Input and output
2.1 input / output flow
The source and destination of a byte sequence can be a file, and usually a file, but it can also be a network connection or even a memory block.
2.1.1 read and write bytes
System.in (which is a predefined object of a subclass of InputStream) reads information from standard input, that is, from the console or a redirected file.
Starting with Java 9, you can read all bytes in the stream:
byte[] bytes = in.readAllBytes();
The transferTo method can transfer all bytes from an input stream to an output stream:
in.transferTo(out);
Both the read and write methods will block during execution until the bytes are actually read in or written out. This means that if the flow cannot be accessed immediately (usually because the network connection is busy), the current thread will be blocked. This allows other threads to perform useful work while the two methods wait for the specified flow to become available.
The available method can check the current number of bytes that can be read in, which means that the following code cannot be blocked:
int bytesAvailable = in.available();
if (bytesAvailable > 0) {
var data = new byte[bytesAvailable];
in.read(data);
}
When the input / output stream is read and written, it should be closed by calling the close method, which will release very limited operating system resources.
Closing an output stream also flushes the buffer used for the output stream: all bytes temporarily placed in the buffer for transmission in the form of larger packets will be sent out when the output stream is closed. In particular, if the file is not closed, the last packet that writes out bytes may never be passed. Of course, you can also use the flush method to artificially flush these outputs.
2.1.3 combined input / output stream filter
For portable programs, the file separator of the platform on which the program runs should be used, which can be obtained through the constant string java.io.File.separator.
2.1.5 how to write text output
For text output, you can use PrintWriter. This class has methods for printing strings and numbers in text format.
var out = new PrintWriter("employee.txt", StandardCharsets.UTF_8);
In order to output to the print writer, you need to use the print, println, and printf methods.
The println method adds the appropriate line terminator for the target system to the line, that is, the string obtained by calling System.getProperty("line.separator").
If the writer is set to auto flush mode, all characters in the buffer are sent to their binding as long as println is called (the print writer is always buffered). By default, the automatic flushing mechanism is disabled. You can enable or disable the automatic flushing mechanism by using printwriter (writer, Boolean autoflush).
Since methods such as print do not throw exceptions, you can call the checkError method to check whether there are some errors in the output stream.
2.1.6 how to read text input
The simplest way to handle arbitrary text is to use the scanner class. Scanner objects can be built from any input stream
Alternatively, you can read a short text file into a string:
var content = Files.readString(path, charset);
However, if you want to read this file line by line, you can call:
List<String> lines = Files.readAllLines(path, charset);
If the file is too large, you can treat the line as a stream < string > Object:
try (Stream<String> lines = Files.lines(path, charset)) {
// ...
}
You can also use the scanner to read in tokens, that is, strings separated by delimiters. The default delimiter is a white space character. You can change the delimiter to any regular expression. For example:
Scanner in = ...;
in.useDelimiter("\\PL+");
Any non unicode letter will be accepted as a delimiter. After that, the scanner will only accept unicode letters.
The next symbol can be generated by calling the next method:
while (in.hasNext()) {
String word = in.next();
}
Alternatively, you can get a stream containing all symbols:
Stream<String> words = in.tokens();
In earlier java versions, the only way to process text input was through the BufferedReader class:
InputStream inputStream = ...;
try (var in = new BufferedReader(new InputStreamReader(inputStream, charset))) {
String line;
while ((line = in.readLine()) != null) {
// do something with line
}
}
Now, the BufferedReader class has a lines method to generate a stream < string > object. However, unlike Scanner, BufferedReader does not have any method for reading in numbers.
2.1.7 storing objects in text format
public class TextFileTest {
public static void main(String[] args) throws IOException {
var staff = new Employee[3];
staff[0] = new Employee("Carl Cracker", 75000, 1987, 12, 15);
staff[1] = new Employee("Harry Hacker", 50000, 1989, 10, 1);
staff[2] = new Employee("Tony Tester", 40000, 1990, 3, 15);
// save all employee records to the file employee.dat
try (var out = new PrintWriter("/Users/kirito/program/java/study/java_study/core_java_volume_two_11/src/main/resources/employee.dat", StandardCharsets.UTF_8)) {
writeData(staff, out);
}
// retrieve all records into a new array
try (var in = new Scanner(new FileInputStream("/Users/kirito/program/java/study/java_study/core_java_volume_two_11/src/main/resources/employee.dat"), StandardCharsets.UTF_8)) {
Employee[] newStaff = readData(in);
// print the newly read employee records
for (Employee e : newStaff) {
System.out.println(e);
}
}
}
/**
* Writes all employees in an array to a print writer
* @param employees an array of employees
* @param out a print writer
*/
private static void writeData(Employee[] employees, PrintWriter out) {
// write number of employees
out.println(employees.length);
for (Employee e : employees) {
writeEmployee(out, e);
}
}
/**
* Reads an array of employees from a scanner
* @param in the scanner
* @return the array of employees
*/
private static Employee[] readData(Scanner in) {
// retrieve the array size
int n = in.nextInt();
in.nextLine(); // consume newline
var employees = new Employee[n];
for (int i = 0; i < n; i++) {
employees[i] = readEmployee(in);
}
return employees;
}
/**
* Writes employee data to a print writer
* @param out the print writer
* @param e the employee
*/
public static void writeEmployee(PrintWriter out, Employee e) {
out.println(e.getName() + "|" + e.getSalary() + "|" + e.getHireDay());
}
/**
* Reads employee data from a buffered reader
* @param in the scanner
* @return the employee
*/
public static Employee readEmployee(Scanner in) {
String line = in.nextLine();
String[] tokens = line.split("\\|");
String name = tokens[0];
double salary = Double.parseDouble(tokens[1]);
LocalDate birthday = LocalDate.parse(tokens[2]);
int year = birthday.getYear();
int month = birthday.getMonthValue();
int day = birthday.getDayOfMonth();
return new Employee(name, salary, year, month, day);
}
}
2.2 reading and writing binary data
2.2.1 datainput and DataOutput interfaces
The DataOutput interface defines methods for writing arrays, characters, boolean values and strings in binary format (the method name for reading back data is similar).
