In depth Mybatis framework
After learning Spring, we have learned how to manage a class as a Bean by the IoC container, that is, now we can use the Mybatis framework in a more convenient way. We can directly hand over SqlSessionFactory and Mapper to Spring for management, and we can use them quickly by injection.
Therefore, we need to learn how to integrate Mybatis with Spring. First, we need to continue to deepen our study on the basis of previous knowledge.
Understanding data sources
Before, if we need to create a JDBC connection, we must use drivermanager Getconnection() to create a connection. After the connection is established, we can operate the database.
After learning Mybatis, instead of using DriverManager to provide us with connection objects, we directly use the SqlSessionFactory tool class provided by Mybatis to obtain the corresponding SqlSession and operate the database through the session object.
So, how does it encapsulate JDBC? We can try to guess whether Mybatis helps us call DriverManager to create database connection every time? We can look at the source code of Mybatis:
public SqlSession openSession(boolean autoCommit) {
return this.openSessionFromDataSource(this.configuration.getDefaultExecutorType(), (TransactionIsolationLevel)null, autoCommit);
}
After calling the openSession method through SqlSessionFactory, it calls an internal private method openSessionFromDataSource. Let's see what is defined in this method:
private SqlSession openSessionFromDataSource(ExecutorType execType, TransactionIsolationLevel level, boolean autoCommit) {
Transaction tx = null;
DefaultSqlSession var8;
try {
//Gets the current environment (the object entity mapped by the configuration file)
Environment environment = this.configuration.getEnvironment();
//Business factory (not mentioned for the time being, explained in the next section)
TransactionFactory transactionFactory = this.getTransactionFactoryFromEnvironment(environment);
//In the configuration file: < transactionmanager type = "JDBC" / >
//Generate transaction (according to our configuration, JdbcTransaction will be generated by default). Here is the key. We see that environment is used here Getdatasource() method
tx = transactionFactory.newTransaction(environment.getDataSource(), level, autoCommit);
//The executor, including all the definitions of database operation methods, is essentially using the executor to operate the database, and the transaction object needs to be passed in
Executor executor = this.configuration.newExecutor(tx, execType);
//Encapsulate object as SqlSession
var8 = new DefaultSqlSession(this.configuration, executor, autoCommit);
} catch (Exception var12) {
this.closeTransaction(tx);
throw ExceptionFactory.wrapException("Error opening session. Cause: " + var12, var12);
} finally {
ErrorContext.instance().reset();
}
return var8;
}
In other words, our data source configuration information is stored in the Transaction object. Now we only need to know how the executor executes SQL statements, and then we can know how to create a Connection object. We need to get the link information of the database. Let's see what the DataSource is:
public interface DataSource extends CommonDataSource, Wrapper {
Connection getConnection() throws SQLException;
Connection getConnection(String username, String password)
throws SQLException;
}
We found that it is in javax An interface defined by SQL, which includes two methods, both of which are used to obtain connections. Therefore, now we can conclude that the connection is not obtained through the previous DriverManager method, but through the implementation class of DataSource. Therefore, it is officially introduced to the topic of this section:
The establishment and closing of database links are extremely resource consuming operations. The database connections obtained through DriverManager,
A database connection object corresponds to a physical database connection. Each operation opens a physical connection and closes the connection immediately after use. Frequent opening and closing connections will continue to consume network resources, resulting in low performance of the whole system.
Therefore, JDBC defines a data source standard for us, that is, the DataSource interface, which tells the Connection information of the data source database, and gives all connections to the data source for centralized management. When a Connection object is needed, you can apply to the data source, and the data source will reasonably allocate the Connection object to us according to the internal mechanism.
Generally, the commonly used DataSource implementation adopts pooling technology, which is to create N connections at the beginning, so that there is no need to connect again after use, but directly use the ready-made Connection object for database operation.
