according to the access order; when the value is false, it means to iterate according to the insertion order)
/**
* The head of the doubly linked list.
*/
private transient Entry<K,V> header; // Header element of bidirectional linked list
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
private final boolean accessOrder; //true means to iterate according to the access order, and false means to insert according to the insertion order
- Construction method
By default, these construction methods adopt the insertion order to maintain the order of extracting key value pairs. All construction methods create objects by calling the construction method of the parent class
// Construction method 1: construct a LinkedList that specifies the initial capacity and load factor and is inserted in order
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// Construction method 2: construct a LinkedHashMap with specified initial capacity, and the order of obtaining key value pairs is the insertion order
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// Construction method 3: create a LinkedHashMap with the default initialization capacity and load factor, and the order of obtaining key value pairs is the insertion order
public LinkedHashMap() {
super();
accessOrder = false;
}
// Construction method 4: create a LinkedHashMap through the incoming map. The capacity is the default capacity (16) and (map. Zise() / default)_ LOAD_ The larger of factory) + 1, the loading factor is the default value
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// Construction method 5: create a LinkedHashMap according to the specified capacity, loading factor and key value pair maintenance order
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
- Entry
LinkHashMap redefines the Entry. The Entry in LinkedHashMap adds two pointers before and after, which are respectively used to maintain the two-way link list. It should be noted that next is used to maintain the connection order of entries in each bucket of HashMap, and before and after are used to maintain the insertion order of entries
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}

🔥 Fast access
put(Key,Value) and get(Key)
LinkedHashMap fully inherits the put(Key,Value) method of HashMap
LinkedHashMap directly overrides the get(Key) method
/**
* Associates the specified value with the specified key in this map.
* If the map previously contained a mapping for the key, the old
* value is replaced.
*
* @param key key with which the specified value is to be associated
* @param value value to be associated with the specified key
* @return the previous value associated with key, or null if there was no mapping for key.
* Note that a null return can also indicate that the map previously associated null with key.
*/
public V put(K key, V value) {
//When the key is null, call putForNullKey method and save the key value pair to the first position of table
if (key == null)
return putForNullKey(value);
//Calculate the hash value according to the hashCode of the key
int hash = hash(key.hashCode());
//Calculate the storage position of the key value pair in the array (which bucket)
int i = indexFor(hash, table.length);
//Iterate on the ith bucket of the table to find the location where the key is saved
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
//Judge whether there is a mapping with the same hash value and the same key value on the chain. If so, directly overwrite the value and return the old value
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this); // LinkedHashMap overrides the recordAccess method in Entry -- - (1)
return oldValue; // Return old value
}
}
modCount++; //The number of modifications is increased by 1, fast failure mechanism
//There is no such Map in the original Map. Add it to the chain head of the chain
addEntry(hash, key, value, i); // LinkedHashMap overrides the createEntry method in the HashMap -- (2)
return null;
}
The above is the data saving process of LinkedHashMap and HashMap. In LinkedHashMap, the addEntry method and the recordAccess method of Entry are rewritten. The comparison between LinkedHashMap and the addEntry method of HashMap shows its implementation:
LinkedHashMap maintains the insertion order
/**
* This override alters behavior of superclass put method. It causes newly
* allocated entry to get inserted at the end of the linked list and
* removes the eldest entry if appropriate.
*
* LinkedHashMap addEntry method in
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//Create a new Entry and insert it into the LinkedHashMap
createEntry(hash, key, value, bucketIndex); // Overriding the createEntry method in HashMap
//The first valid node of the two-way linked list (the node after the header) is the most recently used node, which is used to support the LRU algorithm
Entry<K,V> eldest = header.after;
//If necessary, delete the least recently used node,
//This depends on the override of removeEldestEntry. Since the default is false, no processing is done by default.
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
//Double the original capacity
if (size >= threshold)
resize(2 * table.length);
}
}
******************************************************************************
/**
* Adds a new entry with the specified key, value and hash code to
* the specified bucket. It is the responsibility of this
* method to resize the table if appropriate.
*
* Subclass overrides this to alter the behavior of put method.