For example, writeInt always writes an integer as a 4-byte binary quantity value, no matter how many bits it has; writeDouble always writes out a double value as an 8-byte binary quantity value. The result is not human readable, but the space used is the same for each value of a given type, and it is faster to read it back than parsing text.
Because no other method will use this revision of utf-8, the writeUTF method should be used only when writing a string for the java virtual machine, for example, when you need to write a program to generate bytecode. For other occasions, you should use the writeChars method.
The DataInputStream class implements the DataInput interface. In order to read binary data from a file, you can combine the DataInputStream with a byte source, such as FileInputStream:
var in = new DataInputStream(new FileInputStream("employee.dat"));
2.2.2 random access files
The RandomAccessFile class can find or write data anywhere in a file. Disk files are accessed randomly, but the input / output stream communicating with the network socket is not. You can open a random access file for read-in only or read-write at the same time. You can specify this option by using the string "r" (for read-in access) or "rw" (for read-out access) as the second parameter of the constructor.
var in = new RandomAccessFile("employee.dat", "r");
var inOut = new RandomAccessFile("employee.dat", "rw");
When an existing file is opened as a RandomAccessFile, the file will not be deleted.
The random access file has a file pointer indicating the position of the next byte to be read in or written out. The seek(long) method can be used to set the file pointer to any byte position in the file.
The getFilePointer method returns the current position of the file pointer.
RandomAccessFile class implements both DataInput and DataOutput interfaces. In order to read and write random access files, methods such as readInt/writeInt and readChar/writeChar can be used.
public class RandomAccessTest {
public static void main(String[] args) throws IOException {
var staff = new Employee[3];
staff[0] = new Employee("Carl Cracker", 75000, 1987, 12, 15);
staff[1] = new Employee("Harry Hacker", 50000, 1989, 10, 1);
staff[2] = new Employee("Tony Tester", 40000, 1990, 3, 15);
try (var out = new DataOutputStream(new FileOutputStream("/Users/kirito/program/java/study/java_study/core_java_volume_two_11/src/main/resources/employee.dat"))) {
// save all employee records to the file employee.dat
for (Employee e : staff) {
writeData(out, e);
}
}
try (var in = new RandomAccessFile("/Users/kirito/program/java/study/java_study/core_java_volume_two_11/src/main/resources/employee.dat", "r")) {
// retrieve all records into a new array
// compute the array size
// To determine the total number of bytes in the file, you can use the length method. The total number of records is equal to the total number of bytes divided by the size of each record
int n = (int) (in.length() / Employee.RECORD_SIZE);
var newStaff = new Employee[n];
// read employees in reverse order
for (int i = n - 1; i >= 0; i--) {
newStaff[i] = new Employee();
in.seek(i * Employee.RECORD_SIZE);
newStaff[i] = readData(in);
}
// print the newly read employee records
for (Employee e : newStaff) {
System.out.println(e);
}
}
}
/**
* Writes employee data to a data output
* @param out the data output
* @param e the employee
* @throws IOException
*/
public static void writeData(DataOutput out, Employee e) throws IOException {
DataIO.writeFixedString(e.getName(), Employee.NAME_SIZE, out);
out.writeDouble(e.getSalary());
LocalDate hireDay = e.getHireDay();
out.writeInt(hireDay.getYear());
out.writeInt(hireDay.getMonthValue());
out.writeInt(hireDay.getDayOfMonth());
}
/**
* Reads employee data from a data input
* @param in the data input
* @return the employee
*/
public static Employee readData(DataInput in) throws IOException {
String name = DataIO.readFixedString(Employee.NAME_SIZE, in);
double salary = in.readDouble();
int y = in.readInt();
int m = in.readInt();
int d = in.readInt();
return new Employee(name, salary, y, m - 1, d);
}
}
/**
* The type Data io.
*/
class DataIO {
/**
* Read fixed string
* Read characters from the input stream until size symbols are read, or until a character value with a value of 0 is encountered,
* Then skip the remaining 0 values in the input field
* @param size the size
* @param in the in
* @return the string
* @throws IOException the io exception
*/
public static String readFixedString(int size, DataInput in)
throws IOException {
StringBuilder b = new StringBuilder(size);
int i = 0;
boolean more = true;
while (more && i < size) {
char ch = in.readChar();
i++;
if (ch == 0) more = false;
else b.append(ch);
}
in.skipBytes(2 * (size - i));
return b.toString();
}
/**
* Write fixed string
* Writes out the specified number of symbols starting from the beginning of the string (if there are too few symbols, the method will complement the string with a value of 0)
* @param s the s
* @param size the size
* @param out the out
* @throws IOException the io exception
*/
public static void writeFixedString(String s, int size, DataOutput out)
throws IOException {
for (int i = 0; i < size; i++) {
char ch = 0;
if (i < s.length()) ch = s.charAt(i);
out.writeChar(ch);
}
}
}
// Each record has the same size so that any record can be easily read in
class Employee implements Serializable {
// Use 40 characters to represent the name string
public static final int NAME_SIZE = 40;
public static final int RECORD_SIZE = 2 * NAME_SIZE + 8 + 4 + 4 + 4;
// ...