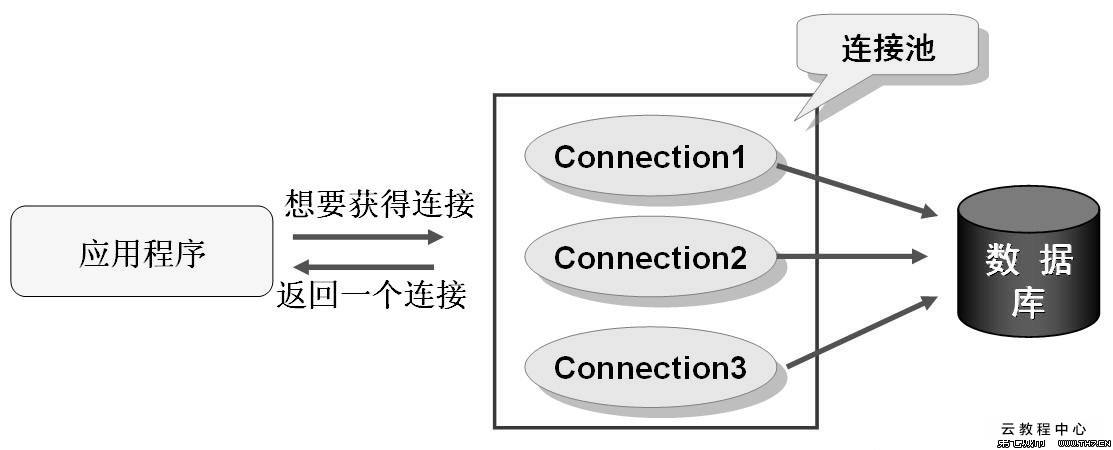
Of course, you can also use the traditional instant connect method to obtain the Connection object. Mybatis provides us with several default data source implementations. We have been using the official default configuration, that is, pooled data source:
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
There are three options:
- UNPOOLED does not use the data source of the connection pool
- POOLED uses the data source of the connection pool
- JNDI data source implemented using JNDI
Interpretation of Mybatis data source implementation
Let's take a look at the implementation of data source without pooling. It is called UnpooledDataSource. Let's take a look at the source code:
public class UnpooledDataSource implements DataSource {
private ClassLoader driverClassLoader;
private Properties driverProperties;
private static Map<String, Driver> registeredDrivers = new ConcurrentHashMap();
private String driver;
private String url;
private String username;
private String password;
private Boolean autoCommit;
private Integer defaultTransactionIsolationLevel;
private Integer defaultNetworkTimeout;
Firstly, many members are defined in this class, including database connection information, database driver information, transaction related information, etc.
How to implement the interface provided by DataSource:
public Connection getConnection() throws SQLException {
return this.doGetConnection(this.username, this.password);
}
public Connection getConnection(String username, String password) throws SQLException {
return this.doGetConnection(username, password);
}
In fact, both methods point to an internal doGetConnection method. Let's continue:
private Connection doGetConnection(String username, String password) throws SQLException {
Properties props = new Properties();
if (this.driverProperties != null) {
props.putAll(this.driverProperties);
}
if (username != null) {
props.setProperty("user", username);
}
if (password != null) {
props.setProperty("password", password);
}
return this.doGetConnection(props);
}
First, it adds the connection information of the database to the Properties object for storage, and gives it to the next doGetConnection for processing. The dolls are finished. Then, let's look at the next layer of source code:
private Connection doGetConnection(Properties properties) throws SQLException {
//If the driver is not initialized, it needs to be initialized first. A Map is maintained internally to record the initialization information, which will not be introduced here
this.initializeDriver();
//Traditional method of obtaining connection
Connection connection = DriverManager.getConnection(this.url, properties);
//Additional configuration of the connection
this.configureConnection(connection);
return connection;
}
Here, the Connection object is returned, and this object is created through DriverManager. Therefore, the non pooled data source implementation still uses the traditional Connection creation method. Let's next look at the pooled data source implementation, which is PooledDataSource class:
public class PooledDataSource implements DataSource {
private static final Log log = LogFactory.getLog(PooledDataSource.class);
private final PoolState state = new PoolState(this);
private final UnpooledDataSource dataSource;
protected int poolMaximumActiveConnections = 10;
protected int poolMaximumIdleConnections = 5;
protected int poolMaximumCheckoutTime = 20000;
protected int poolTimeToWait = 20000;
protected int poolMaximumLocalBadConnectionTolerance = 3;
protected String poolPingQuery = "NO PING QUERY SET";
protected boolean poolPingEnabled;
protected int poolPingConnectionsNotUsedFor;
private int expectedConnectionTypeCode;
We find that the definition here is much more complex than the implementation of non pooling, because it also considers the problem of concurrency, how to store a large number of link objects reasonably and how to allocate them reasonably. Therefore, its playing method is very advanced.
