2021SC@SDUSC
1. .dvd and dvm file
. dvm stores the metadata of DocValue field, such as DocValue offset.
. dvd stores DocValue data.
stay Solr4.8.0 In, dvd as well as dvm Used Lucene The encoding format is Lucene45DocValuesFormat. Similar to the previous file format, it contains Lucene45DocValuesProducer
And Lucene 45docvaluesconsumer to read and write the file.
@Override
public DocValuesConsumer fieldsConsumer(SegmentWriteState state) throws IOException {
return new Lucene45DocValuesConsumer(state, DATA_CODEC, DATA_EXTENSION, META_CODEC, META_EXTENSION);
}
@Override
public DocValuesProducer fieldsProducer(SegmentReadState state) throws IOException {
return new Lucene45DocValuesProducer(state, DATA_CODEC, DATA_EXTENSION, META_CODEC, META_EXTENSION);
}
Lucene 4.5 DocValues format encodes four types through the following strategies:
-
NUMERIC
- Delta compressed: an integer representing the document value is written to a 16k block. In each block, the minimum value is encoded, and each entry is an increment of the minimum value. All these increments use a bit compression method. See BlockPackedWriter below for more information.
- Table compressed: when the number of different values is very small (< 256), or if gap values are used in the document value sequence, solr will use a look-up table instead. The entry of each document value is replaced by the sequence number on the table. These sequence numbers are also compressed into PackedInts format by bit compression.
- GCD compressed: when all numbers share the same divisor, the maximum common denominator (GCD) will be calculated and stored using the delta compressed strategy.
-
BINARY
- Fixed width binary: use a fixed length, large spliced digit group. Each document value can be obtained directly with docID * length.
- Variable width binary: it is also a large concatenated digit group, but the end address of each document is added. These addresses are written from the start of a 16k block, and each entry has an increment of the average length. For each document, the deviation from the increment (actual average) is recorded.
- Prefix compressed binary: the value will be written into a chunk of 16 (byte) size. The first value is completely recorded, while other values share the prefix. The address of the chunk is written into a block of 16k size. Start writing from the starting position of the block, and use the average value as the increment for each entry. For each document, the deviation from the increment (actual average) will be recorded.
-
Sorted:
- The prefix compressed binary compression method is used to realize a mapping from serial number to repeated term, and the serial numbers of all documents use the numerical compression strategy shown above
-
SortedSet:
- The prefix compressed binary compression method is used to realize a mapping from sequence number to repeated term. At the same time, the list of sequence numbers and the indexes of all documents on this list use the numerical compression strategy shown above.
1.1 .dvm and dvd file format
First, let's introduce it File format of dvm:
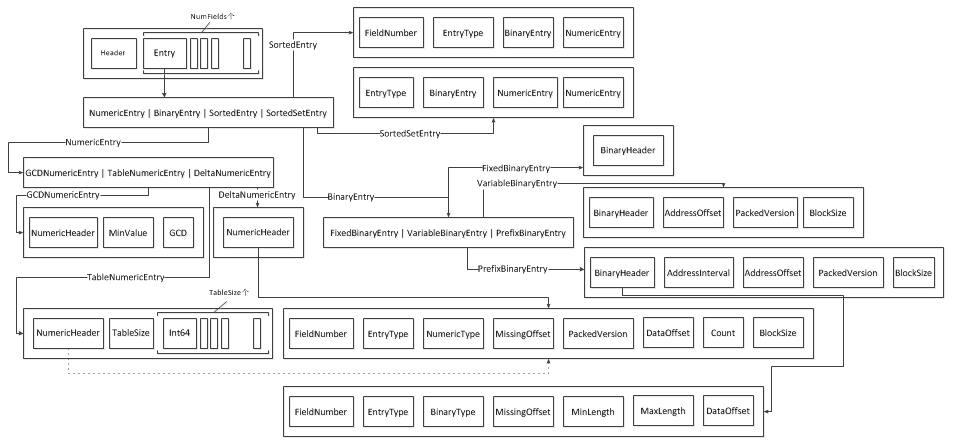
. The file structure of dvm is divided into several layers:
-
First floor: dvm is provided by header, numfields and footer
- Header and Footer are the same as before
- NumFields contains entries. Entry is the entry.