*
* HashMap addEntry method in
*/
void addEntry(int hash, K key, V value, int bucketIndex) {
//Get the Entry at bucketIndex
Entry<K,V> e = table[bucketIndex];
//Put the newly created Entry into the bucket index and point the new Entry to the original Entry
table[bucketIndex] = new Entry<K,V>(hash, key, value, e);
//If the number of elements in the HashMap exceeds the limit, the capacity will be doubled
if (size++ >= threshold)
resize(2 * table.length);
}
Take a look at the rewritten createEntry method:
void createEntry(int hash, K key, V value, int bucketIndex) {
// Insert an Entry into the hash table, which is the same as in HashMap
//Create a new Entry and chain it to the head node of the linked list of the bucket corresponding to the array,
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//Each time an Entry is inserted into the hash table, it will be inserted into the tail of the two-way linked list,
//In this way, the elements are iterated according to the order in which the Entry is inserted into the LinkedHashMap (LinkedHashMap rewrites the iterator according to the two-way linked list)
//At the same time, the newly put Entry is the recently accessed Entry, which is placed at the end of the linked list, which is also in line with the implementation of LRU algorithm
e.addBefore(header);
size++;
}
addBefore method source code:
Is a two-way linked list insertion operation
//In a two-way linked list, insert the current Entry in front of the existing Entry (header)
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
🔥 Capacity expansion
resize()
With the increasing number of elements in HashMap, the probability of collision will be greater and greater, and the length of the generated sub chain will be longer and longer, which is bound to affect the access speed of HashMap. In order to ensure the efficiency of HashMap, the system must expand the capacity at a critical point, which is that the number of elements in HashMap is numerically equal to threshold (table array length * loading factor). However, it has to be said that capacity expansion is a very time-consuming process, because it needs to recalculate the position of these elements in the new table array and copy them. Therefore, if we can predict the number of elements in HashMap in advance, the preset number of elements can effectively improve the performance of HashMap when constructing HashMap
- Source code of resize() method:
/**
* Rehashes the contents of this map into a new array with a
* larger capacity. This method is called automatically when the
* number of keys in this map reaches its threshold.
*
* If current capacity is MAXIMUM_CAPACITY, this method does not
* resize the map, but sets threshold to Integer.MAX_VALUE.
* This has the effect of preventing future calls.
*
* @param newCapacity the new capacity, MUST be a power of two;
* must be greater than current capacity unless current
* capacity is MAXIMUM_CAPACITY (in which case value
* is irrelevant).
*/
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
// If the oldCapacity has reached the maximum value, directly set the threshold to integer MAX_ VALUE
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return; // Direct return
}
// Otherwise, create a larger array
Entry[] newTable = new Entry[newCapacity];
//Re hash each Entry into a new array
transfer(newTable); //LinkedHashMap rewrites the transfer method it calls
table = newTable;
threshold = (int)(newCapacity * loadFactor); // Reset threshold
}
LinkedHashMap fully inherits the resize() method of HashMap. The core of Map expansion operation is re hashing, which refers to the process of recalculating the position of elements in the original HashMap in the new table array and copying. LinkedHashMap rewrites the re hashing process (transfer method)
The source code is as follows:
/**
* Transfers all entries to new table array. This method is called
* by superclass resize. It is overridden for performance, as it is
* faster to iterate using our linked list.
*/
void transfer(HashMap.Entry[] newTable) {
int newCapacity = newTable.length;
// Compared with HashMap, re hashing with the help of the characteristics of two-way linked list makes the code more concise
for (Entry<K,V> e = header.after; e != header; e = e.after) {
int index = indexFor(e.hash, newCapacity); // Calculate the bucket of each Entry
// Chain it into the linked list in the bucket
e.next = newTable[index];
newTable[index] = e;
}
}
LinkedHashMap easily realizes the re hashing operation with the help of its own two-way linked list
3, TreeMap
TreeMap is ordered
- attribute
//Comparator, because TreeMap is ordered, we can precisely control the internal sorting of TreeMap through the comparator interface
private final Comparator<? super K> comparator;
//TreeMap red black node, which is the internal class of TreeMap
private transient Entry<K,V> root = null;
//Container size
private transient int size = 0;
//TreeMap modification times
private transient int modCount = 0;
//Node color of red black tree -- red
private static final boolean RED = false;
//Node color of red black tree -- black
private static final boolean BLACK = true;
- The leaf node Entry is an internal class of TreeMap. Its properties are as follows:
//key
K key;
//value
V value;
//Left child
Entry<K,V> left = null;
//Right child
Entry<K,V> right = null;
//father
Entry<K,V> parent;
//colour
boolean color = BLACK;
🔥 data structure
public class TreeMap<K,V>
extends AbstractMap<K,V>
implements NavigableMap<K,V>, Cloneable, java.io.Serializable
TreeMap inherits AbstractMap and implements NavigableMap, Cloneable and Serializable interfaces. AbstractMap indicates that TreeMap is a Map, that is, a collection that supports key values
🔥 Core method
put()
Code implementation of put method:
public V put(K key, V value) {
//t represents the current node of the binary tree
Entry<K,V> t = root;
//t null indicates an empty tree, that is, there are no elements in the TreeMap, which can be inserted directly
if (t == null) {
//Comparing key values, I think this code has no meaning. Do you still need to compare and sort empty trees?
