Author: Wu Yuntao, senior engineer of Tencent CSIG
Introduction
Recently, I sorted out how to use Flink to realize real-time statistics of UV and PV indicators, and communicated with colleagues in the micro vision Department of the company. Then we simplified the scenario and found that it would be more convenient to use Flink SQL to realize the statistics of these indicators.
I. solution description
1.1 general
In this scheme, combined with the self built Kafka cluster, Tencent cloud computing Oceanus (Flink) and cloud database Redis, the UV and PV indicators of blogs, shopping and other websites are visually analyzed in real time. The analysis indicators include the number of independent visitors (UV), product clicks (PV), conversion rate (conversion rate = transaction times / clicks), etc.
Introduction to related concepts: UV (Unique Visitor): the number of independent visitors. A client visiting your website is a visitor. If a user visits the same page five times, the UV of the page will only be increased by 1, because UV counts the number of users after de duplication, not the number of visits. PV (Page View) : number of hits or page views. If the user visits the same page for 5 times, the PV of the page will be increased by 5.
1.2 scheme structure and advantages
According to the above real-time index statistics scenario, the following architecture diagram is designed:

List of products involved:
- Self built Kafka cluster of local data center (IDC)
- Private network VPC
- Private line access / cloud networking / VPN connection / peer-to-peer connection
- Flow calculation Oceanus (Flink)
- Cloud database Redis
II. Pre preparation
Purchase the required Tencent cloud resources and get through the network. The self built Kafka cluster needs to adopt VPN connection, special line connection or peer-to-peer connection according to the region where the cluster is located to realize network interconnection.
2.1 create a private network VPC
The private network (VPC) is a logically isolated network space customized on Tencent cloud. When building services such as Oceanus cluster and Redis components, it is recommended to select the same VPC before the network can communicate. Otherwise, the network needs to be connected by means of peer-to-peer connection, NAT gateway and VPN. Please refer to the steps of creating a private network Help documentation.
2.2 create Oceanus cluster
Stream computing Oceanus is a powerful tool for real-time analysis of big data product ecosystem. It is an enterprise level real-time big data analysis platform based on Apache Flink with the characteristics of one-stop development, seamless connection, sub second delay, low cost, security and stability. Stream computing Oceanus aims to maximize the value of enterprise data and accelerate the construction process of real-time digitization of enterprises .
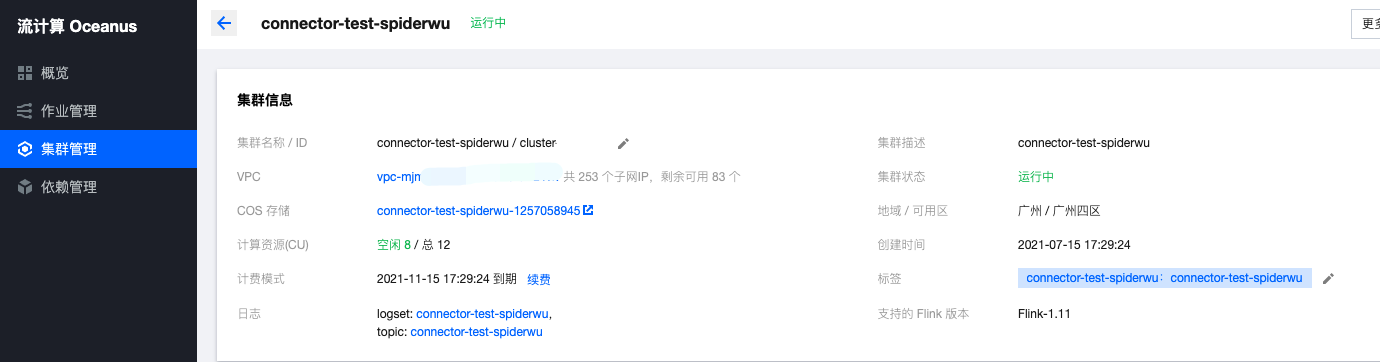
Create a cluster on the [cluster management] - [new cluster] page of Oceanus console, select region, availability area, VPC, log, storage, and set the initial password. The VPC and subnet use the newly created network. After creation, Flink's cluster is as follows:
2.3 create Redis cluster
stay Redis console On the [new instance] page of, create a cluster, select the same private network VPC in the same region and region as other components, and select the same subnet here.

2.4 configure self built Kafka cluster
2.4.1 modify self built Kafka cluster configuration
When connecting a self built Kafka cluster, the bootstrap servers parameter often uses hostname instead of ip to connect. However, the Oceanus cluster on Tencent cloud connected with a self built Kafka cluster is a fully managed cluster. The mapping relationship between the hostname and ip of the self built cluster cannot be resolved on the nodes of the Oceanus cluster, so it is necessary to change the listener address from hostname to ip address.
