Okhttp interceptor details
Okhttp interceptor introduction
Concept: interceptor is a powerful mechanism provided in Okhttp. It can realize network monitoring, request and response rewriting, request failure retry and other functions. Let's first understand the system interceptor in Okhttp:
- RetryAndFollowUpInterceptor: it is responsible for implementing the retry redirection function when the request fails.
- BridgeInterceptor: converts the request constructed by the user into the request sent to the server, and converts the response returned by the server into a user-friendly response.
- CacheInterceptor: read cache and update cache.
- ConnectInterceptor: establish a connection with the server.
- CallServerInterceptor: reads the response from the server.
1. Working principle of interceptor
In the last article, we mentioned that the core of obtaining the network request response is the getResponseWithInterceptorChain() method. From the name of the method, we can also see that the response is obtained through the interceptor chain. The design pattern of responsibility chain is adopted in Okhttp to realize the interceptor chain. It can set any number of interceptors to do any intermediate processing for network requests and their responses, such as setting cache, Https certificate authentication, unified request encryption / tamper proof society, printing log, filtering requests, etc.
Responsibility chain mode: in the responsibility chain mode, each object is connected with the reference of its next family to form a chain. Requests are passed along the chain until an object in the chain decides to process the request. The customer doesn't know which object in the chain will eventually process the request. The customer only needs to send the request to the responsibility chain without paying attention to the processing details of the request and the transmission of the request. Therefore, the responsibility chain decouples the sender of the request from the handler of the request.
Next, let's learn more about the method getResponseWithInterceptorChain():
Response getResponseWithInterceptorChain() throws IOException {
// Build a full stack of interceptors.
List<Interceptor> interceptors = new ArrayList<>();
//Add a user-defined interceptor to the interceptor chain and execute it before the system default interceptor
interceptors.addAll(client.interceptors());
//Add retry redirect interceptor
interceptors.add(retryAndFollowUpInterceptor);
//Add a bridge interceptor, in which many request headers and parse response headers are added by default
interceptors.add(new BridgeInterceptor(client.cookieJar()));
//Add a cache interceptor to return a response from the cache as needed
interceptors.add(new CacheInterceptor(client.internalCache()));
//Add connection interceptor
interceptors.add(new ConnectInterceptor(client));
if (!forWebSocket) {
interceptors.addAll(client.networkInterceptors());
}
//Send the request and get the response data
interceptors.add(new CallServerInterceptor(forWebSocket));
//Create interceptor chain
Interceptor.Chain chain = new RealInterceptorChain(
interceptors, null, null, null, 0, originalRequest);
//Execute specific requests through interceptors
return chain.proceed(originalRequest);
}
From the code, we can see that we first created a List set, the generic type is Interceptor, that is, Interceptor, and then created a series of system interceptors (the five interceptors introduced at the beginning) and our customized interceptors (client.interceptors() and client. Interceptors) Networkinterceptors ()) and add it to the collection, then build the Interceptor chain RealInterceptorChain, and finally start the whole process of obtaining the server response by executing the processed () method of the Interceptor chain. This method is also the core of the whole Interceptor chain. Next, let's take a look at the processed () method in RealInterceptorChain.
public Response proceed(Request request, StreamAllocation streamAllocation, HttpCodec httpCodec,
RealConnection connection) throws IOException {
if (index >= interceptors.size()) throw new AssertionError();
calls++;
......
// Call the next interceptor in the chain.
// The next interceptor in the call chain. index+1 represents the index of the next interceptor
RealInterceptorChain next = new RealInterceptorChain(interceptors, streamAllocation, httpCodec,
connection, index + 1, request, call, eventListener, connectTimeout, readTimeout,
writeTimeout);
// Take out the interceptor to be called
Interceptor interceptor = interceptors.get(index);
// Call the intercept method of each interceptor
Response response = interceptor.intercept(next);
......
return response;
}
The core of the proceed() method is to create the next interceptor. First, we create an interceptor and set index = index+1. Then we take out the current corresponding interceptor from the interceptors collection where the interceptor is stored according to the index and call the intercept() method in the interceptor. In this way, when the next interceptor wants its next level to continue processing the request, it can call the processed () method of the incoming responsibility chain.
2. RetryAndFollowUpInterceptor retry redirection interceptor
RetryAndFollowUpInterceptor: retry redirection interceptor, which is responsible for retrying when the request fails and automatic subsequent requests for redirection. But not all failed requests can be reconnected.
Check the intercept method in RetryAndFollowUpInterceptor as follows:
@Override public Response intercept(Chain chain) throws IOException {
Request request = chain.request();
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Call call = realChain.call();
EventListener eventListener = realChain.eventListener();
// Create streamalallocation
StreamAllocation streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(request.url()), call, eventListener, callStackTrace);
this.streamAllocation = streamAllocation;
int followUpCount = 0;
Response priorResponse = null;
// Enter cycle
while (true) {
// Determine whether to cancel the request
if (canceled) {
streamAllocation.release();
throw new IOException("Canceled");
}
Response response;
boolean releaseConnection = true;
try {
// [1] . send the request to the next interceptor. Exceptions may occur during execution
response = realChain.proceed(request, streamAllocation, null, null);
releaseConnection = false;
} catch (RouteException e) {
// The attempt to connect via a route failed. The request will not have been sent.
// [2] . the routing connection fails, and the request will not be sent again
// In the recover method, it will judge whether to retry. If not, an exception will be thrown
// At the beginning, we mentioned that not all failures can be reconnected. The specific requests that can be reconnected are in this recover method.
if (!recover(e.getLastConnectException(), streamAllocation, false, request)) {
throw e.getFirstConnectException();
}
releaseConnection = false;
// If the retry conditions are met, continue to reconnect
continue;
} catch (IOException e) {
// An attempt to communicate with a server failed. The request may have been sent.
// [3] . the attempt to communicate with the server fails, and the request will not be sent again
boolean requestSendStarted = !(e instanceof ConnectionShutdownException);
if (!recover(e, streamAllocation, requestSendStarted, request)) throw e;
releaseConnection = false;
// If the retry conditions are met, continue to reconnect
continue;
} finally {
// We're throwing an unchecked exception. Release any resources.
if (releaseConnection) {
streamAllocation.streamFailed(null);
streamAllocation.release();
}
}
// Attach the prior response if it exists. Such responses never have a body.
if (priorResponse != null) {
response = response.newBuilder()
.priorResponse(priorResponse.newBuilder()
.body(null)
.build())
.build();
}
Request followUp;
try {
// [4] . in the followUpRequest, you will judge whether redirection is needed. If redirection is needed, you will return a Request for redirection
followUp = followUpRequest(response, streamAllocation.route());
} catch (IOException e) {
streamAllocation.release();
throw e;
}
// followUp == null indicates that redirection is not performed and response is returned
if (followUp == null) {
streamAllocation.release();
return response;
}
closeQuietly(response.body());
// [5] The maximum number of redirects is 20
if (++followUpCount > MAX_FOLLOW_UPS) {
streamAllocation.release();
throw new ProtocolException("Too many follow-up requests: " + followUpCount);
}
if (followUp.body() instanceof UnrepeatableRequestBody) {
streamAllocation.release();
throw new HttpRetryException("Cannot retry streamed HTTP body", response.code());
}
// Recreate the streamalallocation instance
if (!sameConnection(response, followUp.url())) {
streamAllocation.release();
streamAllocation = new StreamAllocation(client.connectionPool(),
createAddress(followUp.url()), call, eventListener, callStackTrace);
this.streamAllocation = streamAllocation;
} else if (streamAllocation.codec() != null) {
throw new IllegalStateException("Closing the body of " + response
+ " didn't close its backing stream. Bad interceptor?");
}
// Reassign to cycle
request = followUp;
priorResponse = response;
}
}
Class introduction
Streamalallocation: maintains the relationship between server connections, concurrent Streams and requests (connections, Streams and Calls). It can find connections and establish Streams for one request, so as to complete remote communication. Not used in the current method, they will be passed to the subsequent interceptor to obtain the response of the request from the server.
HttpCodec: defines the method of operating request and parsing response. The implementation classes are Http1Codec and Http2Codec, which correspond to http1 X and Http2 protocols.
It can be seen that there is no special processing for the Request in the RetryAndFollowUpInterceptor, so the Request is sent to the next interceptor. After receiving the Response returned by the subsequent interceptor, the RetryAndFollowUpInterceptor mainly judges whether to retry or redirect according to the content of the Response.