}
2.2.3 zip document
ZIP documents (usually) store one or more files in a compressed format, and each ZIP document has a header containing information such as the name of each file and the compression method used.
In java, ZipInputStream can be used to read in ZIP documents. You may need to browse each individual item in the document, and the getNextEntry method can return an object of ZipEntry type describing these items. The method reads data from the stream to the end. In fact, the end of this is the end of the entry that is being read, and then calls closeEntry to read the next item. Do not close the stream until the last item is read in:
var zin = new ZipInputStream(new FileInputStream(zipname));
ZipEntry entry;
while ((entry = zin.getNextEntry()) != null) {
// read the contents of zin
zin.closeEntry();
}
zin.close();
To write out to the ZIP file, you can use ZipOutputStream. For each item you want to put into the ZIP file, you should create a ZipEntry object and pass the file name to the constructor of ZipEntry, which will set other parameters such as file date and decompression method. You can override these settings if necessary. Then, you need to call the putNextEntry method to write out the new file and send the file data to the ZIP output stream. When finished, closeEntry needs to be called. Then, you need to repeat this process for all the files you want to store:
var fout = new FileOutputStream("test.zip");
var zout = new ZipOutputStream(fout);
for all files {
var ze = new ZipEntry(filename);
zout.putNextEntry(ze);
// send data to zout
zout.closeEntry();
}
zout.close();
A JAR file is just a ZIP file with a special item called a manifest. You can use the JarInputStream and JarOutputStream classes to read and write list items.
2.3 object input / output stream and serialization
When you need to store the same type of data, using a fixed length record format is a good choice. However, rarely all objects created in object-oriented programs have the same type. For example, there might be an array of records that is nominally an Employee, but actually contains subclass instances such as Manager.
The Java language supports a very general mechanism called object serialization, which can write any object out to the output stream and then read it back.
2.3.1 saving and loading serialized objects
To save the object data, first open an ObjectOutputStream object:
var out = new ObjectOutputStream(new FileOutputStream("employee.dat"));
Now, in order to save the object, you can directly use the writeObject method:
var harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
var boss = new Manager("Carl Cracker", 80000, 1987, 12, 15);
out.writeObject(harry);
out.writeObject(boss);
In order to read these objects back, you first need to obtain an ObjectInputStream object:
var in = new ObjectInputStream(new FileOutputStream("employee.dat"));
Then, use the readObject method to obtain these objects in the order they were written out:
var e1 = (Employee) in.readObject(); var e2 = (Employee) in.readObject();
However, all classes that you want to store in or recover from the object output stream should be modified. These classes must implement the Serializable interface.
Each object is saved with a serial number. The specific algorithm is as follows:
- A sequence number is associated with each object reference encountered.
- For each object, when it is encountered for the first time, its object data is saved to the output stream.
- If an object has been saved before, only write "the same as the previously saved object with serial number x".
When the object is read back, the whole process is reversed:
- For the object in the object input stream, when it first encounters its serial number, build it, initialize it with the data in the stream, and then record the association between the serial number and the new object.
- When the tag "same as the previously saved object with serial number x" is encountered, the object reference associated with this serial number is obtained.
public class ObjectStreamTest {
public static void main(String[] args) throws IOException, ClassNotFoundException {
var harry = new Employee("Harry Hacker", 50000, 1989, 10, 1);
var carl = new Manager("Carl Cracker", 80000, 1987, 12, 15);
carl.setSecretary(harry);
var tony = new Manager("Tony Tester", 40000, 1990, 3, 15);
tony.setSecretary(harry);
var staff = new Employee[3];
staff[0] = carl;
staff[1] = harry;
staff[2] = tony;
// save all employee records to the file employee.dat
try (var out = new ObjectOutputStream(new FileOutputStream("/Users/kirito/program/java/study/java_study/core_java_volume_two_11/src/main/resources/employee.dat"))) {
out.writeObject(staff);
}
try (var in = new ObjectInputStream(new FileInputStream("/Users/kirito/program/java/study/java_study/core_java_volume_two_11/src/main/resources/employee.dat"))) {
// retrieve all records into a new array
var newStaff = (Employee[]) in.readObject();
// raise secretary's salary
newStaff[1].raiseSalary(10);
// print the newly read employee records
for (Employee e : newStaff) {
System.out.println(e);
}
}
}
}
2.4 operation documents
The Path and Files classes encapsulate all the functionality required to process the file system on the user's machine.
2.4.1Path
Path represents a sequence of directory names, followed by a file name. The first part in the path can be the root part, such as / or C: \, and the root part allowed to access depends on the file system. The path starting with the root part is an absolute path; Otherwise, it is a relative path.
