2021SC@SDUSC
catalogue
Hadoop installation and configuration
ZooKeeper installation and configuration
Hbase installation and configuration
2021SC@SDUSC
HBase overview
HBase is a distributed, high reliable The NoSQL database is, high-performance, column oriented and scalable. Hadoop HDFS provides high reliability underlying storage support for HBase, Hadoop MapReduce provides high-performance computing power for HBase, and Zookeeper provides stable services and failover mechanism for HBase.
HBase cluster installation
Hadoop installation and configuration
- Create the virtual machine Hadoop 102 and complete the corresponding configuration
- Install EPEL release
yum install -y epel-release
- Turn off the firewall. Turn off the firewall and start it automatically
systemctl stop firewalld systemctl disable firewalld.service
- The configuration ycx user has root permission, which is convenient for executing commands with root permission later
vim /etc/sudoers ycx ALL=(ALL) NOPASSWD:ALL
- Create software and module folders in the / opt directory, and modify the owner and group
- Uninstall the JDK of the virtual machine
rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps
- Clone virtual machines Hadoop 103 and Hadoop 104 with Hadoop 102
- Modify the three virtual machines to static IP, taking Hadoop 102 as an example
vim /etc/sysconfig/network-scripts/ifcfg-ens33
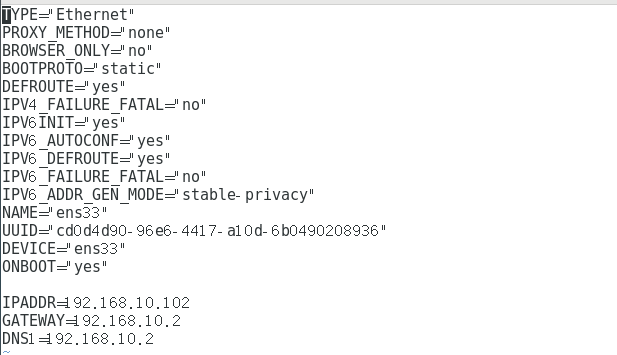
- Set up VMware's network virtual editor
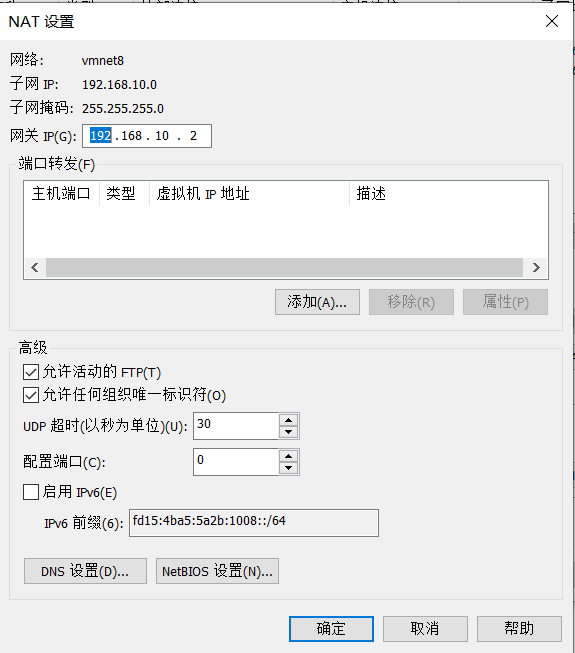