-
Level 2: Entry has four types: NumericEntry | BinaryEntry | SortedEntry | SortedSetEntry
-
Third floor:
- NumericEntry: there are three types: GCDNumericEntry | TableNumericEntry | DeltaNumericEntry
- GCDNumericEntry: contains numericheader, minValue and GCD
- TableNumericEntry: contains numericheader, tablesize and int64tablesize
- DeltaNumericEntry: contains a NumericHeader
- BinaryEntry: there are three types: FixedBinaryEntry | VariableBinaryEntry | PrefixBinaryEntry
- FixedBinaryEntry: contains BinaryHeader
- VariableBinaryEntry: contains binaryheader, addressoffset, packedversion and blocksize
- PrefixBinaryEntry: contains binaryheader, addressinterval, addressoffset, packedversion and blocksize
- NumericEntry: there are three types: GCDNumericEntry | TableNumericEntry | DeltaNumericEntry
-
SortedEntry: contains fieldnumber, entrytype, binaryentry and numericentry
-
SortedSetEntry: contains entrytype, binaryentry, numericentry, and numericentry
Same dvd files have several layers of structure:
-
Layer 1: header, < NumericData | BinaryData | sorteddata > NumFields. Footer is similar to dvm. NumFields contains one Data(SortedData, BinaryData, NumericData)
-
The second floor:
- Numeric data: DeltaCompressedNumerics | TableCompressedNumerics | GCDCompressedNumerics corresponds to the compression method of numerics mentioned above
- BinaryData: ByteDataLength,Addresses
- SortedData: FST
-
Third floor:
- DeltaCompressedNumerics: BlockPackedInts(blockSize=16k)
- TableCompressedNumerics: PackedInts
- GCDCompressedNumerics: BlockPackedInts(blockSize=16k)
- Addresses: MonotonicBlockPackedInts(blockSize=16k)
-
The SortedSet entry stores a list of serial numbers in BinaryData, uses a growing vLong type sequence, and encodes it with a difference.
1.2 .dvm and dvd code implementation
As mentioned earlier, Lucene45DocValuesFormat includes Lucene45DocValuesProducer and Lucene45DocValuesConsumer to read and write the file, so this section mainly takes Lucene45DocValuesProducer as an example to learn about dvm and dvd.
First, learn the initialization of Lucene 45 doc values producer: the main function is to read dvm files and dvd stream. Where is being read During the dvm file, Lucene45DocValuesProducer calls readFields(in, state.fieldInfos) to obtain entry information.
protected Lucene45DocValuesProducer(SegmentReadState state, String dataCodec, String dataExtension, String metaCodec, String metaExtension) throws IOException {
//. dvm file name
String metaName = IndexFileNames.segmentFileName(state.segmentInfo.name, state.segmentSuffix, metaExtension);
// read in the entries from the metadata file.