2.1 retry request
According to [2] and [3], it can be concluded that if RouteException or IOException occurs during the request period, it will judge whether to re initiate the request. These two exceptions are judged according to recover(). If recover() returns true, it means that it can be retried. Let's take a look at what operations are done in the recover() method.
private boolean recover(IOException e, StreamAllocation streamAllocation,
boolean requestSendStarted, Request userRequest) {
streamAllocation.streamFailed(e);
// 1. When OkhttpClient is configured, it is set that retry is not allowed (allowed by default). Once the request fails, it will not be retried
//The application layer has forbidden retries.
if (!client.retryOnConnectionFailure()) return false;
// 2. If it is RouteException, the value of requestSendStarted is false, so you don't need to care
//We can't send the request body again.
if (requestSendStarted && userRequest.body() instanceof UnrepeatableRequestBody)
return false;
//todo 3. Judge whether it is an exception of retry
//This exception is fatal.
if (!isRecoverable(e, requestSendStarted)) return false;
//todo 4. There are no more routes
//No more routes to attempt.
if (!streamAllocation.hasMoreRoutes()) return false;
// For failure recovery, use the same route selector with a new connection.
return true;
}
1. We can configure whether retry is allowed in OkhttpClient. If retry is not allowed, the retry operation will not be carried out after the request is abnormal.
2. If it is RouteException, the value of requestSendStarted is false, so you don't need to care. If it is IOException, the requestSendStarted is false only when http2's io exception occurs. Then let's look at the second condition. We can find that unrepeatable requestbody is an interface. This condition means that if our customized request body implements the unrepeatable requestbody interface, we will not retry the request.
3. It is mainly implemented in isRecoverable() to judge whether it belongs to an exception that can be retried.
private boolean isRecoverable(IOException e, boolean requestSendStarted) {
// In case of protocol exception and ProtocolException, the server will not return the content and cannot retry
// There are exceptions in the request and server response, which are not defined according to the http protocol, and it is useless to retry
if (e instanceof ProtocolException) {
return false;
}
// If it is a timeout exception, you can try again
// The Socket connection timeout may be caused by network fluctuation
if (e instanceof InterruptedIOException) {
return e instanceof SocketTimeoutException && !requestSendStarted;
}
// The certificate is incorrect. There is a problem. Don't try again
if (e instanceof SSLHandshakeException) {
if (e.getCause() instanceof CertificateException) {
return false;
}
}
// Certificate verification failed. Don't try again
if (e instanceof SSLPeerUnverifiedException) {
// e.g. a certificate pinning error.
return false;
}
return true;
}
4. Check whether there is an available route to connect. For example, DNS will return multiple IPS after domain name resolution. If one IP connection fails, you can use the connection of the next IP.
2.2 redirect request
If there is no exception in [2] [3] after the request is completed, then we will continue to judge the redirection operation. The redirection logic is located in the method [4] followUpRequest().
private Request followUpRequest(Response userResponse, Route route) throws IOException {
if (userResponse == null) throw new IllegalStateException();
int responseCode = userResponse.code();
final String method = userResponse.request().method();
switch (responseCode) {
// The 407 client uses the HTTP proxy server. Add "proxy authorization" in the request header to allow the proxy server to authorize
case HTTP_PROXY_AUTH:
Proxy selectedProxy = route != null
? route.proxy()
: client.proxy();
if (selectedProxy.type() != Proxy.Type.HTTP) {
throw new ProtocolException("Received HTTP_PROXY_AUTH (407) code while not " +
"using proxy");
}
return client.proxyAuthenticator().authenticate(route, userResponse);
// 401 authentication is required. Some server interfaces need to verify the user's identity. Add "Authorization" in the request header
case HTTP_UNAUTHORIZED:
return client.authenticator().authenticate(route, userResponse);
// 308 permanent redirection
// 307 temporary redirection
case HTTP_PERM_REDIRECT:
case HTTP_TEMP_REDIRECT:
// If the request method is not GET or HEAD, the framework will not automatically redirect the request
if (!method.equals("GET") && !method.equals("HEAD")) {
return null;
}
case HTTP_MULT_CHOICE:
case HTTP_MOVED_PERM:
case HTTP_MOVED_TEMP:
case HTTP_SEE_OTHER:
// If the user does not allow redirection, null is returned
if (!client.followRedirects()) return null;
// Remove location from the response header
String location = userResponse.header("Location");
if (location == null) return null;
// Configure a new request url based on location
HttpUrl url = userResponse.request().url().resolve(location);
// If it is null, it indicates that there is a problem with the protocol and HttpUrl cannot be obtained, then null will be returned without redirection
if (url == null) return null;
// If redirection is switched between http and https, you need to check whether the user is allowed (allowed by default)
boolean sameScheme = url.scheme().equals(userResponse.request().url().scheme());
if (!sameScheme && !client.followSslRedirects()) return null;
Request.Builder requestBuilder = userResponse.request().newBuilder();
/**
* In the redirection request, as long as it is not a PROPFIND request, both POST and other methods should be changed to GET request,
* That is, only the PROPFIND request can have a request body
*/
if (HttpMethod.permitsRequestBody(method)) {
final boolean maintainBody = HttpMethod.redirectsWithBody(method);
if (HttpMethod.redirectsToGet(method)) {
requestBuilder.method("GET", null);
} else {
RequestBody requestBody = maintainBody ? userResponse.request().body() :
null;
requestBuilder.method(method, requestBody);
}
// If it is not a PROPFIND request, delete the data about the request body in the request header
if (!maintainBody) {
requestBuilder.removeHeader("Transfer-Encoding");
requestBuilder.removeHeader("Content-Length");
requestBuilder.removeHeader("Content-Type");
}
}
// When redirecting across hosts, delete the authentication request header
if (!sameConnection(userResponse, url)) {
requestBuilder.removeHeader("Authorization");
}
return requestBuilder.url(url).build();
// 408 client request timeout
case HTTP_CLIENT_TIMEOUT:
// 408 is a connection failure, so judge whether the user is allowed to retry
if (!client.retryOnConnectionFailure()) {
return null;
}
// Unrepeatable requestbody is actually not used in other places
if (userResponse.request().body() instanceof UnrepeatableRequestBody) {
return null;
}
// If the response itself is the product of the re request, and the last re request is still due to 408, we will not re request this time
if (userResponse.priorResponse() != null
&& userResponse.priorResponse().code() == HTTP_CLIENT_TIMEOUT) {
// We attempted to retry and got another timeout. Give up.
return null;
}
// If the server tells us how long to retry after, the framework doesn't care.
if (retryAfter(userResponse, 0) > 0) {
return null;
}
return userResponse.request();
// 503 service is unavailable, which is similar to 408, but the request is repeated only when the server tells you retry after: 0 (meaning retry immediately)
case HTTP_UNAVAILABLE:
if (userResponse.priorResponse() != null
&& userResponse.priorResponse().code() == HTTP_UNAVAILABLE) {
// We attempted to retry and got another timeout. Give up.
return null;
}
if (retryAfter(userResponse, Integer.MAX_VALUE) == 0) {
// specifically received an instruction to retry without delay
return userResponse.request();
}
return null;
default:
return null;
}
}
We can know from the followUpRequest() method that if the final return is null, it means that we don't need to redirect again. If the return is not null, we need to re Request the returned Request. It should be noted that redirection does not always occur. According to [5], the maximum number of redirections is 20.