Path absolute = Paths.get("/home", "harry");
Path relative = Paths.get("myprog", "conf", "user.properties");
The static Paths.get method accepts one or more strings and connects them with the Path separator of the default file system. Then it parses the connected results and throws an InvalidPathException if it does not represent a legal Path in a given file system. The result of this connection is a Path object.
The get method can get a single string containing multiple parts. For example, read the path from the configuration file:
// May be a string such as /opt/myprog or c:\Program Files\myprog
String baseDir = props.getProperty("base.dir");
// OK that baseDir has separators
Path basePath = Paths.get(baseDir);
The path does not have to correspond to an actual file, it is just an abstract sequence of names.
Combining or parsing paths is a common operation. Calling the resolve(Path/String other) method will return a path according to the following rules:
- If other is an absolute path, return other.
- Otherwise, the path obtained by connecting this and other is returned.
There is also a convenient method resolveSibling(Path/String other), which generates its sibling path by parsing the parent path of the specified path. That is, if other is an absolute path, return other; Otherwise, the path obtained by connecting the parent path of this and other is returned.
// If the workPath is / opt/myapp/work, / opt/myapp/temp will be returned
Path tempPath = workPath.resolveSibling("temp");
The opposite of resolve is relative(Path other). That is, return the relative path parsed with this relative to other. For example, the relative operation of / home/fred/input.txt with / home/harry as the target will produce.. / fred/input.txt, where.. is assumed to represent the parent directory in the file system.
The normalize method removes all redundant. And.. parts (or all parts considered redundant by the file system). It should be noted that if.. is preceded by a non.. name, both are considered redundant. For example, normalizing / home / Harry /... / Fred /. / input.txt will produce / home/fred/input.txt.
The toAbsolutePath method will generate an absolute path for the given path, starting from the root piece, for example, / home/fred/input.txt or c:\Users\fred\input.txt.
The Path class has many useful methods to break a Path:
Path p = Paths.get("/home", "fred", "myprog.properties");
Path parent = p.getParent(); // the path /home/fred
Path file = p.getFileName(); // the path myprog.properties
Path root = p.getRoot(); // the path /
You can also build a Scanner object from a Path object:
var in = new Scanner(Paths.get("/home/fred/input.txt"));
Occasionally, you may need to interact with legacy system API s that use the File class instead of the Path interface. The Path interface has a toFile method, and the File class has a toPath method.
2.4.2 reading and writing documents
The Files class can make ordinary file operations convenient. For example, read all the contents of a file:
byte[] bytes = Files.readAllBytes(path);
You can read from a text file:
var content = Files.readString(path, charset);
However, if you want to read the file as a line sequence, you can call:
List<String> lines = Files.readAllLines(path, charset);
On the contrary, if you want to write a string into a file, you can call:
Files.writeString(path, content, charset);
To append content to the specified file, you can call:
Files.write(path, content.getBytes(charset), StandardOpenOption.APPEND);
You can also write out a set of rows to a file:
Files.write(path, lines, charset);
These simple methods are suitable for processing medium length text files. If the file to be processed is large or binary, the well-known input / output stream or reader / writer should be used:
InputStream in = Files.newInputStream(path); OutputStream out = Files.newOutputStream(path); Reader in = Files.newBufferedReader(path, charset); Writer out = Files.newBufferedWriter(path, charset);
2.4.3 creating files and directories
To create a new directory, you can call:
Files.createDirectory(path);
All parts of the path except the last part must already exist. To create an intermediate directory in the path, you should use:
Files.createDirectories(path);
You can create an empty file using the following statement:
Files.createFile(path);
If the file already exists, the call throws an exception. Check whether the file exists and create the file is atomic. If the file does not exist, it will be created, and other programs cannot perform the file creation operation in the process.
Some convenient methods can be used to create temporary files or temporary directories in a given location or system specified location:
Path newPath = Files.createTempFile(dir, prefix, suffix); Path newPath = Files.createTempFile(prefix, suffix); Path newPath = Files.createTempDirectory(dir, prefix); Path newPath = Files.createTempDirectory(prefix);
Where dir is a Path object, prefix and suffix are nullable strings. For example, calling Files.createTempFile(null, ".txt") may return a Path like / TMP / 1234441234234.txt.
When you create a file or directory, you can specify properties, such as the owner and permissions of the file. However, these depend on the system. Refer to the API documentation for details.
2.4.4 copying, moving and deleting files
Copying files from one location to another can be called directly:
Files.copy(fromPath, toPath);
To move a file (i.e. copy and delete the original file), you can call:
Files.move(fromPath, toPath);
If the destination path already exists, the copy or move will fail. If you want to overwrite the existing target path, you can use replace_ The existing option. If you want to copy all file attributes, you can use COPY_ATTRIBUTES option. You can also select both options:
Files.copy(fromPath, toPath, StandardCopyOption.REPLACE_EXISTNG, StandardCopyOption.COPY_ATTRIBUTES);
The move operation can be defined as atomic, which ensures that either the move operation completes successfully or the source file remains in its original location. You can use ATOMIC_MOVE option to achieve:
Files.move(fromPath, toPath, StandardCopyOption.ATOMIC_MOVE);
You can also copy an input stream to Path, which indicates that you want to store the input stream on your hard disk. Similarly, you can copy a Path to the output stream:
Files.copy(inputStream, toPath); Files.copy(fromPath, outputStream);
For other calls to copy, you can provide corresponding replication options as needed.