compare(key, key); // type (and possibly null) check
//Create a new key value pair as an Entry node and assign the node to root
root = new Entry<>(key, value, null);
//The size of the container = 1, indicating that there is an element in the TreeMap collection
size = 1;
//Modification times + 1
modCount++;
return null;
}
int cmp; //cmp indicates the returned result of key sorting
Entry<K,V> parent; //Parent node
// split comparator and comparable paths
Comparator<? super K> cpr = comparator; //Specified sorting algorithm
//If cpr is not empty, the established sorting algorithm is used to create the TreeMap set
if (cpr != null) {
do {
parent = t; //parent points to t after the last cycle
//Compare the size of the key of the new node with that of the current node
cmp = cpr.compare(key, t.key);
//If the returned value of cmp is less than 0, it means that the key of the new node is less than the key of the current node, then the left child node of the current node is taken as the new current node
if (cmp < 0)
t = t.left;
//If the returned value of cmp is greater than 0, it means that the key of the new node is greater than the key of the current node, then the right child node of the current node is taken as the new current node
else if (cmp > 0)
t = t.right;
//The returned value of cmp is equal to 0, which means that the two key values are equal. Then the new value overwrites the old value and returns a new value
else
return t.setValue(value);
} while (t != null);
}
//If cpr is empty, the default sorting algorithm is used to create the TreeMap set
else {
if (key == null) //An exception is thrown when the key value is empty
throw new NullPointerException();
/* The following process is the same as above */
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
//Treat the new node as the child node of the parent
Entry<K,V> e = new Entry<>(key, value, parent);
//If the key of the new node is less than the key of the parent, it will be regarded as the left child node
if (cmp < 0)
parent.left = e;
//If the key of the new node is greater than that of the parent, it will be regarded as the right child node
else
parent.right = e;
/*
* The construction of sorting binary tree has been completed above. Insert the new node into the appropriate position in the tree
* The following fixAfterInsertion() method is to adjust and balance the tree. Refer to the above five cases for the specific process
*/
fixAfterInsertion(e);
//Number of TreeMap elements + 1
size++;
//TreeMap container modification times + 1
modCount++;
return null;
}
- Get the root node. If the root node is empty, a root node will be generated, colored black, and exit the rest of the process
- Get the Comparator. If the incoming Comparator interface is not empty, use the incoming Comparator interface implementation class for comparison; If the incoming Comparator interface is empty, the Key is forcibly converted to a Comparable interface for comparison
- Start from the root node and compare one by one according to the specified sorting algorithm. Take the comparison value temp. For example, temp=0, indicating that the inserted Key already exists; If temp > 0, take the right child node of the current node; If temp < 0, take the left child node of the current node
- Excluding the existence of the inserted Key, the comparison in step (3) is until the left child node or right child node of the current node T is null. At this time, t is the node we find. If temp > 0, we are ready to insert a new node into the right child node of T, and if temp < 0, we are ready to insert a new node into the left child node of T
- New displays a new node, which is black by default. It is inserted to the left or right of t according to the value of cmp
- Repair after insertion, including left-hand rotation, right-hand rotation and re coloring, to keep the tree balanced. There is no problem in steps 1 to 5. The core of red black tree should be the repair after inserting data in step 6, and the corresponding Java code is fixAfterInsertion method in TreeMap
🎁 Conclusion: I don't know if it's an in-depth analysis. Anyway, it took me a lot of hair and a lot of time
👌 The author is a Java beginner. If there are errors in the article, please comment and correct them in private letters and learn together~~
😊 If the article is useful to the friends, please praise it 👍 follow 🔎 Collection 🍔 Is my biggest motivation!
🚩 Step by step, nothing to a thousand miles, book next time, welcome to see you again 🌹