-
Modify the IP address of Windows system adapter VMware Network Adapter VMnet8
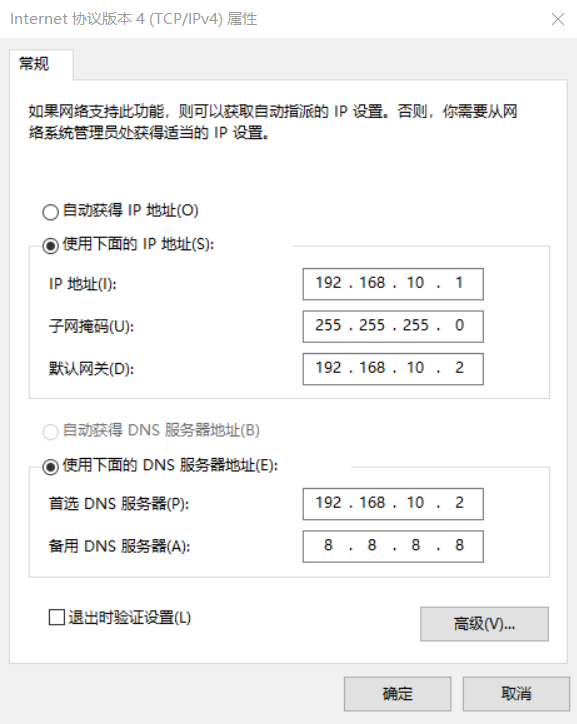
-
Modify the host name, configure the Linux clone host name mapping hosts file, and configure the windows host mapping hosts file
192.168.10.102 hadoop102 192.168.10.103 hadoop103 192.168.10.104 hadoop104
-
Install xshell and xftp, establish a connection with three virtual machines, and download and copy the compressed package required by JDK and hadoop to the virtual machine
-
Install JDK for Hadoop 102, configure environment variables, and write xsync distribution script to distribute JDK to Hadoop 103 and Hadoop 104
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/ sudo vim /etc/profile.d/my_env.sh #JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin source /etc/profile xsync Distribution script: #!/bin/bash if [ $# -lt 1 ] then echo Not Enough Arguement! exit; fi for host in hadoop102 hadoop103 hadoop104 do echo ==================== $host ==================== for file in $@ do if [ -e $file ] then pdir=$(cd -P $(dirname $file); pwd) fname=$(basename $file) ssh $host "mkdir -p $pdir" rsync -av $pdir/$fname $host:$pdir else echo $file does not exists! fi done done chmod 777 xsync xsync /opt/module/ sudo ./bin/xsync /etc/profile.d/my_env.sh -
Install hadoop for hadoop 102, configure environment variables, and distribute them to hadoop 103 and hadoop 104