Finally, to delete a file, you can call:
Files.delete(path);
If the file to be deleted does not exist, this method will throw an exception. Therefore, the following method can be used instead:
boolean deleted = Files.deleteIfExists(path);
This method can also be used to remove empty directories.
Standard options for file operations:
| option | describe |
|---|---|
| StandardOpenOption | Use with newBufferedWriter, newInputStream, newOutputStream, write |
| READ | Open for reading |
| WRITE | Open for writing |
| APPEND | If opened for writing, append at the end of the file |
| TRUNCATE_EXISTING | If it is opened for writing, the existing content is removed |
| CREATE_NEW | Create a new file and fail if the file already exists |
| CREATE | Automatically create a new file if it does not exist |
| DELETE_ON_CLOSE | When a file is closed, delete it as much as possible |
| SPARSE | Give the file system a hint that the file is sparse |
| DSYNC or SYNC | It is required that each update of file data or data and metadata must be written to the storage device synchronously |
| StandardCopyOption | Use with copy and move |
| ATOMIC_MOVE | Move files atomically |
| COPY_ATTRIBUTES | Copy file properties |
| REPLACE_EXISTING | If the target already exists, replace it |
| LinkOption | Use with all the above methods, as well as exists, isDirectory, isRegularFile, and so on |
| NOFOLLOW_LINKS | Do not track symbolic links |
| FileVisitOption | Use with find, walk, walkFileTree |
| FOLLOW_LINKS | Track symbolic links |
2.4.5 obtaining document information
The following static methods will return a boolean value indicating the result of checking a property of the path:
- exists
- isHidden
- isReadable,isWritable,isExecutable
- isRegularFile,isDirectory,isSymbolicLink
The size method will return the number of bytes of the file:
long fileSize = Files.size(path);
The getOwner method returns the owner of the file as an instance of java.nio.file.attribute.UserPrincipal.
All file systems will report a basic attribute set, which is encapsulated in the BasicFileAttributes interface. These attributes partially overlap with the above information. Basic file attributes include:
- The time when the file was created, last accessed, and last modified. These times are expressed as java.nio.file.attribute.FileTime.
- Is the file a regular file, a directory, a symbolic link, or none of these.
- File size.
- File primary key, which is a kind of object. The specific class is related to the file system. It may or may not be the unique identifier of the file.
To get these properties, you can call:
BasicFileAttributes attributes = Files.readAttributes(path, BasicFileAttributes.class);
If you know that the user's file system is POSIX compatible, you can obtain an instance of PosixFileAttributes:
PosixFileAttributes attributes = Files.readAttributes(path, PosixFileAttributes.class);
Then find the group owner, as well as the owner, group, and access rights of the file.
2.4.6 accessing items in the directory
The static Files.list method will return a stream < Path > object that can read each item in the directory. Directories are read lazily, which makes it more efficient to deal with directories with a large number of items.
Since reading the directory involves system resources that need to be closed, you should use the try block:
try (Stream<Path> entries = Files.list(pathToDirectory)) {
// ...
}
The list method does not enter a subdirectory. In order to process all subdirectories in the directory, you need to use the Files.walk method.
try (Stream<Path> entries = Files.walk(pathToRoot)) {
// Contains all descendants, visited in depth-first order
}
Whenever the traversed item is a directory, it will be entered before continuing to access its sibling item.
You can limit the depth of the tree you want to access by calling files. Walk (path to root, depth). Both walk methods have a variable length parameter of FileVisitOption... But can only provide one option - FOLLOW_LINKS, which tracks symbolic links.
If you want to filter the path returned by walk, and the filtering criteria involve file attributes related to directory storage, such as size, creation time and type (file, directory, symbolic link), you should use the find method instead of the walk method. This method can be called with a predicate function that accepts a path and a BasicFileAttributes object. The only advantage of this is high efficiency. Because the path is always read in, these properties are easy to obtain.
Copy one directory to another using the Files.walk method:
Files.walk(source).forEach(p -> {
try {
Path q = target.resolve(source.relativize(p));
if (Files.isDirectory(p)) {
Files.createDirectory(q);
} else {
Files.copy(p, q);
}
} catch (IOException ex) {
throw new UncheckedIOException(ex);
}
});
Unfortunately, you can't easily delete the directory tree using the Files.walk method, because you must delete a subdirectory before deleting the parent directory.
2.4.7 using directory streams
Sometimes, you need more fine-grained control over the traversal process. In this case, you should use the Files.newDirectoryStream object, which will produce a DirectoryStream. Note that it is not a sub interface of java.util.stream.Stream, but an interface dedicated to directory traversal. It is a sub interface of Iterable, so you can use directory flow in the enhanced for loop:
try (DirectoryStream<Path> entries = Files.newDirectoryStream(dir)) {
for (Path entry : entries) {
// Process entries
}
}
The try statement block with resources is used to ensure that the directory flow can be closed correctly. There is no specific order to access items in the directory.