2.3 summary
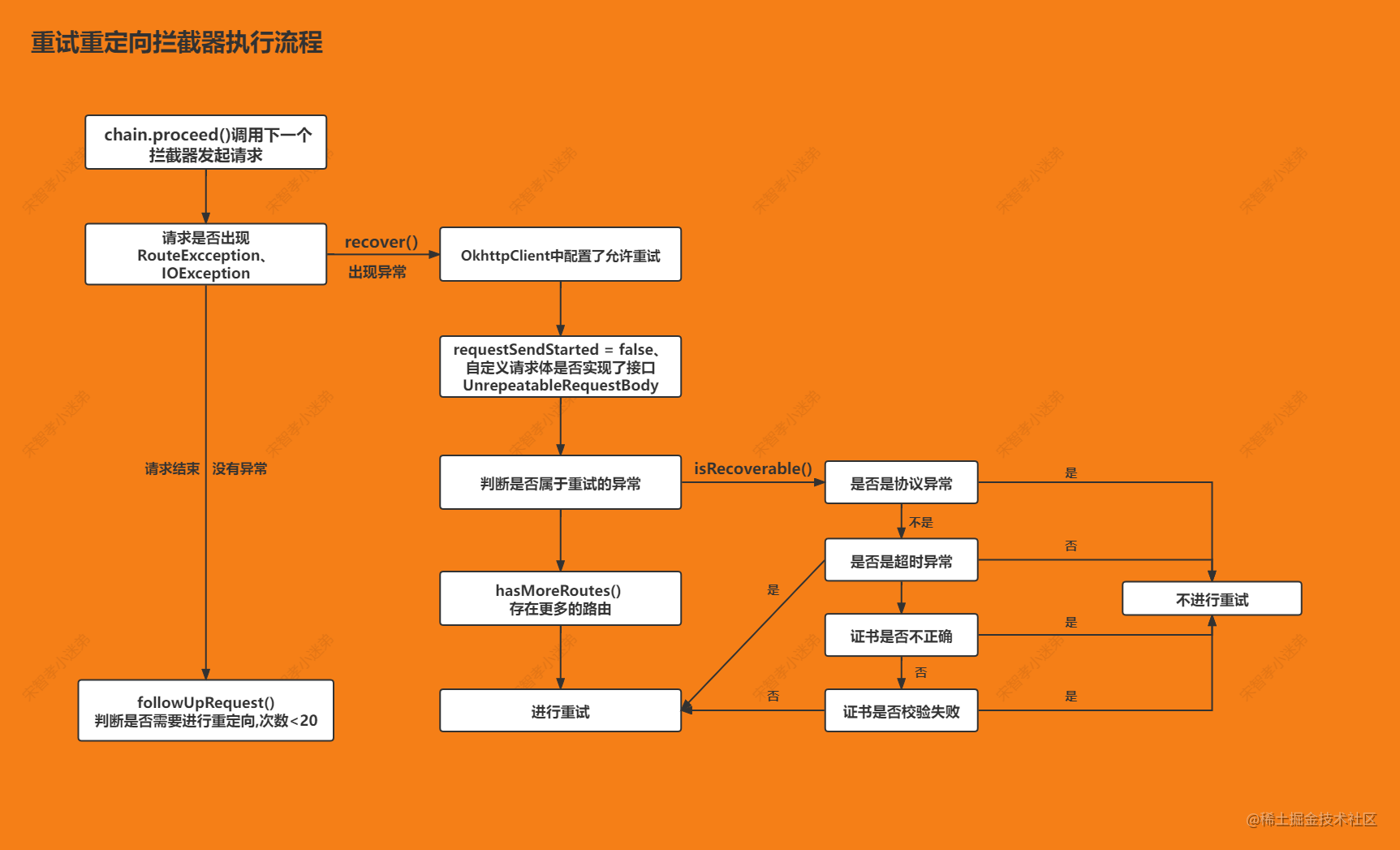
3. BridgeInterceptor bridge interceptor
BridgeInterceptor: Bridge interceptor, the bridge between the user and the network. The Request we send will be processed before it can be sent to the server. We can build the Header and set the response information according to the Request information, such as the calculation and addition of content length, the accept encoding of gzip (gzip), and the unpacking of gzip compressed data.
1. It is responsible for transforming a Request constructed by the user into a Request that can be accessed through the network, such as adding or deleting the header information related to the Request.
2. Make a network Request for the Request that meets the network Request and hand it to the next interceptor for processing.
3. Convert the Response from the network request into the Response available to the user. If it is compressed by GZIP, it needs to be decompressed.
public final class BridgeInterceptor implements Interceptor {
@Override public Response intercept(Chain chain) throws IOException {
Request userRequest = chain.request();
// According to the user's Request, the Request for network access is constructed
Request.Builder requestBuilder = userRequest.newBuilder();
// ... Execute the code of the build request, set the request length, Cookie, etc
// Network request execution
Response networkResponse = chain.proceed(requestBuilder.build());
// Judge whether the response header contains cookies, and store cookies through Cookie jar
HttpHeaders.receiveHeaders(cookieJar, userRequest.url(), networkResponse.headers());
// Get user response builder from network response
Response.Builder responseBuilder = networkResponse.newBuilder().request(userRequest);
// Decompression operation
if (transparentGzip
&& "gzip".equalsIgnoreCase(networkResponse.header("Content-Encoding"))
&& HttpHeaders.hasBody(networkResponse)) {
GzipSource responseBody = new GzipSource(networkResponse.body().source());
Headers strippedHeaders = networkResponse.headers().newBuilder()
.removeAll("Content-Encoding")
.removeAll("Content-Length")
.build();
responseBuilder.headers(strippedHeaders);
String contentType = networkResponse.header("Content-Type");
responseBuilder.body(new RealResponseBody(contentType, -1L, Okio.buffer(responseBody)));
}
// Return response
return responseBuilder.build();
}
}
| Request header | explain |
|---|---|
| content-Type | Request body type, such as: application/x-www-form-urlencoded |
| Content-Length/Transfer-Encoding | Request body resolution method |
| Host | Requested host site |
| Connection: Keep-Alive | Keep long connection |
| Accept-Encoding: gzip | Accept response support gzip compression |
| Cookie | cookie identification |
| User-Agent | Requested user information, such as operating system, browser, etc |
4. CacheInterceptor cache interceptor
CacheInterceptor: a cache interceptor that determines whether a cache exists and can be used according to the requested information and cache response information. Let's look at the intercept() method of CacheInterceptor.
public Response intercept(Chain chain) throws IOException {
//[1] . get the response cache of the corresponding request from the cache
Response cacheCandidate = cache != null
? cache.get(chain.request())
: null;
long now = System.currentTimeMillis();
//[2] . create cache policy: it is composed of various conditions (request header)
CacheStrategy strategy =
new CacheStrategy.Factory(now, chain.request(), cacheCandidate).get();
//
Request networkRequest = strategy.networkRequest;
Response cacheResponse = strategy.cacheResponse;
if (cache != null) {
cache.trackResponse(strategy);
}
if (cacheCandidate != null && cacheResponse == null) {
closeQuietly(cacheCandidate.body()); // The cache candidate wasn't applicable. Close it.
}
//[3] Prohibit the use of network and cache
//If we're forbidden from using the network and the cache is insufficient, fail.
if (networkRequest == null && cacheResponse == null) {
return new Response.Builder()
.request(chain.request())
.protocol(Protocol.HTTP_1_1)
.code(504)
.message("Unsatisfiable Request (only-if-cached)")
.body(Util.EMPTY_RESPONSE)
.sentRequestAtMillis(-1L)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
}
//[4] Prohibit network requests
//If we don't need the network, we're done.
if (networkRequest == null) {
return cacheResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.build();
}
Response networkResponse = null;
try {
//[5] Initiate a request and give it to the next interceptor
networkResponse = chain.proceed(networkRequest);
} finally {
// If we're crashing on I/O or otherwise, don't leak the cache body.
if (networkResponse == null && cacheCandidate != null) {
closeQuietly(cacheCandidate.body());
}
}
//[6] If the cached response is not empty and the server returns 304, the cached response is used to modify the time and other data as the response to this request
if (cacheResponse != null) {
if (networkResponse.code() == HTTP_NOT_MODIFIED) {
Response response = cacheResponse.newBuilder()
.headers(combine(cacheResponse.headers(), networkResponse.headers()))
.sentRequestAtMillis(networkResponse.sentRequestAtMillis())
.receivedResponseAtMillis(networkResponse.receivedResponseAtMillis())
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
networkResponse.body().close();
// Update the cache after combining headers but before stripping the
// Content-Encoding header (as performed by initContentStream()).
cache.trackConditionalCacheHit();
cache.update(cacheResponse, response);
return response;
} else {
closeQuietly(cacheResponse.body());
}
}
//[7] If the cache is not available, use the response of the network
Response response = networkResponse.newBuilder()
.cacheResponse(stripBody(cacheResponse))
.networkResponse(stripBody(networkResponse))
.build();
if (cache != null) {
//[8] Whether the http header has a response body, and the caching policy can be cached
if (HttpHeaders.hasBody(response) && CacheStrategy.isCacheable(response,
networkRequest)) {
// Offer this request to the cache.
CacheRequest cacheRequest = cache.put(response);
return cacheWritingResponse(cacheRequest, response);
}
//[9] . if the method is not cached, remove the cache
if (HttpMethod.invalidatesCache(networkRequest.method())) {
try {
cache.remove(networkRequest);
} catch (IOException ignored) {
// The cache cannot be written.
}
}
}
return response;
}
[1] First, judge whether the cache exists in the cache. If so, return the response and judge whether the current response is available. If not, return null.
[2] Build a cache strategy CacheStrategy, in which networkRequest and cacheResponse are maintained. networkRequest represents network request and cacheResponse represents cache response. Judge whether caching is allowed according to the two.
[3] . if the user configures onlyIfCached when creating the request, it means that the user wants the request to be obtained only from the cache this time and does not need to initiate the request. If there is a networkRequest in the generated CacheStrategy, it means that the request will be initiated, and a conflict occurs at this time! That will directly give the interceptor an object that has neither networkRequest nor cacheResponse. The interceptor returns directly to user 504.