First of all, it stores an UnpooledDataSource. This object is created during construction. In fact, the creation of Connection depends on the database driver. We will analyze it later. First, let's see how it implements the interface method:
public Connection getConnection() throws SQLException {
return this.popConnection(this.dataSource.getUsername(), this.dataSource.getPassword()).getProxyConnection();
}
public Connection getConnection(String username, String password) throws SQLException {
return this.popConnection(username, password).getProxyConnection();
}
It can be seen that it calls the popConnection() method to obtain the connection object, and then performs a proxy. We can guess that the whole connection pool may be implemented by a collection type structure similar to the stack. Then let's take a look at the popConnection method:
private PooledConnection popConnection(String username, String password) throws SQLException {
boolean countedWait = false;
//The returned object is PooledConnection,
PooledConnection conn = null;
long t = System.currentTimeMillis();
int localBadConnectionCount = 0;
while(conn == null) {
synchronized(this.state) { //Lock, because many threads may need to obtain the connection object
PoolState var10000;
//PoolState stores two lists, one is the free List and the other is the active List
if (!this.state.idleConnections.isEmpty()) { //When there is an idle Connection, you can directly assign a Connection
conn = (PooledConnection)this.state.idleConnections.remove(0); //Take the first element from ArrayList
if (log.isDebugEnabled()) {
log.debug("Checked out connection " + conn.getRealHashCode() + " from pool.");
}
//If there are no more connections to allocate, check whether the number of active connections reaches the maximum allocation limit. If not, add a new connection
} else if (this.state.activeConnections.size() < this.poolMaximumActiveConnections) {
//Note that after new, you don't immediately insert it into the List, but save some basic information
//We found that we created a Connection object by relying on UnpooledDataSource and encapsulated it into PooledConnection
conn = new PooledConnection(this.dataSource.getConnection(), this);
if (log.isDebugEnabled()) {
log.debug("Created connection " + conn.getRealHashCode() + ".");
}
//If the above conditions are not met, you can only look for the previous connection to see if there is any stuck link (due to network problems, the previous connection may be stuck all the time, but under normal circumstances, it has long ended and can be used, so this is equivalent to optimization, which is also a way to pick up leaks)
} else {
//Get the oldest connection created
PooledConnection oldestActiveConnection = (PooledConnection)this.state.activeConnections.get(0);
long longestCheckoutTime = oldestActiveConnection.getCheckoutTime();
//Determine whether the maximum use time is exceeded
if (longestCheckoutTime > (long)this.poolMaximumCheckoutTime) {
//Timeout Statistics (unimportant)
++this.state.claimedOverdueConnectionCount;
var10000 = this.state;
var10000.accumulatedCheckoutTimeOfOverdueConnections += longestCheckoutTime;
var10000 = this.state;
var10000.accumulatedCheckoutTime += longestCheckoutTime;
//Remove this link information from the active list
this.state.activeConnections.remove(oldestActiveConnection);
//If the transaction is started, it needs to be rolled back
if (!oldestActiveConnection.getRealConnection().getAutoCommit()) {
try {
oldestActiveConnection.getRealConnection().rollback();
} catch (SQLException var15) {
log.debug("Bad connection. Could not roll back");
}
}
//Here, a new Connection is directly created based on the previous Connection object (note that the previous Connection object is still used, but it is only repackaged)
conn = new PooledConnection(oldestActiveConnection.getRealConnection(), this);
conn.setCreatedTimestamp(oldestActiveConnection.getCreatedTimestamp());
conn.setLastUsedTimestamp(oldestActiveConnection.getLastUsedTimestamp());
//be overdue
oldestActiveConnection.invalidate();
if (log.isDebugEnabled()) {
log.debug("Claimed overdue connection " + conn.getRealHashCode() + ".");
}
} else {
//It's really useless. It's stuck (blocked)
//Then record how many threads are waiting for the current task to finish
try {
if (!countedWait) {
++this.state.hadToWaitCount;
countedWait = true;
}
if (log.isDebugEnabled()) {
log.debug("Waiting as long as " + this.poolTimeToWait + " milliseconds for connection.");
}
long wt = System.currentTimeMillis();
this.state.wait((long)this.poolTimeToWait); //If you wait more than the waiting time, you can only give up
//Note that in this case, con is null
var10000 = this.state;
var10000.accumulatedWaitTime += System.currentTimeMillis() - wt;
} catch (InterruptedException var16) {
break;
}
}
}
//After the previous operation, it has been successfully assigned to the connection object
if (conn != null) {
if (conn.isValid()) { //Is it valid
if (!conn.getRealConnection().getAutoCommit()) { //Clean up previous transaction operations
