1, Selenium
(1) Introduction to Selenium
Selenium is a Web automated testing tool. It was originally developed for website automated testing. Its type is like the key wizard we use to play games. It can operate automatically according to the specified commands. The difference is that selenium can run directly on the browser. It supports all mainstream browsers (including PhantomJS, which has no interface).
Selenium can, according to our instructions, let the browser automatically load the page, obtain the required data, even screen shots of the page, or judge whether some actions on the website occur.
Selenium does not have a browser and does not support browser functions. It needs to be combined with a third-party browser to use. But sometimes we need to make it run embedded in code, so we can use a tool called phantom JS instead of a real browser.
2, Automatically fill in the query keywords of Baidu web pages and complete the automatic search
1. Check the id of the search box and the id of the search button in Baidu source code
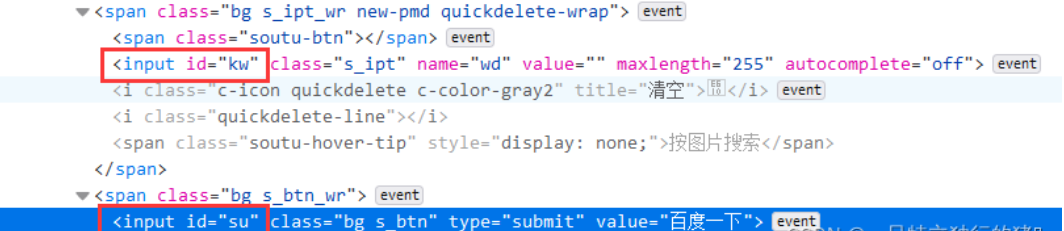
2. Get Baidu website
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
driver.get("https://www.baidu.com/")
If running, Baidu's start page will be opened at this time
 3. Fill in the search box
3. Fill in the search box
p_input = driver.find_element_by_id('kw')
print(p_input)
print(p_input.location)
print(p_input.size)
print(p_input.send_keys('Be My Personal Best '))
print(p_input.text)
4. Simulate Click
Use another input, that is, the click event of the button; Or the form submission event
p_btn = driver.find_element_by_id('su')
p_btn.click()
3, Crawl data from a dynamic web page
(1) Website links
http://quotes.toscrape.com/js/
(2) Analyze web pages
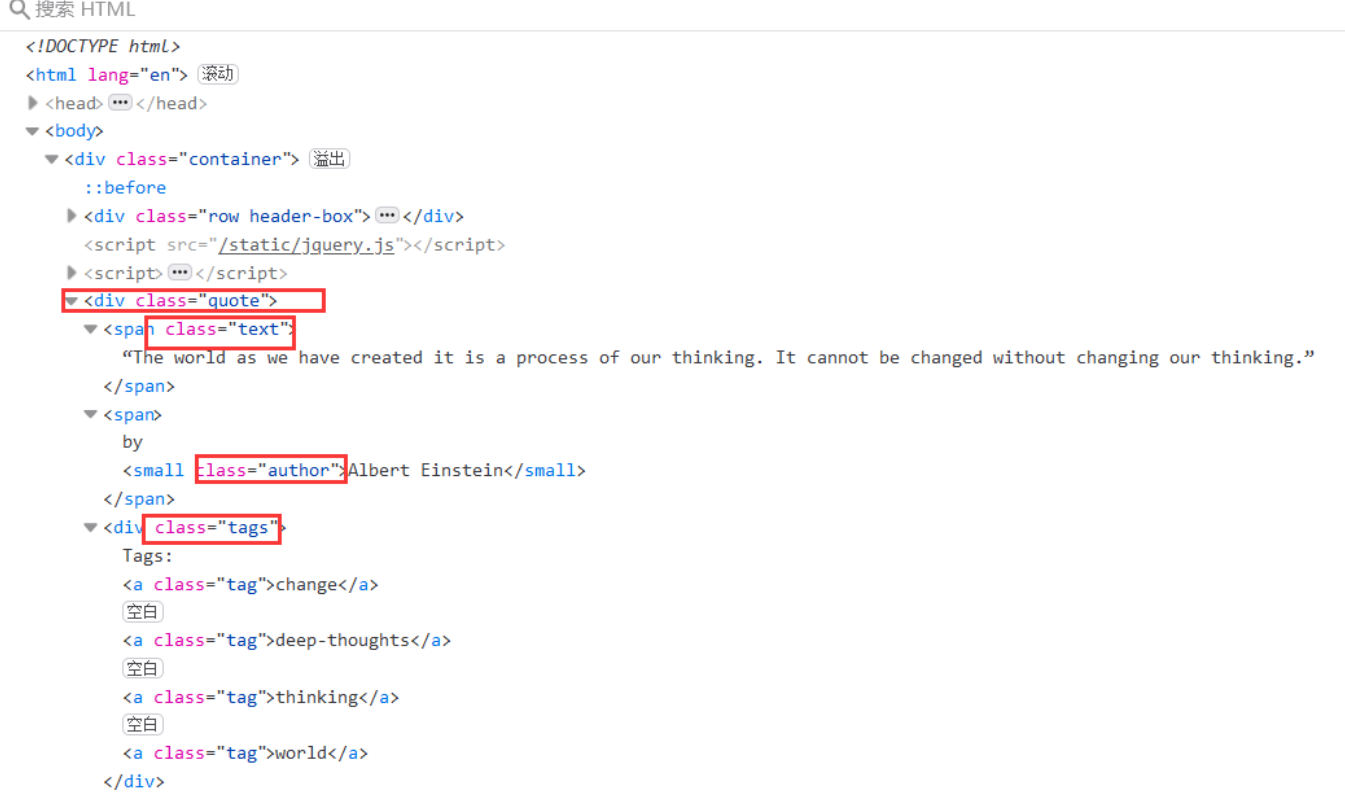
1. Crawl web page elements
contain quote The label of the class is the label you want
text Such famous sayings, author For the author,tags As label
 2. Button properties
2. Button properties
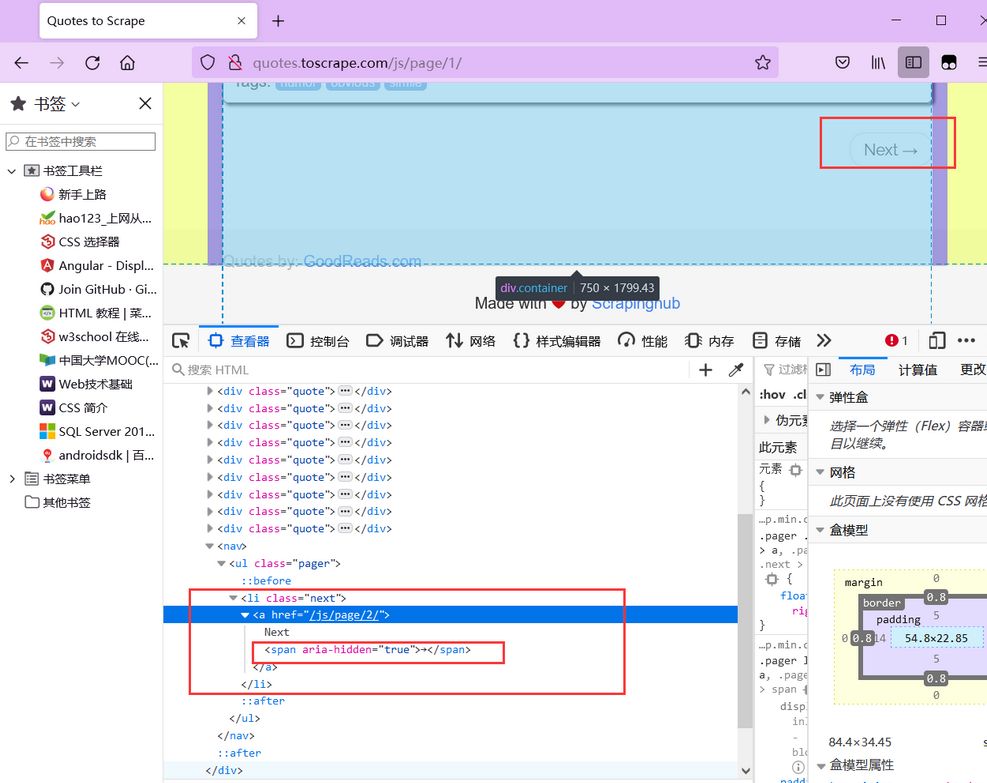
After crawling a page, you need to turn the page, that is, click the turn page button.