[4] If the network request is prohibited and the cache response is not empty, it will directly return to the cache.
[5] Initiate a network request and call the processed method to pass it to the next interceptor to obtain the networkResponse.
[6] If the networkResponse obtained in step 5 returns 304, it indicates that the cache resources have not changed. You can use it directly and update the cache information.
[7] & [8] & [9]. Use the response returned by the network request and judge whether to cache the returned response.
The main content of CacheInterceptor is specifically implemented in CacheStrategy, because whether to allow caching can be determined according to the different combinations of networkRequest and cacheResponse in CacheStrategy. Look at the getCandidate() method in CacheStrategy.
private CacheStrategy getCandidate() {
// No cached response.
//1. No cache, network request
if (cacheResponse == null) {
return new CacheStrategy(request, null);
}
//okhttp will save the ssl Handshake information Handshake. If an https request is initiated this time, but there is no Handshake information in the cached response, a network request will be initiated
//2. https request, but no handshake information, network request
//Drop the cached response if it's missing a required handshake.
if (request.isHttps() && cacheResponse.handshake() == null) {
return new CacheStrategy(request, null);
}
//3. It is mainly to judge whether the response can be cached through the response code and the header cache control field. If not, make a network request
//If this response shouldn't have been stored, it should never be used
//as a response source. This check should be redundant as long as the
//persistence store is well-behaved and the rules are constant.
if (!isCacheable(cacheResponse, request)) {
return new CacheStrategy(request, null);
}
CacheControl requestCaching = request.cacheControl();
//4. If the request contains: CacheControl: no cache, you need to verify the validity of the cache with the server
// Or the request header contains if modified since: the time value is lastModified or data. If the server does not modify the requested data after the time specified in the header, the server returns 304 (no modification)
// Or the request header contains if none match: the value is the Etag (resource tag) server compares it with the Etag value on the server; If it matches, 304 is returned
// As long as any one of the three exists in the request header, make a network request
if (requestCaching.noCache() || hasConditions(request)) {
return new CacheStrategy(request, null);
}
//5. If cache control: immutable exists in the cached response, the content of the response will not change. You can use cache
CacheControl responseCaching = cacheResponse.cacheControl();
if (responseCaching.immutable()) {
return new CacheStrategy(null, cacheResponse);
}
//6. Judge whether the cache is allowed according to the control of the cache response and the response header of the cache
// 6.1. Get the time from the creation of the cached response to the present
long ageMillis = cacheResponseAge();
// 6.2. Get the effective cache time of this response
long freshMillis = computeFreshnessLifetime();
if (requestCaching.maxAgeSeconds() != -1) {
//If Max age is specified in the request, it means that the available cache effective time is specified. It is necessary to combine the response effective cache time with the request available cache time to obtain the minimum response cache time
freshMillis = Math.min(freshMillis,
SECONDS.toMillis(requestCaching.maxAgeSeconds()));
}
// 6.3 the request contains cache control: Min fresh = [seconds] the cache that has not passed the specified time can be used (the cache effective time considered by the request)
long minFreshMillis = 0;
if (requestCaching.minFreshSeconds() != -1) {
minFreshMillis = SECONDS.toMillis(requestCaching.minFreshSeconds());
}
// 6.4
// 6.4.1 cache control: must revalidate can be cached, but it must be confirmed with the source server
// 6.4.2. Cache control: Max stale = [seconds] the specified length of time can be used after the cache expires. If no number of seconds is specified, it means that it can be used no matter how long it expires; If specified, the cache can be used as long as it is within the specified time
// The former ignores the latter, so it is judged that it is not necessary to confirm with the server before obtaining the max stale in the request header
long maxStaleMillis = 0;
if (!responseCaching.mustRevalidate() && requestCaching.maxStaleSeconds() != -1) {
maxStaleMillis = SECONDS.toMillis(requestCaching.maxStaleSeconds());
}
// 6.5 it is not necessary to verify the validity with the server & & the time when the response exists + the cache validity time considered by the request is less than the cache validity time + the time that can be used after expiration
// Allow caching
if (!responseCaching.noCache() && ageMillis + minFreshMillis < freshMillis + maxStaleMillis) {
Response.Builder builder = cacheResponse.newBuilder();
//If it has expired but does not exceed the duration of continued use after expiration, it can still be used. Only add the corresponding header field
if (ageMillis + minFreshMillis >= freshMillis) {
builder.addHeader("Warning", "110 HttpURLConnection "Response is stale"");
}
//If the cache has exceeded one day and the expiration time is not set in the response, you also need to add a warning
long oneDayMillis = 24 * 60 * 60 * 1000L;
if (ageMillis > oneDayMillis && isFreshnessLifetimeHeuristic()) {
builder.addHeader("Warning", "113 HttpURLConnection "Heuristic expiration"");
}
return new CacheStrategy(null, builder.build());
}
//7. Cache expired
String conditionName;
String conditionValue;
if (etag != null) {
conditionName = "If-None-Match";
conditionValue = etag;
} else if (lastModified != null) {
conditionName = "If-Modified-Since";
conditionValue = lastModifiedString;
} else if (servedDate != null) {
conditionName = "If-Modified-Since";
conditionValue = servedDateString;
} else {
return new CacheStrategy(request, null); // No condition! Make a regular request.
}
//If if none match / if modified since is set, the server may return 304 (no modification) and use the cached response body
Headers.Builder conditionalRequestHeaders = request.headers().newBuilder();
Internal.instance.addLenient(conditionalRequestHeaders, conditionName, conditionValue);
Request conditionalRequest = request.newBuilder()
.headers(conditionalRequestHeaders.build())
.build();
return new CacheStrategy(conditionalRequest, cacheResponse);
}
-
If the Response obtained from the cache is null, you need to use the network request to obtain the Response.
-
If it is an Https request but the handshake information is lost, the cache cannot be used and a network request is required.
-
If it is judged that the response code cannot be cached and the response header is marked with no store, a network request is required.
-
If the request header has no cache ID or if modified since / if none match ID, the cache is not allowed and a network request is required.
-
If the response header has no no cache ID and the cache time does not exceed the limit time, the cache can be used without network request.
-
If the cached response contains cache control: immutable, it means that the response content of the corresponding request will not change. At this time, you can directly use the cache. Otherwise, continue to judge whether the cache is available.
-
If the cache expires, judge whether the response header is set to Etag / last modified / date. If not, use the network request directly. Otherwise, consider the server return 304.
4.1 summary
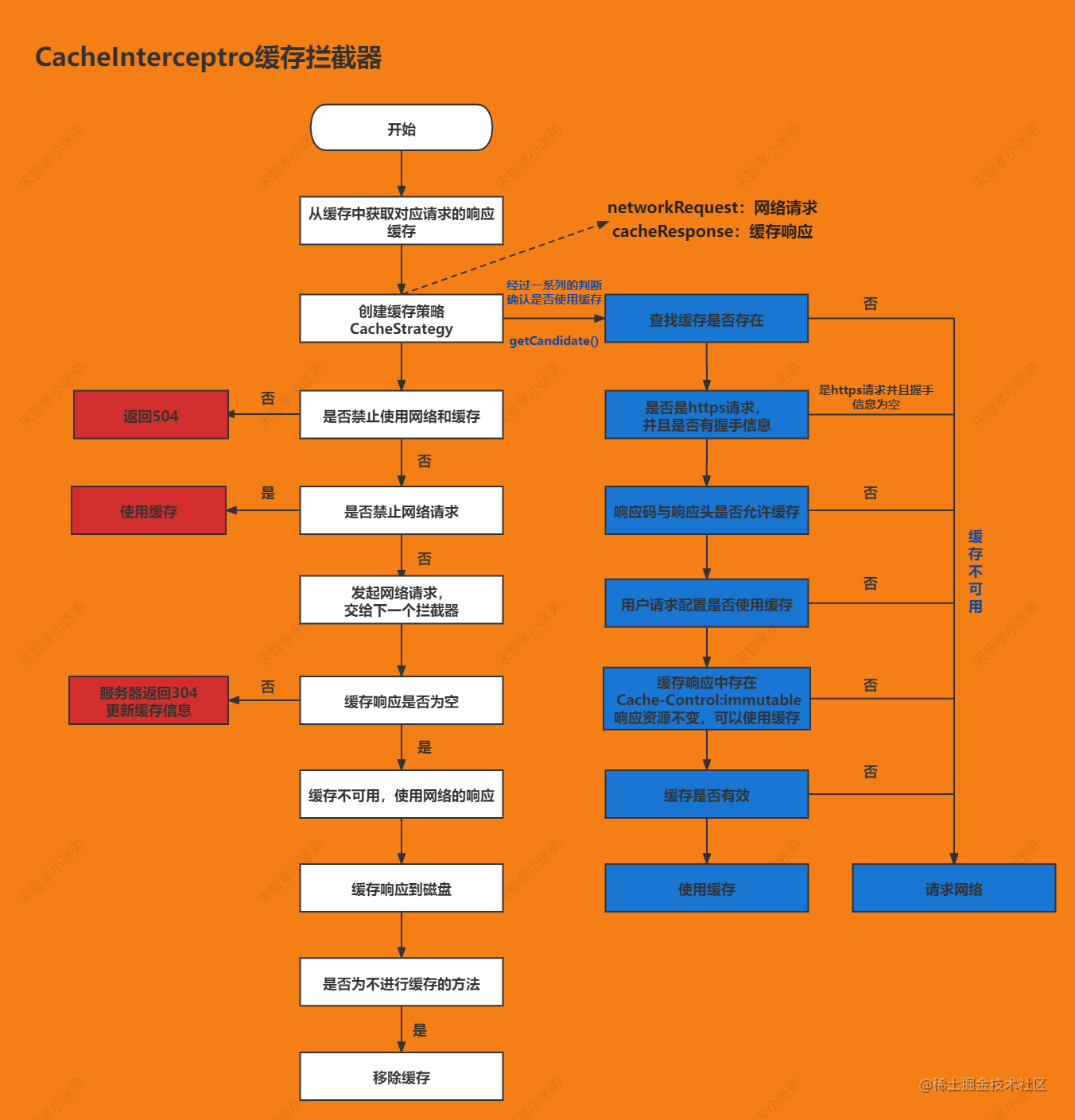
5. ConnectInterceptor connection interceptor
ConnectInterceptor: connection interceptor, which is responsible for establishing a connection with the server.