//Open dvm and get the inspection and, get the file stream,
ChecksumIndexInput in = state.directory.openChecksumInput(metaName, state.context);
//Get the number of document s of segment
this.maxDoc = state.segmentInfo.getDocCount();
boolean success = false;
try {
//obtain. dvm header
version = CodecUtil.checkHeader(in, metaCodec,
Lucene45DocValuesFormat.VERSION_START,
Lucene45DocValuesFormat.VERSION_CURRENT);
numerics = new HashMap<>();
ords = new HashMap<>();
ordIndexes = new HashMap<>();
binaries = new HashMap<>();
sortedSets = new HashMap<>();
//Read NumFields < entry >
readFields(in, state.fieldInfos);
//Join Footer
if (version >= Lucene45DocValuesFormat.VERSION_CHECKSUM) {
CodecUtil.checkFooter(in);
} else {
CodecUtil.checkEOF(in);
}
success = true;
} finally {
if (success) {
IOUtils.close(in);
} else {
IOUtils.closeWhileHandlingException(in);
}
}
success = false;
try {
//. dvd file name
String dataName = IndexFileNames.segmentFileName(state.segmentInfo.name, state.segmentSuffix, dataExtension);
//Open dvd file
data = state.directory.openInput(dataName, state.context);
//obtain. dvd header
final int version2 = CodecUtil.checkHeader(data, dataCodec,
Lucene45DocValuesFormat.VERSION_START,
Lucene45DocValuesFormat.VERSION_CURRENT);
if (version != version2) {
throw new CorruptIndexException("Format versions mismatch");
}
success = true;
} finally {
if (!success) {
IOUtils.closeWhileHandlingException(this.data);
}
}
//The size of the estimation class, that is, estimation dvd stream size
ramBytesUsed = new AtomicLong(RamUsageEstimator.shallowSizeOfInstance(getClass()));
}
Readfields (in, state. Fieldinfo) is mainly used to read the EntryType and select the method to read the subsequent Entry information according to its value,
The following methods are involved in the function:
- Numeric type readNumericEntry()
2.BinaryEntry type (readbinaryentry)
3.SortedSetEntry type readSortedField()
4.SortedSetEntry type: readSortedSetEntry(). Meanwhile, under this type, readFields also calls readSortedSetFieldWithAddresses and readSortedField respectively
private void readFields(IndexInput meta, FieldInfos infos) throws IOException {
//Read the number of the Entry. If the number is - 1, it means that this is the last Entry.
int fieldNumber = meta.readVInt();
while (fieldNumber != -1) {
// check should be: infos.fieldInfo(fieldNumber) != null, which incorporates negative check
// but docvalues updates are currently buggy here (loading extra stuff, etc): LUCENE-5616
if (fieldNumber < 0) {
// trickier to validate more: because we re-use for norms, because we use multiple entries
// for "composite" types like sortedset, etc.
throw new CorruptIndexException("Invalid field number: " + fieldNumber + " (resource=" + meta + ")");
}
//Read the EntryType to distinguish the type of Entry. 0 means numeric, 1 means binary, 2 means SORTEDENTRY, and 3 means SORTED_SETENTRY
byte type = meta.readByte();
if (type == Lucene45DocValuesFormat.NUMERIC) {
//Get the specific NumericEntry content and put it into the map with number as the key and NumericEntry as the value
numerics.put(fieldNumber, readNumericEntry(meta));
} else if (type == Lucene45DocValuesFormat.BINARY) {
//Get the specific BinaryEntry content and put it into the map with number as the key and BinaryEntry as the value
BinaryEntry b = readBinaryEntry(meta);
binaries.put(fieldNumber, b);
} else if (type == Lucene45DocValuesFormat.SORTED) {
//Read SortedEntry
readSortedField(fieldNumber, meta, infos);
} else if (type == Lucene45DocValuesFormat.SORTED_SET) {
//Read SortedSetEntry and put it into the map with number as the key and SortedSetEntry as the value
SortedSetEntry ss = readSortedSetEntry(meta);
sortedSets.put(fieldNumber, ss);
//Whether the standard storage ordered collection is through the indirect conversion of address, SORTED_SET_WITH_ADDRESSES is a docid - > address > ord mapping
if (ss.format == SORTED_SET_WITH_ADDRESSES) {
readSortedSetFieldWithAddresses(fieldNumber, meta, infos);
//SORTED_SET_SINGLE_VALUED_SORTED stores only the value of docid - > ord
} else if (ss.format == SORTED_SET_SINGLE_VALUED_SORTED) {
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.SORTED) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
readSortedField(fieldNumber, meta, infos);
} else {
throw new AssertionError();
}
} else {
throw new CorruptIndexException("invalid type: " + type + ", resource=" + meta);
}
//Read next Entry
fieldNumber = meta.readVInt();