Configure the advertised.listeners parameter in the config/server.properties configuration file as the IP address. Example:
# 0.10.X and later advertised.listeners=PLAINTEXT://10.1.0.10:9092 # Versions before 0.10.X advertised.host.name=PLAINTEXT://10.1.0.10:9092
Restart the Kafka cluster after modification.
! if you use a self built zookeeper address on the cloud, you also need to change the hostname in zk configuration to the IP address form.
2.4.2 sending analog data to topic
In this case, topic is uvpv demo.
1) Kafka client
Enter the self built Kafka cluster node, start the Kafka client and simulate sending data.
./bin/kafka-console-producer.sh --broker-list 10.1.0.10:9092 --topic uvpv-demo
>{"record_type":0, "user_id": 2, "client_ip": "100.0.0.2", "product_id": 101, "create_time": "2021-09-08 16:20:00"}
>{"record_type":0, "user_id": 3, "client_ip": "100.0.0.3", "product_id": 101, "create_time": "2021-09-08 16:20:00"}
>{"record_type":1, "user_id": 2, "client_ip": "100.0.0.1", "product_id": 101, "create_time": "2021-09-08 16:20:00"}
2) Send using script
Script 1: Java code reference: https://cloud.tencent.com/document/product/597/54834
Script 2: Python script. Refer to the python script in the previous case and modify it appropriately: Real time large screen analysis of live video scene based on Tencent cloud Oceanus
2.5 get through the self built IDC cluster to Tencent cloud network communication
The self built Kafka cluster connects Tencent cloud network, and can get through the network communication from the self built IDC to Tencent cloud through the first three ways below.
- Dedicated line access
It is applicable to the connection between Local Data Center IDC and Tencent cloud network. - Cloud networking
It is applicable to the connection between Local Data Center IDC and Tencent cloud network, as well as the connection between private network VPC in different regions on the cloud. - VPN connection
It is applicable to the connection between Local Data Center IDC and Tencent cloud network. - Peer to peer connection + NAT Gateway
It is suitable for VPC connection between private networks in different regions on the cloud, not for local IDC to Tencent cloud network.
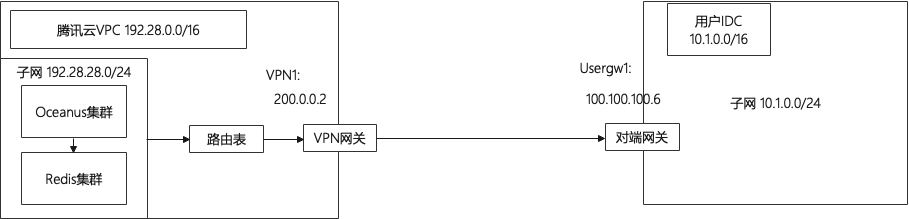
In this scheme, VPN connection is used to realize the communication between local IDC and cloud network. Reference link: Establish VPC to IDC connection (routing table)
The following network architecture diagram is drawn according to the scheme:
III. scheme realization
3.1 business objectives
The flow calculation Oceanus is used to realize the real-time statistics of website UV, PV and conversion rate indicators. Here, only the following three statistical indicators are listed:
- Number of unique visitors to the site. After processing, Oceanus stores the number of independent visitors in Redis through the set type, and also achieves the purpose of de duplication of the data of the same visitor.
- The number of hits on the product page of the website. After processing, Oceanus uses the list type to store page hits in Redis.
- Conversion rate (conversion rate = number of transactions / hits). After Oceanus processing, it can be stored in Redis with String.
3.2 source data format
Kafka topic: uvpv demo (browsing records)
| field | type | meaning |
|---|---|---|
| record_type | int | Customer number |
| user_id | varchar | Customer ip address |
| client_ip | varchar | room number |
| product_id | Int | Time of entering the room |
| create_time | timestamp | Creation time |
Kafka is stored internally in json format, and the data format is as follows:
# Browse records
{
"record_type":0, # 0 indicates browsing records
"user_id": 6,
"client_ip": "100.0.0.6",
"product_id": 101,
"create_time": "2021-09-06 16:00:00"
}
# Purchase record
{
"record_type":1, # 1 means purchase record
"user_id": 6,
"client_ip": "100.0.0.8",
"product_id": 101,
"create_time": "2021-09-08 18:00:00"
}
3.3 writing Flink SQL jobs
In the example, the acquisition logic of UV, PV and conversion is realized and written to the Sink end.