It can be found that the Next button has only href attribute and cannot be located. If the first page only has the Next page button, and the subsequent pages have the previous page and Next page buttons, it cannot be located through xpath, and the attribute aria hidden of its child element span (i.e. arrow) in the first page is unique. The attribute aria hidden exists in the subsequent pages, but the arrow of Next is always the last.
Therefore, you can find the last span tab with aria hidden attribute and click to jump to the next page:
 (3) Number of web pages
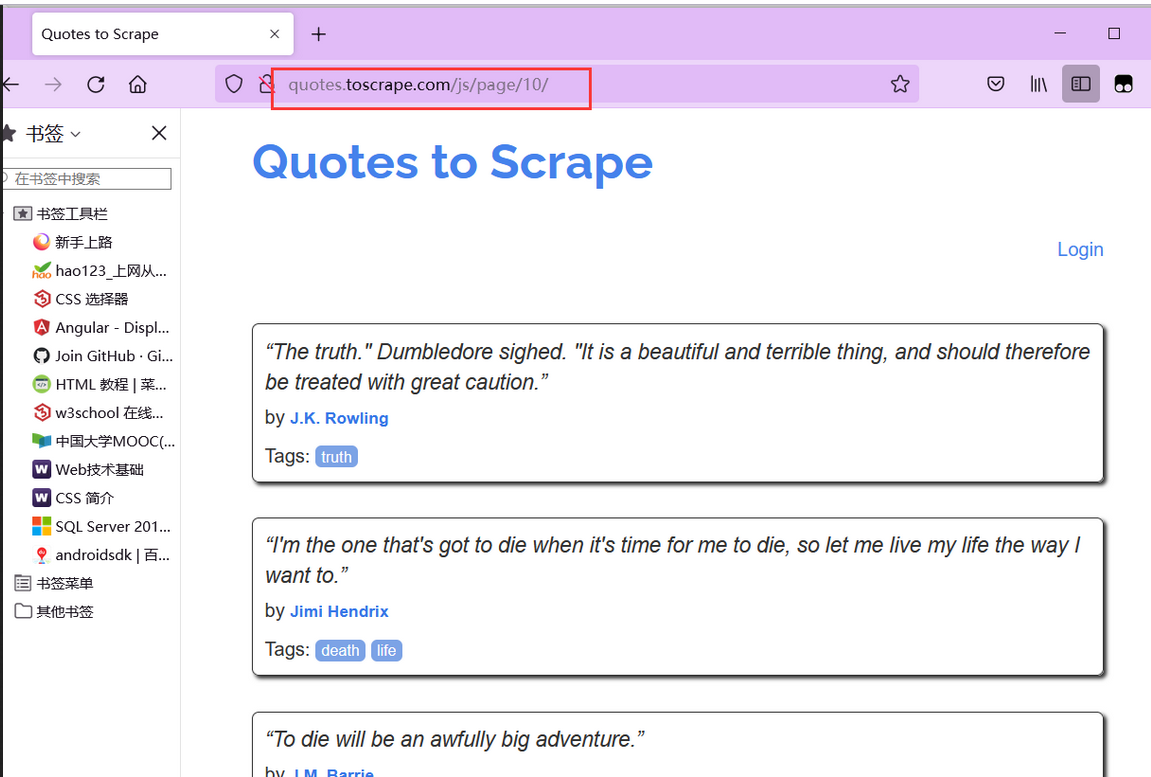
(3) Number of web pages
Click Nest and you can find that the website has 10 pages
(3) Code implementation
1. Code
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# Famous quote website
driver.get("http://quotes.toscrape.com/js/")
# All data
subjects = []
# Single data
subject=[]
#Define csv header
quote_head=['well-known saying','author','label']
#The path and name of the csv file
quote_path='Famous quotes.csv'