}
}
- readNumericEntry()
static NumericEntry readNumericEntry(IndexInput meta) throws IOException {
NumericEntry entry = new NumericEntry();
entry.format = meta.readVInt(); //NumericType, the encoding method of Numeric
entry.missingOffset = meta.readLong(); //MissingOffset indicates the document in which the field is missing. If - 1, there is no missing document field
entry.packedIntsVersion = meta.readVInt(); //PackedVersion the version of the packed integer
entry.offset = meta.readLong(); //DataOffset points to Pointer to the starting position of data in dvd file
entry.count = meta.readVLong(); //Count the number of written values
entry.blockSize = meta.readVInt(); //BlockSize the size of the packed integer
switch(entry.format) {
case GCD_COMPRESSED: //GCD compressed (maximum common divisor compression)
entry.minValue = meta.readLong(); //MinValue
entry.gcd = meta.readLong(); //GCD
break;
case TABLE_COMPRESSED: //Table compressed
if (entry.count > Integer.MAX_VALUE) {
throw new CorruptIndexException("Cannot use TABLE_COMPRESSED with more than MAX_VALUE values, input=" + meta);
}
final int uniqueValues = meta.readVInt(); //TableSize
if (uniqueValues > 256) { //TableSize must be less than 256
throw new CorruptIndexException("TABLE_COMPRESSED cannot have more than 256 distinct values, input=" + meta);
}
entry.table = new long[uniqueValues]; //TableSize Long
for (int i = 0; i < uniqueValues; ++i) {
entry.table[i] = meta.readLong();
}
break;
case DELTA_COMPRESSED: //Delta compressed
break;
default:
throw new CorruptIndexException("Unknown format: " + entry.format + ", input=" + meta);
}
return entry;
}
- BinaryEntry()
static BinaryEntry readBinaryEntry(IndexInput meta) throws IOException {
BinaryEntry entry = new BinaryEntry();
entry.format = meta.readVInt(); //BinaryType type
entry.missingOffset = meta.readLong(); //Missing representation, same as NuericEntry
entry.minLength = meta.readVInt(); //The minimum and maximum values of the length of the bit group that stores values of type Binary.
//If the two values are equal, then all values are of fixed size,
//And can be calculated through DataOffset + (docID * length).
//Otherwise, the value of Binary is indefinite
entry.maxLength = meta.readVInt();
entry.count = meta.readVLong();
entry.offset = meta.readLong(); //Offset of actual binary number
switch(entry.format) {
case BINARY_FIXED_UNCOMPRESSED: //Fixed-width Binary
break;
case BINARY_PREFIX_COMPRESSED: //Variable-width Binary
entry.addressInterval = meta.readVInt();
entry.addressesOffset = meta.readLong();
entry.packedIntsVersion = meta.readVInt();
entry.blockSize = meta.readVInt();
break;
case BINARY_VARIABLE_UNCOMPRESSED: //Prefix-compressed Binary
entry.addressesOffset = meta.readLong();
entry.packedIntsVersion = meta.readVInt();
entry.blockSize = meta.readVInt();
break;
default:
throw new CorruptIndexException("Unknown format: " + entry.format + ", input=" + meta);
}
return entry;
}
- readSortedSetFieldWithAddresses()
private void readSortedSetFieldWithAddresses(int fieldNumber, IndexInput meta, FieldInfos infos) throws IOException {
// sortedset = binary + numeric (addresses) + ordIndex
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.BINARY) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
BinaryEntry b = readBinaryEntry(meta);
binaries.put(fieldNumber, b);
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
NumericEntry n1 = readNumericEntry(meta);
ords.put(fieldNumber, n1);
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) {
throw new CorruptIndexException("sortedset entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
NumericEntry n2 = readNumericEntry(meta);
ordIndexes.put(fieldNumber, n2);
}
- readSortedField
private void readSortedField(int fieldNumber, IndexInput meta, FieldInfos infos) throws IOException {
// sorted = binary + numeric
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.BINARY) {
throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
BinaryEntry b = readBinaryEntry(meta);
binaries.put(fieldNumber, b);
if (meta.readVInt() != fieldNumber) {
throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
if (meta.readByte() != Lucene45DocValuesFormat.NUMERIC) {
throw new CorruptIndexException("sorted entry for field: " + fieldNumber + " is corrupt (resource=" + meta + ")");
}
NumericEntry n = readNumericEntry(meta);
ords.put(fieldNumber, n);
}
As mentioned above dvm file reading, then next learn how to do it dvd file reading.