conn.getRealConnection().rollback();
}
conn.setConnectionTypeCode(this.assembleConnectionTypeCode(this.dataSource.getUrl(), username, password));
conn.setCheckoutTimestamp(System.currentTimeMillis());
conn.setLastUsedTimestamp(System.currentTimeMillis());
//Add to active table
this.state.activeConnections.add(conn);
//Statistics (unimportant)
++this.state.requestCount;
var10000 = this.state;
var10000.accumulatedRequestTime += System.currentTimeMillis() - t;
} else {
//Invalid connection, throw exception directly
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") was returned from the pool, getting another connection.");
}
++this.state.badConnectionCount;
++localBadConnectionCount;
conn = null;
if (localBadConnectionCount > this.poolMaximumIdleConnections + this.poolMaximumLocalBadConnectionTolerance) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Could not get a good connection to the database.");
}
throw new SQLException("PooledDataSource: Could not get a good connection to the database.");
}
}
}
}
}
//Finally, what should I do? If I can't get the connection, I can throw an exception directly
if (conn == null) {
if (log.isDebugEnabled()) {
log.debug("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
}
throw new SQLException("PooledDataSource: Unknown severe error condition. The connection pool returned a null connection.");
} else {
return conn;
}
}
After the above fierce operation, we can get the following information:
It is possible to get the policy directly from the free connection list if it is created.
Then the connection object must be placed in the active list (state. Active connections)
There must be a question. Now we know that getting a link will directly enter the active list. What will happen if a connection is closed? Let's see that after this method returns, it will call getProxyConnection to get a proxy object, which is actually PooledConnection class:
class PooledConnection implements InvocationHandler {
private static final String CLOSE = "close";
private static final Class<?>[] IFACES = new Class[]{Connection.class};
private final int hashCode;
//It will record which data source it was created from
private final PooledDataSource dataSource;
//Connection object ontology
private final Connection realConnection;
//Proxy linked object
private final Connection proxyConnection;
...
It directly proxies the Connection object passed in the construction method and is also implemented by using the dynamic proxy of JDK. Let's see how it proxies:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
//If the close method of the Connection object is called,
if ("close".equals(methodName)) {
//Instead of closing the connection (which is why the proxy is used), the pushConnection method of the previous data source is called to change the connection to idle state
this.dataSource.pushConnection(this);
return null;
} else {
try {
if (!Object.class.equals(method.getDeclaringClass())) {
this.checkConnection();
//The connection is checked for availability before any operation is performed
}
//What should I do
return method.invoke(this.realConnection, args);
} catch (Throwable var6) {
throw ExceptionUtil.unwrapThrowable(var6);
}
}
}
Finally, let's take a look at the pushConnection method:
protected void pushConnection(PooledConnection conn) throws SQLException {
synchronized(this.state) { //The old rule is to lock it first
//Remove this connection from the active list first
this.state.activeConnections.remove(conn);
//Determine whether this link is available
if (conn.isValid()) {
PoolState var10000;
//Check whether the capacity of the idle list is full (you can't go back if the capacity is full)
if (this.state.idleConnections.size() < this.poolMaximumIdleConnections && conn.getConnectionTypeCode() == this.expectedConnectionTypeCode) {
var10000 = this.state;
var10000.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
//Take out the only useful Connection object and recreate a PooledConnection
PooledConnection newConn = new PooledConnection(conn.getRealConnection(), this);
//Put it into the idle list and recycle it successfully
this.state.idleConnections.add(newConn);
newConn.setCreatedTimestamp(conn.getCreatedTimestamp());
newConn.setLastUsedTimestamp(conn.getLastUsedTimestamp());
conn.invalidate();
if (log.isDebugEnabled()) {
log.debug("Returned connection " + newConn.getRealHashCode() + " to pool.");
}
this.state.notifyAll();
} else {
var10000 = this.state;
var10000.accumulatedCheckoutTime += conn.getCheckoutTime();
if (!conn.getRealConnection().getAutoCommit()) {
conn.getRealConnection().rollback();
}
conn.getRealConnection().close();
if (log.isDebugEnabled()) {
log.debug("Closed connection " + conn.getRealHashCode() + ".");
}
conn.invalidate();
}
} else {
if (log.isDebugEnabled()) {
log.debug("A bad connection (" + conn.getRealHashCode() + ") attempted to return to the pool, discarding connection.");
}
++this.state.badConnectionCount;
}
}
}
In this way, we have fully understood the execution process of Mybatis's pooled data source.
