From: earthly Wanderer: procedural ape focusing on technical research. If you have any copyright problems, please leave a message.
You can check the relevant syntax through the help command and preview it in advance to facilitate a deeper understanding
Formal service
Let's take a look at the previous table structure
create table if not exists tb_user(
id bigint primary key auto_increment comment 'Primary key',
login_name varchar(48) comment 'Login account',
login_pwd char(36) comment 'Login password',
account decimal(20, 8) comment 'Account balance',
login_ip int comment 'Sign in IP'
) charset=utf8mb4 engine=InnoDB comment 'User table';
Copy codeinsert data
Before inserting, let's take a look at how we usually use it
insert into table_name[(column_name[,column_name] ...)] value|values (value_list) [, (value_list)] Copy code
In fact, there are so many commonly used ones. Let's take an example to understand
Insert a single piece of data into all fields
insert into tb_user value(1, 'admiun', 'abc123456', 2000, inet_aton('127.0.0.1'));
Copy codeThis inserts a piece of data:
- auto_increment: Auto increment key. When inserting data, you can not specify data for the current column. By default, we recommend setting auto increment for the primary key
- inet_aton: ip conversion function, corresponding to inet_ntoa()
It should also be noted that if the same primary key exists, an error will occur during insertion
# Duplicate primary key Duplicate entry '4' for key 'tb_user.PRIMARY' Copy code
Insert multiple pieces of data in the specified field
insert into tb_user(login_name, login_pwd) values('admin1', 'abc123456'),('admin2', 'abc123456')
Copy code
You can see that the data has been inserted, and the columns that are not filled with data have been NULL filled. About this, we can specify the DEFAULT value through DEFAULT when creating the table, which is used at this time
alter table tb_user add column email varchar(50) default 'test@sina.com' comment 'mailbox' Copy code

Nothing is more convincing than doing it
ON DUPLICATE KEY UPDATE
Here's another point. It's not used very much, but it's quite practical: ON DUPLICATE KEY UPDATE
That is to say, if there is a duplicate primary key in the data table, update it. Let's see:
insert into tb_user(id, login_name, email) value(4, 'test', 'super@sina.com') on duplicate key update login_name = values(login_name), email = values(email); Copy code

Comparing the above data, it is easy to find that the data are different
- Values: the data of the previously inserted field will be taken out
insert into tb_user(id, login_name, email) values(4, 'test', 'super@sina.com'),(5, 'test5', 'test5@sinacom') on duplicate key update login_name = values(login_name), email = values(email); Copy code
Inserting multiple pieces of data is the same, so there is no mapping. Let's try it by ourselves
Modify data
Inserting data is relatively simple. Let's take a look at modifying data
First, in terms of update syntax, this is simpler:
update table_name set column_name=value_list (,column_name=value_list) where condition Copy code
Take chestnuts for example:
update tb_user set login_name = 'super@sina.com' where id = 1 Copy code
This modifies TB_ Loign numbered 1 under user_ Name's data
There can also be multiple conditions after where, which can be divided according to
Of course, if no query criteria are set, the data of the whole table will be modified by default
update tb_user set login_name = 'super@sina.com',account = 2000 Copy code
Well, the modification of data is over here. It's very simple
Delete data
Delete data is divided into
- Delete specified data
- Empty the entire table
If you just want to delete some data, you can delete it through delete, or take chestnuts for example:
delete from tb_user where login_ip is null; Copy code
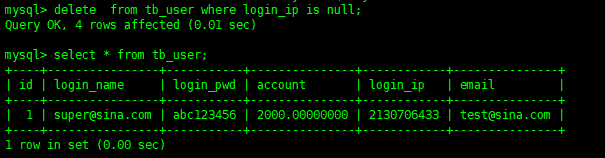
In this way, the data of the specified condition is deleted
So, what if we execute the deletion condition but do not set the condition? Let's take a look
First, execute the insert operation to insert several pieces of data
delete from tb_user ; Copy code
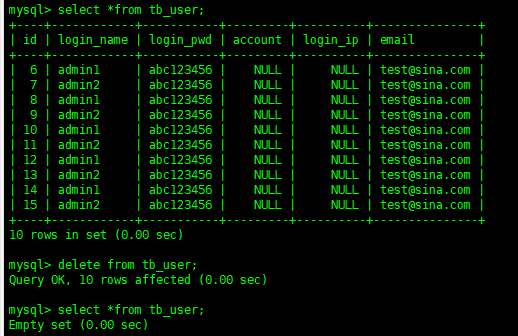
You can see that all the data has been deleted
But in fact, there is another way to empty the whole table, which is through truncate, which is more efficient
truncate tb_user; Copy code
Finally, there is no mapping. It must be no problem
Query data
The query data can be divided into many cases. The combined use can exist in N, so this is the most complex way. Let's introduce it below
In fact, from the perspective of syntax, the key points of query syntax will only include the following points:
SELECT [DISTINCT] select_expr [, select_expr] FROM table_name WHERE where_condition GROUP BY col_name HAVING where_condition ORDER BY col_name ASC | DESC LIMIT offset[, row_count] Copy code
With these key points in mind, the query is quite simple. Let's take a look at a simple operation first
Simple query
select * from tb_user; -- Sort by specified field asc: positive sequence desc: Reverse order select * from tb_user order by id desc; Copy code
A total of 44 pieces of data were inserted without all screenshots