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/ sudo vim /etc/profile.d/my_env.sh #HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin source /etc/profile xsync /opt/module/ sudo ./bin/xsync /etc/profile.d/my_env.sh
- Configure SSH password free login for Hadoop 102, Hadoop 103 and Hadoop 104
hadoop102: ssh-keygen -t rsa ssh-copy-id hadoop102 ssh-copy-id hadoop103 ssh-copy-id hadoop104
- Configure cluster
core-site.xml: <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>ycx</value> </property> hdfs-site.xml: <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> yarn-site.xml: <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> mapred-site.xml: <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> workers: hadoop102 hadoop103 hadoop104 xsync /opt/module/hadoop-3.1.3/etc/hadoop/ -
Start cluster
hdfs namenode -format sbin/start-dfs.sh sbin/start-yarn.sh
ZooKeeper installation and configuration
- Download the ZooKeeper installation package and copy it to the virtual machine using xftp
- Unzip the installation package
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
-
Configure ZooKeeper
mv zoo_sample.cfg zoo.cfg mkdir zkData vim myid myid File: hadoop102 For 2 hadoop103 For 3 hadoop104 For 4 xsync apache-zookeeper-3.5.7-bin/ vim zoo.cfg take zoo.cfg Medium dataDir Change to/opt/module/zkData,And add server.2=hadoop102:2888:3888 server.3=hadoop103:2888:3888 server.4=hadoop104:2888:3888 xsync zoo.cfg
-
Start ZooKeeper
bin/zkServer .sh start bin/zkCli.sh
Hbase installation and configuration
- Download the Hbase installation package and copy it to the virtual machine using xftp