1. Define Source
CREATE TABLE `input_web_record` (
`record_type` INT,
`user_id` INT,
`client_ip` VARCHAR,
`product_id` INT,
`create_time` TIMESTAMP,
`times` AS create_time,
WATERMARK FOR times AS times - INTERVAL '10' MINUTE
) WITH (
'connector' = 'kafka', -- Optional 'kafka','kafka-0.11'. Pay attention to select the corresponding built-in Connector
'topic' = 'uvpv-demo',
'scan.startup.mode' = 'earliest-offset',
--'properties.bootstrap.servers' = '82.157.27.147:9092',
'properties.bootstrap.servers' = '10.1.0.10:9092',
'properties.group.id' = 'WebRecordGroup', -- Required parameter, Be sure to specify Group ID
'format' = 'json',
'json.ignore-parse-errors' = 'true', -- ignore JSON Structure Parsing exception
'json.fail-on-missing-field' = 'false' -- If set to true, If a missing field is encountered, an error will be reported and set to false The missing field is set to null
);
2. Define Sink
-- UV sink CREATE TABLE `output_uv` ( `userids` STRING, `user_id` STRING ) WITH ( 'connector' = 'redis', 'command' = 'sadd', -- Save using collection uv(Supported commands: set,lpush,sadd,hset,zadd) 'nodes' = '192.28.28.217:6379', -- redis Connection address,Cluster mode is used by multiple nodes'',''separate. -- 'additional-key' = '<key>', -- Used to specify hset and zadd of key. hset,zadd Must be set. 'password' = 'yourpassword' ); -- PV sink CREATE TABLE `output_pv` ( `pagevisits` STRING, `product_id` STRING, `hour_count` BIGINT ) WITH ( 'connector' = 'redis', 'command' = 'lpush', -- Save using list pv(Supported commands: set,lpush,sadd,hset,zadd) 'nodes' = '192.28.28.217:6379', -- redis Connection address,Cluster mode is used by multiple nodes'',''separate. -- 'additional-key' = '<key>', -- Used to specify hset and zadd of key. hset,zadd Must be set. 'password' = 'yourpassword' ); -- Conversion rate sink CREATE TABLE `output_conversion_rate` ( `conversion_rate` STRING, `rate` STRING ) WITH ( 'connector' = 'redis', 'command' = 'set', -- Save using list pv(Supported commands: set,lpush,sadd,hset,zadd) 'nodes' = '192.28.28.217:6379', -- redis Connection address,Cluster mode is used by multiple nodes'',''separate. -- 'additional-key' = '<key>', -- Used to specify hset and zadd of key. hset,zadd Must be set. 'password' = 'yourpassword' );
3. Business logic
-- Processed UV Indicators, statistics of all time UV INSERT INTO output_uv SELECT 'userids' AS `userids`, CAST(user_id AS string) AS user_id FROM input_web_record ; -- Processed and obtained PV Indicators, statistics every 10 minutes PV INSERT INTO output_pv SELECT 'pagevisits' AS pagevisits, CAST(product_id AS string) AS product_id, SUM(product_id) AS hour_count FROM input_web_record WHERE record_type = 0 GROUP BY HOP(times, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE), product_id, user_id; -- Process and obtain the conversion index, and count the conversion rate every 10 minutes INSERT INTO output_conversion_rate SELECT 'conversion_rate' AS conversion_rate, CAST( (((SELECT COUNT(1) FROM input_web_record WHERE record_type=0)*1.0)/SUM(a.product_id)) as string) FROM (SELECT * FROM input_web_record where record_type = 1) AS a GROUP BY HOP(times, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE), product_id;
3.4 result verification
Usually, the statistics of UV and PV indicators will be displayed through the Web site. Here, for simplicity, it is directly displayed in the Redis console Log in to query:
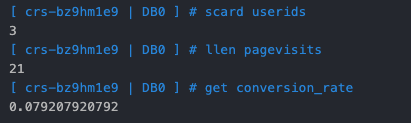
userids: storing UV s
pagevisits: store PV
conversion_rate: storage conversion rate, that is, the number of purchased goods / total page hits.
IV. summary
Collect data through self built Kafka cluster, conduct field accumulation, window aggregation and other operations in real time in flow computing Oceanus (Flink), store the processed data in cloud database Redis, and count the UV, PV and other indicators refreshed in real time. In the design of Kafka json format, this scheme simplifies the browsing records and product purchase records in the same topic for ease of understanding. The focus is to show the whole scheme by opening up the network between self built IDC and Tencent cloud products.
For the ultra large-scale UV weight removal, micro vision colleagues used Redis hyperloglog to realize UV statistics. Compared with the direct use of set type, it has the advantage of minimal memory space occupation. See the link for details: https://cloud.tencent.com/developer/article/1889162 .
Stream computing Oceanus Limited second kill exclusive activity is popular ↓↓


Focus on Tencent public data, official account, technical exchange, latest activities, service exclusive Get~