However, no matter how the Connection management mode changes and no matter how advanced the data source is, we should know that it will eventually use DriverManager to create the Connection object, and the Connection object provided by DriverManager is also used.
Integrate Mybatis framework
By understanding the data sources, we have made it clear that Mybatis is actually using its own data sources (there are many data sources, and we will talk about others later). By default, it uses a pooled data source, which stores a lot of connection objects in advance.
Let's take a look at how to better integrate Mybatis with Spring. For example, we now want to hand over SqlSessionFactory to IoC container for management, rather than creating tool classes to manage it ourselves (we have been using tool classes to manage and create sessions before)
Import dependencies first:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.25</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis-spring</artifactId>
<version>2.0.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.3.13</version>
</dependency>
In the mybatis spring dependency, the SqlSessionTemplate class is provided for us. In fact, it is an officially encapsulated tool class. We can register it as Bean, so that we can ask for it from the IoC container at any time instead of writing a tool class ourselves. We can directly create it in the configuration class:
@Configuration
@ComponentScan("com.test")
public class TestConfiguration {
@Bean
public SqlSessionTemplate sqlSessionTemplate() throws IOException {
SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsReader("mybatis-config.xml"));
return new SqlSessionTemplate(factory);
}
}
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<environments default="development">
<environment id="development">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="com.mysql.cj.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/study"/>
<property name="username" value="root"/>
<property name="password" value="123456"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper class="com.test.mapper.TestMapper"/>
</mappers>
</configuration>
public static void main(String[] args) {
ApplicationContext context = new AnnotationConfigApplicationContext(TestConfiguration.class);
SqlSessionTemplate template = context.getBean(SqlSessionTemplate.class);
TestMapper testMapper = template.getMapper(TestMapper.class);
System.out.println(testMapper.getStudent());
}
@Mapper
public interface TestMapper {
@Select("select * from student where sid = 1")
Student getStudent();
}
@Data
public class Student {
int sid;
String name;
String sex;
}
Finally, the Student entity class is successfully obtained, which proves that SqlSessionTemplate is successfully registered as a Bean and can be used.
Although this is very convenient, it is not convenient enough. We still need to get Mapper objects manually. Can we get the corresponding Mapper objects directly? We hope Spring can directly help us manage all mappers. When necessary, we can get them directly from the container. We can add annotations directly above the configuration class:
@MapperScan("com.test.mapper")
In this way, Spring will automatically scan all mappers and register their implementations as beans. Now we can get them directly through the container:
public static void main(String[] args) throws InterruptedException {
ApplicationContext context = new AnnotationConfigApplicationContext(TestConfiguration.class);
TestMapper mapper = context.getBean(TestMapper.class);
System.out.println(mapper.getStudent());
}
Please note that there must be a SqlSessionTemplate or a Bean of SqlSessionFactoryBean, otherwise it will fail to initialize (after all, the link information of the database is required)
Let's continue. If we want to directly remove the configuration file of Mybatis, how can we implement it?
We can use the SqlSessionFactoryBean class:
@Configuration
@ComponentScan("com.test")
@MapperScan("com.test.mapper")
public class TestConfiguration {
@Bean
public DataSource dataSource(){
return new PooledDataSource("com.mysql.cj.jdbc.Driver",
"jdbc:mysql://localhost:3306/study", "root", "123456");
}
@Bean
public SqlSessionFactoryBean sqlSessionFactoryBean(@Autowired DataSource dataSource){
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(dataSource);
return bean;
}
}
First, we need to create an implementation class of the data source, because this is the most basic information of the database, and then give it to the SqlSessionFactoryBean instance. In this way, we are equivalent to directly configuring SqlSessionFactory through the IoC container at the beginning. We only need to pass in the implementation of a DataSource.
The Mapper configuration file can also be deleted and re run normally.
From here on, through the IoC container, Mybatis no longer needs to use the configuration file. After that, the configuration file of Mybatis will not appear in Spring based development.