You can use glob mode to filter files:
try (DirectoryStream<Path> entries = Files.newDirectoryStream(dir, "*.java"))
All glob modes:
| pattern | describe | Example |
|---|---|---|
| * | Matches 0 or more characters in a path component | *. Java matches all java files in the current directory |
| ** | Matches 0 or more characters across directory boundaries | **. Java matches java files in all subdirectories |
| ? | Match one character | ????. Java matches all four character java files (excluding extensions) |
| [...] | To match a character set, you can use the hyphen [0-9] and negate [! 0-9] | Test[0-9A-F].java matches Testx.java, where x is a hexadecimal number |
| {...} | Matches one of multiple options separated by commas | *. {java,class} matches all java files and class files |
| \ | Escape the characters in any of the above modes and the \ character | *\**Match files with * in all file names |
If you use the glob syntax of windows, you must escape the backslash twice: once for glob syntax and once for java string. For example, Files.newDirectoryStream(dir, "C: \ \ \").
If you want to access the descendant members of a directory, you can call the walkFileTree method instead and pass it an object of FileVisitor type. This object will be notified as follows:
- When a file or directory is encountered: filevisitresult visitfile (t path, basicfileattributes, attributes).
- Before a directory is processed: FileVisitResult preVisitDirectory(T dir, IOException ex).
- After a directory is processed: FileVisitResult postVisitDirectory(T dir, IOException ex).
- An error occurred when trying to access a file or directory, such as no permission to open the directory: FileVisitResult visitFileFailed(path, IOException).
For each of the above cases, you can specify whether you want to perform the following operations:
- Continue to the next file: FileVisitResult.CONTINUE.
- Continue to access, but no longer access any items in this directory: FileVisitResult.SKIP_SUBTREE.
- Continue to access, but no longer access the sibling file of this file (the file in the same directory as this file): FileVisitResult.SKIP_SIBLINGS.
- Terminate access: FileVisitResult.TERMINATE.
When any method throws an exception, the access will be terminated, and the exception will be thrown from the walkFileTree method.
The convenience class SimpleFileVisitor implements the FileVisitor interface, but all its methods except the visitFileFailed method do not do any processing, but directly continue to access, and the visitFileFailed method will throw an exception caused by failure and terminate the access.
For example, print out all subdirectories under a given directory:
Files.walkFileTree(Paths.get("/"), new SimpleFileVisitor<Path>() {
public FileVisitResult preVisitDirectory(Path path, BasicFileAttributes attrs) throws IOException {
System.out.println(path);
return FileVisitResult.CONTINUE;
}
public FileVisitResult postVisitDirectory(Path dir, IOException exc) {
return FileVisitResult.CONTINUE;
}
public FileVisitResult visitFileFailed(Path path, IOException exc) throws IOException {
return FileVisitResult.SKIP_SUBTREE;
}
});
It is worth noting that the postVisitDirectory and visitFileFailed methods need to be overridden. Otherwise, access will fail immediately when encountering a directory that is not allowed to be opened or a file that is not allowed to be accessed.
It should also be noted that many attributes of the path are passed as parameters of the preVisitDirectory and visitFile methods. Visitors have to get these attributes through operating system calls because it needs to distinguish between files and directories. Therefore, there is no need to perform the system call again.
Other methods of the FileVisitor interface are useful if you need to perform certain operations when entering or leaving a directory. For example, when deleting a directory tree, you need to remove all files in the current directory before you can remove the directory. The following is the complete code for deleting the directory tree:
// Delete the directory tree starting at root
Files.walkFileTree(root, new SimpleFileVisitor<Path>() {
public FileVisitResult visitFile(Path file, BasicFileAttributes attrs) throws IOException {
Files.delete(file);
return FileVisitResult.CONTINUE;
}
public FileVisitResult postVisitDirectory(Path dir, IOException e) throws IOException {
if (e != null) {
throw e;
}
Files.delete(dir);
return FileVisitResult.CONTINUE;
}
});
2.4.8 zip file system
The Paths class looks for the path in the default file system, that is, the file on the user's local disk. There can also be other file systems, one of the most useful of which is the ZIP file system. If zipname is the name of a ZIP file, the following call is made:
FileSystem fs = FileSystems.newFileSystem(Paths.get(zipname), null);
A file system will be established that contains all the files in the ZIP document. If you know the file name, it will be easy to copy the file from the ZIP document:
Files.copy(fs.getPath(sourceName), targetPath);
fs.getPath is similar to Paths.get for any file system.
To list all the files in the ZIP document, you can traverse the file tree (this is better):
FileSystem fs = FileSystems.newFileSystem(Paths.get(zipname), null);
Files.walkFileTree(fs.getPath("/"), new SimpleFileVisitor<Path>() {
public FileVisitResult visitFile(Paht file, BasicFileAttributes attrs) throws IOException {
System.out.println(file);
return FileVisitResult.CONTINUE;
}
});
2.5 memory mapping file
Most operating systems can use virtual memory implementations to map a file or part of a file into memory. The file can then be accessed as a memory array. This is much faster than traditional file operations.
2.5.1 performance of memory mapped files
First, get a channel from the file. The channel is an abstraction for disk files. It can access operating system features such as memory mapping, file locking mechanism and fast data transfer between files.
FileChannel channel = FileChannel.open(path, options);
Then, get a ByteBuffer from the FileChannel by calling the map method of the FileChannel class. You can specify the file region and mapping mode you want to map. There are three supported modes:
- FileChannel.MapMode.READ_ONLY: the generated buffer is read-only. Any attempt to write to the buffer will result in a ReadOnlyBufferException exception.