/** Opens a connection to the target server and proceeds to the next interceptor. */
// Open the connection to the target server and go to the next interceptor
public final class ConnectInterceptor implements Interceptor {
public final OkHttpClient client;
public ConnectInterceptor(OkHttpClient client) {
this.client = client;
}
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
Request request = realChain.request();
// The streamalallocation created in the retry redirection interceptor is used here
StreamAllocation streamAllocation = realChain.streamAllocation();
// We need the network to satisfy this request. Possibly for validating a conditional GET.
boolean doExtensiveHealthChecks = !request.method().equals("GET");
// Establish HttpCodec
HttpCodec httpCodec = streamAllocation.newStream(client, chain, doExtensiveHealthChecks);
// Get RealConnection
RealConnection connection = streamAllocation.connection();
// Enter the next interceptor
return realChain.proceed(request, streamAllocation, httpCodec, connection);
}
}
There is little code in ConnectInterceptor. The newStream() method used here is actually to find or establish an effective connection with the requesting host. The returned HttpCodec contains the input and output stream and encapsulates the encoding and decoding of the HTTP request message. It can be used directly to complete HTTP communication with the requesting host.
public HttpCodec newStream(
OkHttpClient client, Interceptor.Chain chain, boolean doExtensiveHealthChecks) {
int connectTimeout = chain.connectTimeoutMillis();
int readTimeout = chain.readTimeoutMillis();
int writeTimeout = chain.writeTimeoutMillis();
int pingIntervalMillis = client.pingIntervalMillis();
boolean connectionRetryEnabled = client.retryOnConnectionFailure();
try {
// Get connection
RealConnection resultConnection = findHealthyConnection(connectTimeout, readTimeout,
writeTimeout, pingIntervalMillis, connectionRetryEnabled, doExtensiveHealthChecks);
// Establish HttpCodec
HttpCodec resultCodec = resultConnection.newCodec(client, chain, this);
synchronized (connectionPool) {
codec = resultCodec;
return resultCodec;
}
} catch (IOException e) {
throw new RouteException(e);
}
}
The newStream() method mainly does two things: obtaining RealConnection and establishing HttpCodec. The specific acquisition process of RealConnection is in the findhealthyconnection () method. Enter the findHealthyConnection() method to view:
/**
* Finds a connection and returns it if it is healthy. If it is unhealthy the process is repeated
* until a healthy connection is found.
* Find the connection and return it if it is in good condition. If not, repeat this process until a healthy connection is found.
*/
private RealConnection findHealthyConnection(int connectTimeout, int readTimeout,
int writeTimeout, int pingIntervalMillis, boolean connectionRetryEnabled,
boolean doExtensiveHealthChecks) throws IOException {
// Open a loop to find connections
while (true) {
RealConnection candidate = findConnection(connectTimeout, readTimeout, writeTimeout,
pingIntervalMillis, connectionRetryEnabled);
// If this is a brand new connection, we can skip the extensive health checks.
// If it is a new connection, there is no need for a health check
synchronized (connectionPool) {
//The newly created connection has not been used
if (candidate.successCount == 0) {
return candidate;
}
}
// Do a (potentially slow) check to confirm that the pooled connection is still good. If it
// isn't, take it out of the pool and start again.
// Check whether the connection in the connection pool is good. If it is unhealthy, remove it from the pool and continue to find it
if (!candidate.isHealthy(doExtensiveHealthChecks)) {
//Disable this connection
noNewStreams();
continue;
}
return candidate;
}
}
findHealthyConnection() mainly does the following:
1. Open a loop to get the connection through the findConnection() method.
2. Judge whether the obtained connection is newly created. If it is newly created, skip the health check and return to use directly.
3. Perform a health check. If it is unhealthy, disable the connection and continue the cycle.
4. Returns the connection finally obtained.
Next, we enter the findConnection() method to check.
/**
* Returns a connection to host a new stream. This prefers the existing connection if it exists,
* then the pool, finally building a new connection.
* Return a connection. First select the existing connection. If the existing connection does not exist, get it from the connection pool. If there is no connection in the connection pool, create a new connection
*/
private RealConnection findConnection(int connectTimeout, int readTimeout, int writeTimeout,
int pingIntervalMillis, boolean connectionRetryEnabled) throws IOException {
boolean foundPooledConnection = false;
RealConnection result = null;//
Route selectedRoute = null;
Connection releasedConnection;
Socket toClose;
synchronized (connectionPool) {
if (released) throw new IllegalStateException("released");
if (codec != null) throw new IllegalStateException("codec != null");
if (canceled) throw new IOException("Canceled");
// Attempt to use an already-allocated connection. We need to be careful here because our
// already-allocated connection may have been restricted from creating new streams.
// Try to use an assigned connection. We need to be careful here that the allocated connections may be limited and we cannot create new streams
releasedConnection = this.connection;
toClose = releaseIfNoNewStreams();
if (this.connection != null) {
// We had an already-allocated connection and it's good.
// Get assigned connections
result = this.connection;
releasedConnection = null;
}
if (!reportedAcquired) {
// If the connection was never reported acquired, don't report it as released!
releasedConnection = null;
}
if (result == null) {
// Attempt to get a connection from the pool.
// If no connection is obtained from the above, obtain the connection from the connection pool and finally call ConnectionPool get()
Internal.instance.get(connectionPool, address, this, null);
if (connection != null) {
// Get connections from connection pool
foundPooledConnection = true;
//Assign the connection to result
result = connection;
} else {
selectedRoute = route;
}
}
}
closeQuietly(toClose);
if (releasedConnection != null) {
eventListener.connectionReleased(call, releasedConnection);
}
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result);
}
if (result != null) {
// If we found an already-allocated or pooled connection, we're done.
// Get an existing connection or get a connection from a connection pool
return result;
}
// If we need a route selection, make one. This is a blocking operation.
// Switch route
boolean newRouteSelection = false;
if (selectedRoute == null && (routeSelection == null || !routeSelection.hasNext())) {
newRouteSelection = true;
routeSelection = routeSelector.next();
}
synchronized (connectionPool) {
if (canceled) throw new IOException("Canceled");
if (newRouteSelection) {
// Now that we have a set of IP addresses, make another attempt at getting a connection from
// the pool. This could match due to connection coalescing.
List<Route> routes = routeSelection.getAll();
for (int i = 0, size = routes.size(); i < size; i++) {
Route route = routes.get(i);
// Traverse the route and find the connection in the connection pool again
Internal.instance.get(connectionPool, address, this, route);
if (connection != null) {
foundPooledConnection = true;
result = connection;
this.route = route;
break;
}
}
}
if (!foundPooledConnection) {
if (selectedRoute == null) {
selectedRoute = routeSelection.next();
}
// Create a connection and assign it to this allocation immediately. This makes it possible
// for an asynchronous cancel() to interrupt the handshake we're about to do.
route = selectedRoute;
refusedStreamCount = 0;
// Create a new connection and assign it to result
result = new RealConnection(connectionPool, selectedRoute);
acquire(result, false);
}
}
// If we found a pooled connection on the 2nd time around, we're done.