The current SQL will query all the data in the table, and the * following the select means: list all the fields. If we just want to list some columns, it's good to replace it with the specified field name:
select id, login_name, login_pwd from tb_user; Copy code

It's that simple
Of course, remember this keyword: DISTINCT, let's experiment:
select distinct login_name from tb_user; Copy code
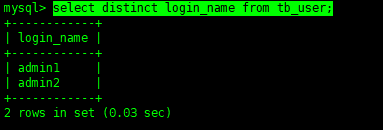
The meaning is already obvious. Yes, it is the de duplication operation.
But what I want to tell you is that if the distinct keyword works on multiple fields, it will only take effect if it is repeated when multiple fields are combined. For example:
select distinct id,login_name from tb_user; Copy code
Only in ID + login_ It will take effect when the name is repeated
Aggregate function
The built-in aggregation function in MySQL performs calculations on a group of data and returns a single value. It has a special role in special scenarios
where condition can be added
-- Query the number of data entries in the current table select count(*) from tb_user; -- Query the largest column in the current table select max(id) from tb_user; -- Query the smallest column in the current table select min(id) from tb_user; -- Query the average value of the specified column in the current table select avg(account) from tb_user; -- Queries the sum of the specified columns in the current table select sum(account) from tb_user; Copy code
In addition to aggregate functions, it also contains many ordinary functions, which will not be listed one by one here Official documents , check the details when using
Condition query
Seeing the first example, does it feel that the query is not so difficult. The above examples all query all the data. Now we need to add some conditions to filter. Here we use our where statement. Remember one thing:
- There can be more than one condition filter
Equivalent query
We can make conditional judgment in the following ways
select * from tb_user where login_name = 'admin1' and login_pwd = 'abc123456'; Copy code
In many cases, column_name = column_value is the more query method we use. This method can be called equivalent query,
Moreover, I noticed that before the condition, I associated it through and, and the little partner with good Java foundation must also remember & &, which means and
Since there is and, the opposite must be or, which means that as long as the two meet one of them
select * from tb_user where login_name = 'admin1' or login_pwd = 'abc123456'; Copy code
In addition to = matching, there are more ways, <, < =, >, >=
- What is different from our cognition is that < > means that it is not equal to
But these are used in the same way
Batch query
In some specific cases, if you want to query a batch of data, you can query through in
select * from tb_user where id in(1,2,3,4,5,6); Copy code
In in, it is equivalent to passing in a set and then querying the data of the specified set. In many cases, this sql can also be written like this
select * from tb_user where id in ( select id from tb_user where login_name = 'admin1' ); Copy code
In addition to in, there is not in. On the contrary: it means that the data to be queried does not contain these specified data
Fuzzy query
After reading the equivalent query, let's look at a fuzzy query:
- As long as the field data contains the queried data, the data can be matched
select * from tb_user where login_name like '%admin%'; select * from tb_user where login_name like '%admin'; select * from tb_user where login_name like 'admin%'; Copy code
like is the key member in our fuzzy query, and the following query keywords are divided into three cases:
- %Admin%:% with query keyword indicates that as long as the data contains admin, it can be matched
- %Any data can be matched from the beginning of admin to the end of admin
- Admin%: it must start with admin, and others are optional, so that the data can be matched
This method is more recommended. If the index is set for the query column, other methods will invalidate the index
Non null judgment
When querying the current table, we will find that some columns in the data are NULL values. If we want to filter these data during the query, we can do this:
select * from tb_user where account is not null; select * from tb_user where account is null; Copy code
Is not null is the key point. In contrast, is not null has the opposite meaning
Time judgment
In many cases, if we want to match queries by time period, we can do this:
tb_ There is no time field in the user table. A field is added here: create_time
select * from tb_user where create_time between '2021-04-01 00:00:00' and now(); Copy code
- **The now() * * function represents the current time
After between indicates the start time, and after and indicates the end time
Row to column
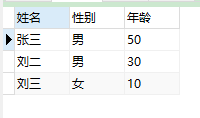
Let me talk about this query from an interview question:
I met such an interview question during my first interview in 14 years. In fact, my heart collapsed
The scenario is the same, but the SQL is different (focus on the key points and see the questions)
create table test( id int(10) primary key, type int(10) , t_id int(10), value varchar(5) ); insert into test values(100,1,1,'Zhang San'); insert into test values(200,2,1,'male'); insert into test values(300,3,1,'50'); insert into test values(101,1,2,'Liu er'); insert into test values(201,2,2,'male'); insert into test values(301,3,2,'30'); insert into test values(102,1,3,'Liu San'); insert into test values(202,2,3,'female'); insert into test values(302,3,3,'10'); Copy code
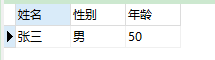
Please write out an SQL to show the following results:
full name Gender Age --------- -------- ---- Zhang San male 50 Liu er male 30 Liu San female 10 Copy code
Compared with conventional queries, it can be said that we need to redefine new attribute columns to display, so we need to complete the conversion of attribute columns through judgment
case
Step by step first. Since you need to judge, pass the case when .. then .. else .. End come
SELECT CASE type WHEN 1 THEN value END 'full name', CASE type WHEN 2 THEN value END 'Gender', CASE type WHEN 3 THEN value END 'Age' FROM test Copy code
Look, it finally became this virtue