#List of stored contents
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
n = 10
for i in range(0, n):
driver.find_elements_by_class_name("quote")
res_list=driver.find_elements_by_class_name("quote")
# Isolate what you need
for tmp in res_list:
saying = tmp.find_element_by_class_name("text").text
author =tmp.find_element_by_class_name("author").text
tags =tmp.find_element_by_class_name("tags").text
subject=[]
subject.append(saying)
subject.append(author)
subject.append(tags)
print(subject)
subjects.append(subject)
subject=[]
write_csv(quote_head,subjects,quote_path)
print('Successfully crawled the second' + str(i + 1) + 'page')
if i == n-1:
break
driver.find_elements_by_css_selector('[aria-hidden]')[-1].click()
time.sleep(2)
driver.close()
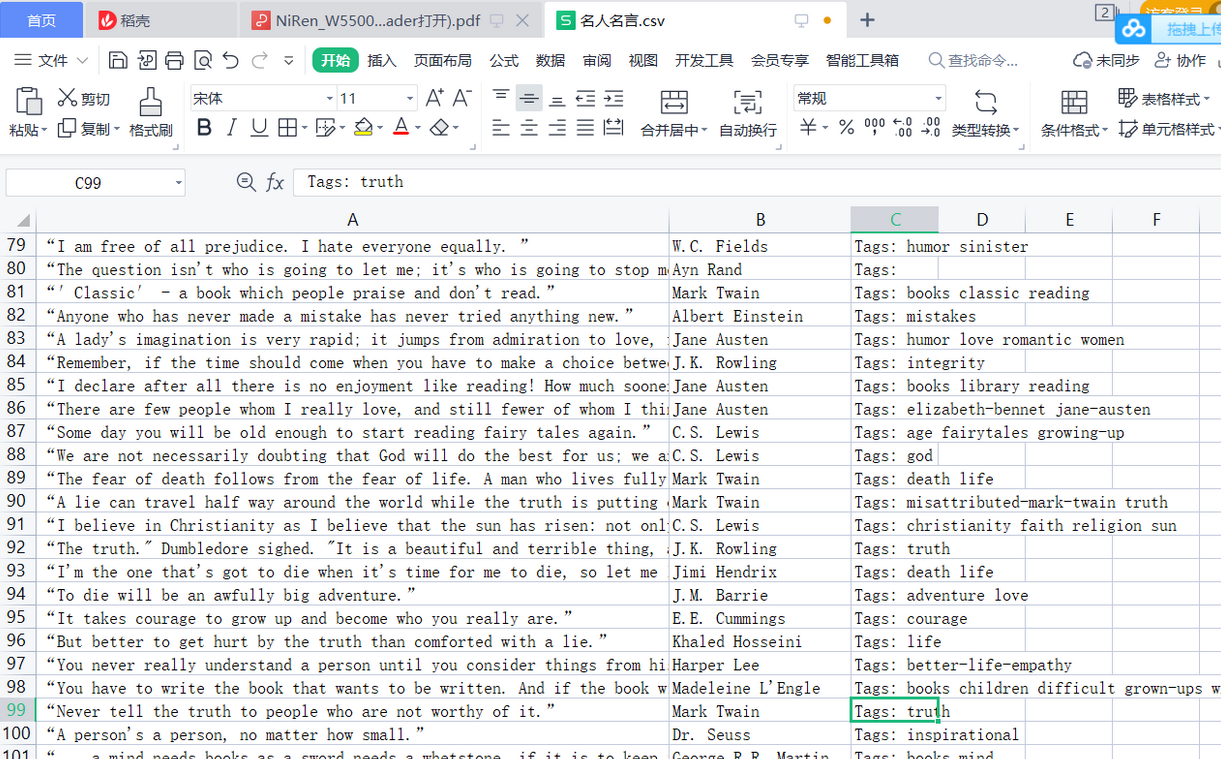
2. Saved crawling results
 There are 100 pieces of information in the table
There are 100 pieces of information in the table
4, Crawl the interested book information on jd.com
(1) Crawl website