// If the reusable is found for the second time, return
if (foundPooledConnection) {
eventListener.connectionAcquired(call, result);
return result;
}
// Do TCP + TLS handshakes. This is a blocking operation.
// TCP+TLS handshake
result.connect(connectTimeout, readTimeout, writeTimeout, pingIntervalMillis,
connectionRetryEnabled, call, eventListener);
routeDatabase().connected(result.route());
Socket socket = null;
synchronized (connectionPool) {
reportedAcquired = true;
// Pool the connection.
// Add connections to the connection pool
Internal.instance.put(connectionPool, result);
// If another multiplexed connection to the same address was created concurrently, then
// release this connection and acquire that one.
if (result.isMultiplexed()) {
socket = Internal.instance.deduplicate(connectionPool, address, this);
result = connection;
}
}
closeQuietly(socket);
eventListener.connectionAcquired(call, result);
return result;
}
The code in findConnection() can be summarized into the following steps:
1. Check whether the currently allocated connection can be reused.
2. If the currently allocated connection is unavailable, try to find a reusable connection from the connection pool.
3. If no reusable connection is found in the connection pool, switch the route and continue to try to find reusable connections in the connection pool
4. If no reusable connection can be obtained in the above methods, create a new connection and coexist in the connection pool.
At this point, the RealConnection has been obtained. Let's take a look at the relevant parts of the connection pool.
5.1 connection pool
OkHttp3 abstracts the connection between client and server as Connection/RealConnection, and designs ConnectionPool to manage the reuse of these connections. Requests that share the same IP/PORT can reuse connections. TCP needs to shake hands three times to establish a connection. If it needs to wave hands four times to disconnect, and if it needs to perform three handshakes and four waves for each network request, such frequent request operations will lead to performance problems. Therefore, in order to reuse the connection, there is a KeepAlive mechanism in Http, which still maintains the connection after data transmission, When waiting for the next request, the connection can be reused directly, which greatly improves the efficiency of the request.
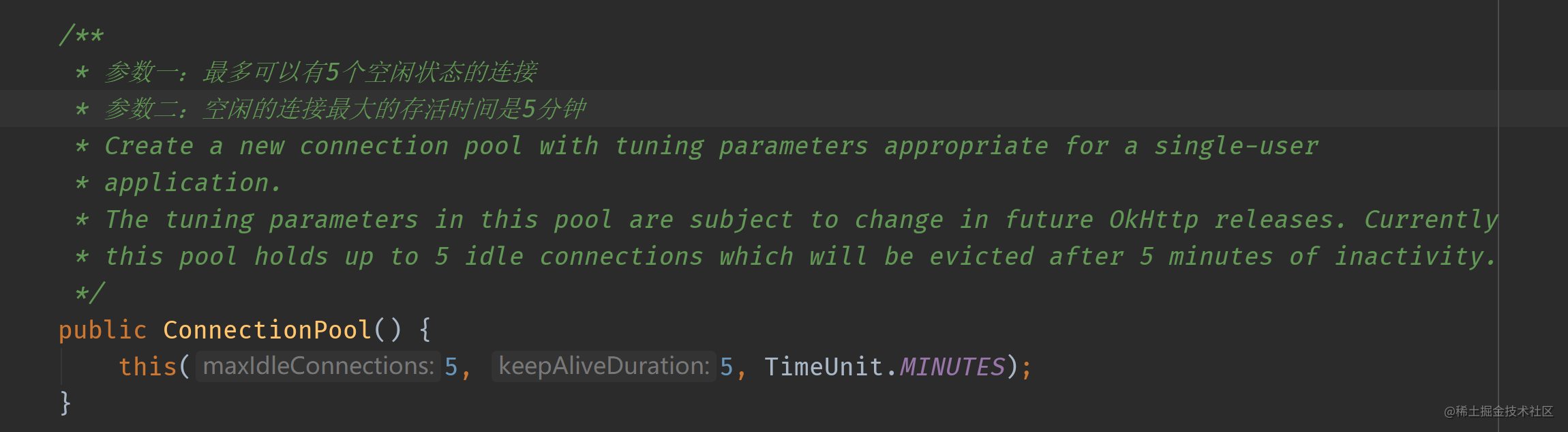
Connection pool storage

You can see that in the put method, all connections will be added to the queue, but before adding, it will judge whether the cleaning task has been executed. If not, it will be started.
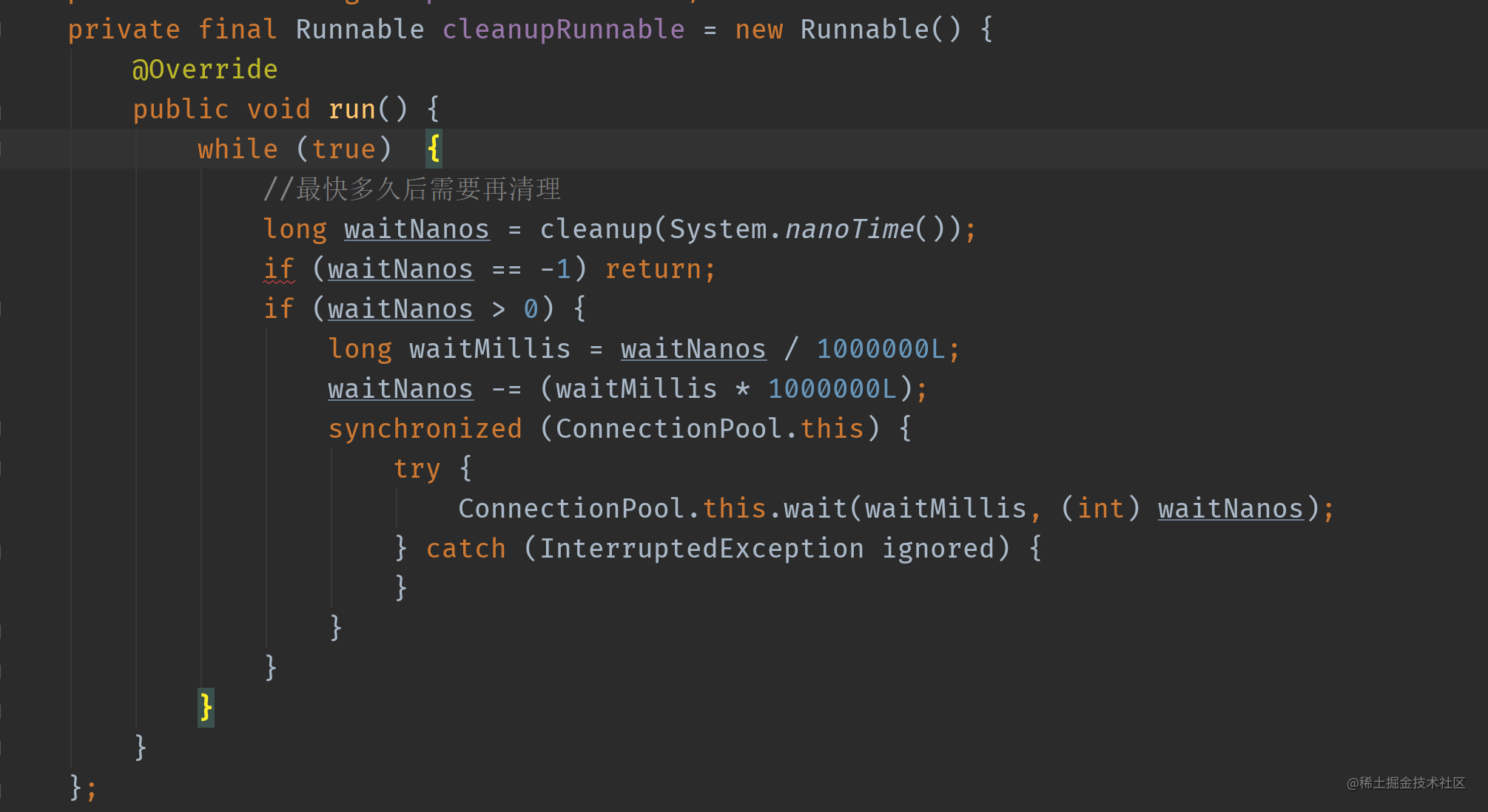 Continue to check the clearup() method, which is all in the comments. I won't describe it too much here.