- FileChannel.MapMode.READ_WRITE: the generated buffer is writable, and any modification will be written back to the file at some time. Note that other programs that map the same file may not see these changes immediately. The exact behavior of multiple programs mapping files at the same time depends on the operating system.
- FileChannel.MapMode.PRIVATE: the generated buffer is writable, but any modification is private to the buffer and will not be propagated to the file.
Once you have a Buffer, you can use the methods of ByteBuffer class and Buffer superclass to read and write data.
Buffer supports sequential and random data access. It has a location that can be moved by get and put operations. For example, sequentially traverse all bytes in the buffer:
while (buffer.hasRemaining()) {
byte b = buffer.get();
// ...
}
Or, random access:
for (int i = 0; i < buffer.limit(); i++) {
byte b = buffer.get(i);
// ...
}
The following methods can be used to read and write byte arrays:
get(byte[] bytes) get(byte[], int offset, int length)
Finally, there are the following methods:
getInt getChar getLong getFloat getShort getDouble
Used to read in basic type values stored as binary values in a file. Java uses the high-order sorting mechanism for binary data. However, if you need to process files containing binary numbers in the low-order sorting method, you only need to call:
buffer.order(ByteOrder.LITTLE_ENDING);
To query the current byte order in the buffer, call:
ByteOrder b = buffer.order();
To write a number to the buffer, use the corresponding set method. These changes are written back to the file at the right time and when the channel is closed.
/**
* It is used to calculate the 32-bit cyclic redundancy checksum (CRC32) of a file. This value is often used to judge whether a file has been damaged,
* Because file corruption is likely to cause checksum changes
*/
public class MemoryMapTest {
public static long checksumInputStream(Path filename) throws IOException {
try (InputStream in = Files.newInputStream(filename)) {
var crc = new CRC32();
int c;
while ((c = in.read()) != -1) {
crc.update(c);
}
return crc.getValue();
}
}
public static long checksumBufferedInputStream(Path filename) throws IOException {
try (var in = new BufferedInputStream(Files.newInputStream(filename))) {
var crc = new CRC32();
int c;
while ((c = in.read()) != -1) {
crc.update(c);
}
return crc.getValue();
}
}
public static long checksumRandomAccessFile(Path filename) throws IOException {
try (var file = new RandomAccessFile(filename.toFile(), "r")) {
long length = file.length();
var crc = new CRC32();
for (long p = 0; p < length; p++) {
file.seek(p);
int c = file.readByte();
crc.update(c);
}
return crc.getValue();
}
}
public static long checksumMappedFile(Path filename) throws IOException {
try (FileChannel channel = FileChannel.open(filename)) {
var crc = new CRC32();
int length = (int) channel.size();
MappedByteBuffer buffer = channel.map(FileChannel.MapMode.READ_ONLY, 0, length);
for (int p = 0; p < length; p++) {
int c = buffer.get(p);
crc.update(c);
}
return crc.getValue();
}
}
public static void main(String[] args) throws IOException {
System.out.println("Input Stream:");
long start = System.currentTimeMillis();
Path filename = Paths.get(args[0]);
long crcValue = checksumInputStream(filename);
long end = System.currentTimeMillis();
System.out.println(Long.toHexString(crcValue));
System.out.println((end - start) + " milliseconds");
System.out.println("Buffered Input Stream:");
start = System.currentTimeMillis();
crcValue = checksumBufferedInputStream(filename);
end = System.currentTimeMillis();
System.out.println(Long.toHexString(crcValue));
System.out.println((end - start) + " milliseconds");
System.out.println("Random Access File:");
start = System.currentTimeMillis();
crcValue = checksumRandomAccessFile(filename);
end = System.currentTimeMillis();
System.out.println(Long.toHexString(crcValue));
System.out.println((end - start) + " milliseconds");
System.out.println("Mapped File:");
start = System.currentTimeMillis();
crcValue = checksumMappedFile(filename);
end = System.currentTimeMillis();
System.out.println(Long.toHexString(crcValue));
System.out.println((end - start) + " milliseconds");
}
}
2.5.2 buffer data structure
When using memory mapping, a single buffer is created across the entire file or file area of interest. More buffers can also be used to read and write moderately sized blocks of information.
Buffer is an array of values of the same type. Buffer class is an abstract class. It has many specific subclasses, including ByteBuffer, CharBuffer, DoubleBuffer, IntBuffer, LongBuffer and ShortBuffer(StringBuffer class has no relationship with these buffers).
In practice, the most commonly used will be ByteBuffer and CharBuffer. Each buffer has:
- A capacity that can never be changed.
- A read / write location where the next value will be read / written.
- A limit beyond which reading and writing is meaningless.
- An optional tag that repeats a read in or write out operation.
These values meet the following conditions: 0 ⩽ \leqslant ⩽ marking ⩽ \leqslant ⩽ read / write position ⩽ \leqslant ⩽ boundary ⩽ \leqslant ⩽ capacity.
The main purpose of using buffers is to write and then read into the loop. Suppose there is a buffer, at the beginning, its position is 0, and the limit is equal to the capacity. Continuously call put to add the value to the buffer. When all the data is exhausted or the amount of written data reaches the capacity, it is time to switch to the read operation.