Next, we need to aggregate all the data. According to the aggregation function we learned earlier, we can choose to use max()
SELECT max(CASE type WHEN 1 THEN value END) 'full name', max(CASE type WHEN 2 THEN value END) 'Gender', max(CASE type WHEN 3 THEN value END) 'Age' FROM test GROUP BY t_id; -- Second grammar SELECT max(CASE WHEN type = 1 THEN value END) 'full name', max(CASE WHEN type = 2 THEN value END) 'Gender', max(CASE WHEN type = 3 THEN value END) 'Age' FROM test GROUP BY t_id; Copy code
In this way, we have completed the row to column conversion. If we encounter such requirements later, we can also use the same method:
- The main thing is to find the law of the data
If it is just aggregation, only one piece of data can be displayed in the end, so we need to group here
It doesn't matter if you don't know about GROUP BY. We'll talk about it in detail later
if()
In addition to using case, there are other ways. Let's take a look
SELECT max(if(type = 1, value, '')) 'full name', max(if(type = 2, value, '')) 'Gender', max(if(type = 3, value, 0)) 'Age' FROM test GROUP BY t_id Copy code
if() means that if the condition is met, the first value will be returned; otherwise, the second value will be returned
In addition, if we want to query the default value for NULL data, we can operate through ifnull()
-- If`account`by`null`,Then it is displayed as 0 select ifnull(account, 0) from tb_user; Copy code
Paging sort
General paging
Now the above queries match all the qualified data. If there is a large number in the actual development, this method is likely to drag down the server, so we need to display the data page by page
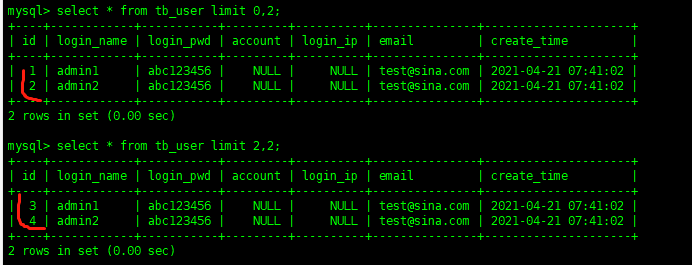
In MySQL, paging is performed through the limit keyword
select * from tb_user limit 0,2 Copy code
The former parameter indicates the start position, and the latter parameter indicates the number of display bars
Paging optimization
There is such a scenario: there are 2000W data in MySQL. Now we want to display the 10 data after 1000W in pages. The conventional way is as follows:
select * from tb_user limit 10000000,10 Copy code
Here, let's talk about how limit performs paging
-
When paging, limit will query the start position to be displayed, then discard the queried data, start from that position and continue to read the data of the number of display bars backward
-
Therefore, the larger the start position, the more data to be read and the longer the query time
Here is an optimization scheme: given the query range of the data, the best is the index column (the index column can speed up the query efficiency)
select * from tb_user where id > 10000000 limit 10; select * from tb_user where id > 10000000 limit 0 10; Copy code
If only one parameter is followed after limit, this parameter only indicates the number of display items
Association query
At present, our queries are all single table queries. Our SQL queries basically involve operations between multiple tables, so we need to perform multi table Association queries
Next, let's simply create a table, and then look at how to perform multi table Association query
create table tb_order(
id bigint primary key auto_increment,
user_id bigint comment 'User',
order_title varchar(50) comment 'Order name'
) comment 'Order form';
insert into tb_order(user_id, order_title) values(1, 'order-1'),(1, 'order-2'),(1, 'order-3'),(2, 'order-4'),(5, 'order-5'),(7, 'order-71');
Copy codeEquivalent query
If you want to perform association query, SQL operates like this
select * from tb_user, tb_order where tb_user.id = tb_order.user_id; Copy code
Equivalent query means that two tables contain the same column names, and the same column names are matched when querying
Compared with the equivalent query, there are also non equivalent queries: there is no same column name in the two tables, but a column is within the range of the column of the other table
We have already introduced the range query through * * between and ..** To query
Subquery
The so-called sub query can be understood as:
- Complete SQL statements nested in other SQL statements
Or the above query, let's change the way
select * from tb_order where user_id = (select id from tb_user where id = 1); select * from tb_order where user_id in ( select id from tb_user); Copy code
According to the different results returned by sub queries, sub queries can also be divided into different types
- SQL1 returns only one piece of data, and it can be called single line sub query if it is judged by equivalence during query
- SQL2 is obviously a multi row subquery
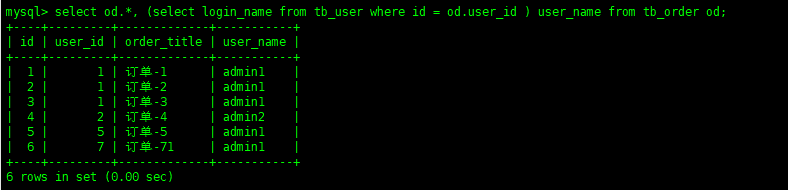
It can also be used after the where column in the query
select od.*, (select login_name from tb_user where id = od.user_id ) from tb_order od; Copy code
Left Association
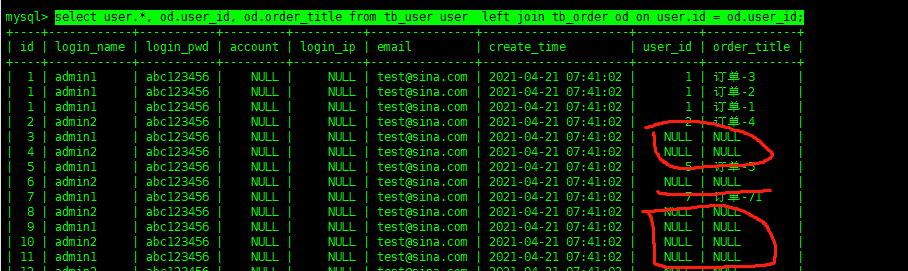
left join is the main key point in the left Association query, and the key fields in the two tables are associated through on. The data queried in this way is dominated by the left table. If there is no data in the associated table, NULL is returned
select user.*, od.user_id, od.order_title from tb_user user left join tb_order od on user.id = od.user_id; Copy code
Right Association
The right join is the main key point of the right association, and the data has been based on the association table on the right. Other operations are the same as the left Association
select user.*, od.user_id, od.order_title from tb_user user right join tb_order od on user.id = od.user_id; Copy code
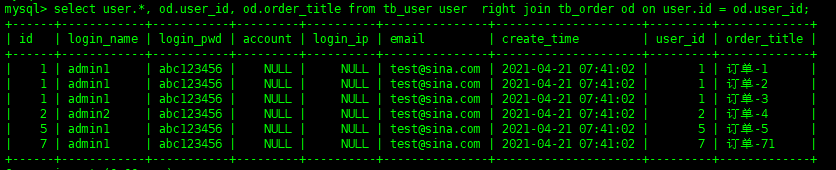
If there is no data on the left, it will not be displayed in the table on the left
If the query in the actual work is so simple, it's not very comfortable