Continue to check the clearup() method, which is all in the comments. I won't describe it too much here.
long cleanup(long now) {
int inUseConnectionCount = 0;
int idleConnectionCount = 0;
RealConnection longestIdleConnection = null;
long longestIdleDurationNs = Long.MIN_VALUE;
// Find either a connection to evict, or the time that the next eviction is due.
synchronized (this) {
for (Iterator<RealConnection> i = connections.iterator(); i.hasNext(); ) {
RealConnection connection = i.next();
//Check whether the connection is in use (number of references to StreanAllocation)
//If the connection is in use, keep searching.
if (pruneAndGetAllocationCount(connection, now) > 0) {
// If in use, record the number of connections in use
inUseConnectionCount++;
continue;
}
// Record the number of idle connections
idleConnectionCount++;
// If the connection is ready to be evicted, we're done.
//Idle time = current time - the last time this connection was used
//After traversal, get the connection that has been idle for the longest time
long idleDurationNs = now - connection.idleAtNanos;
if (idleDurationNs > longestIdleDurationNs) {
longestIdleDurationNs = idleDurationNs;
longestIdleConnection = connection;
}
}
// 1. Idle time > keep alive time is removed from the connection pool. After removal, return to 0 and continue checking
// 2. The number of idle > the maximum number of idle in the connection pool is removed from the connection pool. After removal, it returns 0 and continues to check
if (longestIdleDurationNs >= this.keepAliveDurationNs
|| idleConnectionCount > this.maxIdleConnections) {
// We've found a connection to evict. Remove it from the list, then close it
// below (outside
// of the synchronized block).
connections.remove(longestIdleConnection);
} else if (idleConnectionCount > 0) {
// A connection will be ready to evict soon.
// There are idle connections in the pool. Waiting time = how long can they be idle = keep alive time - the connection that has been idle for the longest time
return keepAliveDurationNs - longestIdleDurationNs;
} else if (inUseConnectionCount > 0) {
// All connections are in use. It'll be at least the keep alive duration 'til we
// run again.
// There is a connection in use. Wait 5 minutes to continue checking
return keepAliveDurationNs;
} else {
// No connections, idle or in use.
//Not satisfied. There may be no connection in the pool. Stop cleaning directly and start again after put
cleanupRunning = false;
return -1;
}
}
Connection pool deletion
public boolean isEligible(Address address, @Nullable Route route) {
// If this connection is not accepting new streams, we're done.
// If there is a connection in use, it cannot be reused
if (allocations.size() >= allocationLimit || noNewStreams) return false;
// If the non-host fields of the address don't overlap, we're done.
// If the addresses are different, they cannot be reused. It includes configured dns, proxy, certificate, port, etc
if (!Internal.instance.equalsNonHost(this.route.address(), address)) return false;
// If the host exactly matches, we're done: this connection can carry the address.
// The domain names are the same, so you can reuse them
if (address.url().host().equals(this.route().address().url().host())) {
return true; // This connection is a perfect match.
}
. . .
}
5.2 summary
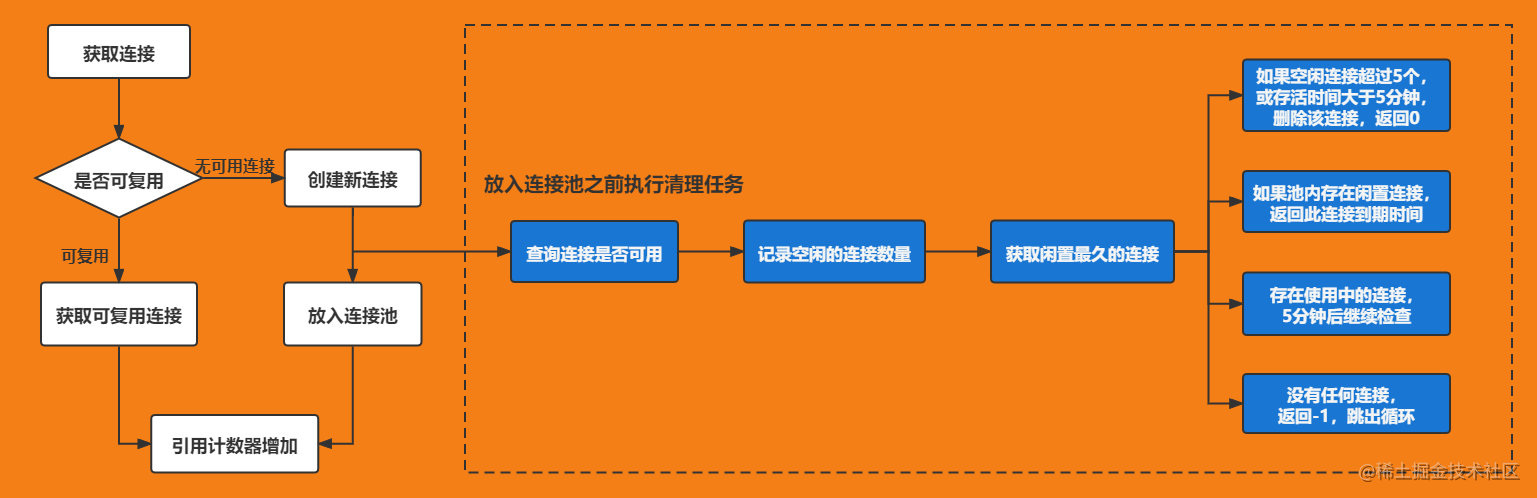
6. CallServerInterceptor service request interceptor
Call server Interceptor: a service request interceptor that initiates a real network request to the server and then receives a response from the server. This is the last interceptor in the whole interceptor chain. In this interceptor, the processed method will not call the next interceptor, but will process the received response and return it to the interceptor of the upper layer.
/** This is the last interceptor in the chain. It makes a network call to the server. */
public final class CallServerInterceptor implements Interceptor {
private final boolean forWebSocket;
public CallServerInterceptor(boolean forWebSocket) {
this.forWebSocket = forWebSocket;
}
@Override public Response intercept(Chain chain) throws IOException {
RealInterceptorChain realChain = (RealInterceptorChain) chain;
HttpCodec httpCodec = realChain.httpStream();
StreamAllocation streamAllocation = realChain.streamAllocation();
RealConnection connection = (RealConnection) realChain.connection();
Request request = realChain.request();
long sentRequestMillis = System.currentTimeMillis();
realChain.eventListener().requestHeadersStart(realChain.call());
// Write request header information to socket
httpCodec.writeRequestHeaders(request);
realChain.eventListener().requestHeadersEnd(realChain.call(), request);
Response.Builder responseBuilder = null;
if (HttpMethod.permitsRequestBody(request.method()) && request.body() != null) {
// If there's a "Expect: 100-continue" header on the request, wait for a "HTTP/1.1 100
// Continue" response before transmitting the request body. If we don't get that, return
// what we did get (such as a 4xx response) without ever transmitting the request body.
// If there is a "Expect: 100 continue" header on the request, please wait for the "HTTP 1.1 100 continue" response before sending the request body.
// If not, please return the result we obtained (e.g. 4xx response) without transmitting the request body.
// Whether the request body and the request body 100: expect server are willing to send the request before sending the request body
if ("100-continue".equalsIgnoreCase(request.header("Expect"))) {
httpCodec.flushRequest();
realChain.eventListener().responseHeadersStart(realChain.call());
responseBuilder = httpCodec.readResponseHeaders(true);
}
if (responseBuilder == null) {
// Write the request body if the "Expect: 100-continue" expectation was met.
realChain.eventListener().requestBodyStart(realChain.call());
long contentLength = request.body().contentLength();
CountingSink requestBodyOut =
new CountingSink(httpCodec.createRequestBody(request, contentLength));
BufferedSink bufferedRequestBody = Okio.buffer(requestBodyOut);
// Write request body to socket
request.body().writeTo(bufferedRequestBody);
bufferedRequestBody.close();
// Write complete
realChain.eventListener()
.requestBodyEnd(realChain.call(), requestBodyOut.successfulCount);
} else if (!connection.isMultiplexed()) {
// If the "Expect: 100-continue" expectation wasn't met, prevent the HTTP/1 connection
// from being reused. Otherwise we're still obligated to transmit the request body to
// leave the connection in a consistent state.
streamAllocation.noNewStreams();
}
}
// Complete the writing of the network request
httpCodec.finishRequest();
if (responseBuilder == null) {
realChain.eventListener().responseHeadersStart(realChain.call());
// Read the header information of the request in the network response
responseBuilder = httpCodec.readResponseHeaders(false);
}
Response response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
int code = response.code();
if (code == 100) {
// If the response is 100, it means that the request expect: 100 continue is successful. You need to read a response header again immediately. This is the real response header corresponding to the request.
// server sent a 100-continue even though we did not request one.