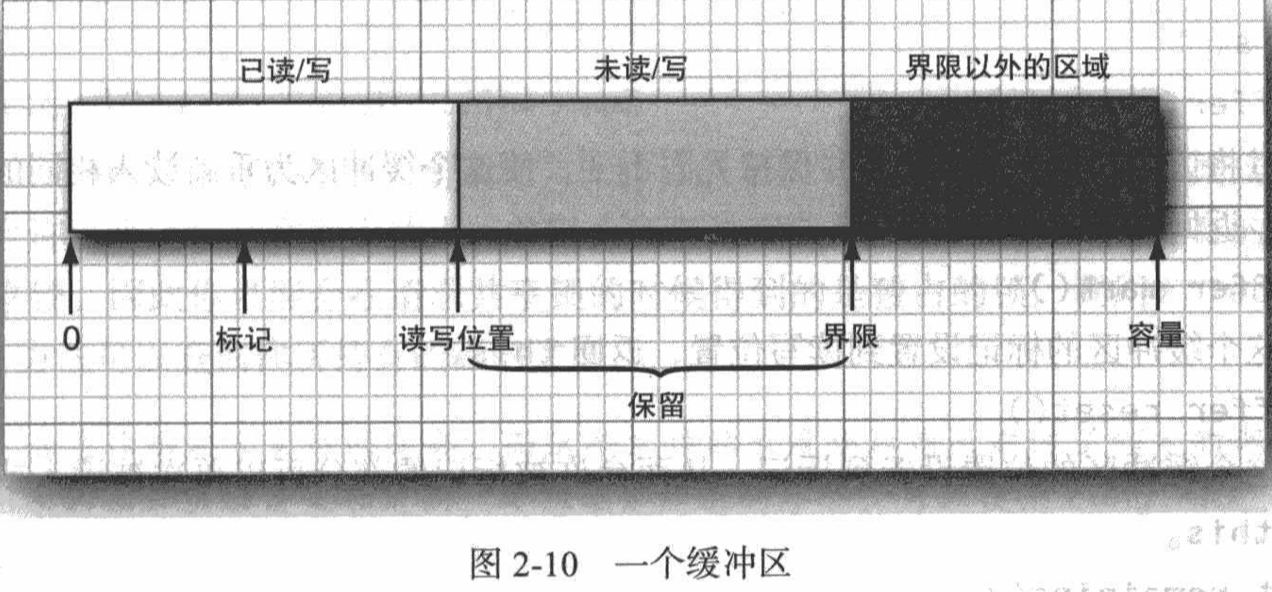
At this time, call the flip method to set the boundary to the current position and reset the position to 0. Now, when the remaining method returns a positive number (the value it returns is boundary position), get is constantly called. After reading all the values in the buffer, call clear to make the buffer ready for the next write cycle. The clear method resets the position to 0 and the limit to capacity.
If you want to reread the buffer, you can use rewind or mark/reset methods. See the API for details.
To get the buffer, you can call static methods such as ByteBuffer.allocate or ByteBuffer.wrap.
The buffer can then be filled with data from a channel or the contents of the buffer can be written out to the channel. For example:
ByteBuffer buffer = ByteBuffer.allocate(RECORD_SIZE); channel.read(buffer); channel.position(newpos); buffer.flip(); channel.write(buffer);
This is a very useful alternative to random access to files.
2.6 file locking mechanism
A file lock can control access to a file or a range of bytes in a file.
If the application stores the user's preferences in a configuration file, when the user calls two instances of the application, the two instances may want to write the configuration file at the same time. In this case, the first instance should lock the file. When the second instance finds that the file is locked, it must decide whether to wait until the file is unlocked or skip the write operation directly.
To lock a file, you can call the lock or tryLock methods of the FileChannel class:
FileChannel channel = FileChannel.open(path); FileLock lock = channel.lock();
Or
FileLock lock = channel.tryLock();
The first call blocks until the lock is available, while the second call returns immediately, either a lock or null if the lock is not available. This file will remain locked until the channel is closed or the release method is called on the lock.
You can also lock a part of the file through the following call:
FileLock lock(long start, long size, boolean shared);
Or
FileLock tryLock(long start, long size, boolean shared);
If the shared flag is false, the purpose of locking the file is to read and write; If true, this is a shared lock that allows multiple processes to read from files and prevents any process from obtaining an exclusive lock. Not all operating systems support shared locks, so you may get exclusive locks when requesting shared locks. Call the isShared method of FileLock class to query the type of lock held.
If the tail of the file is locked, and the length of the file then increases and exceeds the locked part, the increased additional area is unlocked. To lock all bytes, you can use Long.MAX_VALUE to represent the size.
To ensure that the lock is released when the operation is completed, as usual, it is best to release the lock in a try statement with resources:
try (FileLock lock = channel.lock()) {
// access the locked file or segment
}
Remember that the file locking mechanism depends on the operating system. Note:
- In some systems, file locking is only recommended. If an application fails to get the lock, it can still write to the file concurrently locked by another application.
- In some systems, you cannot map a file to memory while locking it.
- File locks are held by the entire java virtual machine. If two programs are started by the same virtual machine (such as applet and application launcher), they cannot each obtain a lock on the same file. When the lock and tryLock methods are called, if the virtual machine already holds another overlapping lock on the same file, the two methods will throw an OverlappingFileLockException.
- In some systems, closing a channel releases all locks on the underlying files held by the java virtual machine. Therefore, avoid using multiple channels on the same locked file.
- Locking files on a network file system is highly system dependent and should be avoided as much as possible.