JD.COM: https://www.jd.com/
(2) Web page analysis
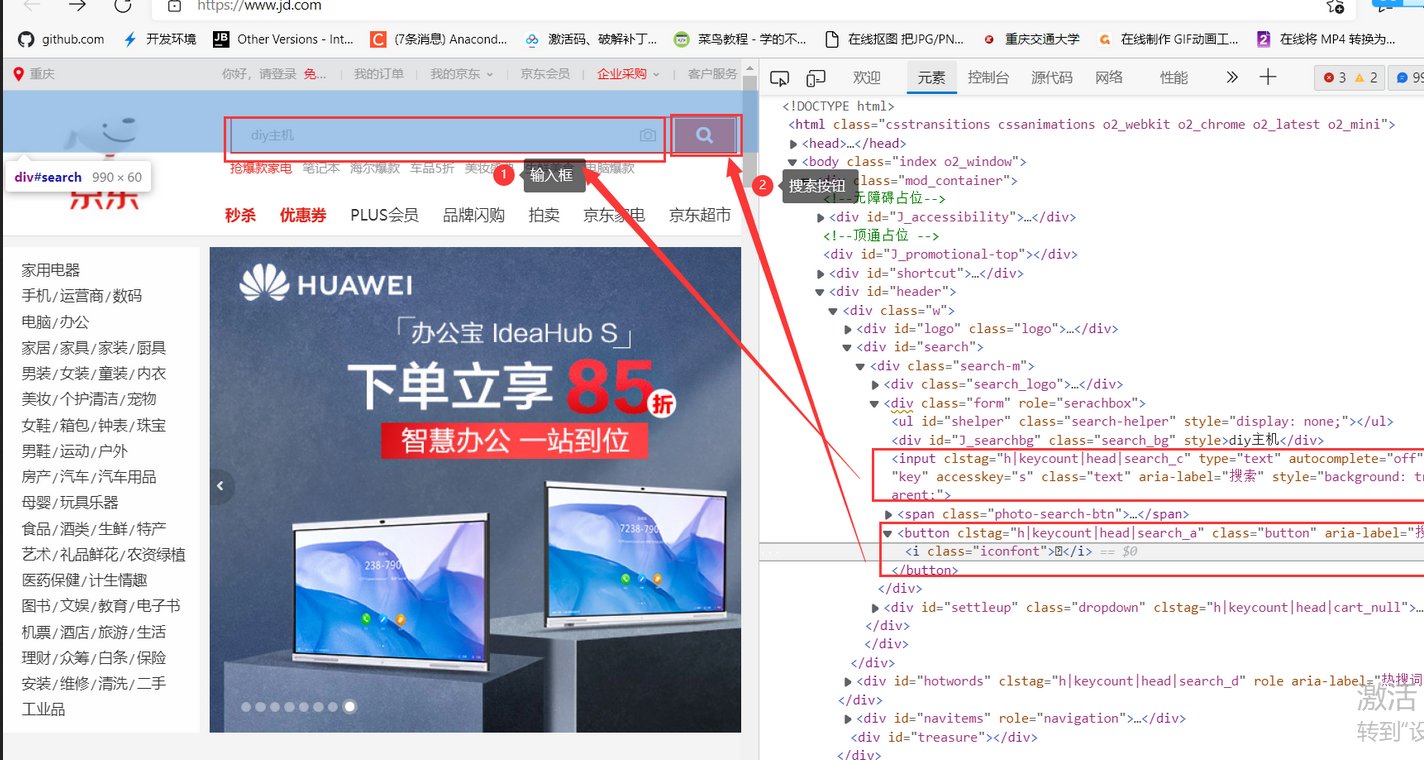
1. View the home page of the website, input box and search button
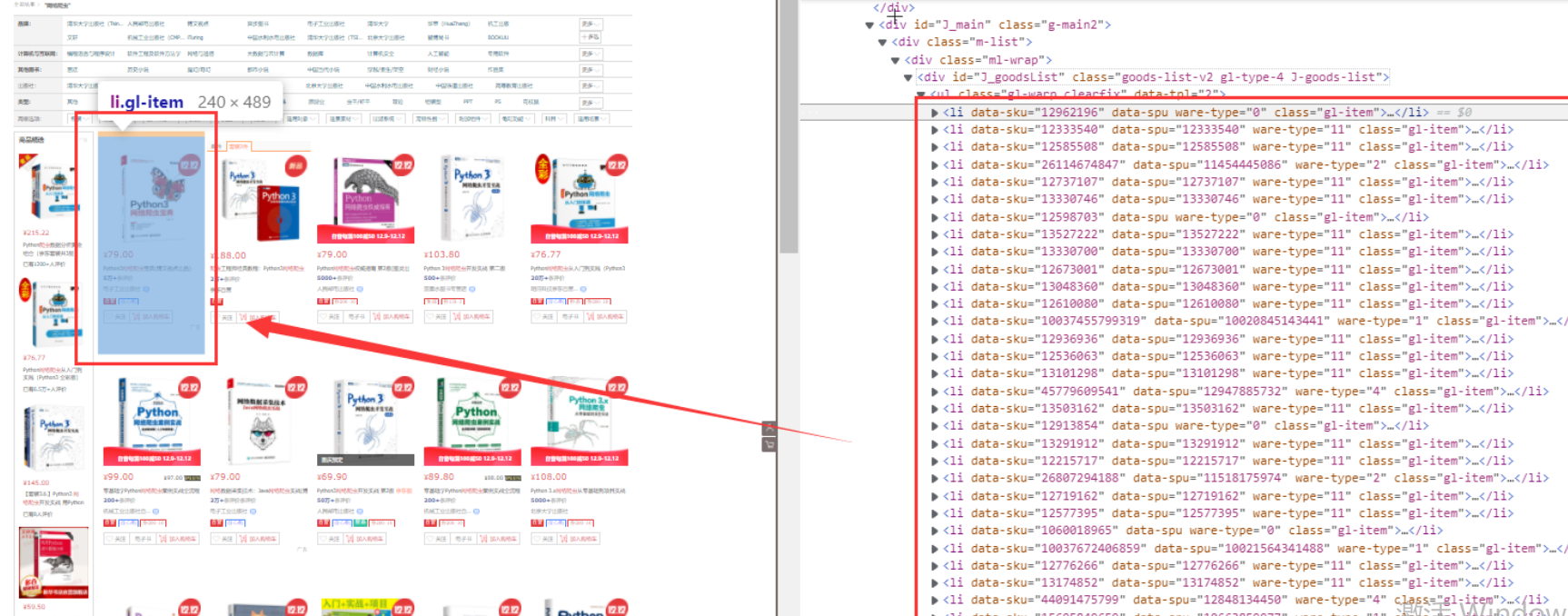
 2. Book display list, in J_goodsList
2. Book display list, in J_goodsList
 3. One to one correspondence of labels
3. One to one correspondence of labels
Each book detail has a li tag
There are many li tags
 4. Specific contents in Li
4. Specific contents in Li
 (1) Price
(1) Price
 (2) Title
(2) Title
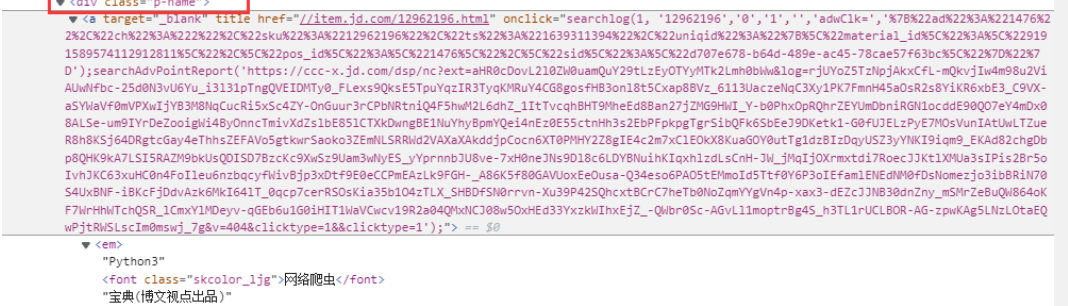
(3) Publishing House
 5. Next page
5. Next page

(3) Code implementation
1. Code
import time
import csv
from bs4 import BeautifulSoup as bs
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
from lxml import etree
driver = webdriver.Firefox(executable_path=r'F:\browserdriver\geckodriver-v0.30.0-win64\geckodriver.exe')
# Jingdong website
driver.get("https://www.jd.com/")
# Enter the keyword you want to find
p_input = driver.find_element_by_id('key')