// try again to read the actual response
responseBuilder = httpCodec.readResponseHeaders(false);
response = responseBuilder
.request(request)
.handshake(streamAllocation.connection().handshake())
.sentRequestAtMillis(sentRequestMillis)
.receivedResponseAtMillis(System.currentTimeMillis())
.build();
code = response.code();
}
realChain.eventListener()
.responseHeadersEnd(realChain.call(), response);
// Read the body information of the network response
if (forWebSocket && code == 101) {
// Connection is upgrading, but we need to ensure interceptors see a non-null response body.
response = response.newBuilder()
.body(Util.EMPTY_RESPONSE)
.build();
} else {
response = response.newBuilder()
.body(httpCodec.openResponseBody(response))
.build();
}
if ("close".equalsIgnoreCase(response.request().header("Connection"))
|| "close".equalsIgnoreCase(response.header("Connection"))) {
//Close flow
streamAllocation.noNewStreams();
}
if ((code == 204 || code == 205) && response.body().contentLength() > 0) {
throw new ProtocolException(
"HTTP " + code + " had non-zero Content-Length: " + response.body().contentLength());
}
return response;
}
7. Summary
The whole Okhttp function is implemented in these five default system interceptors. When the user initiates a request, the task Dispatcher will send the request to the retry interceptor for processing.
- After the retry redirection interceptor sends a request to the next interceptor, it will obtain the results returned by the subsequent interceptor, and judge whether to retry the redirection operation according to the response.
- Before sending a request to the next interceptor, the bridge interceptor is responsible for adding the necessary request header of http protocol and adding some default behaviors. After the result is obtained, the cookie saving interface will be called and GZIP data will be parsed.
- The cache interceptor will judge whether there is a cache that can be used directly before sending a request to the next interceptor, and will judge whether to cache the result after the result is obtained.
- The connection interceptor will reuse or establish a new connection and obtain the corresponding socket stream before sending a request to the next interceptor.
- Request the server interceptor to conduct real communication with the server, send data to the server, and parse the read response data. After this series of processes, an HTTP request is completed!
Finally, a figure is used to summarize the whole process of Okhttp Interceptor:
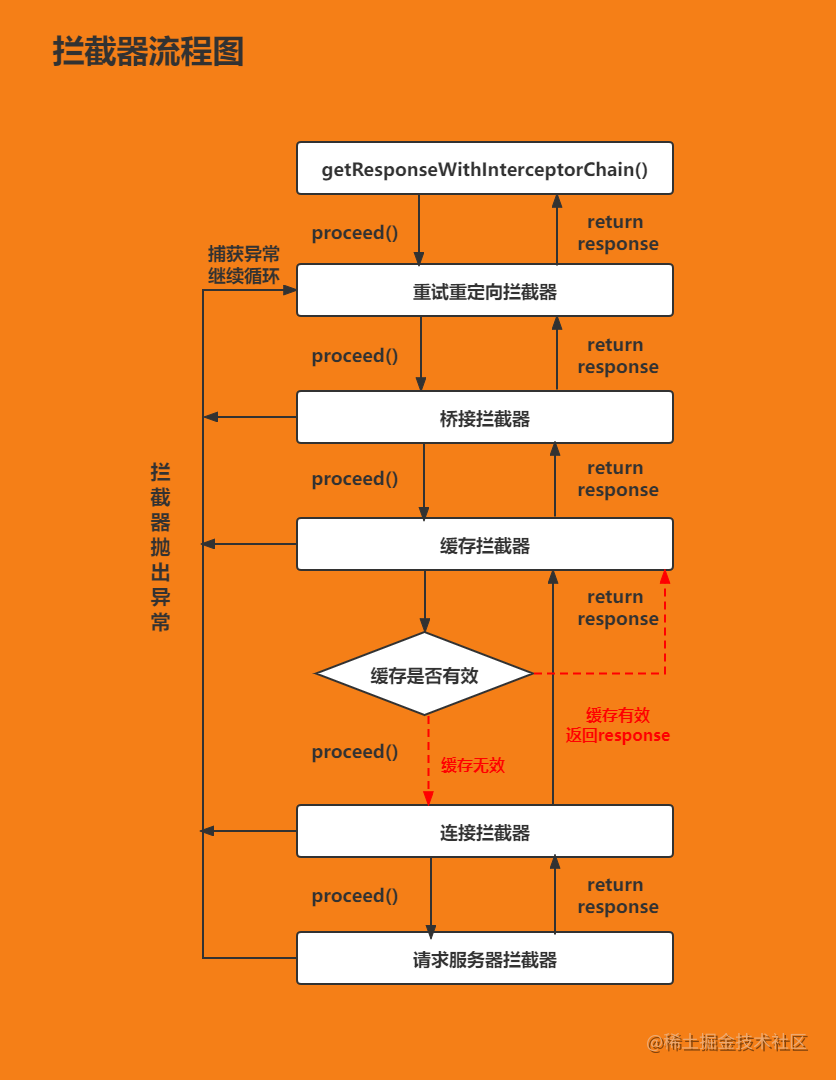
This is the end of the introduction of Okhttp interceptor. If there is anything that needs to be corrected, please correct it in time and forgive me.
Reference link
okhttp source code analysis (I) -- basic process (super detailed)
OkHttp3 source code analysis (II) principle analysis of five interceptors
Android network framework OkHttp source code analysis
Android OKHttp may be an interceptor you've never used before [practical recommendation]
7. Summary
The whole Okhttp function is implemented in these five default system interceptors. When the user initiates a request, the task Dispatcher will send the request to the retry interceptor for processing.
- After the retry redirection interceptor sends a request to the next interceptor, it will obtain the results returned by the subsequent interceptor, and judge whether to retry the redirection operation according to the response.
- Before sending a request to the next interceptor, the bridge interceptor is responsible for adding the necessary request header of http protocol and adding some default behaviors. After the result is obtained, the cookie saving interface will be called and GZIP data will be parsed.
- The cache interceptor will judge whether there is a cache that can be used directly before sending a request to the next interceptor, and will judge whether to cache the result after the result is obtained.
- The connection interceptor will reuse or establish a new connection and obtain the corresponding socket stream before sending a request to the next interceptor.
- Request the server interceptor to conduct real communication with the server, send data to the server, and parse the read response data. After this series of processes, an HTTP request is completed!
Finally, a figure is used to summarize the whole process of Okhttp Interceptor:
[external chain picture transferring... (img-SYS7t80o-1645704810176)]
This is the end of the introduction of Okhttp interceptor. If there is anything that needs to be corrected, please correct it in time and forgive me.
last
In accordance with international practice, I would like to share with you a set of very useful advanced Android materials: the most complete Android Development notes of the whole network.
The whole note consists of 8 modules, 729 knowledge points, 3382 pages and 660000 words. It can be said that it covers the most cutting-edge technical points of Android development and the technologies valued by Alibaba, Tencent, byte and other large manufacturers.

Because it contains enough content, this note can be used not only as learning materials, but also as a reference book.
If you need to know a certain knowledge point, whether it is Shift+F search or search by directory, you can find the content you want as quickly as possible.
Compared with the fragmented content we usually watch, the knowledge points of this note are more systematic, easier to understand and remember, and are arranged in strict accordance with the whole knowledge system.
(1) Essential Java foundation for Architects
1. Deep understanding of Java generics
2. Notes in simple terms
3. Concurrent programming
4. Data transmission and serialization
5. Principles of Java virtual machine
6. High efficiency IO
......
(2) Interpretation of open source framework based on design ideas
1. Thermal repair design
2. Plug in framework design
3. Component framework design
4. Picture loading frame
5. Design of network access framework
6. Design of RXJava responsive programming framework
......

(3) 360 ° performance optimization
1. Design idea and code quality optimization
2. Program performance optimization
- Optimization of startup speed and execution efficiency
- Layout detection and optimization
- Memory optimization
- Power consumption optimization
- Network transmission and data storage optimization
- APK size optimization
3. Development efficiency optimization
- Distributed version control system Git
- Automated build system Gradle
......

(4) Android framework architecture
1. Advanced UI promotion
2. Android kernel components
3. Necessary IPC for large projects
4. Data persistence and serialization
5. Framework kernel parsing
......

(5) NDK module development
1. Introduction to C/C + + for NDK development
2. JNI module development
3. Linux Programming
4. Bottom image processing
5. Audio and video development
6. Machine learning
......

(6) Flutter advanced learning
1. Overview of Flutter cross platform development
2. Construction of fluent development environment in Windows
3. Write your first fluent app
4. Introduction to fluent dart language system
......
(7) Wechat applet development
1. Applet overview and introduction
2. Applet UI development
3. API operation
4. Shopping mall project practice
......
(8) kotlin from introduction to mastery
1. Ready to start
2. Foundation
3. Classes and objects
4. Functions and lambda expressions
5. Other
......

Well, this information will be introduced to you. If you need detailed documents, you can scan the QR code below on wechat for free~
