In October 2021, Guangdong strong net cup, CRYPTO's RSA AND BASE?
Download the attachment, which is a txt file. Open it and find the RSA ciphertext and a codec table similar to base32, which also conforms to the hint of the title:
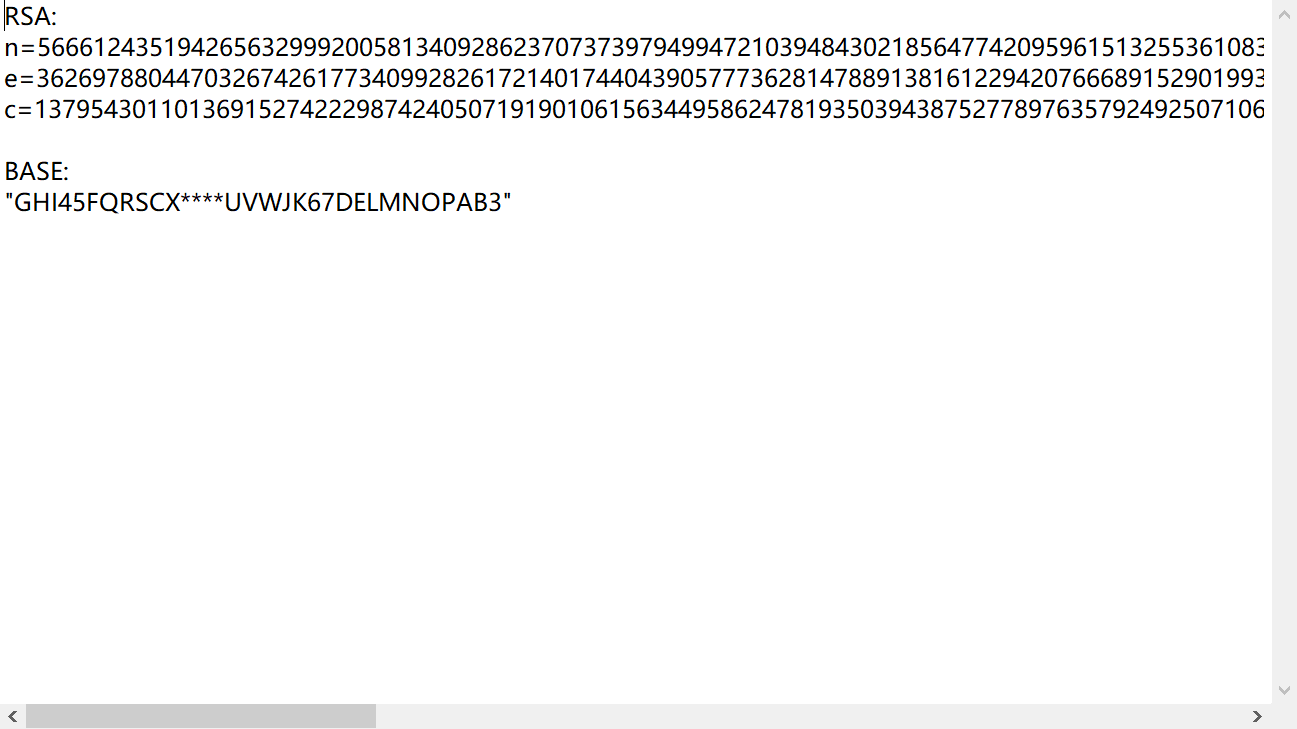
.
.
As usual, use CTF-RSA-TOOL to run the RSA problem and find that it can run out:

.
.
This should be the flag of one layer, and it looks like the four equal signs of BASE32. It can be guessed that it is the encryption of BASE32 variable code, and there are four unknown bits:

.
.
.
(first experience here)
Firstly, by comparing with the ciphertext and the traditional base32 code table, it can be found that the four letters 2tyz are missing. There are 24 permutations and combinations in total. The permutation and combination can be calculated with the following code:
list1=['2','T','Z','Y'] len1=len(list1) list2=[] w="" for i in list1: for j in list1: if j!=i: for k in list1: if k!=j and k!=i: for l in list1: if l !=k and l !=j and l !=i: w=i+j+k+l list2.append(w) print(list2) print(len(list2))
.
result:

.
.
(second experience here)
Then I got the encoding implementation of base32 to replace the code table. Because I couldn't find the python encoding implementation of base32 on the Internet, and I didn't know the GO language, I couldn't directly replace the encapsulated function code table, so I used my BabySmc technique of Guangzhou Yangcheng cup to convert it to the traditional base32 ciphertext through subscript correspondence.
Subscript correspondence method, which requires understanding the essence of base32 encryption and decryption.
Base32 encryption changes from 5 * 8 to 8 * 5, and the obtained five 8-bit numbers correspond to the range of 0 ~ 32, while the basic character table ABCDEFGHIJKLMNOPQRSTUVWXYZ234567 of base32 is just the mapping subscript corresponding to the range of 0 ~ 32.
During decryption, the number of each encrypted character in the range of 0 ~ 32 is also used to split decryption. The key is how to find the 5 digits during decryption? Is to find the corresponding subscript from 0 to 32 through base32.index('encrypted character ').
Therefore, the encrypted character form is only used to map the range of 0 ~ 32 of 5 digits according to the subscript. In essence, it is a subscript of 0 ~ 64.
Then we can use the one-to-one correspondence method to correspond the subscript of the new encrypted form in the title to the original base32 encrypted subscript, because the base32 online decryption tool can only find the subscript of 0 ~ 32 through base32.index('encrypted character ').
The script is as follows. Pay attention to extract '=' and add '=' at the end, because base32 decryption must be a multiple of 8.
import base64 #key1="GHI45FQRSCX****UVWJK67DELMNOPAB3" #2TYZ is missing key1="GHI45FQRSCX" #Deformation form 1 key2="UVWJK67DELMNOPAB3" #Deformation form 2 base32="ABCDEFGHIJKLMNOPQRSTUVWXYZ234567" #Traditional form key3="TCMDIEOH2MJFBLKHT2J7BLYZ2WUE5NYR2HNG" #Deformation ciphertext list1=['2TZY', '2TYZ', '2ZTY', '2ZYT', '2YTZ', '2YZT', 'T2ZY', 'T2YZ', 'TZ2Y', 'TZY2', 'TY2Z', 'TYZ2', 'Z2TY', 'Z2YT', 'ZT2Y', 'ZTY2', 'ZY2T', 'ZYT2', 'Y2TZ', 'Y2ZT', 'YT2Z', 'YTZ2', 'YZ2T', 'YZT2'] secret="" for i in list1: key4=key1+i+key2 #Final deformation form #print(key4) for m in key3: g=key4.index(m) secret+=base32[g] secret+='====' print(secret) print(base64.b32decode(secret)) secret=""
result:
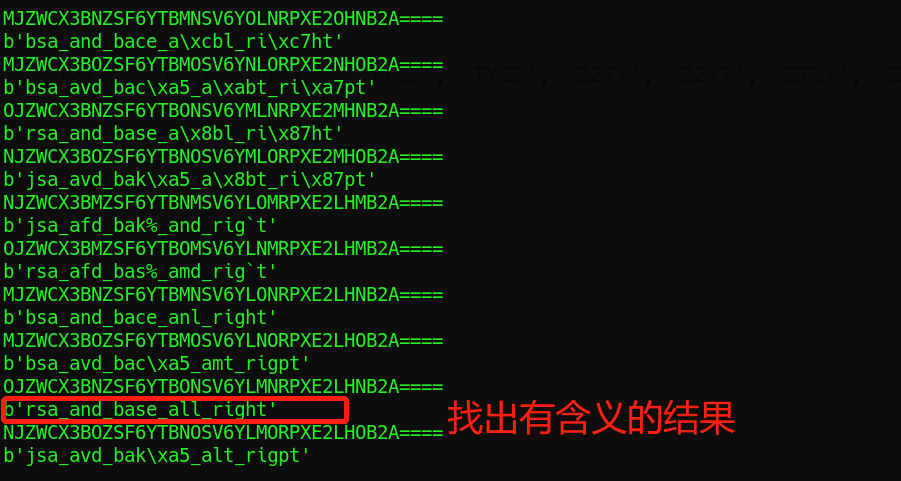
.
.
.
Summary:
1:
(first experience here)
Firstly, by comparing with the ciphertext and the traditional base32 code table, it can be found that the four letters 2tyz are missing. There are 24 permutations and combinations of these four letters. The permutation and combination can be calculated with the following code
list1=['2','T','Z','Y'] len1=len(list1) list2=[] w="" for i in list1: for j in list1: if j!=i: for k in list1: if k!=j and k!=i: for l in list1: if l !=k and l !=j and l !=i: w=i+j+k+l list2.append(w) print(list2) print(len(list2))
2:
(second experience here)
Then I got the encoding implementation of base32 to replace the code table. Because I couldn't find the python encoding implementation of base32 on the Internet, and I didn't know the GO language, I couldn't directly replace the encapsulated function code table, so I used my BabySmc technique of Guangzhou Yangcheng cup to convert it to the traditional base32 ciphertext through subscript correspondence.
.
Subscript correspondence method, which requires understanding the essence of base32 encryption and decryption.
Base32 encryption changes from 5 * 8 to 8 * 5, and the obtained five 8-bit numbers correspond to the range of 0 ~ 32, while the basic character table ABCDEFGHIJKLMNOPQRSTUVWXYZ234567 of base32 is just the mapping subscript corresponding to the range of 0 ~ 32.
.
During decryption, the number of each encrypted character in the range of 0 ~ 32 is also used to split decryption. The key is how to find the 5 digits during decryption? Is to find the corresponding subscript from 0 to 32 through base32.index('encrypted character ').
.
Therefore, the encrypted character form is only used to map the range of 0 ~ 32 of 5 digits according to the subscript. In essence, it is a subscript of 0 ~ 64.
.
Then we can use the one-to-one correspondence method to correspond the subscript of the new encrypted form in the title to the original base32 encrypted subscript, because the base32 online decryption tool can only find the subscript of 0 ~ 32 through base32.index('encrypted character ').
.
The script is as follows. Pay attention to extract '=' and add '=' at the end, because base32 decryption must be a multiple of 8.
Finish it! Salute!