p_input.send_keys('Internet worm') # Find the input box and enter
time.sleep(1)
# Click the search element button
button=driver.find_element_by_class_name("button").click()
time.sleep(1)
all_book_info = []
num=200
head=['title', 'Price', 'author', 'press']
#The path and name of the csv file
path='Internet worm.csv'
def write_csv(head,all_book_info,path):
with open(path, 'w', newline='',encoding='utf-8') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(head)
fileWriter.writerows(all_book_info)
# Crawl a page
def get_onePage_info(web,num):
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(2)
page_text =driver.page_source
# with open('3-.html', 'w', encoding='utf-8')as fp:
# fp.write(page_text)
# Analyze
tree = etree.HTML(page_text)
li_list = tree.xpath('//li[contains(@class,"gl-item")]')
for li in li_list:
num=num-1
book_infos = []
book_name = ''.join(li.xpath('.//div[@class="p-name"]/a/em/text()) # book title
book_infos.append(book_name)
price = '¥' + li.xpath('.//Div [@ class = "p-price"] / strong / I / text() '[0] # price
book_infos.append(price)
author_span = li.xpath('.//span[@class="p-bi-name"]/a/text()')
if len(author_span) > 0: # author
author = author_span[0]
else:
author = 'nothing'
book_infos.append(author)
store_span = li.xpath('.//span[@class="p-bi-store"]/a[1]/text()) # Publishing House
if len(store_span) > 0:
store = store_span[0]
else:
store = 'nothing'
book_infos.append(store)
all_book_info.append(book_infos)
if num==0:
break
return num
while num!=0:
num=get_onePage_info(driver,num)
driver.find_element_by_class_name('pn-next').click() # Click next
time.sleep(2)
write_csv(head,all_book_info,path)
driver.close()
2. Crawling results
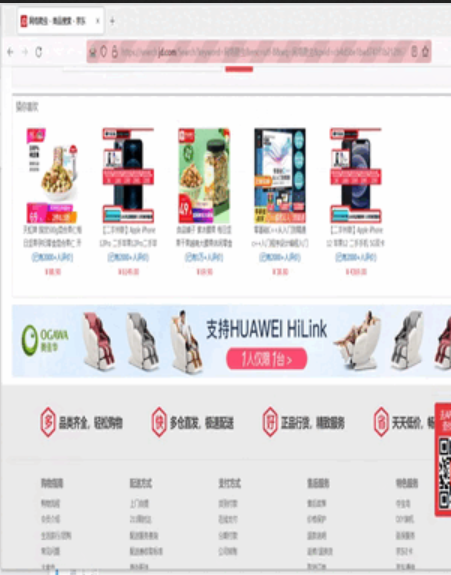
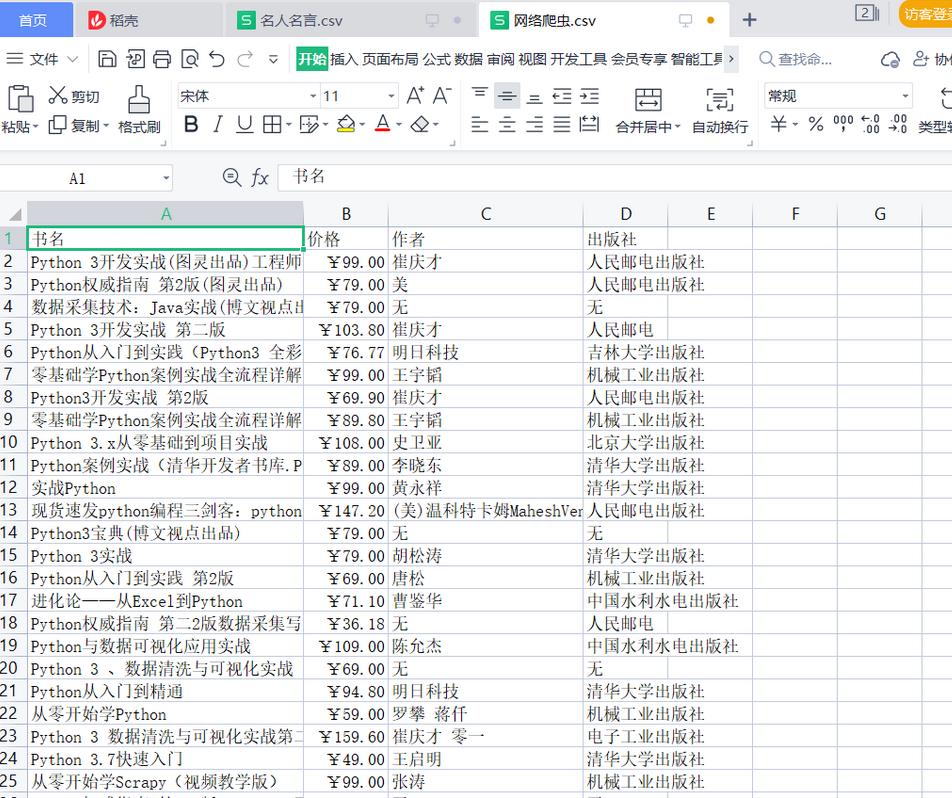
4, Summary
This experiment is based on the content of crawling web pages in Python language to better understand the principle and process of Selenium crawling web pages.
5, References
https://zhuanlan.zhihu.com/p/331712873
https://blog.csdn.net/weixin_43563705/article/details/107792278