Aggregate query
Earlier, we talked about aggregate functions, which perform calculations on a set of data and return a single value.
In many cases, if we want to group the data in the table through the aggregation function, we need to use group by to query
For the data in the current table, we can make a scenario:
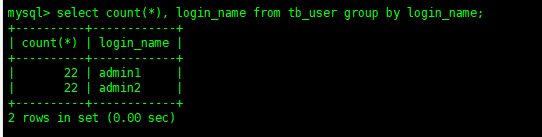
- Calculate the number of records for each login account in the table
select count(*), login_name from tb_user group by login_name Copy code
In fact, the use of each query syntax is very simple
If you want to filter the aggregated data by criteria, you can't use where to query. You need to filter by having
select count(*), login_name from tb_user group by login_name having login_name = 'admin1'; Copy code

It should also be noted that:
- If the current column is not grouped by group by, it cannot be queried by having
Grammatical problems

If we encounter such a problem during operation: This is because the display column contains columns that are not grouped, which is determined by sql_mode. Let's check the default settings first
The main thing is that the grammar is not standardized
-- ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION select @@sql_mode; Copy code

set sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'; Copy code
Just modify it according to the prompt
Last words
As I said earlier, at the database level, there is no difficulty in adding, deleting and modifying. What is more important is to check. How to query these data quickly and efficiently is our most important work. We still need to practice more
I haven't talked about many details. Let's see the official website documents later