- Unzip the installation package
tar -zxvf hbase-2.3.6-bin.tar.gz -C /opt/module
-
Configure Hbase
hbase-env.sh: export JAVA_HOME=/opt/module/jdk1.8.0_212 export HBASE_MANAGES_ZK=false hbase-site.xml: <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.master.port</name> <value>16000</value> </property> <property> <name>hbase.wal.provider</name> <value>filesystem</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>hadoop102,hadoop103,hadoop104</value> </property> <property> <name>hbase.zookeeper.property.dataDir</name> <value>/opt/module/zkData</value> </property> regionservers: hadoop102 hadoop103 hadoop104 ln -s /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml /opt/module/hbase/conf/core- site.xml ln -s /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml xsync hbase-2.3.6/
-
Start Hbase
bin/start-hbase.sh
Hbase source code download
- Enter the Hbase download page : https://hbase.apache.org/downloads.html
- Download version 2.3.6
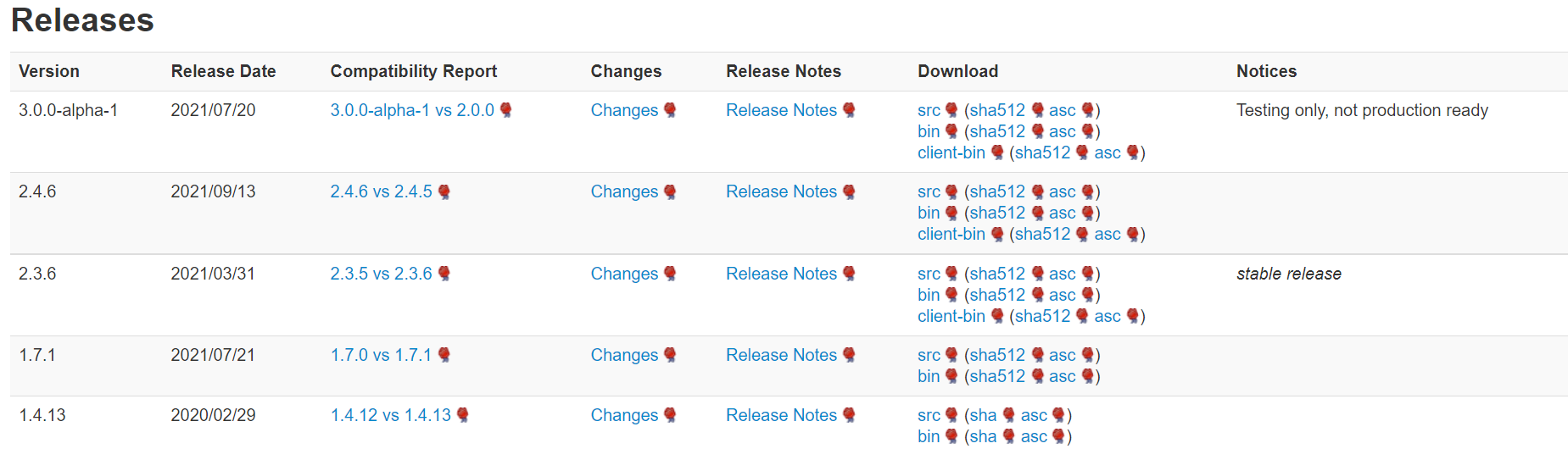
-
Decompression, maven compilation
mvn clean compile package -DskipTests
-
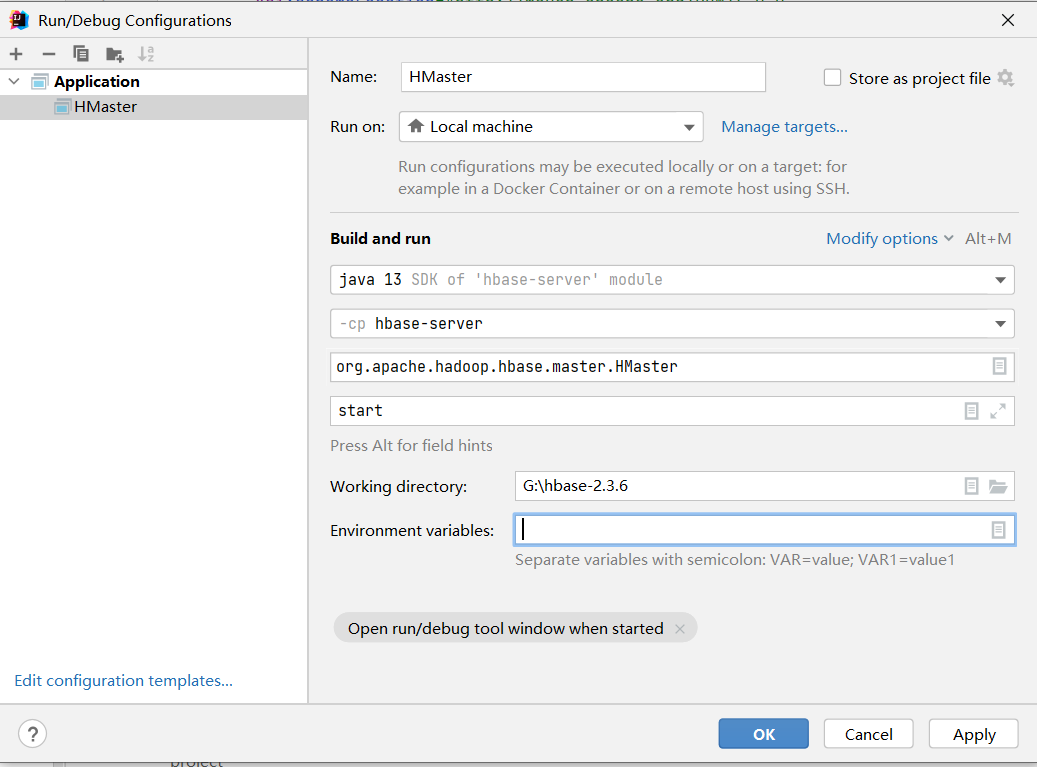
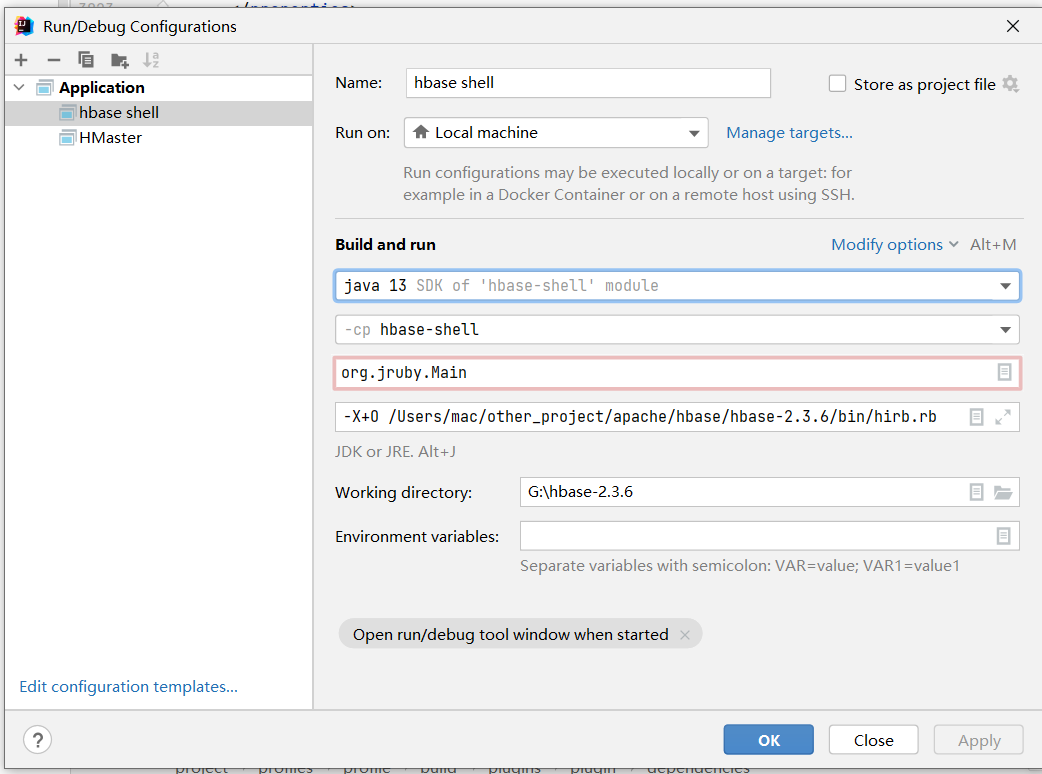
Import IDEA and configure
-
Copy the files in the conf directory to the resources of HBase server and HBase shell
Intra group division of labor
I am responsible for the source code analysis of Hbase data reading and writing process, and the subsequent dynamic adjustment according to the actual progress